◆ Q & A 요약
Q1. 지도 학습과 비지도 학습의 차이는 무엇인가요?
A1. y값(정답) 제공 유무의 차이다. 지도 학습은 X와 y의 관계를 함께 알려주고, 비지도 학습은 X와 y의 관계를 스스로 형성한다.
Q2. 손실 함수(loss function)란 무엇이며, 왜 중요한가요?
A2. 손실 함수는 예측 y값과 실제 y값의 차이를 수치화하는 함수다. 이 값이 낮을수록 모델 학습이 잘 된 것이다.
Q3. 모델 학습 시 발생할 수 있는 편향과 분산에 대해 설명하고, 두 개념의 관계에 대해 설명해 주세요.
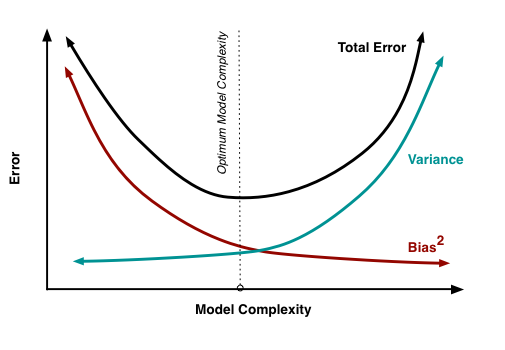
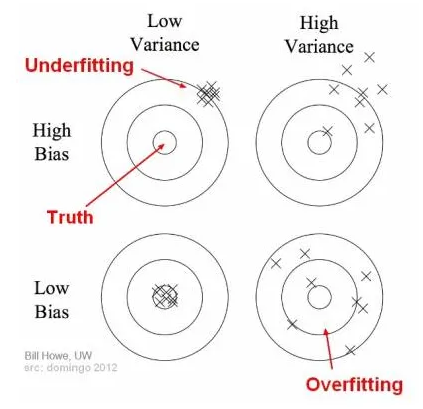
A3. 편향(Bias)이 높으면 제공한 데이터를 제대로 학습하지 못한 것이고, Underftting 문제가 발생한다. 분산(Variance)이 높으면 제공한 데이터만 지나치게 학습한 것이고, Overfitting 문제가 발생한다. 둘은 반비례하는 관계이지만, bias의 감소와 variance의 증가가 같아지는 최적의 지점이 있다. 그 지점을 찾는 것이 핵심이다.
Q4. K-폴드 교차 검증에서 K의 값을 선택할 때 고려해야 할 점은 무엇인가요?
A4. K값에 따라 훈련용 평가용 데이터가 나뉜다. K값이 낮으면 학습은 잘 할 수 있지만, 평가가 불안정할 수 있다. K값이 높으면 평가는 안정적이지만 학습을 제대로 못할 수 있다. 데이터 크기, 모델 성능, 계산 비용을 고려해 적정 K값을 설정해야 한다.
1. 지도 학습과 비지도 학습의 차이는 무엇인가요?
(1) 지도 학습
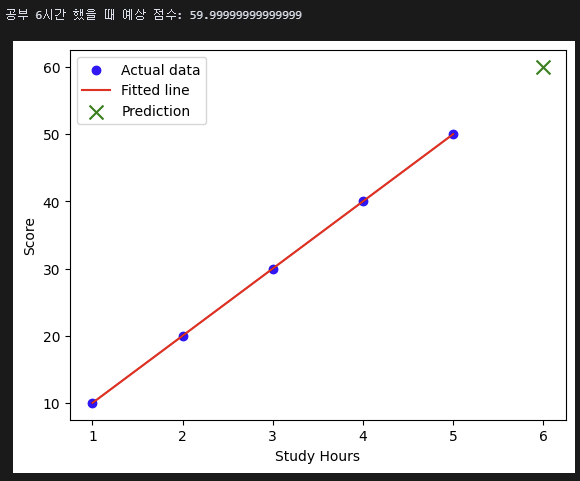
지도 학습(Supervised Learning)이란, 문제(X, 입력데이터, 독립변수)와 정답(y, 출력데이터, 종속병수)이 주어진 상태에서 모델을 학습하는 방식이다. 대표적인 알고리즘으로 선형 회귀, 로지스틱 회귀, 랜덤 포레스트, 신경망 등이 있다. 예측과 분류 문제에 주로 사용된다.
- 예시(선형 회귀)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
# 간단한 학습 데이터 (X: 공부 시간, Y: 시험 점수)
X = np.array([1, 2, 3, 4, 5]).reshape(-1, 1) # 입력 데이터 (공부 시간)
y = np.array([10, 20, 30, 40, 50]) # 정답 데이터 (시험 점수)
# 선형 회귀 모델 생성 및 학습
model = LinearRegression()
model.fit(X, y)
# 예측 수행
X_test = np.array([6]).reshape(-1, 1) # 공부 6시간 했을 때 예상 점수
y_pred = model.predict(X_test)
print(f"공부 6시간 했을 때 예상 점수: {y_pred[0]}") # 출력 예: 60.0
# 그래프 시각화
plt.scatter(X, y, color='blue', label='Actual data')
plt.plot(X, model.predict(X), color='red', label='Fitted line')
plt.scatter(X_test, y_pred, color='green', marker='x', s=100, label='Prediction')
plt.xlabel('Study Hours')
plt.ylabel('Score')
plt.legend()
plt.show()
(2) 비지도 학습
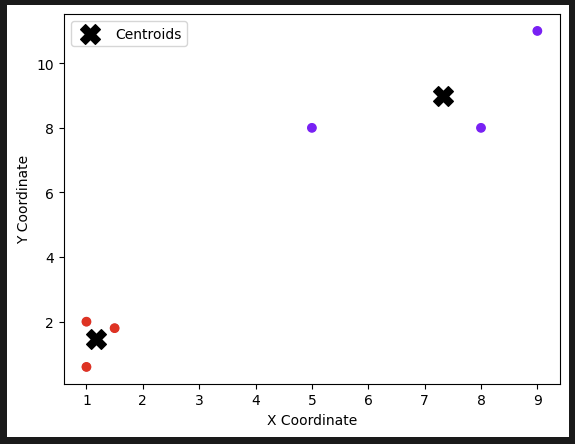
비지도 학습(Unsupervised Learning)이란, y값 없이 X만 가지고 데이터의 패턴을 찾아내는 방식이다. 군집화(K-Means), 차원 축소(PCA) 등의 기법이 있다.
