[Hands-On-Machine Learning]5장 서포트 벡터 머신
Hands-on-Machine Learning
_뒷부분...수식이 많아서 따로 써야 하니...앞부분에 미리 광기를 담아 써야겠다. 나중에 봐도 이해할 수 있도록 써보았다...그리고...선형대수 열심히 더 해야겠다...
선형, 비선형 분류, 회귀, 특이치 탐지에도 쓸 수 있는 SVM! 골라 드세요!
주의 : 근데 데이터 많으면 별로...
😗 근데 어느 정도여야 많다고 보는 거지?
👶 샘플이 수십만~수백만 개일 때, 차원이 수천 개 이상일 때! 인데 내가 그동안 해온 데이터들을 다 응애 수준이었구나... 컬럼 80개라 많다고 찡찡대던 거 반성하자...
수식 때문에 어질어질한 서포터 벡터 머신(support vetor machine, SVM)...너무 큰 데이터만 아니면 생각보다 다재다능하다...!
장점
- 고차원의 공간에서, 또는 차원 수가 샘플 수보다 많더라도 효과적으로 작동함
- 결정 함수에서 일부 훈련 포인트(=서포트 벡터)만 사용하기에 메모리 효율이 높다!
- 다양성이 높아 결정 함수에 대해 여러 종류의 커널 함수를 지정할 수 있다!
- 일반적인 커널도 제공하지만, 직접 커널 🖌️커스텀도 가능하다!
단점
- feature 수 >>> sample 수
- 커널 함수와 정규화 항을 잘 선택 → 과적합을 방지용
- 확률 추정치를 안 줌!😶
- 얻으려면 비용이 많이 드는 5겹 교차 검증을 사용해야 한다. (마치 깡통에서 시작하는 자동차 옵션을 보는 것만 같다...!)
본격적으로 정리 가보자고~
선형부터 가자!
5.1 선형 SVM 분류
🤓 결론 : 클래스 사이에 가장 폭이 넓은 도로를 찾는 것!
그래서 라지 마진 분류 (large margin classification)이라고 부른다.
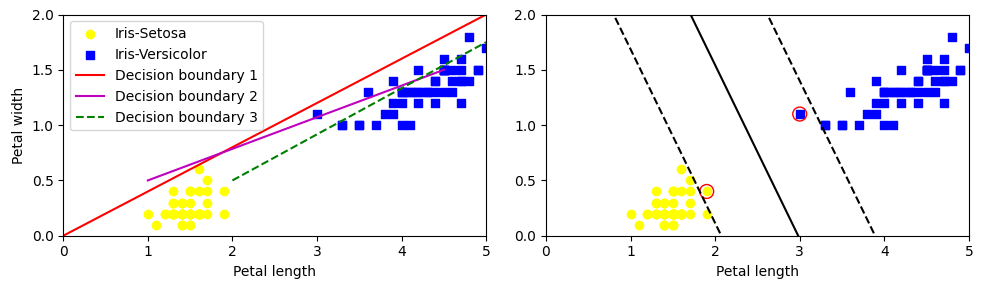
누가봐도 데이터를 잘 구분할 수 있는 선이 그려진 그림은 오른쪽 그림이다. 이게 바로 SVM이다!
실선 : SVM 분류기의 결정 경계
점선 : 점선은 각각의 결정 경계에서 가장 가까이 있는 점 주위의 선이라 보면 된다.
점선과 점선 사이의 폭이 마진으로, 앞으로 '도로'라고 표현할 것이다. SVM은 목적은 이 도로를 가장 넓게 만드는 경계를 찾는 것이다!
