https://arxiv.org/abs/2306.08302
본 논문이 등장한 배경 :
LLM
1.LLM의 사실적 지식 부족 => 사실과 다른 진술 생성해서 환각 현상을 겪음
2. LLM은 블랙박스 모델로서 해석 가능성이 부족함(매개변수 안에 지식을 암묵적으로 표현하기 때문)
KG
엄청난 양의 사실을 트리플 (head entity, relation, tail entity) 형식으로 저장
ex) (Bob Dylan, wrote, Blowin' in the Wind) 같은 형식, 이를 통해, 데이터 간의 명시적인 연결성을 강조
이점 :
1. 상징적 추론 능력 -> 해석 가능한 결과
2. 새로운 지식의 추가로 능동적 진화
단점 :
1. 보이지 않는 엔티티를 효과적으로 모델링하거나 새로운 사실을 나타내지 못함
정리 :
KG만 활용하는 경우: KG는 매우 구조적이고 신뢰할 수 있는 지식을 제공하지만, 실시간으로 변화하는 정보를 반영하거나 비구조적인 새로운 지식을 쉽게 추가하기 어려움
LLM만 활용하는 경우: LLM은 많은 지식을 비구조적으로 저장하고 있지만, 그 지식이 암묵적이기 때문에 어떤 정보가 사실인지, 그리고 어떤 추론 과정을 거치는지 명확하지 않음. 또한, KG와 같은 명시적 지식을 활용하지 않으면 환각 문제나 불완전한 추론이 발생할 수 있음
본 논문에서 제시한 해결 로드맵
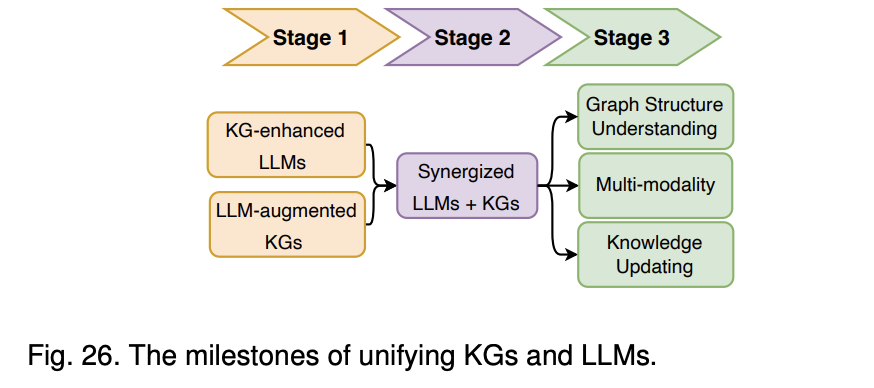
Stage 1
- KG 강화 LLM (KG-enhanced LLMs) : LLM의 학습 과정이나 추론 과정에서 KG를 활용하여 더 정확하고 사실에 기반한 결과를 도출하는 데 중점
- LLM 증강 KG (LLM-augmented KGs): LLM이 비구조화된 텍스트에서 새로운 정보를 추출하고, 이를 KG에 추가하여 KG의 완성도를 높이는 것이 목표
Stage2
- 두개를 합쳐서 시너지 효과 -> KG가 LLM의 신뢰성을 강화하고, LLM이 KG의 정보를 보완하는 형태
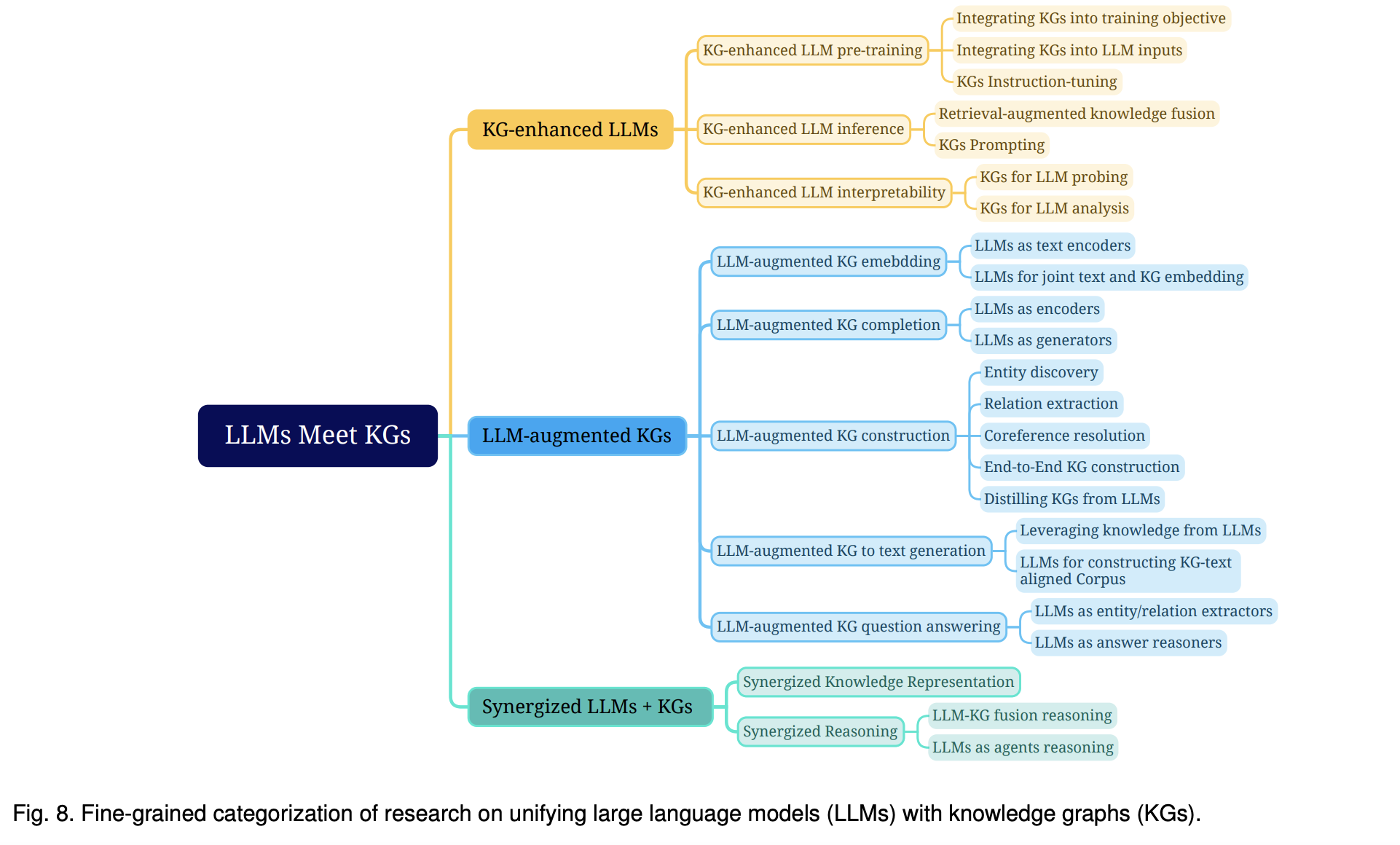
KG 강화 LLM (KG-enhanced LLMs)
KG를 통합함으로써 LLM은 다양한 다운스트림 작업에서 성능과 해석 가능성을 향상시킬 수 있음
- KG 강화 LLM 사전 학습에는 KG를 사전 학습 단계에서 적용하고 LLM의 지식 표현을 개선하는 연구가 포함됨
