[SIGIR 2020] How Dataset Characteristics Affect the Robustness of Collaborative Recommendation Models
paper-review
(2020/11/14 작성)
- How Dataset Characteristics Affect the Robustness of Collaborative Recommendation Models
- Yashar Deldjoo, Tommaso Di Noia, Eugenio Di Sciascio, Felice Antonio Merra
- Polytechnic University of Bari
TL;DR
- 가짜 사용자로 추천 시스템의 성능을 망가뜨리는 방법을 Shilling attack이라고 한다.
- 추천 데이터셋에는 크기, 희소성 등 여러 특징이 있다.
- 데이터셋 특징이 Shilling attack 효과를 설명할 수 있다.
- 선형 회귀로 실험한 결과, 데이터셋의 특징 (특히, 크기, 모양 희소성 등)이 유의미한 설명을 하는 것으로 밝혀졌다.
Motivation
Robustness of Recommender System: Collaborative Filtering 기반 추천 시스템은 수 많은 사용자들의 평점 기록들이 힘을 모아 만든 패턴을 분석하여 다른 사용자에게 추천을 제공합니다. 당연하게도, 가장 중요한 것은 사람들의 평점 기록이며, 이것이 달라질 경우 추천 또한 달라집니다. 예를 들어, 해리포터를 좋아하는 사람이 반지의 제왕도 많이 좋아하는 패턴이 존재하는데, 어느 순간 "해리포터를 좋아하지만 반지의 제왕은 안보고 공포영화만 엄청 보는 사용자" 가 늘어난다면 추천 시스템은 패턴을 파악하여 해리포터와 공포영화 패턴을 학습하게 됩니다.
이를 극단적으로 악용하면 (그러면 안되지만..), 경쟁 업체의 서비스에 가짜 사용자를 마구 추가하여 임의의 패턴을 넣어버리면 추천 시스템을 망가뜨릴 수 있게 됩니다. 따라서, "가짜 혹은 터무니없는 패턴의 사용자에 의한 추천 성능 변화가 얼마나 예민하게 일어나는가"는 서비스 입장에서 중요한 고려사항이고 이를 Robustenss of Recommender System이라고 부릅니다.
일반적으로 Robustness 관련 연구는 모델링에 집중합니다 (어떻게 하면 더 Rubust한 모델을 만들수 있을까?). 하지만, 이 논문의 저자는 다른 관점으로 문제를 바라봅니다.
데이터의 특성에 따라서 가짜 사용자에 의한 공격효과가 다를까?
Dataset Characteristics
추천 데이터셋의 특징에는 여러가지가 있습니다. 크게 3가지 그룹으로 나누어 살펴보면 다음과 같습니다.
Structural: Size, Shape, Density
U명의 사용자, I개의 아이템에 대한 R개의 평점이 존재한다고 할 때, 추천 시스템 데이터는 U-I Rating matrix로 표현할 수 있습니다. 구조적 특징은 데이터의 모양에 관한 것으로 Size (U x I), Shape (U / I), Density (R / (U x I)) 가 있습니다.
Rating frequency: Gini-index User/Item
추천 시스템의 평점은 흔히 Long-tail 이라고 합니다. 즉, 소수의 사용자/아이템이 다수의 평점을 소유한다는 말입니다. 이때, 얼마나 불평등하게 평점이 분배되어있는지를 불평등지수인 Gini-index로 수치화할 수 있습니다. Gini-index는 0~1사이의 값을 가지며 1에 가까울 수록 불평등합니다.
이 외에 평점 값 자체의 특징으로 R개 평점의 평균 및 분산이 있습니다. 다양한 데이터셋의 통계를 여러 전처리에 따라 정리한 자료를 첨부합니다. (https://github.com/yoongi0428/recsys_data_zoo)
Shilling Attack Strategy
추천 시스템에 가짜 사용자를 추가하여 패턴을 망가뜨리는 방법을 Shilling attack 이라고 합니다. Shilling attack 방법에는 6가지가 있습니다. 무작위 아이템을 좋아하는 사용자, 인기 아이템만 좋아하는 사용자, 관련 있는 아이템 평점을 모두 1로 주는 사용자 등 6가지가 있습니다. 자세한 설명은 공간상 생략합니다.
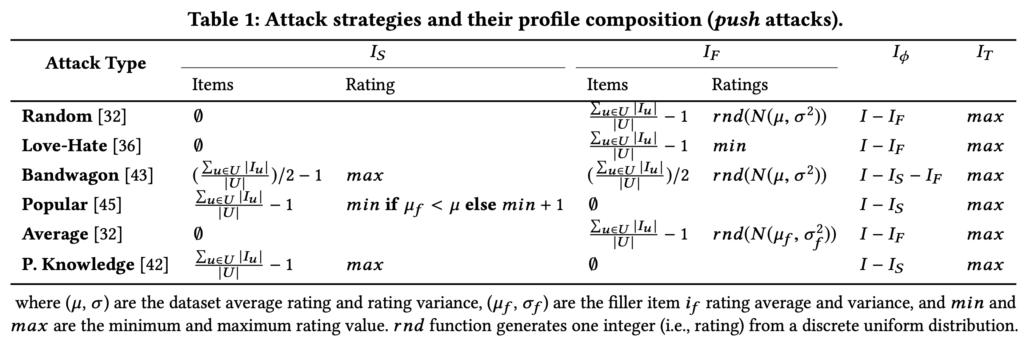
Explanatory Regression Model
앞서 말한 질문에 대답하기 위해 논문에서는 회귀모형을 도입합니다. 구체적으로는, (데이터셋, 모델, 공격방법, 공격량)이 주어질 때, 공격 효과에 각 특징의 유효성을 검증하고자 합니다.
