아무것도 모르는 상태에서 뭔가 하려니까 아무것도 못하겠다. 미션은 일단 멈추고 처음부터 복습해야겠다.
학습시간 09:00~02:00(당일17H/누적202H)
◆ 오늘 깨달은 것
없다.
◆ 자전거 데이터 머신러닝
전제는 아래와 같다.
나는 자전거 대여 시스템의 운영 담당자다. 내 목표는 자전거 대여 패턴을 분석하여 자전거 배치 및 운영 전략을 최적화하고, 대여 수요를 정확히 예측하는 것이다. 수치적 최종 목표는 RMSLE를 최대한 낮추는 것이다.
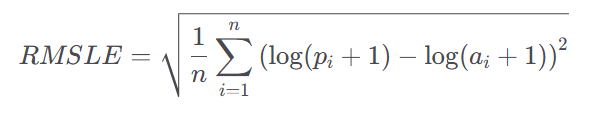
RMSLE는 Root Mean Squared Logarithmic Error의 약자로, 예측 값과 실제 값의 차이를 로그 변환하여 계산한 후, 그 차이의 제곱 평균의 제곱근을 구한 값이다. 이 지표는 예측 오차를 측정하는 데 사용되며, 특히 큰 값보다 작은 값의 오차를 더 중요시하는 경우에 유용하다. 이는 예측 값이 실제 값보다 훨씬 클 때 더 큰 패널티를 부과하므로, 예측 값이 과대평가되는 것을 방지하는 데 효과적이다.
- 특정 시간대의 자전거 대여 패턴
- 날씨와 자전거 대여 수요 간의 상관관계
- 계절별 자전거 대여 패턴의 차이
- 주말과 평일의 자전거 대여 수요 차이
- 자전거 대여 수요를 예측하기 위해 사용할 수 있는 가장 중요한 변수
- 자전거 대여 수요 예측 모델을 구축하고, 이를 기반으로 한 운영 전략을 제안
1. 데이터 전처리
 데이터 2개를 전달받았다.
데이터 2개를 전달받았다.
df_train = pd.read_csv('train.csv')
df_test = pd.read_csv('test.csv')
df_train.head()
df_test.head()
df_train.info()
df_test.info() train파일에만 casual, registered, count열이 추가로 있다. 동일한 환경에서 진행하기 위해 test 파일에도 같은 열을 추가해줘야겠다.
train파일에만 casual, registered, count열이 추가로 있다. 동일한 환경에서 진행하기 위해 test 파일에도 같은 열을 추가해줘야겠다.
 추가 완료.
추가 완료.
 dtype도 모두 동일하다. null값도 없다. 근데 두 파일 모두 날짜가 오브젝트니 datetime 타입으로 변경해야겠다.
dtype도 모두 동일하다. null값도 없다. 근데 두 파일 모두 날짜가 오브젝트니 datetime 타입으로 변경해야겠다.
df_train['datetime'] = pd.to_datetime(df_train['datetime'])
df_test['datetime'] = pd.to_datetime(df_test['datetime']) datetime64 타입으로 변경 완료!
datetime64 타입으로 변경 완료!
null값은 없었으니 바로 중복값을 확인하자.
df_train.duplicated().sum()
df_test.duplicated().sum()
중복값도 없다. 이상치를 확인하자.
df_train.describe().loc[['mean', '50%', 'max']].T
df_test.describe().loc[['mean', '50%', 'max']].T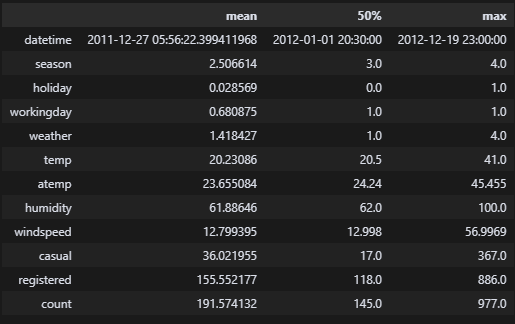 음.. 크게 눈에 띄는 부분은 없다. 근데 풍속 56은 조금 심하지 않나..? 풍속 56이면 어느 정도지..?