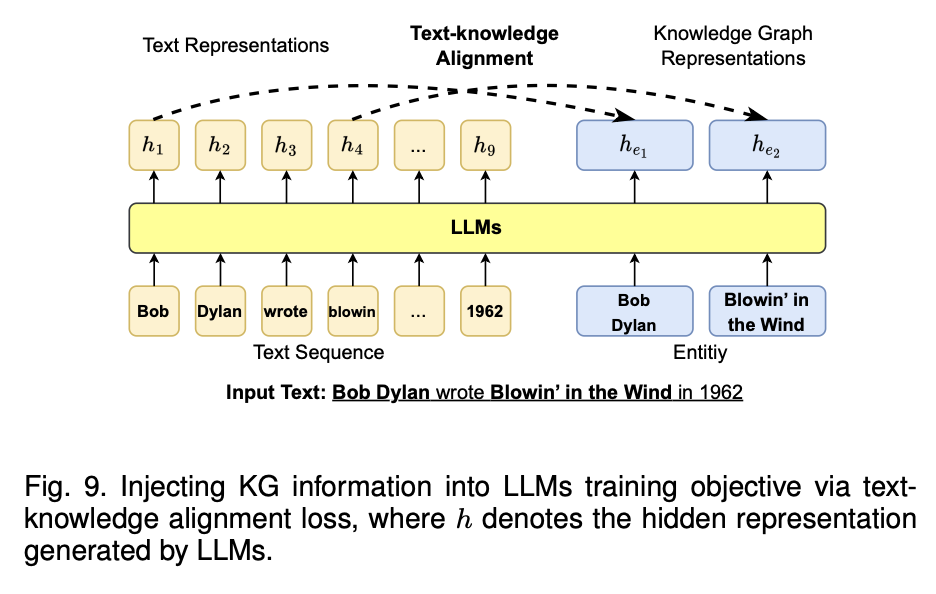
이 아키텍처의 핵심은 LLM이 텍스트를 처리하는 동안, KG 엔티티와의 정렬을 동시에 학습 즉, 텍스트-지식 정렬 손실(text-knowledge alignment loss)을 통해 LLM에 KG 정보를 주입하는 방식텍스트 표현:
입력 텍스트("Bob Dylan wrote Blowin' in the Wind in 1962")가 LLM에 입력되면, 각 단어가 히든 레이어(hidden layers)로 변환됨 각 단어에 대한 히든 레이어는 ℎ1,ℎ2,ℎ3,...,ℎ9와 같이 표현
지식 그래프 표현:
입력된 텍스트와 관련된 지식 그래프의 엔티티들(예: "Bob Dylan", "Blowin' in the Wind")이 따로 엔티티 임베딩(ℎ𝑒1,ℎ𝑒2) 으로 변환
정렬 과정:
텍스트의 히든 표현과 KG 엔티티 임베딩 사이의 정렬 손실을 최소화하는 방식으로 학습이 진행
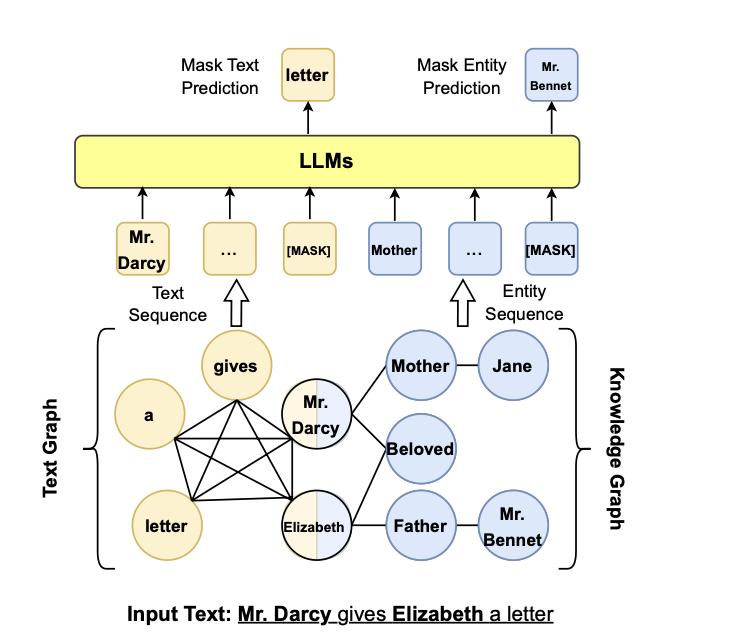
텍스트 마스킹과 엔티티 마스킹을 활용하여 LLM에 KG를 통합하는 방식 이를 통해, 텍스트와 지식 그래프 사이의 상호작용을 강화
텍스트 시퀀스 마스킹:
입력 텍스트("Mr. Darcy gives Elizabeth a letter")의 일부 단어를 마스킹하고, LLM이 이를 예측하도록 학습 이 경우, "letter"라는 단어가 마스킹된 상태에서, LLM은 문맥을 통해 이 단어를 예측
엔티티 시퀀스 마스킹:
동일하게 KG의 엔티티("Mr. Bennet")를 마스킹하여, LLM이 엔티티 정보를 예측, 이는 LLM이 KG의 구조적 관계를 통해 특정 엔티티를 예측할 수 있게 도와줌
텍스트와 엔티티 간의 연결:
이 아키텍처에서는 텍스트 그래프와 지식 그래프가 서로 연결되며, 텍스트와 엔티티 간의 관계를 LLM이 학습할 수 있게 도와줌 예를 들어, "Mr. Darcy", "Elizabeth", "letter" 간의 텍스트 관계가 KG의 엔티티 정보와 연결되어 더 정교한 추론이 가능
-
KG 강화 LLM 추론에는 KG를 추론 단계에서 활용하여 LLM이 재학습 없이 최신 지식에 접근할 수 있도록 하는 연구가 포함

위 아키텍처에서는 지식 검색기(Knowledge Retriever)가 핵심역할을 수행함1.질문 입력
Q: Which country is Obama from?
