https://arxiv.org/pdf/2306.11489
본 포스팅은 2024년 IEEE Transactions on Knowledge and Data Engineering에 등재된 "Give Us the Facts" 논문리뷰 입니다.
해당 논문은 PLM의 한계를 아래와 같이 꼽는다.
이를 해결하기 위해서 KG + LLM의 형식을 아래 사진과 같이 3단계로 나누어 설명을 한다.

각각의 방식과 각 단계에서 사용되는 매커니즘을 정리하면 다음과 같다.
1. 학습 전 강화 (Before-training Enhancement)
매커니즘:
입력 구조 확장: 입력 데이터를 확장하여 더 많은 정보를 포함할 수 있도록 합니다.
임베딩 결합: 토큰 임베딩, 세그먼트 임베딩, 위치 임베딩 등을 결합하여 입력을 더 풍부하게 표현합니다.
인공 텍스트 생성: 사전 학습에 사용할 인공 데이터를 생성하여 데이터의 다양성을 높입니다.
지식 마스킹 전략: 입력 토큰 중 일부를 마스킹하여 모델이 마스킹된 부분을 예측하도록 하는 방식으로 학습을 진행합니다.
2. 학습 중 강화 (During-training Enhancement)
매커니즘:
지식 인코더 통합: 외부 지식(예: 지식 그래프)을 통합하는 지식 인코더를 도입하여 학습 중에 모델에 지식을 주입합니다.
지식 인코딩 레이어 삽입: 모델의 내부에 추가적인 레이어를 삽입하여 지식을 처리할 수 있도록 합니다.
독립 어댑터 추가: 원래 모델의 매개변수에 영향을 주지 않으면서 학습할 수 있는 독립적인 어댑터를 추가하여 지식을 주입합니다.
사전 학습 작업 수정: 기존의 사전 학습 작업을 지식 기반의 과제로 수정하여 학습 성능을 높입니다.
3. 학습 후 강화 (Post-training Enhancement)
매커니즘:
지식을 사용한 PLM 미세 조정: 특정 도메인에서 성능을 높이기 위해 도메인 특화 데이터로 PLM을 미세 조정합니다.
지식 기반 프롬프트 생성: 자동으로 생성된 프롬프트를 사용하여 모델의 출력을 개선하거나, 도메인 특화된 텍스트를 생성하도록 유도합니다.
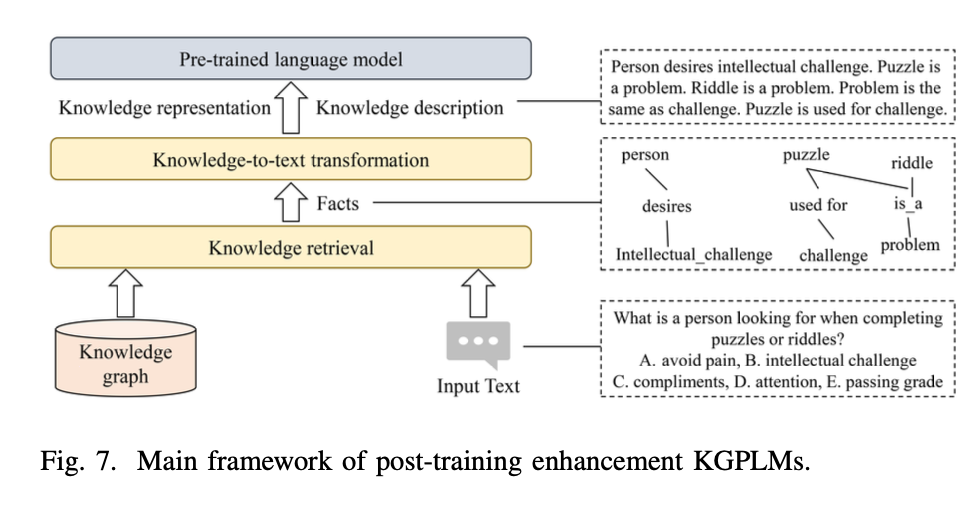
위 사진은 학습 후 강화의 방식중 프롬프트엔지니어링과 관련된 아키텍처이다.
간단히 설명을 해보자면
1) 지식 검색(Knowledge Retrieval):
지식 그래프(Knowledge Graph)에서 관련 지식을 검색합니다.
이를 통해 외부의 구조화된 지식을 가져와 모델에 필요한 정보를 제공하게 됩니다.
2) 지식-텍스트 변환(Knowledge-to-Text Transformation):
검색된 지식(사실 정보)은 자연어 형태로 변환되어, 모델이 이해할 수 있도록 텍스트 설명으로 나타냅니다.
이 과정은 모델이 지식 그래프에서 가져온 정보를 자연어로 바꿔 활용하는 중요한 단계입니다.
3) 지식 설명 및 표현(Knowledge Description and Representation):
변환된 텍스트는 지식 설명으로 제공되며, 이를 통해 모델은 질문에 답변하거나 새로운 텍스트를 생성할 수 있습니다.
이 단계에서는 지식 기반의 텍스트 생성을 통해 문제 해결을 지원합니다.
4) 입력 텍스트와 결합:
사용자가 제공한 입력 텍스트(Input Text)는 모델이 지식을 결합하여 보다 정확한 응답을 생성할 수 있도록 사용됩니다.
모델은 입력 텍스트와 지식 그래프에서 가져온 정보를 바탕으로 최종 응답을 도출하게 됩니다.
예시는 퍼즐이나 수수께끼를 해결할 때 무엇을 찾고 있는가?라는 질문에 대해 상식 지식을 사용하여 답변을 생성하는 과정을 보여줍니다.
"Person desires intellectual challenge." 등과 같은 텍스트로 변환된 지식이 질문에 맞게 설명되고, 이를 기반으로 적절한 선택지 (B. Intellectual challenge)를 생성하게 됩니다.
위 방식은 프롬프트 기반 최적화로 비용 효율적인 부분에 이득이 있으나
1) 유연성 제한: 프롬프트에 의존하는 방식이기 때문에, 생성되는 텍스트의 자유도가 제한될 수 있음
2) 사전 지식 의존: 프롬프트나 미세 조정을 위한 사전 지식이 부족할 경우 최적화 효과가 제한될 수 있음
위와 같은 어려움도 있다.