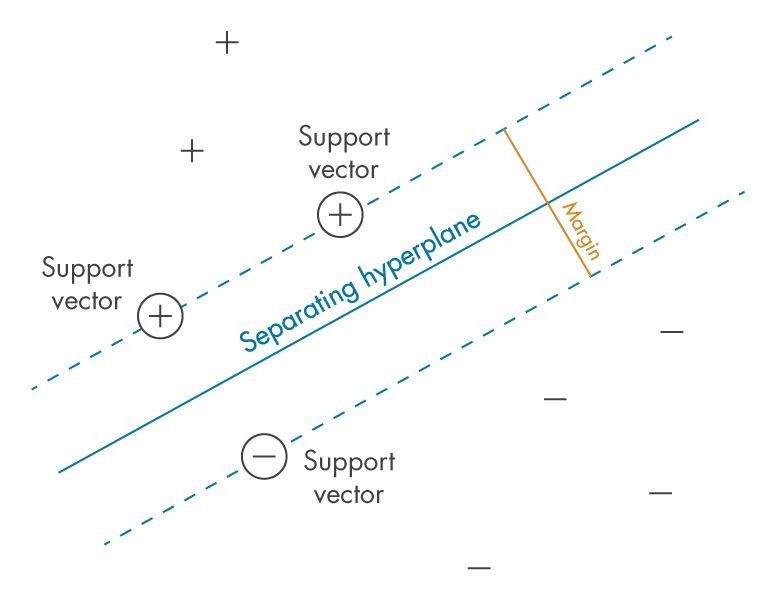
SVM은 예측 시 도로를 위주로 보게 된다. 즉, 도로 바깥쪽에 열심히 샘플을 들이부어도 도로 경계에 위치한 샘플에 의해 결정된다. 이게 위에서 말한 일부 훈련 포인트로 이런 샘플을 서포트 백터(support vector)라고 한다. (훈련 포인트의 점들은 빨간 동그라미가 쳐진 것이다!)
StandardSclaer
SVM은 특성의 스케일에 민감하다. 더 넓은 도로를 만들기 위해 스케일을 조정한다고 보면 된다.
1) 소프트 마진 분류 vs 하드 마진 분류
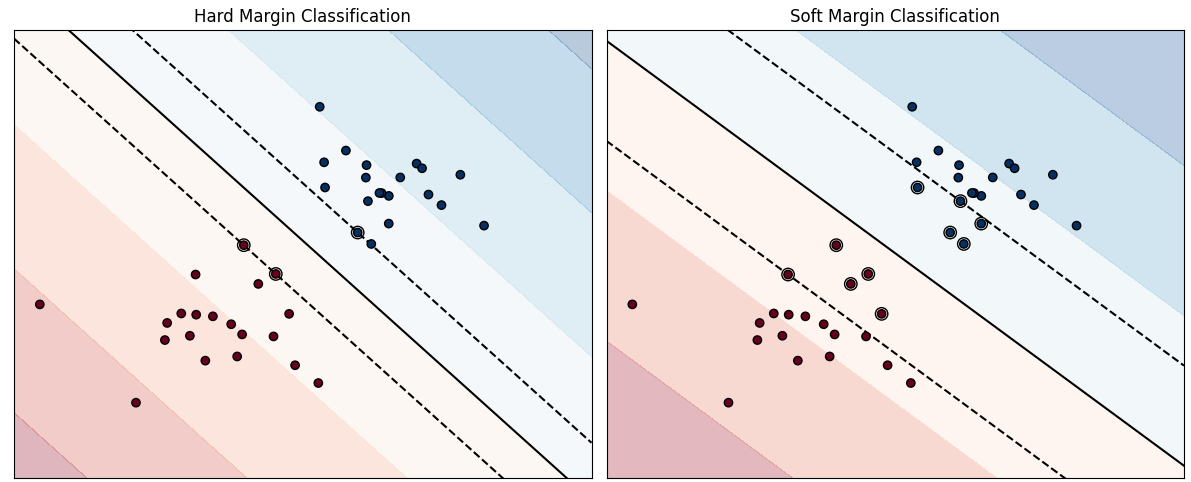
소프트와 하드의 차이점은 도로 폭을 볼 때 깐깐한 정도에 따라 구분할 수 있다!