음.. 크게 눈에 띄는 부분은 없다. 근데 풍속 56은 조금 심하지 않나..? 풍속 56이면 어느 정도지..?
 기상청에 찾아봤다. 지붕이 날아간다고 한다. 근데 자전거를 탄다고?
기상청에 찾아봤다. 지붕이 날아간다고 한다. 근데 자전거를 탄다고?
df_train.loc[df_train['windspeed'] >= 40].sort_values(by=['windspeed','count'], ascending=False)
df_train.loc[df_train['windspeed'] >= 40].count()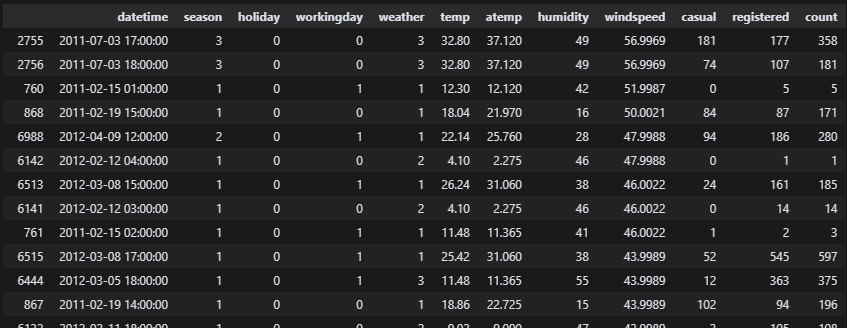
 풍속 40m/s 이상에 자전거 대여자가 40명 있다. 흠 그래도 내 눈에는 이상치로 보이기에 mode 값으로 변경한다.
풍속 40m/s 이상에 자전거 대여자가 40명 있다. 흠 그래도 내 눈에는 이상치로 보이기에 mode 값으로 변경한다.
df_train['windspeed'] = df_train['windspeed'].where(df_train['windspeed'] <= 40, df_train['windspeed'].mode()[0])
df_train.loc[df_train['windspeed'] >= 40].count() train 파일 풍속 40 이상을 mode값으로 변경했다. test는 일단 변경하지 말고 해봐야겠다.
train 파일 풍속 40 이상을 mode값으로 변경했다. test는 일단 변경하지 말고 해봐야겠다.
이렇게 전처리한 파일로 머신러닝을 할 거긴 한데, 그 전에 상관관계를 확인해야겠다.
df_train['year'] = df_train['datetime'].dt.year
df_train['month'] = df_train['datetime'].dt.month
df_train['day'] = df_train['datetime'].dt.day
df_train['hour'] = df_train['datetime'].dt.hour
df_test['year'] = df_test['datetime'].dt.year
df_test['month'] = df_test['datetime'].dt.month
df_test['day'] = df_test['datetime'].dt.day
df_test['hour'] = df_test['datetime'].dt.hour
df_train[['year', 'month', 'day', 'hour', 'count']], print(df_train.dtypes) 두 파일의 datetime을 연월일시 4개로 나눴다. 음 날짜 dtype이 int인데 그냥 이걸로 진행하면 되려나?
두 파일의 datetime을 연월일시 4개로 나눴다. 음 날짜 dtype이 int인데 그냥 이걸로 진행하면 되려나?
