매번 컬럼 많은 데이터만 나오는 우려먹는 얘기지만...LG Aimers 하면서 느꼈던 것... 우와 컬럼이 진짜 정말정말 많구나...!!대체 얼마나 충격을 받았었으면
하지만 이렇게 많은 특성이 있으면 훈련을 느리게 할 뿐만 아니라 좋은 솔루션을 찾기 어렵다! 그래서 이런 문제를 차원의 저주(curse of dimensionality)라고 한다.
실전에서는 특성 수를 줄여 불가능한 문제→가능한 범위로 변경 가능
ex) MNIST
이미지 경계의 픽셀은 거의 흰색이기에, 이런 인접한 픽셀을 하나의 픽셀로 합치더라도 잃는 정보가 많지 않음!
→ 이렇게 하면 학습할 정보가 타노스 되었기에 훈련 속도를 높이는 것이 가능해진다. 또한 데이터 시각화에도 유용하다고 한다.(하나의 압축된 그래프를 그려 새로운 패턴을 찾을 수도 있다는 것!)
차원 축소에 사용되는 두 가지 주요 접근 방법인
- 투영(projection)
- 매니폴드(manifold learning)
를 정리해 보겠다.
참고로 가장 인기 있는 차원 축소 기법 : PCA(주성분 분석), 랜덤 투영, 지역 선형 임베딩(locally linear embedding)
8.1 차원의 저주
- 고차원 공간에 있다
→ 데이터셋이 너무 많아서 훈련 데이터가 서로 멀리 떨어져 있게 된다.이런 경우 외삽(extrapolation)을 하게 되기에 저차원일 때보다 예측이 더 불안정해진다.
외삽(extrapolation)
주어진 데이터 범위를 넘어 새로운 값을 예측하거나 추정하는 과정을 말한다. 이를 통해 이미 알고 있는 데이터의 패턴이나 관계를 기반으로, 데이터 범위 밖의 값을 추정할 수 있다.
차원의 저주를 해결하려면 훈련 샘플의 밀도가 충분히 높아질 때 까지 훈련 세트의 크기를 키워야 하지만 실제 이런 밀도에 도달하기 까지 위한 훈련 샘플 수는 기하급수적을 커지기에 사실상 불가능하다!
8.2 차원 축소를 위한 접근법
크게 두 가지가 있다. 위에서 언급했듯이 투영과 매니폴드다.
1) 투영 (projection)
흔히 선형대수에서 배웠던 그 투영을 생각하면 된다. 3차원 공간이 있다면 특정 평면에 대해 모두 수직으로 투영하는 것을 생각해주면 된다.
실전 문제에서 훈련 샘플은 모든 차원에 걸쳐 균일하게 퍼져 있지는 않기에 대부분의 훈련 샘플이 고차원 공간 안의 저차원 subspace에 위치하게 된다. (특정 특성은 거의 변화가 없지만, 일부 특성들이 강하게 연관되어 있기에 이런 결과가 나타난다.)
차원 축소에서 언제나 투영이 최선의 방법인 것은 아니다.
스위스 롤이 바로 그 예시다.
2) 매니폴드 (manifold)
스위스 롤은 2D 매니폴드의 한 예시다. 즉 2D 매니폴드는 고차원 공간에서 휘어지거나 뒤틀린 2D 모양이라는 것이다.
일반화해서 나타내면
→ d차원의 매니폴드는 d차원 초평면(hyperplane)으로 보일 수 있는 n차원 공간의 일부이다. (d<n),
→ 스위스롤에서 d = 2, n = 3 즉 국부적으로 2D평면으로 보이지만 3차원으로 말려있다는 것이다.