2.지식 검색기(Knowledge Retriever)
질문이 입력되면 지식 검색기는 지식 그래프(KG)에서 관련된 사실을 검색, 지식 그래프는 여러 엔티티와 그들 간의 관계를 표현한 구조적 데이터베이스로, 오바마와 관련된 지식을 포함
(Obama, BornIn, Honolulu)
(Honolulu, LocatedIn, USA)
3.검색된 사실(Retrieved Facts)
지식 검색기를 통해 검색된 결과는 Retrieved Facts로 불림
위 예시에서는 오바마가 호놀룰루에서 태어났고, 호놀룰루는 미국에 위치한다는 두 가지 사실을 검색해냄, 이 정보를 LLM에 전달하여, LLM이 올바른 답을 도출할 수 있도록 도움
4.LLM(대형 언어 모델)
LLM은 검색된 사실들을 바탕으로 질문에 대한 답변을 생성
이때, KG에서 제공한 정보를 통해 LLM은 더 정확한 답변을 도출
예를 들어, 오바마가 호놀룰루에서 태어났다는 사실과, 호놀룰루가 미국에 있다는 정보를 바탕으로, 답변: USA를 도출
5.역전파(Backpropagation)
검색된 지식이 LLM의 학습 과정에 반영, 이 과정은 LLM이 더 나은 추론을 할 수 있도록, 새로운 지식을 학습하는 데 사용함
하지만 이 아키텍처의 중요한 특징은, LLM이 재학습을 하지 않고도 최신 지식을 활용할 수 있다는 점에 따라서 매번 새로운 사실을 학습하는 것이 아니라, 지식 검색기를 통해 필요한 시점에만 관련 정보를 활용할 수 있다는 게 정말 큰 장점임 -
KG 강화 LLM 해석 가능성에는 LLM이 학습한 지식을 이해하고 LLM의 추론 과정을 해석하는 데 KG를 사용하는 연구가 포함
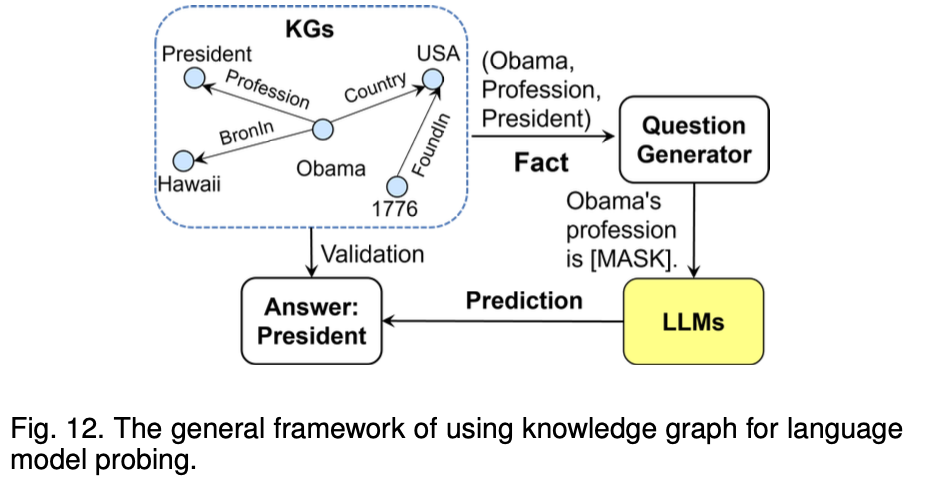
위 아키텍처의 핵심은 지식 그래프(KG)를 활용하여 LLM이 도출한 답변을 검증하고, 추론 과정을 명확하게 해석한다는 것지식 그래프(KGs)
지식 그래프는 엔티티와 관계를 저장하여 LLM이 학습한 정보를 구조화된 방식으로 제공
질문 생성기(Question Generator)
지식 그래프에서 추출된 정보를 바탕으로, LLM이 예측할 수 있는 질문이 생성
LLM에 질문 입력 및 예측
생성된 질문이 LLM에 입력되고, LLM은 [MASK]에 해당하는 정답을 예측
검증(Validation)
LLM이 예측한 답변을 지식 그래프의 실제 정보와 비교하여 정확도를 확인합
결과: 추론 과정 해석
LLM이 올바른 답변을 도출했다면, 지식 그래프의 정보를 잘 활용했음을 의미하고, 그렇지 않다면 개선이 필요함을 나타냄
LLM 증강 KG (LLM-augmented KGs)
LLM은 다양한 KG 관련 작업을 증강하는 데 적용
-
LLM 증강 KG 임베딩에는 엔티티와 관계의 텍스트 설명을 인코딩하여 KG의 표현을 풍부하게 만드는 LLM을 적용하는 연구가 포함
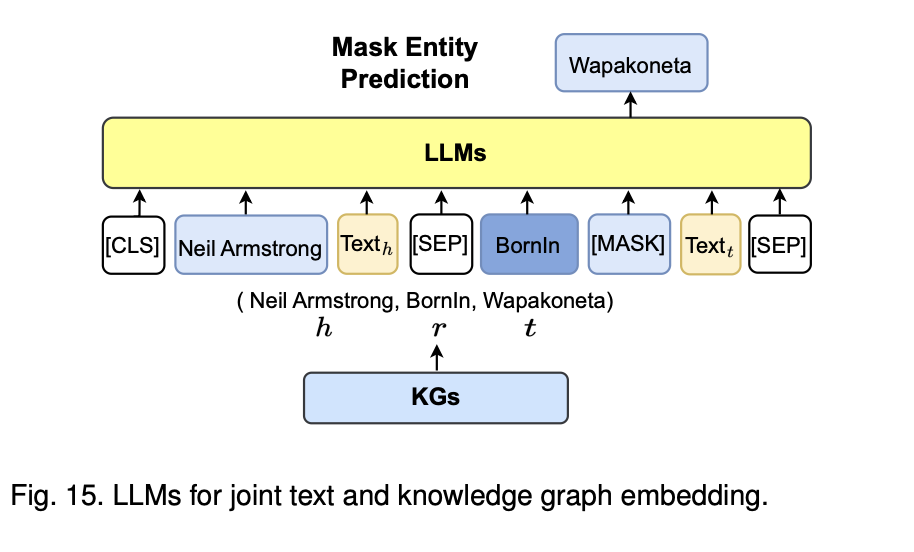