🤔Hard : 모든 샘플이 도로 바깥쪽에 있어야 함! → 깐깐
😉Soft : Hard 보다는 좀 더 덜 깐깐하게! 적당히 균형을 잡은 것!
하드 마진 분류는 😗깐깐하기에 크게 두 문제점을 갖는다
1. 데이터는 선형적인 것으로 부탁해요~ 🙏
2. 이상치는 좀...^^ 🙏
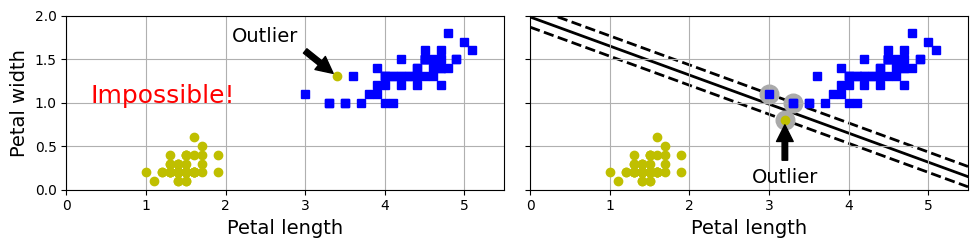
코드 참고
이상치가 들어가면 최악의 경우
✅ 하드 마진 자체를 찾을 수 없거나! (왼쪽)
✅ 모델의 일반화가 잘 안 되게 된다! (오른쪽)
이럴거면 하드 마진 고르지도 않았지!!
이런 문제를 피하려면 좀 더 유연한 모델인 soft 버전을 쓰면 된다.
결국
✅ 마진 오류 (margin violation) : 샘플이 도로 중간이나 반대쪽에 위치
✅ 도로의 폭을 넓게 유지하는 것
이 두 가지 사이에 적절한 균형을 잡아야 하며,
이를 소프트 마진 분류 (soft margin classification) 이라고 한다.
2) 규제 하이퍼 파라미터 C
뭐든 과하면 안 되니, 규제 역할도 필요하다! 이 역할은 c가 한다
| C : 커질게~ ⬆️ | 구분 | C : 작아질게~⬇️ |
|---|---|---|
| 가자~ 확장 공사! | 도로 폭 | 자리없다~ 줄이자 |
| 그렇게 늘리니까 마진 오류가 많지! | 마진 오류 | 그렇게 줄이니까 마진 오류가 없네?! |
| 과대적합 주의! | ⚠️주의⚠️ | 과소적합 주의! |
직접 C=1인 선형 SVM 모델을 만들어 보겠다
사이킷런의LinearSVC를 사용할 것이다.
Iris-Virginia 품종을 감지하기 위한 모델이다.
from sklearn.datasets import load_iris
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import LinearSVC
iris = load_iris(as_frame=True)
X = iris.data[["petal length (cm)", "petal width (cm)"]].values
y = (iris.target == 2) # Irirs-Virginica
svm_clf = make_pipeline(StandardScaler(),
LinearSVC(C=1, random_state =42)) #
svm_clf.fit(X, y)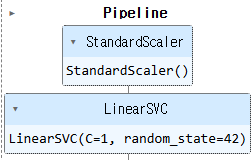
있어 보이도록 모델 구성을 잘 알 수 있게 해주는 파이프라인도 그렸다
X_new = [[5.5, 1.7], [5.0, 1.5]]
svm_clf.predict(X_new)
>>> array([ True, False])첫 꽃은 Iris-Virginica로 분류되었지만, 두 번째 꽃은 아니다.
3) 성적표 공개가 깐깐한 SVM
👨🏫 성적을 공개하기 위해
각 샘플과 결정 경계 사이의 거리(양수 또는 음수)를 측정할게요~
svm_clf.decision_function(X_new)
>>> array([ 0.66163411, -0.22036063]) # 거리 측정 완료~
이게 점...수?