많은 축소 알고리즘이 훈련 샘프링 놓여 있는 manifold를 모델링하는 식드로 작동하며 이를 매니폴드 학습 이라고 한다! 대부분 실제 고차원 데이터셋이 더 낮은 저차원 매니폴드에 가깝게 놓여 있다는 매니폴드 가정(=매니폴드 가설)에 의거한다. 즉 대부분의 실전 문제는 훈련 샘플은 모든 차원에 걸쳐 균일하게 퍼져 있지는 않기에 대부분의 훈련 샘플이 고차원 공간 안의 저차원 subspace에 위치하게 된다는 특성을 이용한 거승로 보이며, 이는 경험적으로도 잘 맞는다고 한다!
좀 더 문제를 간단하게 하고자 암묵적으로 다른 가정과 병행되기도 한다.
- 분류나 회귀가 이 저차원의 매니폴드 공간에 표현되면 더 간단해질 것
다만 당연히 항상 암묵적 가정이 성립하는 것은 아니다...! 즉 모델 훈련 전에 세트의 차원을 감소시키면 훈련 속도는 빨라지는 것은 보자오디지만, 항상 더 낫거나 간단한 solution에는 도달하지 못할 수 있다는 것이다!
스위스롤 문제를 생각하면 어떤 방향으로 단면을 잘라야 잘 구분될 수 있는지를 생각해보면 좋을 것 같다...!
8.3 주성분 분석 (PCA)
저차원으로 샘플들을 고르게 눌러서 투영해주어요~
1) 주성분 분석 과정
-
1) 분산 보존
훈련 세트를 투영하기 전에 올바른 초평면을 선택하는 것은 필수다! 결국 주성분 분석은 데이터를 잃는 과정이나 마찬가지다. -
2) 주성분
훈련 세트에서 분산이 최대인 축을 차례로 찾기
→ 번째 축 = 번째 주성분(principal component)
훈련 세트의 주성분 찾는 방법
SVD, 특잇값 분해(singular value decomposition)를 이용하여 구하며, 이때 단위 벡터 V가 모든 주성분의 단위 벡터가 된다.
numpy의 svd()
linalg.svd(a, full_matrices=True, compute_uv=True, hermitian=False)- 3) 차원으로 투영
개의 주성분 → 데이터셋을 차원으로 축소 가능
이때 초평면은 분산을 가능한 범위 내에서 최대로 보존하는 투영(project)
W2 = Vt[:2].T
X2D = X_centered @ W22) sklearn으로 PCA하기
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
X2D = pca.fit_transform(X)여기서 components_속성이
배열의 행은 처음 개의 주성분에 해당
3) 설명된 분산의 비율
explained variance ratio
각 주성분의 축을 따라 있는 데이터셋의 분산 비율을 나타냄
>>> pca.explained_variance_ratio_
array([0.7578477J 0.15186921])→ 데이터셋 분산의 76%가 첫 번째 pc에 놓여 있고, 15%가 두 번째 pc를 따라 놓임
세 번째 pc에는 9%미만이 남아있을 것으로 보임. → 아주 적은 양의 정보
4) 적절한 차원 수 선택
기준 : 충분한 분산(예 : 95%)이 될 때까지 더해야 할 차원수 선택
cumsum을 그래프로 그리면 분산을 차원 수에 대한 함수로 그릴 수 있음.
- 지도 학습의 전처리로 차원 축소 이용하는 경우
RandomizedSearchCV를 사용하여 PCA와 다른 학습 모델의 하이퍼파라미터 조합을 찾으면 됨.- 이때 학습하는 다른 모델의 성능이 좋을 경우 필요한 차원 수가 많이 줄어들게 됨!
5) 압축을 위한 PCA
- 압축된 데이터셋에 PCA 투영의 변환을 반대로 적용하면 다시 고차원으로 만들기 가능
- 단 이때 원본 데이터와 완전히 같은 것은 만들 수 없음(정보 유실)
- 원본 데이터 & 재구성된 데이터 사이의 평균 제곱 거리 → 재구성 오차(reconstruction error)
inverse_transform()method를 이용
<원본의 차원 수로 되돌리는 PCA 역변환
6) 랜덤 PCA
svd_solver = randomized : sklearn은 랜덤 PCA라 부르는 확률적 알고리즘을 사용해 처음 개의 주성분에 대한 근삿값을 빠르게 찾을 수 있음.