sns.set_theme(
rc={'figure.figsize':(15, 8)},
style='whitegrid',
font='Malgun Gothic',
font_scale=1,
palette='Set2')
sns.heatmap(
df_train.corr(numeric_only=True),
annot=True,
cmap='RdYlGn',
square=True,
linewidths=0,
fmt='.2f',
cbar_kws={'shrink': 1})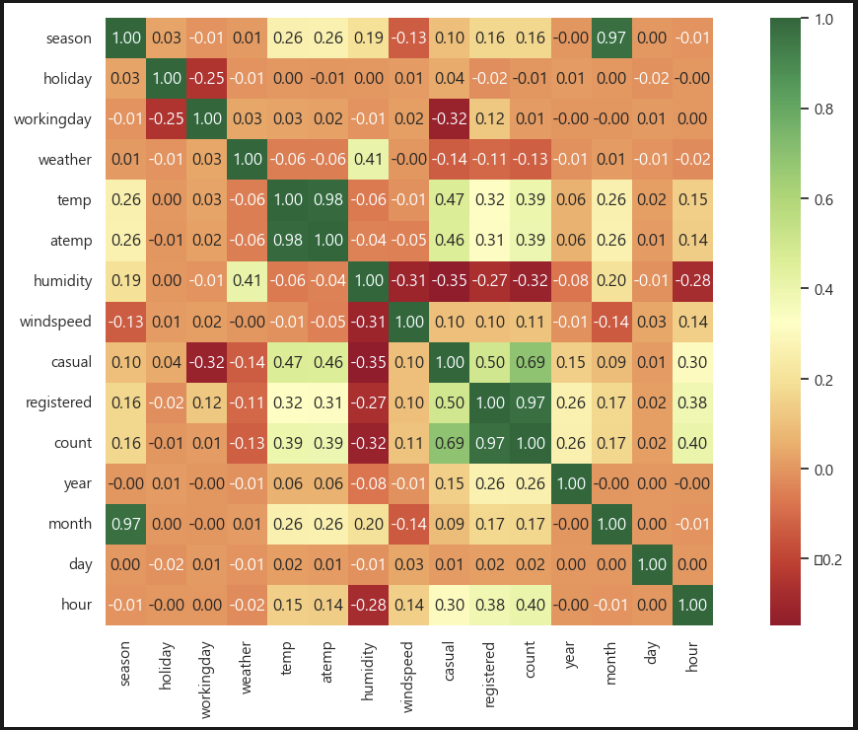 히트맵으로 보니 count와 눈에 띄게 상관관계가 있는 것이 몇 보인다.
히트맵으로 보니 count와 눈에 띄게 상관관계가 있는 것이 몇 보인다.
- 기온이 높을수록 대여가 많다.
- 습도가 높을수록 대여가 적다.
- 오후 시간대에 대여가 많다.
조금 더 자세히 보자!
2. 시각화
sns.barplot(x='hour', y='count', data=df_train, errorbar=None, color='c')
plt.title('시간대별 대여량')
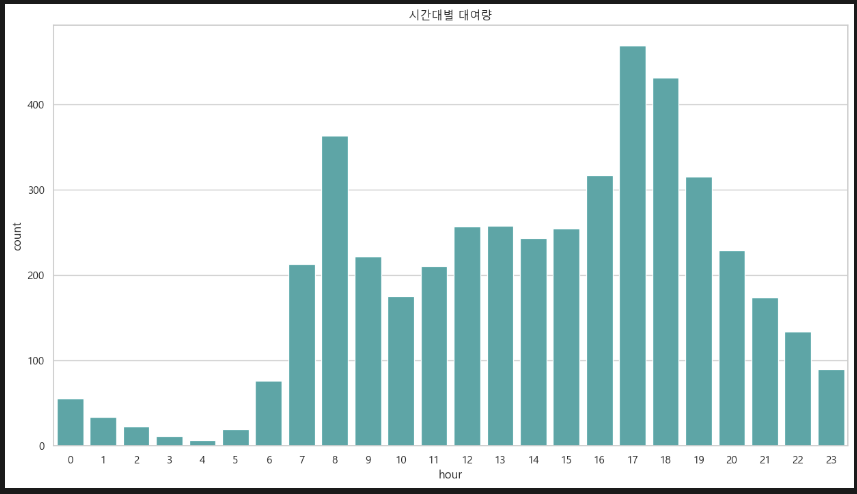 전반적으로 보면 오후가 많긴 한데, 출퇴근 시간에 많이 몰리는 것 같다. 생각해 보니 당연한 소리인 것 같다.
