📌 학습 개요
Optimization
- Generalizatoin
- Under-fitting and over-fitting
- Cross Validation
- Bias-Variance tradeoff
- Bagging and boosting
Gradient Descent Methods
- Stochastic gradient descent (SGD)
- Momentum
- Nesterov accelerated gradient
- Adagrad
- Adadelta
- RMSprop
- Adam
Regularization
- Early stopping
- Parameter norm penalty
- Data augmentation
- Noise robustness
- Label smoothing
- Dropout
- Batch normalization
Gradient Descent (경사하강법 글 이동)
: 1차 미분계수를 이용하여 함수의 local minimum을 찾는 iterative optimization 알고리즘
Optimization
01. Generalization (일반화)
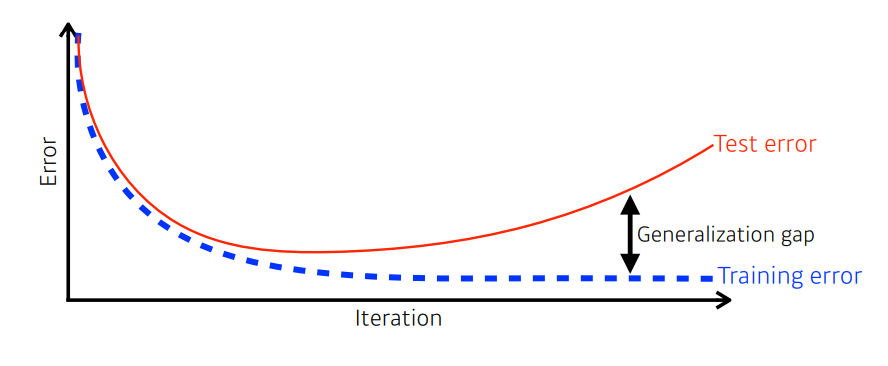
trainige data를 학습하여 모델이 한 번도 본 적 없는 test data도 잘 맞춰야 한다.
위 그림처럼 Training error는 iteration이 커질수록 감소하지만, Test error는 어느정도 감소하다 점점 커져 Generalization gap이 커지는 과적합이 발생할 수 있다.
또한 Training data 또한 덜 학습하여 training data와 test data 둘 다 잘 못 맞추는 과소적합이 발생할 수 있다.
즉, training data를 충분히 잘 학습하여 test data에도 일반화되어 적용될 수 있어야 한다.
02. Underfitting (과소적합) and Overfitting (과적합)
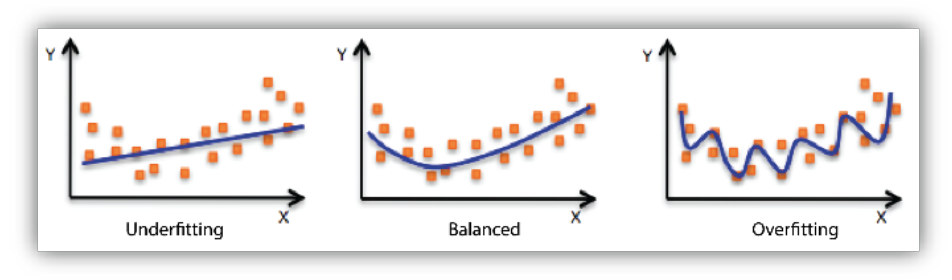
왼쪽 그림은 training data에 대해 덜 학습하여 잘 못 맞추는 Underfitting (과소적합)
오른쪽 그림은 training data에 대해 과하게 학습하여 test에 대해 일반화되지 않는 Overfitting (과적합)
가운데 그림처럼 Balanced된 모델 학습이 요구된다.