로지스틱 회귀와 달리 LinearSVC에는 클래스 확률을 추정하는 predict_proba()메서드가 없다!
class sklearn.svm.LinearSVC(penalty='l2',
loss='squared_hinge', *, dual='auto', tol=0.0001, C=1.0,
multi_class='ovr', fit_intercept=True, intercept_scaling=1,
class_weight=None, verbose=0, random_state=None,
max_iter=1000)진짜 없다! (공식문서 레츠고~)
여기서 눈에 띄는 C를 잠깐 보자
C : float, default=1.0
Regularization parameter. The strength of the regularization is inversely proportional to C. Must be strictly positive. For an intuitive visualization of the effects of scaling the regularization parameter C, see Scaling the regularization parameter for SVCs.
👶 점수를 안 줄 수가 있네 신기...
👨🏫 방법이 없진 않아요~(sklearn User Guide_SVM)
step 1 ) SVC 클래스에서 probability = True 설정
step 2 ) 훈련 종료 전까지 SVM 결정 함수 점수를 추정 확률에 매핑하기 위해 추가적인 모델 훈련
step 2 모델 훈련 과정)
- 5-fold 교차 검증을 사용하여 훈련 세트의 모든 샘플에 대해 표본 외 예측 생성
- 로지스틱 회귀 모델 훈련
→ 정말 정말 오래 걸린다
step 3) 드디어 predict_proba() 및 predict_long_proba() 메서드 사용 가능...!
👶 이런 도른 놈들...!! (마치 사과에서 과거 예약 메시지 걸려고 날뛰던 나같다)
세상은 호락호락하지 않다! 많은 데이터는 비선형이지...!
5.2 비선형 SVM 분류
⭐이전 공략법⭐
→ 다항 특성을 이용!
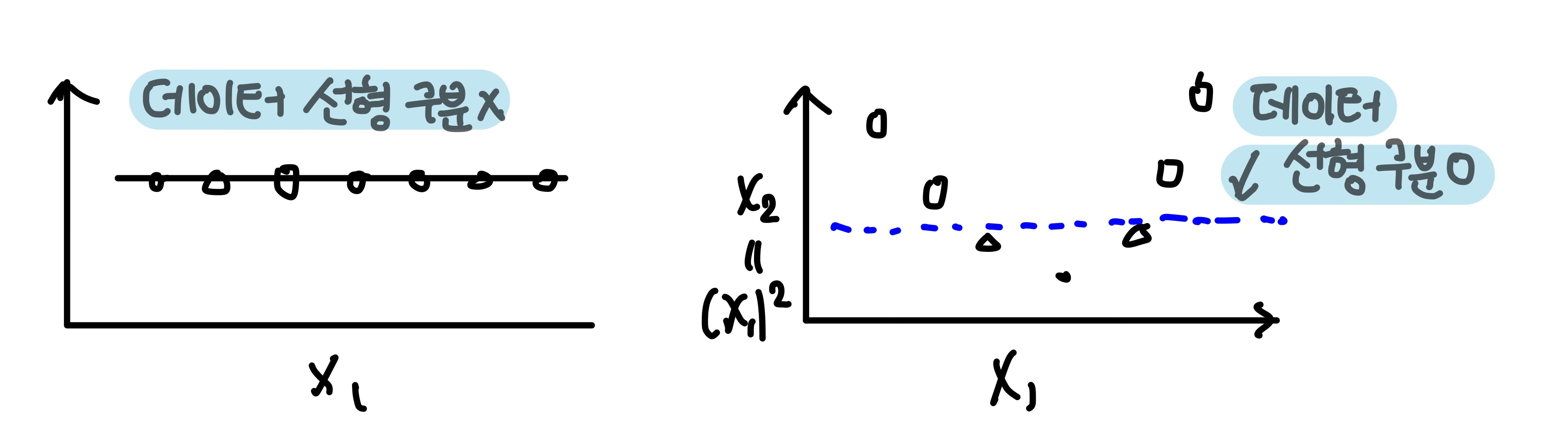
하나의 특성 만 가지고 있다면 선형으로 구분할 수 없지만,
만약 두 번째 특성 을 추가한다면 2차원 데이터 셋을 선형적으로 구분할 수 있다!
