드디어! 캐글 단골 소재 앙상블에 대해 알아보는 시간이다! 바로 가보자~
✅ 앙상블(ensemble)
앙상블은 일련의 예측기, 즉 여러 예측기(모델)를 모아둔 것으로 보면 된다! 그래서 여러 모델을 이용해서 예측을 하기에 앙상블 학습(ensemble learning), 앙상블 학습 알고리즘을 앙상블 방법(ensemble method)라고 한다!
앙상블을 방법을 이용하여 괜찮은 예측기를 연결하면 더 성능 좋은 예측기를 만들 수 있다고 한다. 그 중 인기있는 앙상블 방법을 다룬다.
- 투표 기반 분류기
- 배깅과 페이스팅 앙상블
- 랜덤 포레스트
- 부스팅
- 스태킹 양상
7.1 다수결! 투표 기반 분류기
- 직접 투표(hard voting) : 예측값 바로 이용, 다수결 투표
- 간접 투표(soft voting) : 예측의 '평균' 이용
투표 기반 분류기는 여러 개의 모델을 학습시킨 후 각 분류기의 예측을 집계하는 것이다! (집단 지성을 생각하면 좋을 것 같다)
직접 분류기의 경우 각각의 분류기에게 분류값을 취합한 후, 가장 많이 분류된 것으로 예측을 낸다. 신기하게도 이렇게 하면 각각의 분류기 중 가장 뛰어난 것보다도 정확도가 높은 경우가 많다!
각각은 약할지라도 모이면 더 큰 성과를 낸다는 것이 포인트다!
약한 학습기(weak learner) → 강한 학습기(strong learner)
이런 효과가 가능한 이유 : 큰 수의 법칙(law of large numbers)
앙상블 기법은 기본적으로 여러 모델이 예측하게 되기에 여러 번 예측하는 것과 다름 없다. 그래서
- 서로 독립적일 때
- 각각의 오차에 상관관계가 없을 때
이런 경우 앙상블의 정확도가 올라가게 된다.
(각기 다른 알고리즘으로 학습시키는 것이 곧 매우 다른 종류의 오차를 만들 수 있다 .)
sklearn의 VotingClassifier
이름/예측기 쌍의 리스트만 제공하면 일반 분류기처럼 쉽게 사용 가능하다.
투표 기반 분류기의 predict() 메서드를 호출하면 직접 투표를 진행한다.
7.2 배깅과 페이스팅
다양한 분류기를 만드려면...
- 각기 다른 알고리즘 활용(투표 기반 분류기에서 다룬 내용!)
- 같은 알고리즘 + 훈련 세트의 subset 랜덤 구성
이때 훈련 세트에서 샘플링 하는 방식에 따라 배깅과 페이스팅이 나뉜다.
✅배깅 : 중복을 허용하여 샘플링
(bootstrap aggregating의 줄임말) → (bagging)
✅페이스팅 : 중복을 허용하지 않고 샘플링
pasting
통계학에서는 중복을 허용한 resampling을 bootstrapping이라고 한다고 한다
✅집계 함수
- 분류 : 통계적 최빈값(statiscal mode, 직접 투표 분류기처럼 가장 많은 예측 결과)
- 회귀 : 평균 계산
개별 예측기는 편향 큼
집계 함수 통과하면 편향 분산 모두 감소
일반적으로 앙상블 결과 : 편향 비슷, 분산 감소
⭐ 장점 : 예측기는 무려 병렬로 학습 가능!
→ 유사하게 예측도 병렬로 가능!
→ 그냥 cpu만 때려박으면 되잖아!!!
→ 그래서 인기가 많다고 한다!
sklearn의 Bagging & Pasting
BaggingClassifier- 기반이 되는 분류기가 클래스 확률 추정이 가능하면 (=
predict_proba()함수 있으면) 직접 투표 대신 간접 투표 방식 사용
- 기반이 되는 분류기가 클래스 확률 추정이 가능하면 (=
BaggingRegressor- 회귀용
OOB 평가
배깅을 이용하면 어떤 샘플은 전혀 선택되지않을 수 있음
→ 이걸 이용하여 각 예측기를 평가하여 OOB 평가의 평균을 앙상블의 평가로 활용할 수 있음!