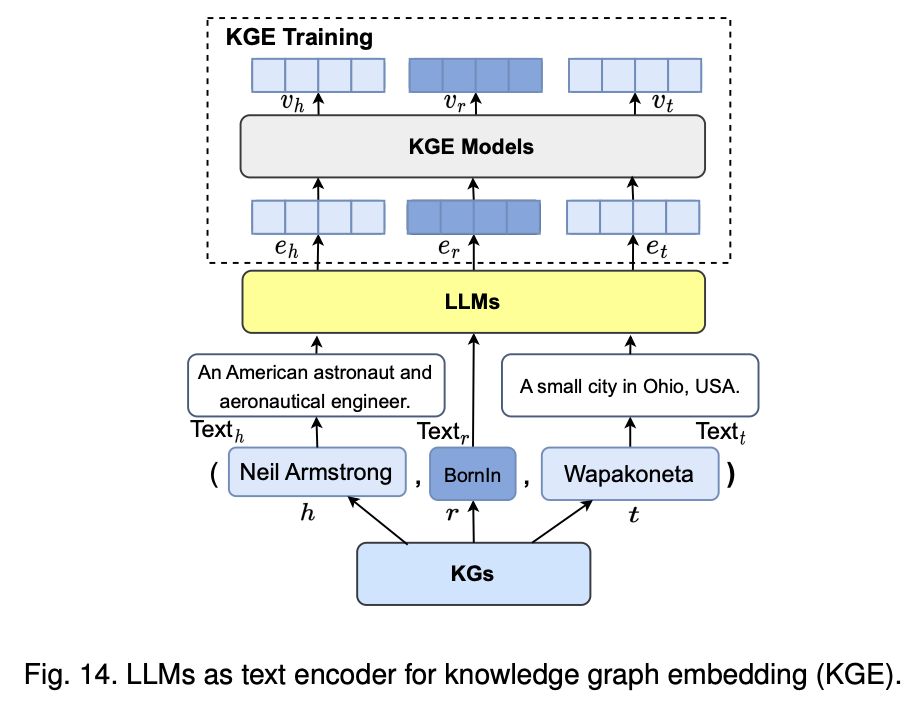
이 아키텍처의 핵심은 LLM(대형 언어 모델)을 사용하여 KG(지식 그래프)의 엔티티와 관계를 풍부하게 임베딩(embedding)하는 방식임, 텍스트와 지식 그래프의 정보를 결합하여 KG의 표현을 강화하는 데 중점1.입력 텍스트와 KG의 결합
텍스트와 엔티티의 연결: 입력 텍스트에서 추출한 엔티티와 관계를 LLM에 입력예시로, Neil Armstrong이 Wapakoneta에서 태어났다는 사실을 LLM에 제공하여 임베딩하고 있음
이때 텍스트는 [CLS], Neil Armstrong, Textₕ, BornIn, [MASK], Textₜ, [SEP]와 같은 형태로 LLM에 입력
여기서 [MASK]는 LLM이 예측해야 하는 부분으로, KG에서 제공한 정보를 바탕으로 LLM이 Wapakoneta라는 답을 예측할 수 있게 하는 것
2.지식 그래프(KG)로부터 정보 제공
KG 엔티티와 관계: KG에서는 Neil Armstrong이라는 엔티티가 BornIn 관계를 통해 Wapakoneta와 연결되어 있다는 정보를 제공하고 있음
이때, (Neil Armstrong, BornIn, Wapakoneta)라는 삼중항(triple)이 KG에서 추출되어 LLM이 이해할 수 있는 형태로 입력됨
3.LLM의 추론 및 예측
Mask Entity Prediction: LLM은 [MASK]로 표시된 부분에 대해 올바른 엔티티를 예측하는 작업을 수행하기 시작함
예를 들어, Neil Armstrong이 태어난 도시가 무엇인지 예측하는 과정에서, LLM은 Wapakoneta를 예측
4.텍스트와 KG 임베딩의 통합
이 아키텍처는 텍스트 임베딩과 KG 임베딩을 통합하여 LLM이 지식 그래프의 구조적인 정보와 텍스트 정보를 동시에 학습할 수 있도록 설계되었음 따라서, LLM은 단순한 텍스트 기반 학습에 비해 더욱 정확한 엔티티와 관계를 학습하고 예측할 수 있게 됨 -
LLM 증강 KG 완성에는 LLM을 활용하여 텍스트를 인코딩하거나 사실을 생성하여 KGC 성능을 향상시키는 논문이 포함
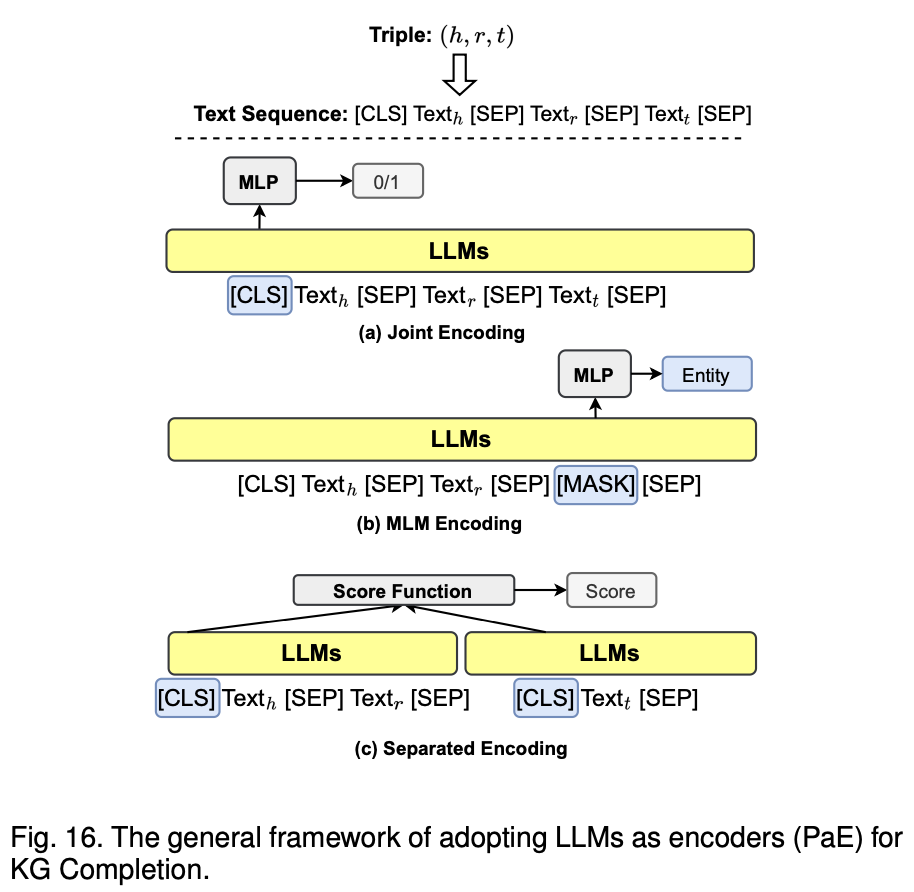
이 아키텍처의 핵심은 KG Completion을 위해 다양한 방식으로 트리플의 각 요소를 인코딩하는 방법을 설명, 트리플의 구성 요소를 어떻게 인코딩하고 예측하는지에 따라, Joint Encoding, MLM Encoding, Separated Encoding으로 나뉘며 각각의 방법이 상이한 방식으로 사실을 예측하거나 KG를 완성하는 데 기여1.Joint Encoding
설명: 트리플(Triple) (h, r, t)를 [CLS], [SEP]와 함께 텍스트 시퀀스로 변환하여 LLM에 입력
이 방법에서는 트리플의 모든 구성요소인 h (head), r (relation), t (tail)가 함께 인코딩되어, 각 구성요소 간의 관계를 한 번에 학습할 수 있음