🌜make_moons()🌛 이용해보기
make_moons : 두 개의 마주보는 반원을 만드는 함수, 비선형적인 분류, 군집이나 분류 알고리즘의 성능 시각화 및 실험에 유리하다.
- 원문 설명을 보면
interleaving한 반원을 만든다고 설명하는데, 즉 서로 겹치며 얽혀 있는 형태를 만든다는 것이다.
sklearn.datasets.make_moons(n_samples=100, *, shuffle=True,
noise=None, random_state=None)[source]noise : 데이터에 추가되는 가우시안 노이즈의 강도(표준 편차), float값
→ 표준 편차가 클수록 데이터에 더 많이 날뛴다 생각하면 됨!(변동 많음)
from sklearn.datasets import make_moons
from sklearn.preprocessing import PolynomialFeatures
X, y = make_moons(n_samples=200, noise=0.15, random_state=42)
polynomial_svm_clf = make_pipeline(PolynomialFeatures(degree=3), #차수 3
StandardScaler(),
# 규제 10, 최대 반복 횟수 10000
LinearSVC(C=10, max_iter=10000, random_state=42))
polynomial_svm_clf.fit(X, y)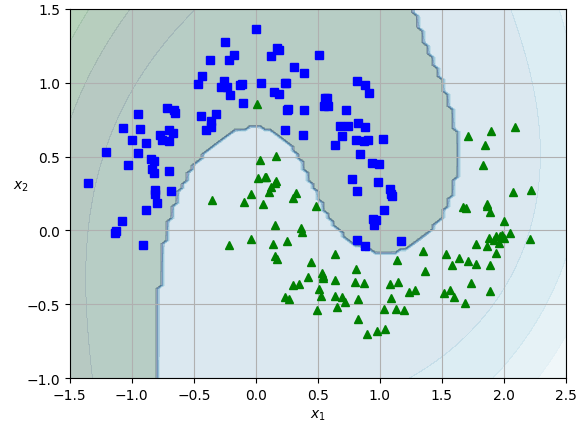
1) 다항식 커널
다항식 커널을 추가하는 것은 간단하고, 모든 머신러닝 알고리즘에서 잘 작동한다. 하지만 낮은 차수의 다항식은 복잡한 곳에는 쓰기 영 그렇고, 높은 차수는 모델을 느~리게 만든다. 🤔
그런데 SVM에서는 사기행각 수학적 방법을 이용할 수 있다.
실제 트릭을 추가하지도 않으면서 추가한 것과 같은 결과를 얻도록 해주는 것이다...!
 쩐다...!
쩐다...!
SVC에 이게 구현되어 있다. 테스트 하러 가보자고~
from sklearn.svm import SVC
poly_kernel_svm_clf = make_pipeline(StandardScaler(),
SVC(kernel="poly", degree=3, coef0=1, C=5))
poly_kernel_svm_clf.fit(X, y)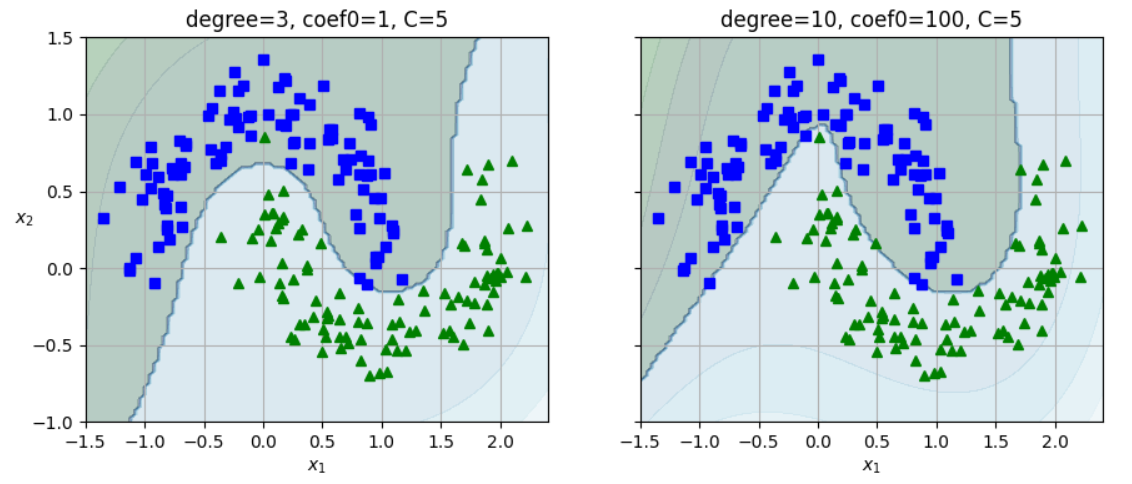
coef : 모델이 차수에 얼마나 영향을 받을지 조절, 기본값 0