-
알고리즘 계산 복잡도
-
SVD :
-
svd_solver :
PCA의 매개변수 :svd_solver
PCA(n_components=None, *, copy=True, whiten=False, svd_solver='auto',
tol=0.0, iterated_power='auto', n_oversamples=10,
power_iteration_normalizer='auto', random_state=None)svd_solver{‘auto’, ‘full’, ‘covariance_eigh’, ‘arpack’, ‘randomized’}, default=’auto’
“auto”- 기본값: ‘auto’
- 입력 데이터 의 특성과 추출하려는 주성분 개수()에 따라 나뉨
covariance_eighsolver- 데이터가 특징 개수(열)가 1000개 미만이고, 샘플 수(행)가 특징 개수의 10배 이상인 경우
- 데이터의 공분산 행렬을 계산하고, 고유값 분해(eigh)를 사용해 주성분을 계산
- 작은 데이터에서 효율적
randomizedsolver- 데이터 크기 500 X 500 이상, 추출하려는 주성분 개수가 데이터의 가장 작은 차원의 80%미만인 경우
- 랜덤화된 SVD(Singular Value Decomposition) 알고리즘을 사용
- 대규모 데이터에서 빠르고 효율적
fullSVD solver- 위의 두 조건을 만족하지 않는 경우, 정확한 SVD 알고리즘이 수행
- 데이터의 모든 특성을 활용하며, 필요하면 결과를 축소
- 계산 비용이 높지만 가장 정확한 결과를 제공
7) 점진적 PCA
-
기존 PCA 구현의 문제점
→ SVD 알고리즘 실행을 위해 전체 훈련 세트를 메모리에 올려야 함.
→ 점진적 PCA(incremental PCA, IPCA) 알고리즘 개발 -
점진적 PCA(incremental PCA, IPCA)
- 훈련 세트를 미니배치로 나눔
- IPCA 알고리즘에 한 번에 하나씩 주입
- 훈련 세트가 클수록 유리하고, 온라인(실시간으로 데이터가 주입되는 환경)에서도 PCA 적용 가능
-
다만 매우 고차원 데이터셋인 경우, PCA가 너무 느려질 수 있음.
→ 수만 개 이상의 특성이 있다면 랜덤 투영을 사용하는 것을 고려해야 함IncrementalPCAIncrementalPCA(n_components=None, *, whiten=False, copy=True, batch_size=None) -
개요
- 데이터 선형 차원 축소를 위해 SVD 사용
- 가장 중요한 특이 벡터만 유지하여 데이터를 저차원 공간으로 투영
- 데이터는 중심화(mean centering)되지만, 특징 스케일링(scaling)은 적용 X
-
희소 데이터(sparse data)지원
- 희소 행렬을 처리할 수 있으며, 필요시 배치 단위로 밀집 행렬(dense matrix)로 변환
-
상수 메모리 복잡도
:- 데이터 전체를 메모리에 로드하지 않아도 되기에
np.memmap파일과 같은 메모리 매핑 기법을 사용해 큰 파일을 효율적으로 처리 가능
- 데이터 전체를 메모리에 로드하지 않아도 되기에
-
희소 행렬 처리
- 입력 희소 행렬은 배치 단위로 밀집 행렬로 변환 → 평균값을 계산하기 위해 필요
- 위의 과정은 전체 밀집 행렬을 저장하지 않고 처리
-
IPCA에서 SVD 연산복잡도
:- 이때 메모리에 저장되는 샘플은 최대 배치 사이즈의 2배(개)로 제한
-
전체 데이터셋에서 IPCA가 수행해야 하는 SVD 개수
: n_samples / batch_size -
: PCA에서 사용하는 큰 크기의 SVD 연산()과 비교하면 효율적
memmap
memmap(filename, dtype=<class 'numpy.ubyte'>, mode='r+', offset=0, shape=None, order='C')- 역할
- 디스크에 저장된 큰 이진 파일을 직접 메모리에서 다루는 것처럼 사용할 수 있도록 만들어줌
- 전체 파일을 메모리에 로드하지 않고, 필요한 부분만 메모리에 맵핑하여 작업