과정: 이 인코딩된 시퀀스를 기반으로 LLM이 학습하며, MLP(다층 퍼셉트론)를 통해 0/1로 이 트리플이 유효한지 여부를 예측하게 됨
이 과정은 주로 사실(truth)을 예측하거나 검증하는 데 사용
2.MLM Encoding (Masked Language Model)
설명: 트리플 중 t(tail)를 마스킹한 후에 LLM에 입력
이는 주로 MASK된 엔티티를 예측하는 방식을 사용하며, LLM이 텍스트와 관계를 기반으로 마스킹된 엔티티를 예측할 수 있게 도움
과정: LLM은 MASK 자리에 어떤 엔티티가 들어갈지를 예측하며, 이 과정은 사실을 예측하거나 새로운 정보를 생성하는 데 적합함
3.Separated Encoding
설명: 트리플의 두 구성요소 (h, r)와 t를 각각 별도로 인코딩하여 각자의 텍스트 시퀀스로 처리함
각각의 시퀀스는 LLM을 통해 인코딩된 후, 최종적으로 두 시퀀스 간의 관계를 계산하는 방식
과정: 두 개의 인코딩된 표현을 Score Function을 통해 스코어링하여 해당 트리플이 유효한지 예측하게 됨,이 방식은 트리플의 구성 요소들을 개별적으로 처리한 후 다시 결합하여 예측을 수행함
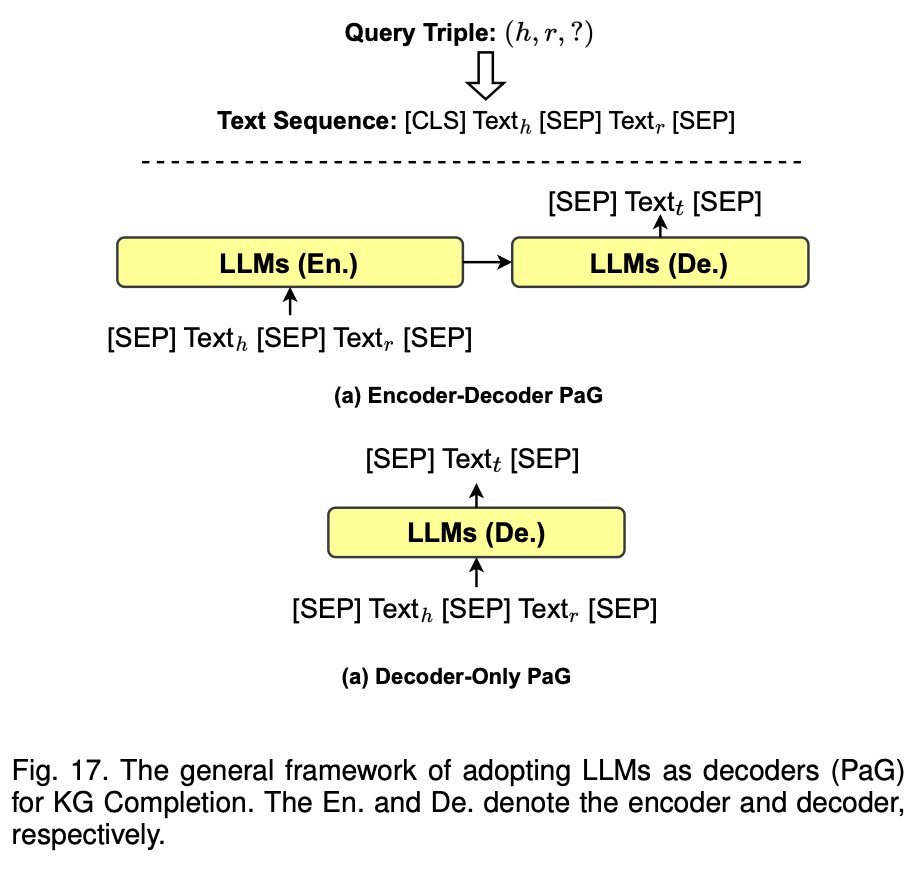
이 아키텍처의 핵심은 PaG 임, PaG (Prediction as Generation) 방식은 엔티티와 관계를 입력받아, 트리플의 tail을 직접 생성하는 방식
(a) Encoder-Decoder PaG
설명: LLM이 인코더와 디코더로 구성된 모델로서 작동하는 방식
먼저, 트리플 (h, r, ?)에서 head와 relation을 포함하는 텍스트 시퀀스 Text_h와 Text_r가 LLM 인코더에 입력
인코더는 이 정보를 처리한 후, 해당 정보를 디코더에 전달하여, tail 엔티티 t를 예측하게 됨
과정: 인코더가 입력 시퀀스를 처리한 후, 디코더는 tail 엔티티를 생성
방식은 주로 시퀀스 투 시퀀스 모델에서 사용되는 구조로, 입력된 정보로부터 직접적으로 tail 엔티티를 생성하는 방식을 취함
(b) Decoder-Only PaG
설명: 이 방식에서는 오직 디코더만을 사용하여 트리플의 tail을 예측
Text_h와 Text_r가 디코더에 입력되고, 이 정보로부터 LLM이 직접 tail 엔티티 t를 생성
과정: 디코더는 입력된 트리플 정보로부터 tail 엔티티를 생성하는데, 별도의 인코더를 거치지 않고, 한 번에 tail을 생성하는 방식
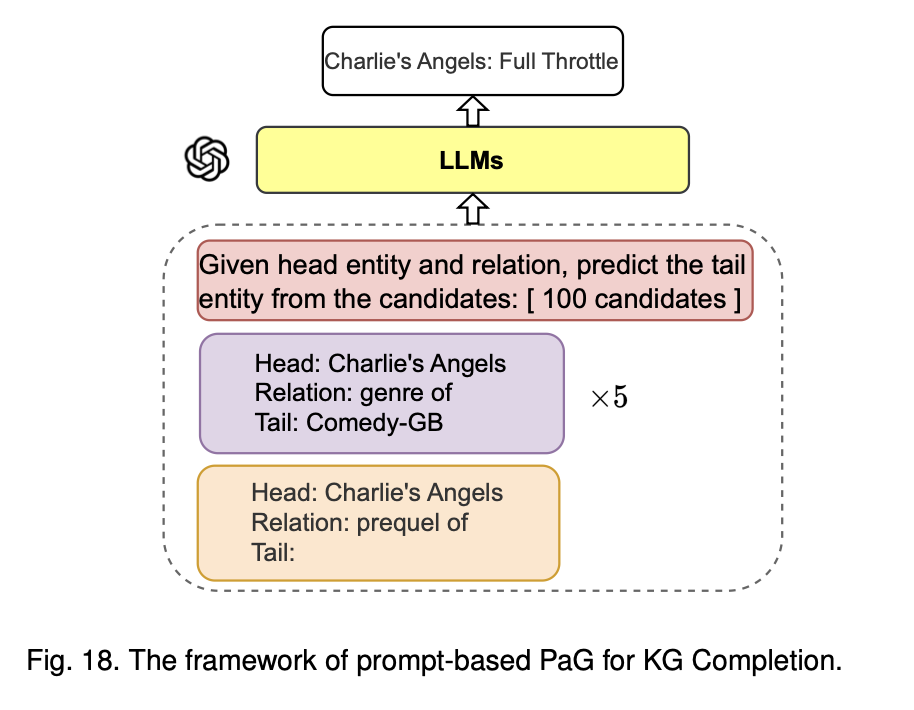
이 아키텍처는 Prompt-based PaG (Prediction as Generation) 방식으로 Knowledge Graph Completion (KGC)을 수행하는 구조임 즉, LLM에 프롬프트를 활용하여, head 엔티티와 관계가 주어졌을 때, tail 엔티티를 예측하는 방식으로 생각하면 됨