03. Cross-Validation (CV, 교차검증)
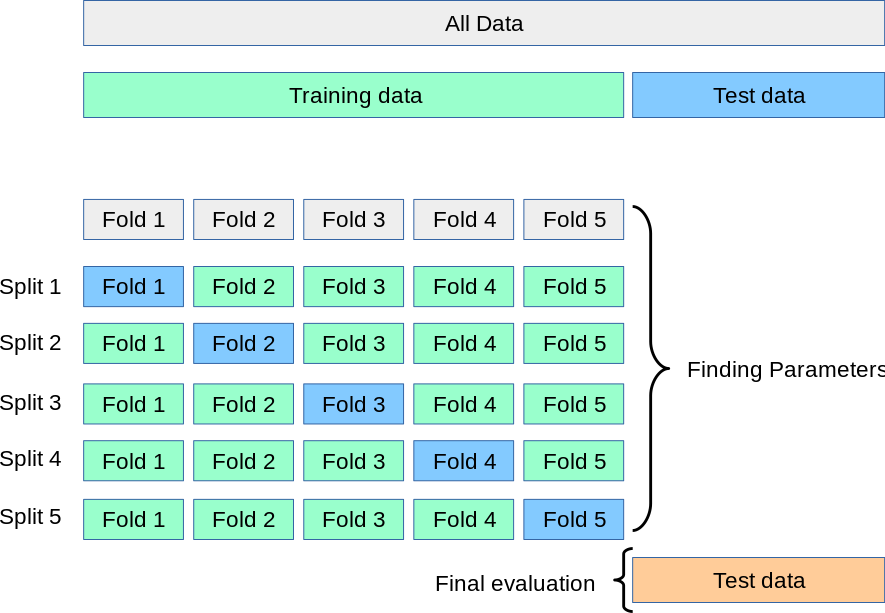
교차검증은 training data의 일부를 학습하지 않고 모델을 검증하는 validation data를 사용한다.
이때 위 그림처럼 iteration마다 training data와 validation data가 다르게 사용된다.
CV를 통해 최적의 parameter-set을 찾는다.
04. Bias-Variance Tradeoff
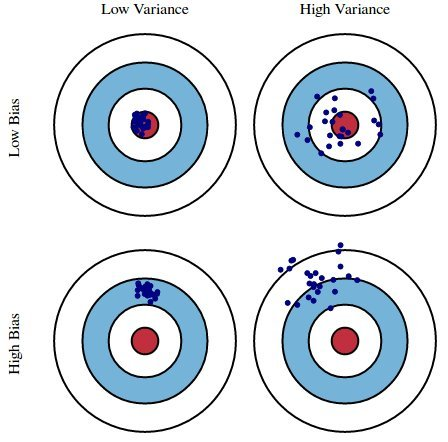
Variance(분산)이 크면 -> 일관되지 않은 출력값, outlier까지 포함하는 overfitting 발생
Bias(편향)이 크면 -> 정답값과 거리가 먼 출력값, 그냥 틀리는거니 underfitting 발생
즉, 최고의 결과는 Variance와 Bias 모두 낮아지는 것이다.
하지만 이 둘은 Tradeoff 관계이다.
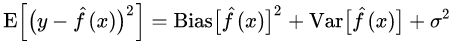
위는 표본 x에 대한 기대 오차를 나타낸 수식이다.
여기서 Bias와 Var의 수식은 다음과 같다.
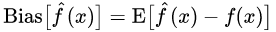
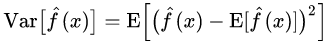
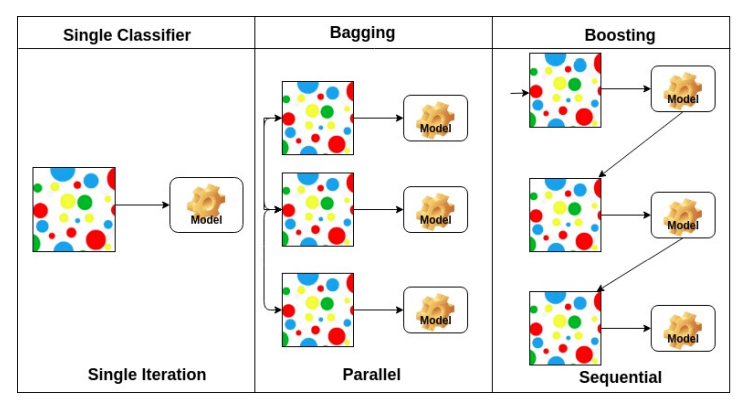
05. Bagging and Boosting
Bootstrapping
: random sampling(표본 추출)을 사용하는 test나 metric
-
Bagging (Bootstrapping aggregating)
Bootstrapping을 통해 여러 샘플을 추출하고 각 모델에 학습시켜 각 결과물을 aggragate한다.