전반적으로 보면 오후가 많긴 한데, 출퇴근 시간에 많이 몰리는 것 같다. 생각해 보니 당연한 소리인 것 같다.
sns.barplot(x='temp', y='count', data=df_train, errorbar=None, color='c')
plt.title('온도별 대여량')
plt.xticks(rotation=45)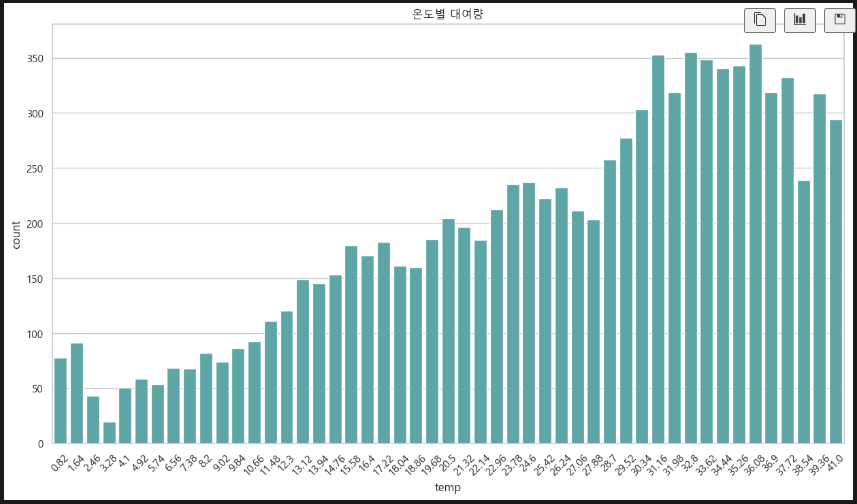 기온(섭씨)에 따른 대여량 비교. 30~37도 정도에 대여량이 많다.
기온(섭씨)에 따른 대여량 비교. 30~37도 정도에 대여량이 많다.
sns.barplot(x='humidity', y='count', data=df_train, errorbar=None, color='c')
plt.title('습도별 대여량')
plt.xticks(rotation=70)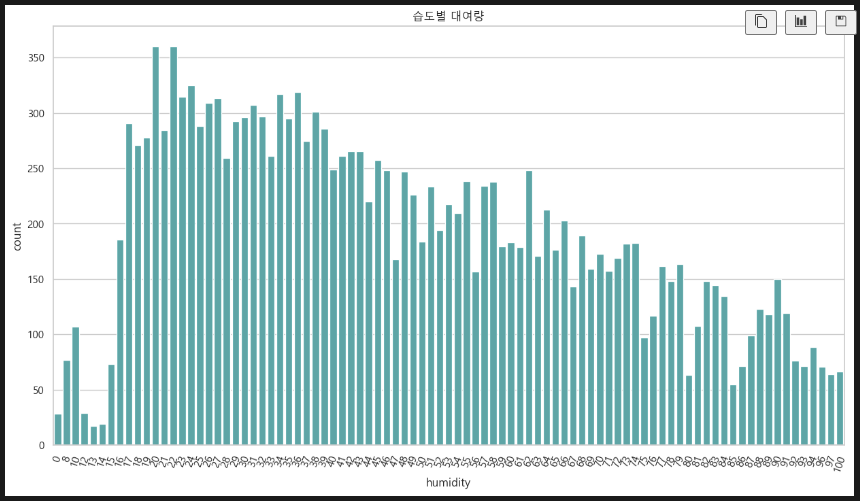 습도에 따른 대여량. 습도 20~40% 정도에 대여량이 많다.