입력:
주어진 트리플 (h, r, ?)에서 head 엔티티(Charlie’s Angels)와 관계(genre of)가 주어짐, 이 정보를 프롬프트를 통해서 LLM에 입력
프롬프트:
LLM은 여러 후보 tail 엔티티들 중에서 적절한 tail을 예측해야 하기에 'Charlie’s Angels'라는 영화의 장르(genre of)를 예측하는 경우가 프롬프트로 주어지면, LLM은 이에 적합한 장르 후보들을 제공받고 이 중에서 예측을 진행함
후보 엔티티:
후보 엔티티는 100개로 제한되며, LLM은 이 후보 엔티티들 중에서 가장 적절한 tail 엔티티를 예측해야 하는 상황, 예시로는 Comedy-GB와 같은 장르가 tail 엔티티로 예측될 수 있음,
추가로 다른 관계나 엔티티를 기반으로 tail 엔티티를 예측하는 과정이 반복됨
- LLM 증강 KG 구축에는 엔티티 발견, 코리퍼런스(텍스트에서 같은 대상을 지칭하는 모든 표현을 찾아내고, 이를 올바르게 연결하는 작업) 해결, 관계 추출 작업을 처리하기 위해 LLM을 적용하는 연구가 포함
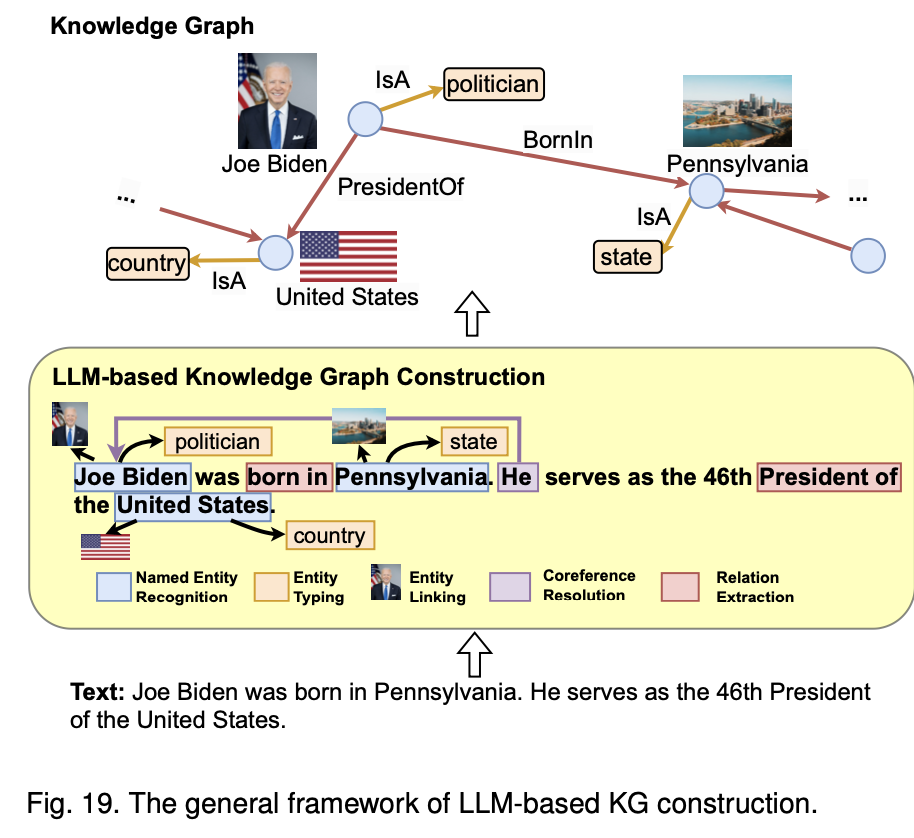
이 아키텍처는 LLM 기반 KG(Knowledge Graph, 지식 그래프) 구축을 설명하는 구조임1.지식 그래프 (Knowledge Graph):
엔티티: Joe Biden, Pennsylvania, United States와 같은 정보가 저장됨.
관계: BornIn, PresidentOf 등의 관계로 엔티티 간 지식이 구조화됨.
예시: Joe Biden은 정치인이고, 펜실베이니아에서 태어나 미국의 대통령임.
2.텍스트 기반 정보 추출:
입력 텍스트: "Joe Biden was born in Pennsylvania. He serves as the 46th President of the United States."
정보 추출 단계:
NER: Joe Biden, Pennsylvania, United States 식별.
Entity Typing: Joe Biden은 "politician", Pennsylvania는 "state", United States는 "country"로 분류.
Entity Linking: 엔티티를 적절한 지식 그래프에 연결.
Coreference Resolution: "He"가 "Joe Biden"을 지칭하는 것 인식.
Relation Extraction: BornIn, PresidentOf와 같은 관계 추출.
3.LLM 기반 지식 그래프 구축:
노드 및 엣지 구성: 추출된 엔티티와 관계를 노드와 엣지로 지식 그래프에 표현.
예시: "Joe Biden" 노드와 "Pennsylvania" 노드를 BornIn 관계로 연결, "United States" 노드와 PresidentOf 관계 형성.