- RAM이 부족한 상황에서 대규모 데이터를 처리할 때 유용
8.4 랜덤 투영
랜덤 투영은 간단하고 빠르고 메모리 효율이 높음!! 특히 고차원 데이터셋엥 아주아주 유용함!! 뿐만 아니라 검색 엔진에서 유사한 문서를 그룹화하는데 사용되는 LSH(locality sensitive hashing) 알고리즘과 유사
- 선형 투영을 사용하여 데이터를 저차원 공간에 투영
→ 실제로 기존 샘플들 간의 거리를 상당히 잘 보존할 가능성이 매우 높음- William B.Johnson과 Joram Lindenstrauss가 수학적으로 증명해냄
- 더 처차원으로 갈수록 더 많은 정보가 손실되고 더 많은 거리가 왜곡
→ 최적의 차원을 고르는 방법은?>- William B.Johnson과 Joram Lindenstraussdl이 고안한 방정식 이용
→johnson_lindenstrauss_min_dim()함수에 구현되어 있음!
- William B.Johnson과 Joram Lindenstraussdl이 고안한 방정식 이용
johnson_lindenstrauss_min_dim()
만약
-
, 은 특성
-
, 은 샘플 개수
-
두 샘플 간의 제곱 거리가 를 초과하여 변경되지 않도록 하려면 제곱 거리가 ε = 10%를 변경되지 않도록 데이터를 7,300개 차원으로 투영해야 함.
이 방정식을 보면 m과 ε에 의존하며, n에는 의존하지 않는다는 것을 알 수 있음.
-
평균 : 0, 분산 : 1/d의 가우스 분포에서 랜덤 샘플링한 크기의 랜덤 행렬 를 생성하고 이를 사용하여 데이터셋을 차원에서 차원으로 투영할 수 있음.
-
→알고리즘이 랜덤한 행렬을 생성하는 데 필요한 것 : 데이터셋의 크기(데이터 자체 이용 X)
sklearn의 GaussianRndomProjection
- 위의 함수와 같은 역할을 함.
- step 1)
fit():johnson_lindenstrauss_min_dim()사용해 출력 차원 결정, 랜덤한 행렬 생성하여components_속성에 저장 - step 2)
transform(): step 1)에서 만든 행렬 사용하여 투영 수행 - 이때 ε을 조정하려면
eps를 설정하고 특정 차원 를 강제로 적용하려면n_components를 설정해야함.
sklearn의 SparseRndomProjection
-
GaussianRndomProjection와 step 1), step 2) 과정이 똑같이 작용하지만, 랜덤 행렬의 희소하다는 차이점이 존재
→ 메모리를 더 적게 활용할 수 있음.(속도도 향상 시킬 수 있음) -
입력이 희소 → 변환은 희소성을 유지(
dense_output-True로 설정 X 경우) -
GaussianRndomProjection와 동일한 거리 보존 속성을 가지며 차원 축소 품질도 비슷
→ <규모가 크거나 희박한 데이터셋>인 경우SparseRndomProjection쓰는 것이 더 바람직 -
밀도(density) : 희소한 랜덤 행렬에서 0이 아닌 항목의 비율
- 기본적으로 밀도는
-
원하는 경우
density매개변수를 이용하여 다른 값으로 설정 가능- 희소 랜덤 행렬의 각 항목이 0이 아닐 확률
- 희소 랜덤 행렬의 각 항목이 0일 확률 또는 ←둘 다 동일 확률
- 여기서
-
역변환 수행 필요
- 사이파이의
pinv()함수 이용하여 성분 행렬의 유사역행렬 계산 후, 축소된 데이터에 유사역행렬의 전치를 곱해야 함.pinv()의 계산 복잡도- 일 경우 :
- 일 경우 :
- 사이파이의
8.5 지역 선형 임베딩
locally linear embedding(LLE)
비선형 차원 축소(NLDR) 기술임.(nonlinear dimensionality reduction)
- 투영에 의존하지 않는 매니폴드 학습
- step 1) 각 훈련 샘플이 최근점 이웃에 얼마나 선형적 연관되어 있는지 측정
- step 2) 국부적인 관계가 가장 잘 보존되는 훈련 세트의 전차원 표현 찾기
- 참고로 이 방법은 noise가 너무 많지 않은 경우, 꼬인 매니폴드 펼칠 때 좋음.