습도에 따른 대여량. 습도 20~40% 정도에 대여량이 많다.
sns.barplot(x='season', y='count', data=df_train, errorbar=None, color='c')
plt.title('계절별 대여량')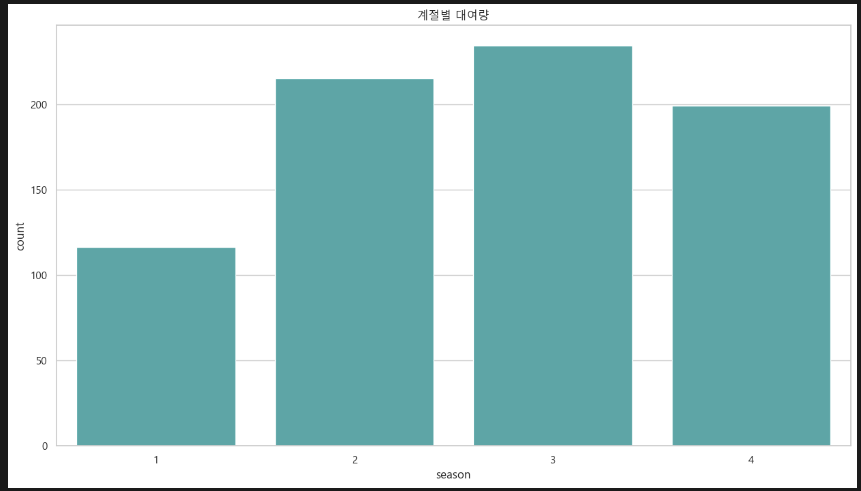 계절에 따른 대여량. 1분기(봄)엔 대여량이 적고 그 외 대여량이 약 2배 높다.
계절에 따른 대여량. 1분기(봄)엔 대여량이 적고 그 외 대여량이 약 2배 높다.
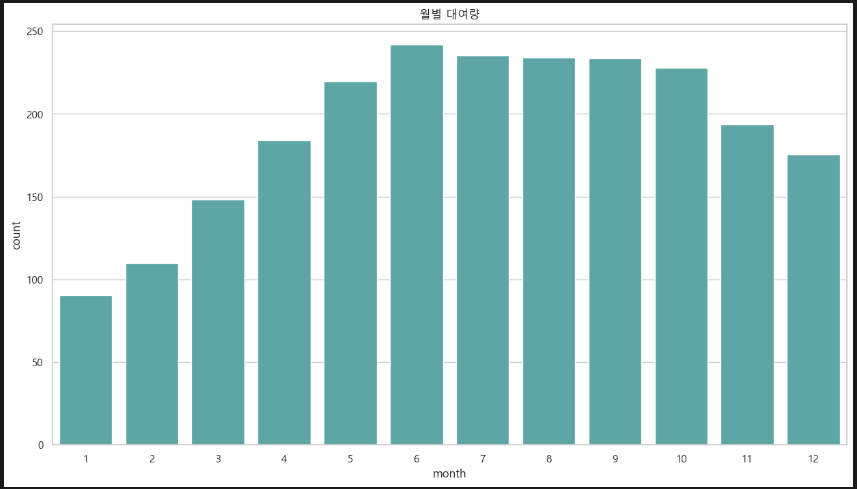 월별로 보아도 마찬가지.
월별로 보아도 마찬가지.
sns.barplot(x='workingday', y='count', data=df_train, errorbar=None, color='c')
plt.title('주말여부별 대여량')
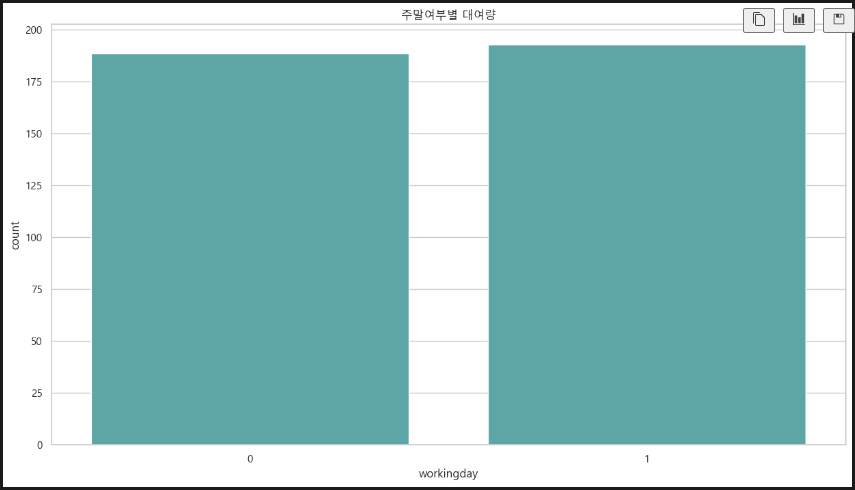 주중 주말 대여량에는 큰 차이가 없다. 신기하다. 주말이 훨씬 많을 줄 알았는데... 아마도 평일이 day off인 사람도 있어서 그런 게 아닐까 싶다.