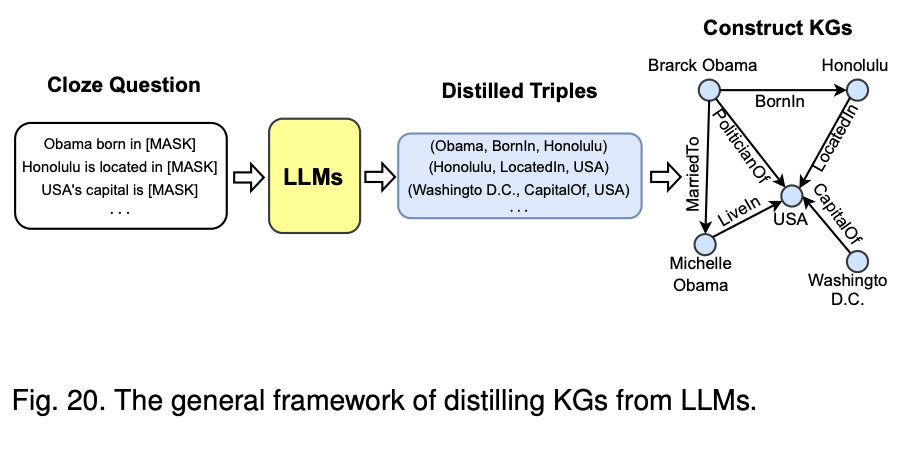
1.Cloze Question 생성:
먼저 LLM에 입력할 클로즈 질문(Cloze Question)을 생성,이는 문장 중 특정 부분이 [MASK]로 가려져 있는 형태임
예시 질문: "Obama born in [MASK]", "Honolulu is located in [MASK]", "USA's capital is [MASK]".
LLM은 이 [MASK] 부분을 예측하는 작업을 수행함
2.LLM을 이용한 예측 (Distilled Triples):
LLM은 주어진 클로즈 질문에 대해 예측을 수행하고, 결과적으로 엔티티와 관계로 구성된 삼중항(triple)을 도출함
예측된 삼중항의 예시:
(Obama, BornIn, Honolulu)
(Honolulu, LocatedIn, USA)
(Washington D.C., CapitalOf, USA)
3.지식 그래프(KG) 생성:
LLM이 도출한 삼중항을 기반으로 지식 그래프를 구성, 각 엔티티(예: Obama, Honolulu)와 그들 사이의 관계(예: BornIn, LocatedIn)가 노드와 엣지로 표현됨
예시 그래프:
Barack Obama는 Honolulu에서 태어났고(BornIn), Michelle Obama와 결혼했으며(MarriedTo), 미국에 살고(LiveIn), 미국의 수도는 Washington D.C.(CapitalOf)로 나타내는 그래프가 완성
- LLM 증강 KG-to-텍스트 생성에는 LLM을 사용하여 KG의 사실을 설명하는 자연어를 생성하는 연구가 포함
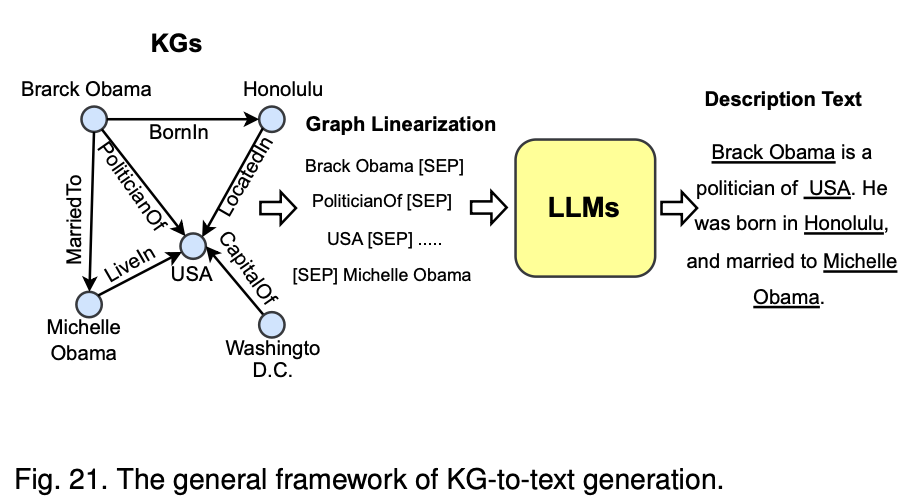
이 아키텍처는 지식 그래프에서 추출된 정보를 LLM을 통해 자연어로 변환하는 과정에 중점지식 그래프(KGs):
지식 그래프에는 엔티티(예: Barack Obama, Michelle Obama, USA, Honolulu)와 이들 사이의 관계(BornIn, MarriedTo, PoliticianOf 등)가 구조적으로 표현
그래프 선형화(Graph Linearization):
지식 그래프에서 엔티티와 관계를 선형화하여 LLM이 처리할 수 있는 텍스트 시퀀스로 변환
예시: "Barack Obama [SEP] PoliticianOf [SEP] USA [SEP] ... [SEP] Michelle Obama"
LLM을 활용한 텍스트 생성:
선형화된 그래프 정보를 LLM에 입력하여 자연어 설명을 생성
LLM은 입력된 엔티티와 관계를 기반으로 자연스러운 문장을 출력
설명 텍스트(Description Text):
LLM이 생성한 결과는 지식 그래프의 정보를 설명하는 자연어 문장으로 출력
예시: "Barack Obama is a politician of the USA. He was born in Honolulu, and married to Michelle Obama."
- LLM 증강 KG 질의응답에는 자연어 질문과 KG에서 답변을 검색하는 작업 간의 간극을 연결하기 위해 LLM을 적용하는 연구가 포함
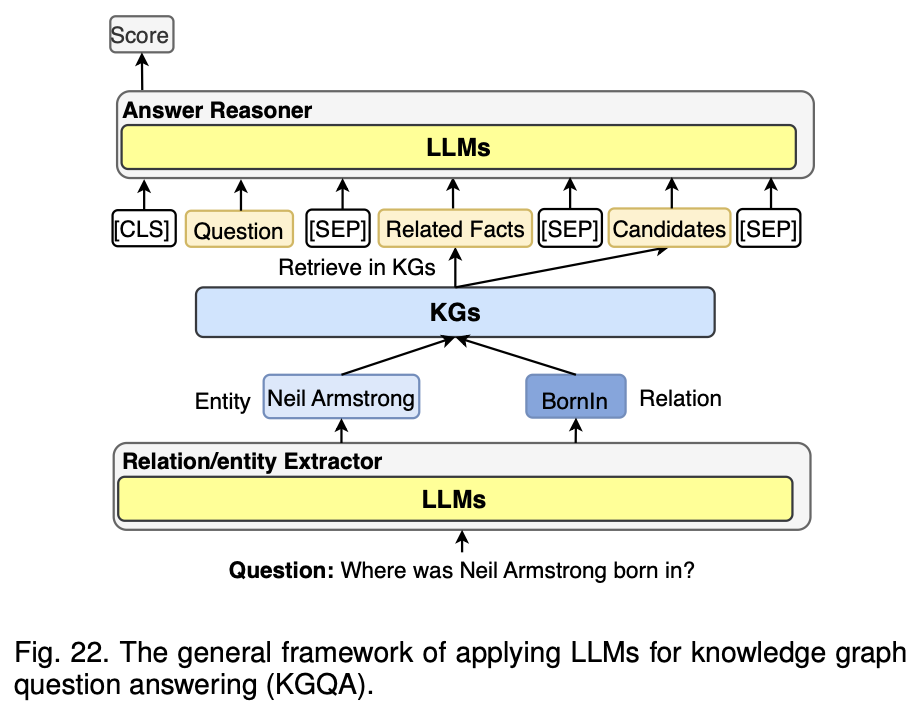
1.LLM을 통한 질문 입력:
사용자가 입력한 자연어 질문이 LLM으로 들어,예시 질문은 "Where was Neil Armstrong born?