이 방법을 활용한 모델 - Random Forest -
Boosting
마찬가지로 여러 샘플을 활용하여 각 모델에 학습시키지만, 먼저 한 모델을 학습시킨 후 오답에 높은 가중치를 부여하여 다음 모델을 생성한다.
이에 대해서는 따로 더 자세히 설명하는 글을 올릴 예정
Gradient Descent Methods
01. Stochastic graident descent (SGD)
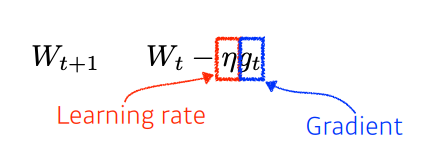
가장 기본적 gradient descent 방법.
문제점: 적절한 Learning Rate를 찾기 힘듦.
02. Momentum
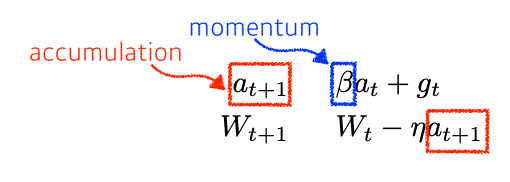
현재 주어져있는 파라미터에서 그레디언트를 계산하고 그 그레디언트를 가지고 momentun을 accumulate한다.
이전 그레디언트를 다음 그레디언트 계산에 흘려줘서 같이 활용하기 위한 방법.
문제점: 왔다리갔다리 하니까 local minimun으로 converge하기 어려움.
03. Nesterov Accelerated Gradient
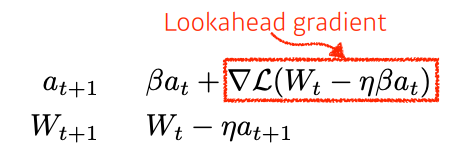
a라는 현재 정보가 있으면 그 방향으로 일단 가보고 거기서 그레디언트를 계산하여 accumulation한다.
momentum보다 local minumum에 더 빠르게 수렴할 수 있다.
04. Adagrad
Neural Network의 parameter가 지금까지 어느정도 변해왔는지 고려하여 각 parameter를 update 한다.
이전에 크게 변했다면 적게 변하도록, 적게 변했다면 크게 변하도록.
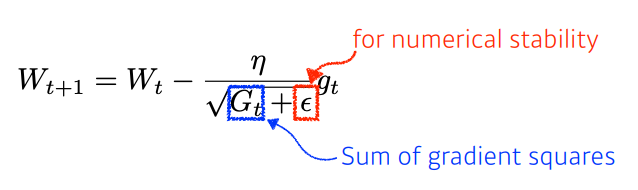
입실론: division of 0를 방지하기 위해 더해줌.
Gt: 지금까지 그레디언트가 얼마나 많이 변했는지 제곱해서 더해준 값.
문제점: Gt값은 점점 커질 것이기 때문에 가면 갈수록 분모가 커져 0에 가까워지므로 weight가 업데이트되지 않는, 즉 학습이 점점 멈춰지는 현상 발생.
05. Adadelta
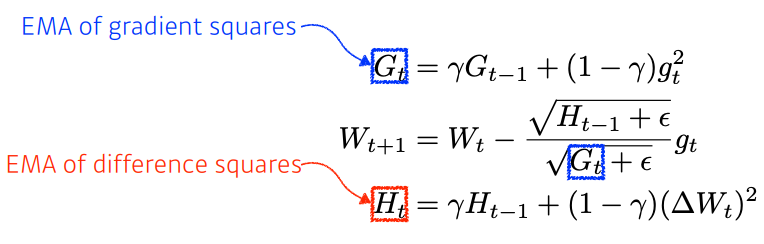
Adagrad의 문제를 방지하기 위해 window size만큼의 이전 그레디언트 정보만 사용하겠다.
window size가 크면 그만큼 큰 그레디언트의 정보를 들고 있어야 함. -> GPU 터짐
=> 이를 방지하기 위한 것: EMA
문제점: Learning Rate가 없다.