SVC의 kernel 항목
kernel{‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’}
or callable, default=’rbf’✅ callable : 호출 가능한 형태로 커널 지정 (=❗커스텀 커널❗)
✅ 커널 행렬은 형태의 배열이어야 함! 각 커널 행렬의 요소는 두 샘플 간의 유사도를 나타낸다.
2) 유사도 특성
⭐이전 공략법⭐
→ 다항 특성을 이용!
→ 랜드마크 건설 이용!
유사도 함수(similarity function) : 랜드마크와 닮은 정도 측정
유사도 함수로 계산한 특성을 추가하면 비선형 데이터를 다룰 수 있다!
👶 유사도 함수는 뭘 쓸건데
📢 가우스 방사 기저 함수 (Radial Basis Function) 쓸거다!
👶 그게 무슨 역할 하는데
📢 0~1까지 변화하며 종 모양으로 변화며 🔔종 모양으로 나타난다!
0 : 랜드마크에서 아주 멀리 떨어진 경우
1 : 랜드마크와 같은 위치인 경우
= 0.3인 가우스 방사 기저 함수 적용시...
인 샘플이
랜드마크1에서는 1만큼,
랜드마크 2에서는 2만큼 떨어져 있다면...
,
아래 그림에서 오른쪽이 변환된 그림이다!
 👶 근데 랜드마크 어떻게 골라?
👶 근데 랜드마크 어떻게 골라?
📢 간단하게 데이터셋에 있는 모든 샘플 위치에 랜드마크를 설정하면 된다!
👶 ??? 그럼 훈련 세트에 있는 n개의 특성을 가진 m개의 샘플이 m개의 특성을 가진 m개의 샘플이 되잖아...!!
그렇다...훈련 세트가 너무 많으면 추가되는 특성이 너무 많아진다...주의!
3) 가우스 형님의 RBF 커널
어지간히 중요한 부분이다. sklearnl공식 문서에서 SVM 부분에서 가장 먼저 나오는 항목이다...!
👶 유사도 특성 방법은 훈련 셍트가 너무 큰 경우에는 🤑연산 비용🤑이 너무 많이 들어가는데... 아까 본 그 사기가 아니라 커널 트릭을 쓰면 연산 비용을 아낄 수 있지 않을까?!
실제로 해보기
gamma: 규제의 역할 담당!
😉 증가할게~ ➡️ 종 모양 그래프 좁아짐, 각 샘플의 영향 범위 ↓, 결정 경계 더 불규칙해지고 각 샘플을 따라 구불구불 휘어진다...!
➡️ 과소적합 때 사용!
😉 감소할게~ ➡️ 넓은(flex) 종 모양, 샘플이 넓은 버무이에 걸쳐 영향 주어서 결정 경계가 부드러워짐
➡️ 과대적합 때 사용!
모델의 복잡도를 조절할 땐 만 조절하기 보다는 C와 함께 조절해 주는 것이 좋음!
✅ 다른 커널들
도 존재는 하지만 잘 안 쓴다!