주중 주말 대여량에는 큰 차이가 없다. 신기하다. 주말이 훨씬 많을 줄 알았는데... 아마도 평일이 day off인 사람도 있어서 그런 게 아닐까 싶다.
요약하면, 전반적으로 대여량에 큰 영향은 미치는 요인은 아래와 같다.
- 시간대: 출퇴근 시간(08시, 17시, 18시)에 대여가 많다.
- 기온(섭씨) 30~37도 정도에 대여가 많다.
- 습도 20~40% 정도에 대여가 많다.
- 1분기(봄)엔 대여량이 적고 그 외 대여량이 약 2배 높다.
3. 머신러닝
(1). 데이터 변수 선언
헉 큰일이다. 원래 하나의 파일에서 변수를 선언하고 스플릿하는데, 이번 파일은 이미 스플릿 되어 있는 상태다. 그럼 어쩌지? 피벗테이블 쪽에서 파일 두개를 합치는 어떤 기능을 배운 것 같은데,, 기억이 안 난다.
일단 나에게는 df_train과 df_test 파일이 있다. 둘다 X, y가 나누어지지 않은 상태고 X값 스케일링도 안 된 상태다. 그럼 df_train를 X_train, y_train으로 나누고 df_test를 X_test, y_test로 나누면 되겠군! 그리고나서 X 데이터만 스케일링을 해보자!
X_train = df_train.drop(['count'], axis=1)
y_train = df_train['count']
X_test = df_test.drop(['count'], axis=1)
y_test = df_test['count'] 됐다! X_train에 count열만 빠졌다!
됐다! X_train에 count열만 빠졌다!
(2). 스케일링
이제 스케일링을 해줄 차례다. 역순으로 하려니 너무 헷갈리네.
from sklearn.preprocessing import StandardScaler
X_train = StandardScaler().fit_transform(X_train)
X_test = StandardScaler().fit_transform(X_test) 에러가 났다. 아무래도 datetime열 dtype이 datetime64여서 그런 것 같다. 그럼 삭제하고 진행하는 수밖에 없나?
에러가 났다. 아무래도 datetime열 dtype이 datetime64여서 그런 것 같다. 그럼 삭제하고 진행하는 수밖에 없나?
X_train = X_train.drop(['datetime'], axis=1)
X_test = X_test.drop(['datetime'], axis=1) datetime열을 드롭하고 다시 하니 된다! 스케일링 적용 끝!
datetime열을 드롭하고 다시 하니 된다! 스케일링 적용 끝!
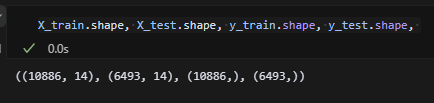 train셋과 test셋의 차원을 확인했다. 14차원이 둘 다 동일하다.
train셋과 test셋의 차원을 확인했다. 14차원이 둘 다 동일하다.
이제 본격적으로 모델을 학습시켜 보자!
(3). 모델 학습
사실 지금부턴 제대로 하고 있는 것인지 잘 모른다. 그래도 해보자...
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(degree=5, include_bias=False)
X_train_poly = poly.fit_transform(X_train)
X_test_poly = poly.transform(X_test)
feature_names = poly.get_feature_names_out()
feature_names일단 독립변수가 여러 개니 다항식이 좋지 않을까 생각해서 5차식으로 변환했다. 그리고 정답이 분류가 아니라 예측이기 때문에 로지스틱회귀 보다는 선형회귀가 좋겠다고 판단했다.
 뭐가 나왔는데 무슨 뜻인지는 모르겠다.