06. RMSprop
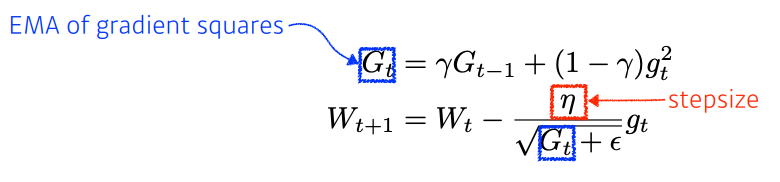
Adadelta와 다르게 EMA를 활용하며 Learning Rate이 있다.
어떤 교수가 논문도 안 내고 걍 일케 했더니 잘되더라~ 로 등장.
07. Adam
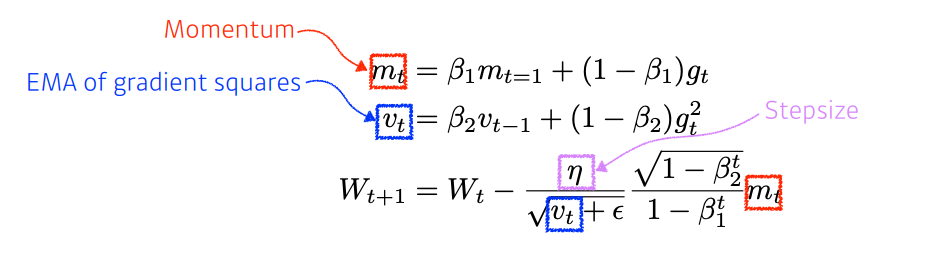
Adaptive learning rate와 Momentum을 모두 가져 가장 무난하게 많이 사용된다.
Hyper-parameters
- 베타1: Momentum을 얼마나 유지할지
- 베타2: Gradient squared에 대한 EMA 정보
- 에타: Learning Rate
- 입실론: division of 0 방지
Regularization
01. Early Stopping
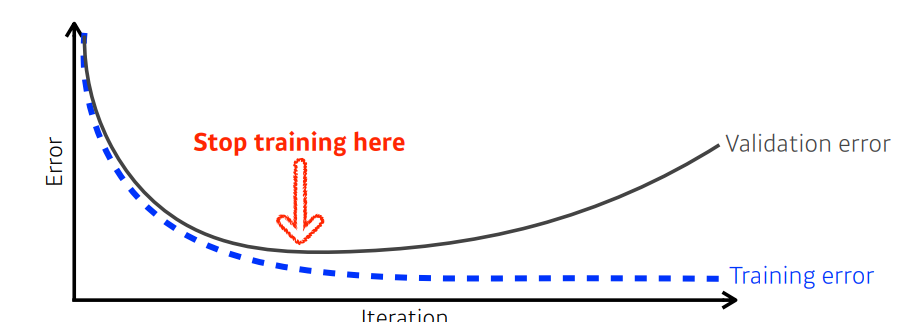
과적합되기 전에 일찍 끝내라
02. Parameter Norm Penalty

놈 규제, weight decay
parameter Norm Penalty를 주어 이도 loss와 함께 줄이는 것.
weight 크기가 작으면 작을수록 좋다. -> function space에서 함수를 부드럽게 하여 일반화하기 위해.
03. Data Augmentation
데이터가 적을 때는 Traditional ML의 성능이 더 좋았지만, 데이터가 커지며 DL의 성능이 월등히 높아졌다.
label이 바뀌지 않는 조건으로 data를 여러 방법으로 확대하는 것. (label preserving aumentation)
04. Noise Robustness

inputs 데이터나 weight에 noise를 추가하면 성능이 좋아짐.
왜인지는 모름.