7.3 랜덤 패치와 서브스페이스
BaggingClassifier
✅ 랜덤 패치 방식(random patches method)
훈련 특성과 샘플을 모두 샘플링하는 것
✅ 랜덤 서브스페이스 방식(random subspaces method)
훈련 샘플을 모두 사용하고 특성을 샘플링하는 것
7.4 그저 갓...치트키 랜덤 포레스트
한마디로 정리! 랜덤 포레스트는 Bagging 또는 Pasting을 적용한 Ensemble이다!
BaggingClassifier에 DecisionTreeClassifier 대신 결정 트리에 최적화되어 사용하기 편한 RandomForestRegressor를 사용하면 된다!
랜덤 포레스트 알고리즘)
- 랜덤으로 선택한 후보 중에서 최적의 특성을 찾음(무작위성 주입)
- 기본적으로 전체 특성 개수가 이면 개의 특성을 선택
- 트리 다양한게 만든다
→ 편향 손해, but 분산 ↓ :전체적으로 더 훌륭한 모델
sklearn의 RandomForestClassifier
참고 : sklearn RandomForestClassifier
class sklearn.ensemble.RandomForestClassifier(n_estimators=100, *, criterion='gini',
max_depth=None, min_samples_split=2, min_samples_leaf=1,
min_weight_fraction_leaf=0.0, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, bootstrap=True, oob_score=False, n_jobs=None,
random_state=None, verbose=0, warm_start=False, class_weight=None, ccp_alpha=0.0,
max_samples=None, monotonic_cst=None)splitter : DecisionTreeRegressor에 있던 항목이다.
best(기본값)이면 노드를 적절하게 나누고 (임곗값 활용)random이면 노드를 랜덤하게 나눈다 → 후보 특성을 사용해 랜덤 분할 후 그 중 최상의 분할 선택
7.4.1 엑스트라 트리
이렇게 극단적으로 랜덤한 트리의 랜덤 포레스트는 익스트림 랜덤 트리(extremely randomized tree) 앙상블 또는 줄여서 엑스트라 트리(extra-tree)라고 함.)
-
랜덤 포레스트이기에 편향이 늘어나는 대신 분산은 낮아짐
-
모든 노드에서 특성마다 가장 최적의 임계값 찾는 것은 트리 알고리즘에서 가장 많은 시간을 소요함.
- 그래서 랜덤 포레스트보다 엑스트라 트리의 훈련 속도가 훬씬 더 빠름.
sklearn에서ExtraTreesClassifier사용-
참고로 이 함수에서
boostrap = "False" {default}를 제외하곤RandomForestClassifier와 같음. -
참고로
ExtraTreeRegressor에서도boostrap = "False" {default}를 제외하곤RandomForestRegressor와 같은 API 제공 -
엑스트리와 일반 랜덤 포레스트 중 어떤 것이 나은지 보려면 교차 검증으로 비교하는 것이 유일함.
sklearn의 RandomForestRegressor
참고 : sklearn RandomForestRegressor
class sklearn.ensemble.RandomForestRegressor(n_estimators=100, *,
criterion='squared_error', max_depth=None, min_samples_split=2,
min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=1.0,
max_leaf_nodes=None, min_impurity_decrease=0.0, bootstrap=True,
oob_score=False, n_jobs=None, random_state=None, verbose=0,
warm_start=False, ccp_alpha=0.0, max_samples=None, monotonic_cst=None)RandomForestRegressor에는 split 항목 없음
7.4.2 특성 중요도
랜덤 포레스트 장점 → 특성의 상대적 중요도를 쉽게 측정
- sklearn에서 어떤 특성을 사용한 노드가 평균적으로 불순도를 얼마나 감소시키었는지 확인하여 특성의 중요도를 측정할 수 있다. (정확히는 가중치 평균을 보는 것이며, 각 노드의 가중치는 연관된 훈련 샘플 수와 같음)
property featureimportances
The impurity-based feature importances.
- 특성의 중요도가 높다 = 특성이 모델에서 더 중요하다
- 특성의 중요도는 해당 특성이 가져오는 기준(criterion, 보통 불순도)의 총 감소량으로 계산
- 랜덤 포레스트는 특성 선택 시 어떤 특성이 중요한지 빠르게 확인 가능해서 매우 편리함.
7.5 부스팅 (boosting)
부스팅(boosting)
원래 가설 부스팅(hypothesis boosting)이라 불렸음.
약한 학습기를 연결하여 강한 학습기를 만드는 앙상블 방법으로,
앞의 모델을 보완하면서 일련의 예측기를 학습한다.
