어느덧 핸즈온 머신러닝도 3장 째다. 드디어 본격적으로 머신러닝 기법에 대해서 학습한다! 먼저 분류, 즉 Classification에 대해서 다루어 보려고 한다. 지금부터는 나중에 해당 주제에 대한 내용을 한 번에 몰아볼 수 있도록 글을 나누어 작성하려고 한다. 필요한 부분만 찾아서 읽기에 이런 방법이 좋을 것 같아 택한다...
🔥3.1 MNIST
MNIST dataset은 70,000개의 이미지로 이루어진 데이터셋이다. 머신 러닝계의 "Hello world" 급의 데이터셋이라 보면 된다.
Scikit-Learn에서 MNIST dataset을 다운로드할 수 있도록 제공한다.
from sklearn.datasets import fetch_openml
#데이터 로드
mnist = fetch_openml('mnist_784', version=1)
mnist.keys()dict_keys(['data', 'target', 'frame', 'categories', 'feature_names', 'target_names', 'DESCR', 'details', 'url']) 라는 결과가 나오는 것을 확인할 수 있다.
# 데이터의 형상 출력
print(X.shape)
print(y.shape)(70000, 784) (70000,) 결과를 확인할 수 있다.
70000개의 이미지는 784개의 픽셀을 가진다. 왜냐하면 28*28 pixcel로 이루어졌기 때문이다. 각각의 feature는 하나의 픽셀의 강도를 나타내며, 강도는 0(white)에서 255(black)까지의 범위를 가진다.
matplotlib의 imshow() 함수를 이용해서 예시로 이미지를 하나 가져오겠다.
import matplotlib as mpl
import matplotlib.pyplot as plt
# 일부 숫자 이미지 가져오기
some_digit = X.iloc[0].values
some_digit_image = some_digit.reshape(28, 28)
# 이미지 출력
plt.imshow(some_digit_image, cmap=mpl.cm.binary, interpolation="nearest")
plt.axis("off")
plt.show()
print("label :",y.iloc[0]) #라벨링 된 결과 확인
그림을 보면 숫자 5처럼 보이며, 실제 라벨링도 '5'라고 되어 있는 것을 확인할 수 있다.
항상 시작하기 전에 훈련데이터과 테스트 데이터을 나누어 주어야 한다. MNIST 데이터셋은 이미 앞의 6만 개가 훈련 데이터, 뒤의 1만 개가 테스트 데이터이다. 훈련 데이터는 이미 잘 섞여 있기에 후에 교차 검증(cross-validation)이나 각 폴드(fold)의 데이터의 분포를 고르게 반영할 수 있도록 보장해준다. 간혹 특정 learning algorithms이 훈련 데이터의 순서에 민감한 경우, 성능이 떨어지게 된다.
🔥3.2 이진 분류기 훈련
상황을 조금 단순하게 만들어보자. 숫자 5가 맞는지, 맞지 않는지 판단하는 이진 분류기(binary classifier)를 만들어 볼 것이다.
y_train_5 = (y_train == 5) #True for all 5s, False for all other digits.
y_test_5 = (y_test == 5)SGD(Stochastic Gradient Descent), 확률적 경사 하강법을 이용할 것이며, Scikit-Learn의 SGDClassifier을 이용할 것이다. 확률적 경사 하강법은 빠른 데이터셋이라도 효율적으로 처리가 가능하다.
some_digit = X.iloc[0].values
from sklearn.linear_model import SGDClassifier
sgd_clf = SGDClassifier(random_state = 42)
sgd_clf.fit(X_train, y_train_5)
sgd_clf.predict([some_digit]) # 첫 번째 데이터 5인지 판별array([ True])라는 결과가 나오는 것을 확인할 수 있다.
🔥3.3 성능 평가
classifier을 평가하는 것은 regressor를 평가하는 것보다 훨씬 까다로운 경우가 많다. 이 주제에 대해 많은 얘기를 할 것이다.
3.3.1 교차 검증을 통한 정확도 측정
교차 검증은 데이터의 편중을 막기 위해 데이터를 여러 부분으로 나누어 각각의 부분을 학습 및 검증에 사용하는 방법이다.
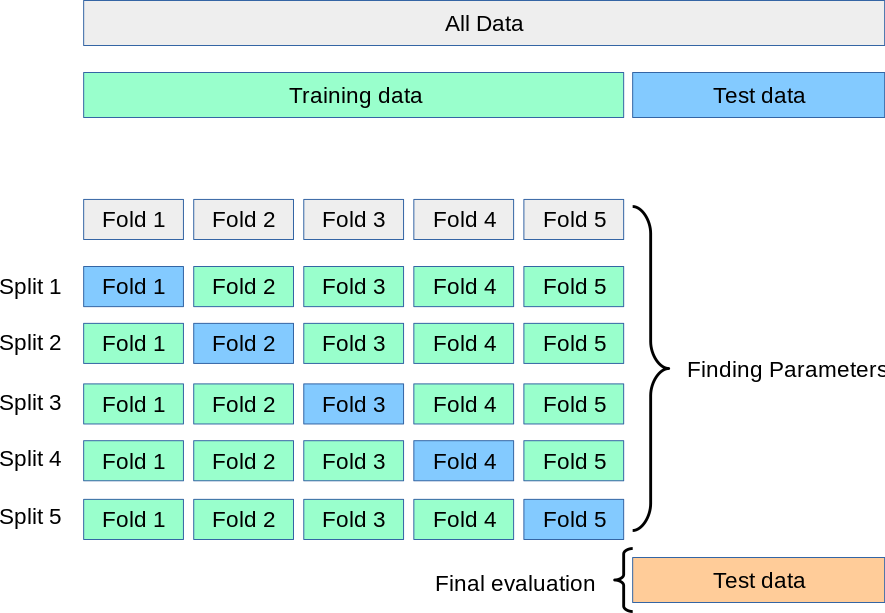
Scikit-Learn에서는 cross_val_score() 함수를 이용해서 교차 검증 기법을 활용해서 정확도를 측정할 수 있다. y가 이진 클래스 또는 다중 클래스인 경우 이 함수는 StratifiedKFold를 사용한다. 다른 모든 경우, 예를 들어 회귀 문제나 다중 출력 회귀 문제인 경우에는 KFold가 사용된다.