뭐가 나왔는데 무슨 뜻인지는 모르겠다.
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(X_train_poly, y_train) 내가 뭘해야 하는지 모르지만 일단 선형회귀 모델을 호출했다. 학습시켜야할 파일이 X_train인지 X_train_poly인지 모르겠다. 그래도 파랑색 창이 나왔으니까 잘 하고 있다는 거겠지...?
내가 뭘해야 하는지 모르지만 일단 선형회귀 모델을 호출했다. 학습시켜야할 파일이 X_train인지 X_train_poly인지 모르겠다. 그래도 파랑색 창이 나왔으니까 잘 하고 있다는 거겠지...?
lr.coef_, lr.intercept_기울기와 절편을 확인하는 코드라고 들었던 것 같다.
 뭐가 나왔는데 무슨 뜻인지는 모르겠다.
뭐가 나왔는데 무슨 뜻인지는 모르겠다.
pred_train = lr.predict(X_train_poly)
pred_test = lr.predict(X_test_poly)
print(lr.score(X_train_poly, y_train))
print(lr.score(X_test_poly, y_test))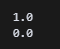 X_train_poly와 X_test_poly를 예측하는 코드를 넣었다. 스코어 함수를 사용했는데 위 처럼 나왔다. 이건 망했다는 뜻이겠지? train셋은 1.0점인데, test셋은 0.0점이다.
X_train_poly와 X_test_poly를 예측하는 코드를 넣었다. 스코어 함수를 사용했는데 위 처럼 나왔다. 이건 망했다는 뜻이겠지? train셋은 1.0점인데, test셋은 0.0점이다.
흠,, 뭔가 문제지 ㅠㅠ 혹시 test셋에 casual과 registered컬럼을 0으로 비워둬서 그런가...
 지선생에게 물어보니 이러면 과적합이 될 수도 있다고 한다. 그럼 지우고 다시 시작해보자.
지선생에게 물어보니 이러면 과적합이 될 수도 있다고 한다. 그럼 지우고 다시 시작해보자.
X_train = X_train.drop(['casual', 'registered'], axis=1)
X_test = X_test.drop(['casual', 'registered'], axis=1)casual, registered 컬럼 삭제.
pred_train = lr.predict(X_train_poly)
pred_test = lr.predict(X_test_poly)
print(lr.score(X_train_poly, y_train))
print(lr.score(X_test_poly, y_test))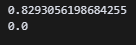 다시 해보니 train셋이 1점에서 0.83점으로 줄어들었다. 점수는 낮아졌는데 뭔가 인간미 있는 점수가 나와서 안심이 된다. test셋은 여전히 0점이다. 아예 분류를 못하고 있다는 뜻인가?
다시 해보니 train셋이 1점에서 0.83점으로 줄어들었다. 점수는 낮아졌는데 뭔가 인간미 있는 점수가 나와서 안심이 된다. test셋은 여전히 0점이다. 아예 분류를 못하고 있다는 뜻인가?
 물어보니 여전히 과적합된 상태라고 한다. 릿지 규제를 하면 뭐가 어떻게 된다고 했던 것 같은데...
물어보니 여전히 과적합된 상태라고 한다. 릿지 규제를 하면 뭐가 어떻게 된다고 했던 것 같은데...
''' ridge 정규화 '''
from sklearn.linear_model import Ridge
ridge = Ridge(alpha=0.001, max_iter=100, random_state=20)
ridge.get_params()
ridge.fit(X_train_poly, y_train)
pred_train = ridge.predict(X_train_poly)
pred_test = ridge.predict(X_test_poly)
print(lr.score(X_train_poly, y_train))
print(lr.score(X_test_poly, y_test))
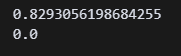 변함이 없다. 진짜 모르겠다.
변함이 없다. 진짜 모르겠다.
내가 볼 때 이번 미션은 아직 내가 건드릴 수준이 아닌 것 같다. 일단 실력을 쌓고 다시 해봐야겠다.
너 딱 기다려라.