AdaBoost (adaptive boosting, '에이다 부스트')
인기있는 부스팅 방법 중 하나이다.
이전 예측기를 보완할 때, 이전 모델이 과소적합했던 훈련 샘플의 가중치를 더 높여서 새로운 예측기를 만듦.
- 이 과정을 따라가면서 새로운 예측기는 학습하기 어려운 샘플에 점점 맞춰짐.
- 다음 업데이트 시, 다음 알고리즘이 잘못 분류된 훈련 샘플의 가중치를 상대적으로 높임 → 다음 분류기는 업데이트된 가중치를 사용해 훈련 세트에서 훈련 및 예측, 가중치 업데이트
훈련 마치면 배깅이나 페이스팅과 비슷한 방식으로 예측을 만듦
가중치가 적용된 훈련 세트의 전반적인 정확도에 따라 예측기마다 다른 가중치 적용
중요한 단점
각 예측기는 이전 예측기가 훈련되고 평가된 후에 학습될 수 있기에 훈련 병렬화 불가
→ 배깅이나 페이스팅만큼 확장성 높지 X
그레이디언트 부스팅 gradient boosting
또 다른 인기 부스팅 알고리즘
AdaBoost처럼 그레이디언트 부스팅은 앙상블에 이전까지의 오차를 보정하도록 예측기를 순차적으로 추가차를 보정하도록 예측기를 순차적으로 추가, AdaBoost와 다르게 이전 예측기가 만든 잔여 오차(residual error)에 새로운 예측기 학습
- GRBT
gradient tree boosting,gradient boosted regression- 결정트리에 기반한 예측기를 사용하는 방식이다.
- 축소(shrinkage)
learning rate가 각 트리의 기여도 조절 → 낮게 설정하면 앙상블을 훈련 세트에 학습시키기 위해 많은 트리가 필요하지만 일반적으로 예측의 성능은 좋아짐
- 확률적 그레이디언트 부스팅(stohastic gradient boosting) : 무작위성을 추가한 것 (무작위 데이터 샘플링을 통해 이루어짐)
- 유명한 XGBoost, LightGBM, CatBoost 가 이에 해당
히스토그램 기반 그레디언트 부스팅(HGB)
- HGB는 대규모 데이터셋에서 일반 GBRT보다 수백 배 빠르게 훈련 가능
- 구간 분할은 규제처럼 작동 → 정밀도 손실 유발 →
과대적합 줄이는 데 도움될 수도 있으나 과소적합 유발할 수도 있음.
7.6 스태킹 (staking)
스태킹은 stacked generalization의 줄임말이다.
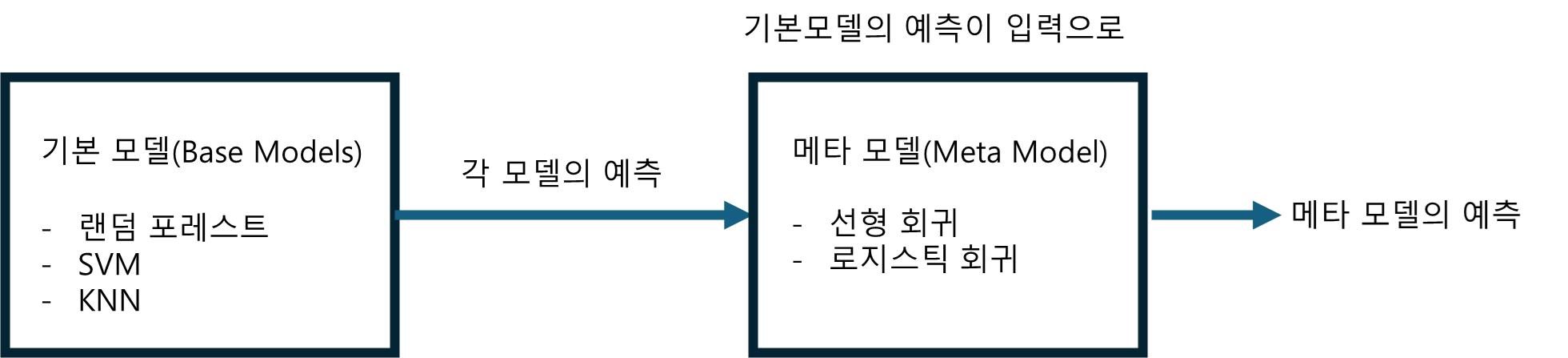
그동안 모든 예측기의 예측을 취합하는 간단한 함수를 사용해왔다. 하지만 스태킹은 이 간단한 함수를 갈아치우고, 이렇게 취합하는 것 자체를 학습시킨다! (정말 별걸 다 훈련시키려고 하네)
n개의 예측기가 각각의 예측을 내놓으면, 마지막 예측기(블렌더, blender 또는 메타 학습기 meta learner)가 각 예측들을 입력으로 받아 최종 예측을 만드는 것이다.