해당 함수의 매개변수 중 cv는 정수값을 넣을 수 있다. 기본값은 5이다.
cross_val_score : sk-learn 공식 문서
3.3.2 Confusion Matrix (혼동행렬)
3.3.3 정밀도와 재현율
3.3.4 정밀도/재현율 트레이드 오프
위의 내용은 이전 블로그 글에 잘 정리해 두었다.
3.3.5 ROC 곡선
위의 내용은 이전 블로그 글에 잘 정리해 두었다.
🔥3.4 다중 분류
2개 이상의 클래스로 분류하는 것을 다중 분류라고 한다.
Random Forest classifiers와 Bayes classifiers = multinomial classifiers의 경우, 다중 분류가 가능하다.
하지만 Support Vector Machine classifiers와 Linear classifiers는 이진 분류에만 한정된다. 하지만 여러 개의 이진 분류기를 통해 다중 분류하는 것도 가능하다.
다중 분류에는OvA(One-versus-all) 전략과 OvO(One-versus-one)이 있다.
다중 분류에 관한 내용은 이전 블로그 글에 잘 정리해 두었다.
🔥3.5 오류 분석
모델 성능을 개선하고자 할 때 흔히 사용하는 방법이 있다. 바로 error를 분석하는 것이다.
혼동 행렬(Confusion Matrix) 이용해서 분석
sk-learns에서는 cross_val_predict()을 이용해서 예측값을 구한 후, confusion_matrix() 을 이용해서 쉽게 구할 수 있다.
또한 matplotlib의 matshow()함수를 이용해서 이를 시각화 할 수 있다. 분류가 잘 되었다면 메인 대각선이 잘 보일 것이다.
TIP! 오차 행렬을 컬러 그래프로 나타내면 분석하기가 훨씬 쉽다.
이럴 땐 ConfusionMatrixDisplay.from_predictions() 함수를 이용해 주면 된다!
주의!! 오차 행렬에서 백분율 해석하는 방법
올바른 예측을 제외했다는 점을 기억해야 한다.
예를 들어 7번 행, 9번 열의 36%는 모든 7 이미지 중 36%가 9로 잘못 분류된 것이 아니라 7 이미지에서 발생한 오류 중 36%가 9라고 잘못 분류 되었다는 것이다! 참고로 오차 행렬은 대칭으로 나타나지 않는다!
🔥3.6 다중 레이블 분류
🔥3.7 다중 출력 분류
하나의 입력에 대해 여러 개의 예측값을 동시에 출력하는 분류 문제
다중 출력 다중 클래스 분류 (multioutput-multiclass classification)
다중 출력 분류 (multioutput classification)
두 용어는 같은 말이다.
다중 레이블 분류에서 한 레이블이 다중 클래스가 될 수 있도록 일반화 한 것이다. 다중 레이블 분류 + 다중 클래스 분류가 합쳐진 형태로 보면 될 것 같다. 끝판왕인 느낌?
1) 다중 레이블과의 차이점
다중 레이블 분류와는 다소 비슷하지만, 다중 출력 분류는 여러 레이블이 서로 다른 유형의 출력을 가질 수 있다.
2) 활용
다중 출력 분류는 여러 개의 종속 변수(레이블)를 예측하는 문제를 해결하는 데 사용되며, 각 레이블이 서로 독립적이지 않을 수 있다. 이러한 방식은 하나의 입력에서 여러 결과를 동시에 예측해야 할 때 유용하다.
1. 자율주행 차량의 신호등 상태 및 차선 위치 예측
- 자율 주행 차량이 주변 환경을 인식할 때, 차량 신호등 상태(3가지)와 차선 위치(차선 유지, 이탈 여부 등)도 예측해야 한다면
- 출력 1: 신호등 상태 (빨강, 노랑, 초록)
출력 2: 차선 상태 (정상 차선 유지, 차선 이탈)
2. 의료 이미지 분석
- 하나의 흉부 X-ray 이미지를 분석할 때 여러 장기나 신체 부위 상태를 각각 예측할 수 있어야 한다!
- 출력 1: 폐 상태 (정상, 폐렴, 결핵)
출력 2: 심장 상태 (정상, 비대, 기능 저하)
3. 자연어 처리(NLP)
- 출력 1: 감정 분석 (긍정, 중립, 부정)
- 출력 2: 주제 분류 (정치, 경제, 스포츠)
4. 이미지 태그 및 속성 분류
- 출력 1: 의류 종류 (셔츠, 바지, 코트)
- 출력 2: 색상 (빨강, 파랑, 녹색)
- 출력 3: 스타일 (캐주얼, 포멀)
