(2020/12/04 작성)

TensorFlow Recommenders (TFRS)는 (당연하게도) TensorFlow 2.0을 기반으로 개발중인 TensorFlow 공식 라이브러리로, 사용자가 데이터 로드부터 모델 학습 및 배포까지 손쉽게 할 수 있는 많은 기능을 제공한다. 최근, 0.3.0 버전으로 업데이트 되는 등 빠르게 개발되고 있는데, Catch-up도 하고, 영감도 얻고, Contribution할 것들이 뭐가 있을까 살펴볼 겸 코드를 실행하고 살펴보았다.
아직 완전히 이해하진 못했지만, 지금까지 재미있게 본 점들을 아래 기록하고자 한다.
Two Stage Approach
현실의 추천 시스템은 몇 천, 몇 만의 사용자, 아이템을 넘어 수 백만의 단위에서 실행된다. 수 백만개의 아이템에서 사용자가 관심있는 영화는 아주 소수일 것이기 때문에, 모든 아이템에 대해 매번 전부 scoring 및 ranking을 하는 것은 비효율적, 비현실적이다. 따라서, 관심있을만한 후보 아이템(candidate)을 추리고, 이 안에서 순위를 매기는 방법을 생각해볼 수 있다. 이를 Retrieval, Ranking 으로 부른다.
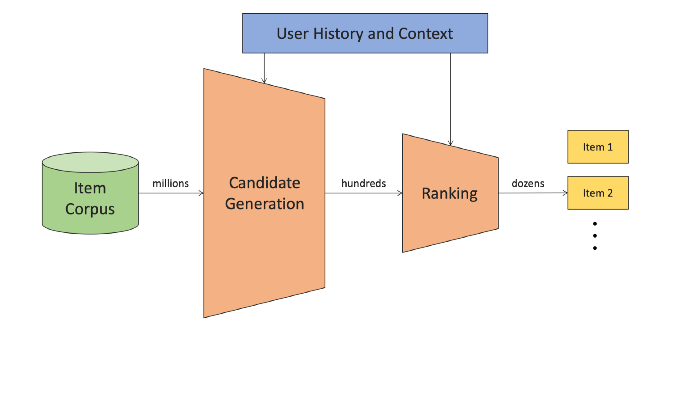
Retrieval은 사용자의 정보와 구매 이력 등으로 전체 아이템에서 후보 아이템을 추출하는 과정이다. 수 백만개의 유튜브 영상에서 1000개 후보 영상을 뽑아 효율적인 Ranking을 가능하게 한다. 이 과정에서 중요한 점은 정확하고 빠르게 후보를 생성하는 것이다. 추천 된다면 좋아했을 영상이 후보에서 탈락할 수 있는데, 이를 최대한 방지해야 하며, 아무리 정확한 후보를 1000개 뽑는다고 해도 시간이 너무 오래걸린다면 현실적으로 적용하기 어렵다.
Google에서는 최근 ICML 2020에 Approaximate Neraest-Neighbor(ANN)를 빠르게 찾는 ScaNN이라는 모델을 발표한 바 있으며, TFRS 내부에도 사용되는 것을 확인할 수 있다.
Ranking은 Retrieval에서 생성한 후보 아이템에서 사용자가 좋아할 아이템을 Scoring하고 Top-K를 추출하는 역할을 한다. 그 동안 Top-N Recommendation이라는 문제로 제안된 많은 논문들은 One Stage Ranking 문제를 풀고 있다고 이해할 수 있다.
Streaming Top-k
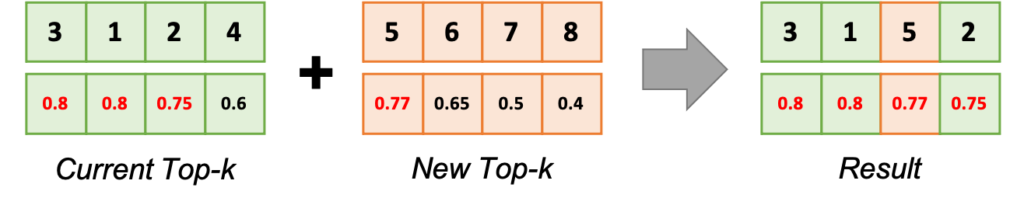
TFRS의 Top-k를 보다가 흥미로운 것을 발견했다. Streaming 이라는 이름의 class로 구현되어 있는데, 일반적인 Top-k에 변형이다. 학습 기반 추천 모델은 학습이 진행됨에 따라 사용자에 대한 Top-k 아이템과 추천 score가 계속 바뀐다. 일반적인 Top-k는 Inference time을 기준으로 계산한 Score로 Top-k를 제공한다.
Streaming은 여기서 한발 더 나아가 현재의 Top-k와 이전에 제공한 Top-k (State)의 점수를 같이 놓고 다시 한번 Top-k 연산을 수행한다. 즉, 현재에서는 Top-k일지 모르지만, 지금까지의 Top-k와 비교했을 때 score가 그리 높지 않다면 현재의 추천을 바꾸지 않는 것이다. 여기서 이름이 Streaming인 이유를 알 수 있다. 한번의 추천으로 끝나는 것이 아니라, 사용자의 Session이 계속 진행 중이며, 추천이 이미 제공되었다는 가정 하에, 새로운 추천을 이에 적용하는 것이다. 기존 추천보다 score가 낮다면 사용자에게 보여줄 이유가 없다.
마무리
위 Two Stage 설계와 Streaming Top-k의 공통점은 "실제 서비스를 고려한 설계"라는 점이다. 현업에서는 매번 모든 아이템을 Ranking하지 않으며, 사용자가 서비스를 계속 이용하는 상황 (e.g. YouTube, Spotify)에서는 모든 추천 리스트를 통째로 update하는 것보다 기존 추천 리스트에 새로운 추천 아이템을 잘 섞는 것이 필요하다.
개인적으로 추천을 석사 과정에 조금이나마 연구해본 경험으로는 생각해보지 못했는데, 이러한 점에서 학계와 현업의 간극 (?)이 느껴진다. 실제 추천 시스템은 도대체 어떻게 돌아가며, 현업에서는 어떤 고민들을 하는 것일까?