sklearn의LocallyLinearEmbedding이용 가능
sklearn의 LocallyLinearEmbedding
class sklearn.manifold.LocallyLinearEmbedding(*, n_neighbors=5,
n_components=2, reg=0.001, eigen_solver='auto', tol=1e-06,
max_iter=100, method='standard', hessian_tol=0.0001, modified_tol=1e-
12, neighbors_algorithm='auto', random_state=None, n_jobs=None)변수 t : 스위스 롤의 회전 축을 따라 각 샘플의 위치를 포함하는 1D 넘파이 배열
→ 비선형 회귀 작업의 타깃으로 이용 가능
이용하게 되면 샘플 간 거리가 잘 유지되지 않고, 펼쳐진 스위스 롤은 늘어나거나 꼬인 밴드가 아니라 직사각형이 된다. 그럼에도 불구하고 LLE는 매니폴드를 모델링할 때 잘 작동함!
작동 원리
- step 1) 알고리즘이 각 훈련 샘플 에 대해 k개의 최근접 이웃 찾기
- step 2) 이웃에 대한 선형 함수로 재구성
- 와 사이의 제곱 거리가 최소가 되는 를 찾는 것
- 만약 가 의 가장 가까운 개 이웃 중 하나가 아닐 경우엔 이 됨.
LLE 단계 1: 선형적인 지역 관계 모델링
같은 제한이 있는 최적화 문제가 되어 아래와 같이 식을 작성할 수 있다.
: 가중치 를 담은 가중치 행렬
두 번째 제약 : 각 훈련 샘플 에 대한 가중치를 단순히 정규화하는 것
위의 단계를 거치면 가 모인 가중치 행렬 은 훈련 샘플 사이에 있는 지역 선형 관계를 담게 된다.
-
step 3) 가능한 한 이 지역 선형 관계가 보존되도록 훈련 샘플을 차원 공간 ( < )으로 매핑해야함.
-
만약 가 차원 공간에서 의 상(image)라면 가능한 한 와 사이의 거리가 최소화 되어야 한다.
→ 제약이 없는 최적화 문제가 된다.
LLE 단계 2: 관계를 보존하는 차원 축소
- 첫 번째 단계 : 샘플을 고정하고 최적의 가중치 찾기
- 두 번째 단계 : 가중치를 고정하고 저차원의 공간에서 샘플 이미지의 최적 위치 찾기
- 이때 는 모든 를 포함하는 행렬
sklearn의 LLE 구현
- 계산 복잡도
- 개의 최근접 이웃 찾기 :
- 가중치 최적화 :
- 저차원 표현 만들기 :
정리!
- 마지막 항의 때문에 대규모 데이터셋에 알고리즘 적용이 어려움.
- LLE는 투영 기법과는 상당히 다르며 훨씬 더 복잡하지만 데이터가 비선형인 경우 훨씬 더 나은 저차원 표현 구성 가능!