05. Label Smoothing
data augmentation과 비슷하지만, label smoothing은 학습 데이터 두 개를 뽑아 활용함.
-> decision boundary가 부드러워짐.

두 이미지와 레이블을 mixup, cutout, cutmix하여 학습시키면 성능이 노력에 비해 상당히 높아진다고 한다.
왜인지는 모름.
06. Dropout
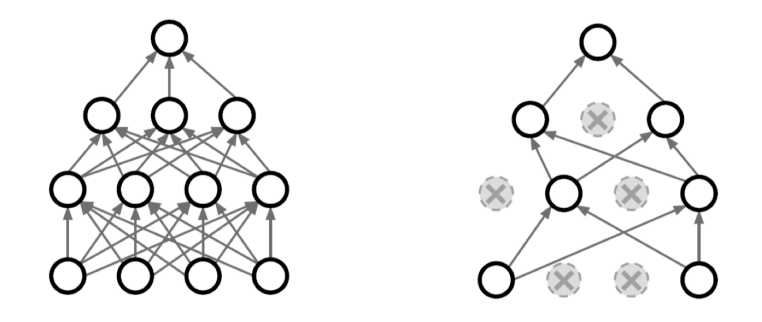
노드 간 dense한 연결은 과적합을 일으킬 수 있으니 적당히 끊어주는 것.
07. Batch Normalization
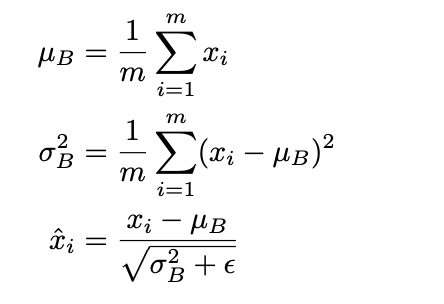
적용하고자 하는 layer에 statistic을 정규화시키는 것.
각 layer가 1000개 파라미터라고 하면, 1000개 파라미터값들에 대해 mean 0, univariance가 되게 만드는 것.
BN을 사용하면 특히 layer가 깊게 쌓이는 경우에 성능이 많이 향상된다.
cf. Adam > Momentum > SGD 비교
-
SGD가 비교적 결과가 안 좋은 이유
momentum, adam의 경우, 이전의 그레디언트를 고려하지만 sgd는 매번 새로운 데이터로 개별적으로 데이터를 보기 때문에 epoch을 더 많이 돌아야 한다.
예를 들어 10000개 데이터 중 64개 batch라고 한다면 10000개에 대해 정보를 맞추려면 엄청 많은 iter를 돌아야 함. -
MSE 사용 시 오류에 대해 제곱을 해주는 squared loss이기 때문에, 오류가 큰 것에 대해 더 맞추려 하게 되고 적게 틀리는 부분은 덜 집중하게 된다. -> outlier가 있는 경우에 squared loss를 사용하는 것은 좋지 않음.
-
Adam은 Adaptive Learning rate, momentum이 모두 활용되기 때문에 가장 빨리 수렴한다.
-> 일단 Adam을 써보는게 무난하다. -
그렇다고 항상 SGD가 Adam보다 안 좋은 것은 아님.
많은 에폭을 봐야하는 만큼 수렴 속도가 오래 걸리지만 그렇게 다 돌렸을 때 Adam보다 좋을 수도 있음. -
optimizer에 따라 모델의 성능과 수렴 속도 등이 달라질 수 있다.

2개의 댓글

Dropout을 이용할 경우 1. 어떻게 오버피팅을 방지할 수 있는지 2. 학습이 끝난 후 결과를 예측할 때 어떻게 사용하는지 추가로 알아두면 좋을 것 같습니다!
모델의 적합에서 Bias와 Variance가 의미하는게 무엇인지 파악하면 좋을 것 같습니다!
간단하게 Regression의 경우라고 가정하고 머신러닝 방법론들과 연결지어서 생각하면 좋을 것 같습니다.
Ex) 의사결정나무는 Bias가 낮고 Variance가 높다. 이것이 무엇을 의미하는가?