2.관계 및 엔티티 추출:
LLM은 질문에서 핵심 엔티티(예: "Neil Armstrong")와 관계(예: "BornIn")를 추출,이 과정은 질의에 포함된 중요한 정보가 무엇인지 이해하는 단계
3.지식 그래프(KG)에서 정보 검색:
추출된 엔티티와 관계를 바탕으로, 지식 그래프(KG)에서 관련된 사실(예: "Neil Armstrong"이 "BornIn" 관계를 통해 "Wapakoneta"와 연결됨)을 검색
4.관련된 사실과 후보 정보 정리:
지식 그래프에서 검색된 사실들은 다시 LLM으로 전달됨. 이 때, 관련된 사실들과 함께 답변 후보 정보들이 정리됨
5.LLM을 통한 답변 추론:
LLM은 전달받은 관련 사실과 후보 정보들을 기반으로 질문에 대한 최적의 답변을 추론, 이 과정에서 LLM은 KG로부터 검색된 사실을 바탕으로 논리적 추론을 수행하게 된다.
6.최종 점수 평가 및 답변 제공:
추론된 답변은 LLM의 Answer Reasoner 모듈을 통해 점수화되고, 최종적으로 가장 높은 점수를 가진 답변이 사용자에게 제공됨
그래서 SYNERGIZED LLMS + KGS 는 어떻게 하는 건데?
- Synergized Knowledge Representation
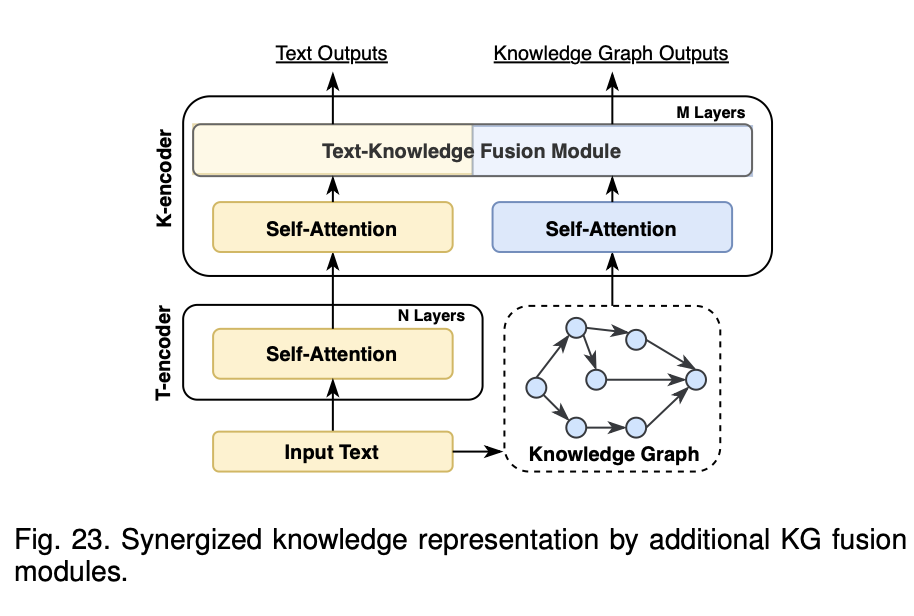
이 아키텍처는 텍스트-지식 이중 인코터 아키텍처를 가져감
입력 문장을 먼저 인코딩한후, 지식그래프 처리를해서 T-인코터 텍스트 표현과 융합하는 형식으로 감
이 아키텍처방식에서 관심이 가는 모델은 Coke-BERT모델 - Synergized Reasoning
1) LLM-KG Fusion Reasoning
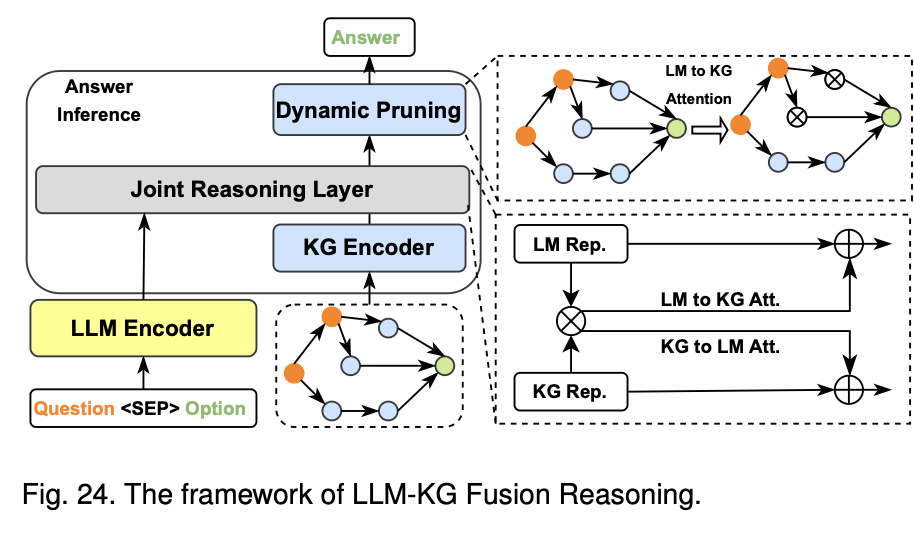
이 아키텍처는 먼저 모든 텍스트 토큰과 KG엔터티에 대해 쌍별 내적점수를 계산한후, 양방향 주위를 각각 계산 하는 형식으로 진행된다 여기서 관심이 가는 모델은 GreaseLM
2) LLMs as Agents Reasoning