어떻게 갈아버리만들지?!
1. 먼저 데이터 준비부터! 데이터 분할 (Training and Validation Split)
- 훈련 데이터를 기본 모델들이 학습하고 예측하도록 분할
- 일반적으로 교차 검증(cross-validation) 방식을 사용하여 다양한 데이터 분할에서 모델 성능을 평가
2. 기본 모델 (Base Models) 훈련
- 다양한 알고리즘을 선택하여 각각의 기본 모델을 학습
- 각 기본 모델이 예측한 값을 저장
→ 이 예측값들은 나중에 메타 모델의 입력으로 사용
3. 예측 결과 저장 (Save Predictions)
- 기본 모델들이 만든 예측 결과를 훈련 데이터로부터 별도로 저장
- 일반적으로...
- 훈련 데이터의 일부 → 모델을 학습
- 나머지 데이터 → 예측에 활용(예측값 get)
4. 메타 모델 (Meta Model) 훈련
- 메타 데이터셋 생성
- 기본 모델들의 예측값을 특징(feature)으로 사용
- 메타 모델 학습
- 주로 간단한 회귀 모델 이용 (선형 회귀, 로지스틱 회귀)
- 복잡한 메타 모델을 사용할 수도 있음!(XGBoost 등)
- 기본 모델 간의 예측이 비선형적인 관계 가질 때
- 대규모 데이터셋
- 기본 모델 간의 상호작용 효과 고려해야할 때
5. 최종 예측 (Final Prediction)
- 테스트 데이터가 주어짐
- 기본 모델들 : 각각 예측을 수행 → 메타 모델에 입력할 예측값을 생성
- 메타 모델 : 이 예측값을 조합하여 최종 예측 결과를 출력
왜 간단한 모델을 메타 모델로 쓸까?
크게 세 가지 이유가 있다.
1. 과적합 방지
이미 기본 모델에서 다양한 패턴을 학습하기에 메타 모델까지 복잡해지면 과적합될 가능성이 큼.
2. 해석 용이성
선형 회귀나 로지스틱 회귀 모델은 해석이 간단하여 각 기본 모델이 메타 모델에 얼마나 기여하는지를 쉽게 알 수 있음.
3. 계산 비용 절감
간단한 모델은 훈련 속도가 빠르고, 파라미터 튜닝이 덜 필요함 → 특히 스태킹 과정에서는 이미 여러 기본 모델을 학습하기 때문에 메타 모델은 가볍고 빠르게 설정하는 것이 효율적
sklearn의 StackingClassifier
class sklearn.ensemble.StackingClassifier(estimators,
final_estimator=None, *, cv=None, stack_method='auto',
n_jobs=None, passthrough=False, verbose=0)[source]estimators : list of(str, estimator)
- 베이스 모델을 여기에 넣는다.
- 각 베이스 추정기는 리스트의 요소로 정의되며, 각 요소는 튜플 형태다.(문자열추정기 이름, 추정기 인스턴스실제 모델 객체로 이루어진다.)
- 'set_params' 메서드를 사용하여 특성 추정기를 drop가능,
- 일반적으로 베이스 추정기는 분류기(classifier)가 되며, 특성 사용 사례(순서형 회귀 등)에서는 베이스 추정기로도 활용 가능하다.
최종 예측기 기본값 : LogisticRegression 사용
stack_method : {‘auto’, ‘predict_proba’, ‘decision_function’, ‘predict’}, default=’auto’
- 사용 가능한 경우엔
predict_proba()호출 - 그 다음 순위 :
decision_function호출 - 최후의 수단 :
predict()호출
sklearn의 StackingRegressor
참고 : sklearn StackingRegressor
class sklearn.ensemble.StackingRegressor(estimators,
final_estimator=None, *, cv=None, n_jobs=None, passthrough=False,
verbose=0)StackingClassifier와 비슷한데, `stack_method='auto'는 없다.
최종 예측기 기본값 : RidgeCV 사용 (RidgeCV)