선형 회귀에는 독립변수와 종속변수가 있습니다. 문제 정의에 따라 독립변수는 6개의 데이터 특징이고 종속변수는 공격효과로 (공격 이전 HR - 공격 이후 HR)로 계산됩니다. 모델 최적화는 OLS에 의해 아래와 같이 수행합니다.
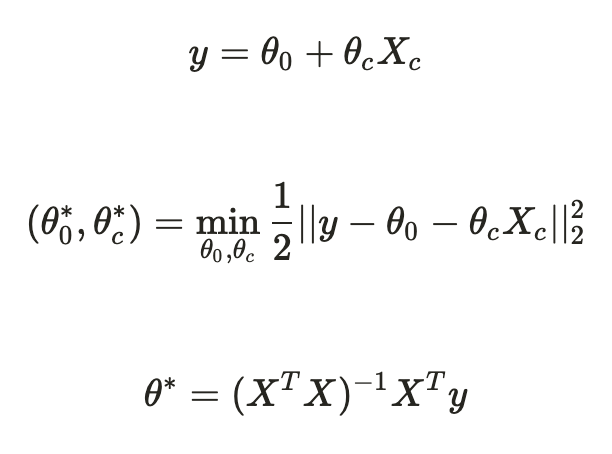
Experiment Setups
데이터 생성: 앞서 말했듯, 선형회귀를 돌리려면, 다양한 특징 (X)과 그에 따른 공격효과 (Y)가 필요합니다. 이를 위해, 각 원본 사용자-아이템 행렬로부터 무작위 사용자, 아이템을 선택하여 600개의 작은 행렬을 만듭니다. 600개의 작은 데이터 위에서 주어진 (데이터셋, 모델, 공격방법, 공격량)에 대해 X, Y를 측정하고 선형회귀를 수행합니다.
실험 모델은 UserKNN, ItemKNN, SVD로 3개이며, 데이터셋 또한 ML-20M, Yelp, LFM-1b로 3개입니다. 공격 방법은 무작위, 인기 사용자를 포함한 6가지이고, 공격 크기는 기존 사용자의 1, 2.5, 5%입니다.
위 설정을 보면 수행해야 되는 선형 회귀의 수는 데이터 수 (3) X 모델 수 (3) X 공격 방법 (6) X 공격 크기 (3) X 샘플 수 (600)로 총 97200이다. (WOW)
Experimental Results
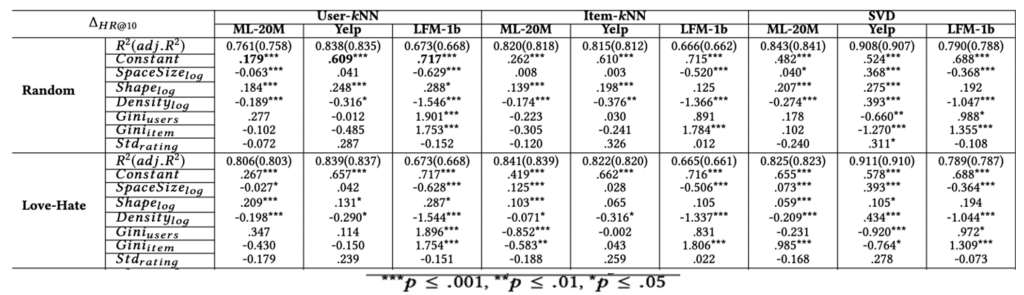
실험 결과를 핵심 부분만 간단히 살펴보겠습니다. 공간상 6개 공격방법 중 2개만 가져왔습니다.
- R^2는 IV가 DV를 얼마나 설명하는 지를 나타낸다고 볼 수 있습니다. 실험 결과 모든 경우 60% 이상의 설명을 IV가 하는 것으로 밝혀졌습니다. (최대 90%까지)
- 6개의 특징 중 구조적 특징 (size, shape, density)가 크게 영향을 미치는 것으로 밝혀졌습니다.
- Density가 높을수록 (평점이 많이 쌓일수록) 공격의 효과가 적으며
- 아이템에 비해 사용자의 수가 많을 경우 공격의 효과가 큰 것으로 밝혀졌습니다.
위 결과로부터 데이터셋 특징이 공격효과를 유의미한 수준으로 설명한다고 결론지을 수 있습니다.
Conclusion
이 논문은 Shilling attack에 따른 추천 시스템의 성능 변화가 데이터셋 특징에 얼마나 영향을 받는지를 실험적으로 분석하였습니다. Shilling attack이 아닌 추천 그 자체에도 데이터셋의 특징이 영향을 받을 것 이라고 생각하는데, 이 부분에 대한 연구도 진행하면 재밌을 것 같습니다. 도메인에 따라 (음악, 영화, 이커머스), 데이터가 갖는 특징은 다를 것 입니다. 예를 들어, 이커머스의 경우 사용자보다 아이템의 수가 훨씬 많을 수 있고, 영화의 경우 한 영화를 평점을 매긴 후 다른 영화들에 대해 평점을 매기는 시간의 차이가 크고 그 사이 사용자의 intention이 변할 수 있습니다. 만약 각 도메인에서 데이터 특징을 이해하고, 어떤 모델이 어떤 데이터에서 잘 동작하는 지를 알 수 있다면, 한층 더 서비스에 도움이 되지 않을까 싶습니다.