8.6 다른 차원 축소 기법
sklearn에서 제공하는 몇 가지 인기 차우너 축소 기법들
- 다차원 스케일링(multidimensional scaling, MDS)
- 샘플 간의 거리 보존하면서 차원 축소
- 랜덤 투영은 고차원 데이터에는 적합하지만 저차원 데이터에서 잘 작동 X
- 전체 곡률을 유지하면서 스위스 롤을 평평하게 만듦
- Isomap
- step 1) 각 샘플을 가장 가깡누 이웃과 연결하는 식으로 그래프 생성
- step 2) 샘플 간의 지오데식 거리(geodesic distance)를 유지하면서 차원 축소
- 그래프 두 노드 사이의 지오데식 거리 = 두 노드 사이의 최단 경로를 이루는 노드의 수
- 스위스롤의 곡률을 완전히 없앰.
- 후속 작업에 따라 거시적인 구조를 보존하는 것이 좋을 수도 있지만, 나쁠 수도 있음.
- t-SNE(t-distributed stochastic neighbor embedding)
- 비슷한 샘플 → 가까이, 안 비슷한 샘플 → 멀리 떨어지도록 차원 축소
- 주로 시각화에 많이 이용되며, 특히 고차원 공간에 있는 샘플의 군집 시각화에 이용
- t-SNE를 사용하여 MNIST 이미지의 2D 맵 그리기 가능
- 스위스 롤을 평평하게 만들고, 약간의 곡률을 보존하는 합리적인 작업 수행 → 클러스터 강조시키기 위해 롤을 분해 (후속 작업을 잘하면 좋을 수도 있음)
- 선형 판별 분석(linear discriminant analysis, LDA)
- 선형 분류 알고리즘
- 훈련 과정에서 클래스 사이를 가장 잘 구분하는 축을 학습
- 축 → 데이터가 투영되는 초평면을 정의하는 데 이용 가능
- 투영을 통해 가능한 한 클래스를 멀리 떨어지게 유지시키기에 LDA만으로 충분하지 않으면 다른 분류 알고리즘을 적용하기 전에 차원을 축소시키기에 좋음.
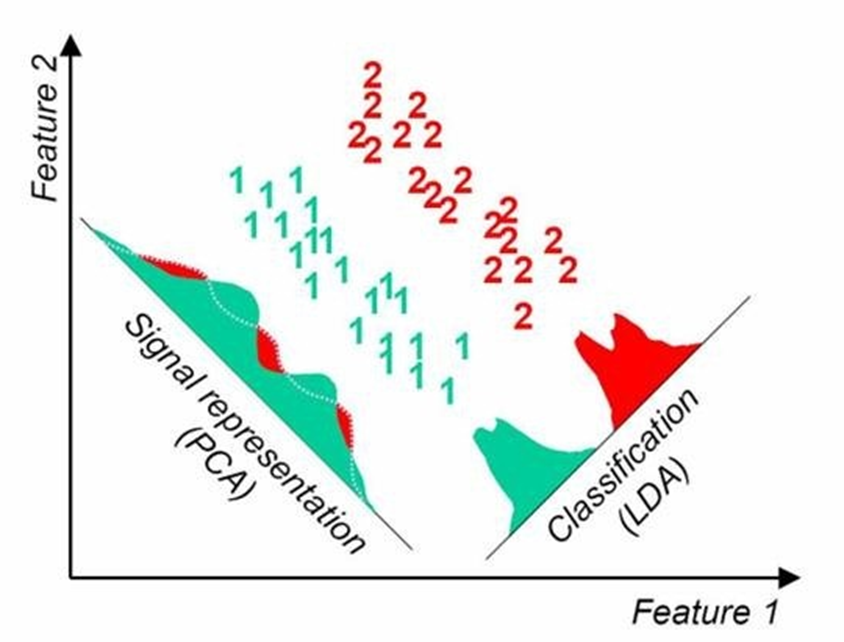
사진 출처 : 캡쳐
PCA의 성능이 이렇게 뛰어난 줄 몰랐다. 특히 선형 판별 분석...전에 열심히 했는데 잊어버리기 전에 정리해야겠다. 피셔의 선형 판별 기다려라...