다만 문자열 커널(string kernel)과 같이 특정 데이터 구조에 특화되어 있으면 쓴다. 텍스트 문서나 DNA 서열 분류에 이용된다.
✔️ string subsequence kernel
✔️ Levenshtein distance
🔗 궁금하면 여기로
👶 이렇게 커널이 많은데 뭘 써야하지
1) 선형 커널 first (LinearSVC가 SVC(kernel="linear")보다 빠름!)
: 일단 훈련 세트가 아주 큰(샘플 수만 개 정도) 경우에 유리
2) 👶 훈련 세트 좀 작은데(샘플 수천 개 정도) ? ➡️ RBF 커널 시도, 정확도 👍
4) 계산 복잡도
일단 정말 여러 알고리즘이 나왔는데...헷갈리니까 정리해보자.
✅ LinearSVC 🔗sklearn 공식문서
- 선형 SVM을 위한 최적화된 알고리즘을 구현한
liblinear라이브러리 기반 - 커널 트릭 ❌
- 훈련 샘플과 특성 수에 선형적으로 늘어남, 정밀도 높이면 수행 시간 ⬆️
- 허용 오차 파라미터 ε(앱실론)로 조절!
tol: float, 기본값 0.0001, 알고리즘 종료 조건에 대한 허용 오차- 대부분의 문제는 허용 오차를 기본값으로 두면 잘 작동!
✅ SVC 🔗 sklearn 공식문서
- 커널 트릭 알고리즘을 구현한
libsvm라이브러리 기반 - 훈련 샘플이 많으면 너무 느려요... ➡️ 중소규모 비선형 훈련 세트에 최적!
- tol` : float, 기본값 0.001, 알고리즘 종료 조건에 대한 허용 오차
- ❗희소 특성(sparse feature)❗인 경우에 잘 확장!!
- 👶 희소 특성이 뭔데 : 샘플에 0이 아닌 특성이 몇 개 없는 경우
- 알고리즘 성능이 샘플이 가진 0이 아닌 특성의 평균 수에 거의 비례
✅ SGDClassifier 🔗 sklearn 공식문서
- 라지 마진 분류 수행
- 훈련을 위한 점진적 학습 가능, 메모리 거의 사용 ❌ ➡️ 대규모 데이터셋 학습 가능(외부 메모리 학습 가능)
- 확장성이 뛰어남!
| pyhton class | 시간 복잡도 | 외부 메모리 지원 | 스케일 조정 필요 | 커널 트릭 |
|---|---|---|---|---|
LinearSVC | ❌ | ⭕ | ❌ | |
SVC | ❌ | ⭕ | ⭕ | |
SGDClassifier | ⭕ | ⭕ | ❌ |
이제 회귀할 시간이다!
5.3 SVM 회귀
회귀를 위해서는 목표 수정이 필요하다
⭐ 기존 목표 : 일정한 마진 오류 안에서 두 클래스 간의 도로 폭 최대로 만들기
⬇️
⭐ 새로운 목표 : 제한된 마진 오류(도로 밖 샘플) 아네어 도로 안에 가능한 한 많은 샘플이 들어가도록 학습 (도로 폭은 ε(=마진)으로 조절!
🙃 ε을 조절해보자
ε : 감소할게~ ⬇️
→ 서포트 벡터 수 ⬆️ = 경계에서 예측에 영향 주는 정도 ⬆️
→ 모델 규제
→ 마진 안에서 훈련 샘플이 추가되어도 예측 영향 NO!
= ε에 민감하지 않다(ε-insensitive)
이름이 비슷한 데에는 이유가 있다
SVR는 SVC 회귀 ver. (훈련 세트가 커지면 훨씬 느려짐!)
LinearSVR는 LinearSVC 회귀 ver. (시간이 선형적으로 늘어남!)
5.4 SVM 이론
따로 다른 링크에서 다루었다...수식 살려줘
5.5 쌍대 문제
따로 다른 링크에서 다루었다2 수식 어려워요