- 예시(K-Means 클러스터링)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
# 무작위 2D 데이터 생성 (x, y 좌표)
X = np.array([[1, 2], [1.5, 1.8], [5, 8], [8, 8], [1, 0.6], [9, 11]])
# K-Means 클러스터링 수행 (k=2로 설정)
kmeans = KMeans(n_clusters=2, random_state=0)
kmeans.fit(X)
# 클러스터링 결과 시각화
plt.scatter(X[:, 0], X[:, 1], c=kmeans.labels_, cmap='rainbow')
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], s=200, color='black', marker='X', label='Centroids')
plt.xlabel('X Coordinate')
plt.ylabel('Y Coordinate')
plt.legend()
plt.show()
2. 손실 함수(loss function)란 무엇이며, 왜 중요한가요?
손실 함수는 모델이 예측한 값과 실제 값 간의 차이를 수치화하는 함수이다. 학습 과정에서 이 값을 최소화하는 방향으로 모델이 최적화된다. 대표적인 손실 함수로는 회귀 문제에서는 MSE(평균제곱오차), 분류 문제에서는 크로스 엔트로피 등이 있다. 손실 함수는 모델의 성능을 평가하고 업데이트하는 핵심 역할을 한다.
- 예시(평균제곱오차, MSE)
import numpy as np
# 실제 값 (y)와 예측 값 (y_pred)
y = np.array([10, 20, 30, 40, 50])
y_pred = np.array([12, 18, 33, 37, 49])
# MSE 계산 함수
def mse(y, y_pred):
return np.mean((y - y_pred) ** 2)
# 결과 출력
print(f"MSE: {mse(y, y_pred)}") # 출력 예: 4.8
3. 모델 학습 시 발생할 수 있는 편향과 분산에 대해 설명하고, 두 개념의 관계에 대해 설명해 주세요.
(1) 편향과 분산
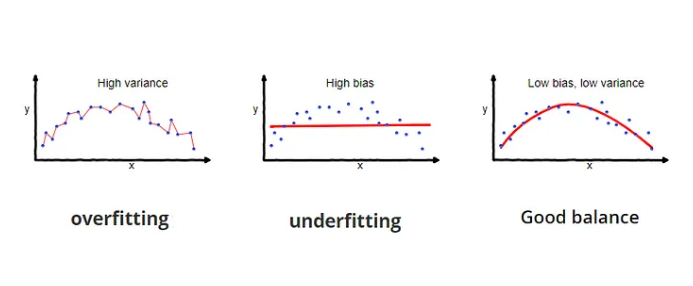
편향(Bias): 모델이 단순화되어 실제 데이터 패턴을 충분히 학습하지 못하는 경향. 편향이 크면 과소적합(Underfitting) 발생.
분산(Variance): 모델이 훈련 데이터에 과도하게 적합하여 새로운 데이터에 대한 일반화 능력이 떨어지는 경향. 분산이 크면 과적합(Overfitting) 발생.
- 코드 예시
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.pipeline import make_pipeline
# 데이터 생성
np.random.seed(42)
x = np.linspace(-3, 3, 30)
y_true = np.sin(x) # 실제 패턴
noise = np.random.normal(scale=0.3, size=y_true.shape)
y_noisy = y_true + noise # 노이즈 추가된 데이터
# 편향이 높은 모델 (선형 회귀)
model_low_bias = LinearRegression()
model_low_bias.fit(x.reshape(-1, 1), y_noisy)
def plot_model(ax, model, degree, title):
"""모델을 학습하고 그래프로 출력"""
x_test = np.linspace(-3, 3, 100)
model.fit(x.reshape(-1, 1), y_noisy)
y_pred = model.predict(x_test.reshape(-1, 1))
ax.scatter(x, y_noisy, color='blue', label='Noisy Data')
ax.plot(x_test, np.sin(x_test), 'g--', label='True Function')
ax.plot(x_test, y_pred, 'r-', label=f'Predicted (Degree {degree})')
ax.set_title(title)
ax.legend()
# 분산이 높은 모델 (고차 다항 회귀)
model_high_variance = make_pipeline(PolynomialFeatures(degree=10), LinearRegression())
# 그래프 시각화
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
plot_model(axes[0], model_low_bias, 1, 'High Bias (Underfitting)')
plot_model(axes[1], model_high_variance, 10, 'High Variance (Overfitting)')
plt.show()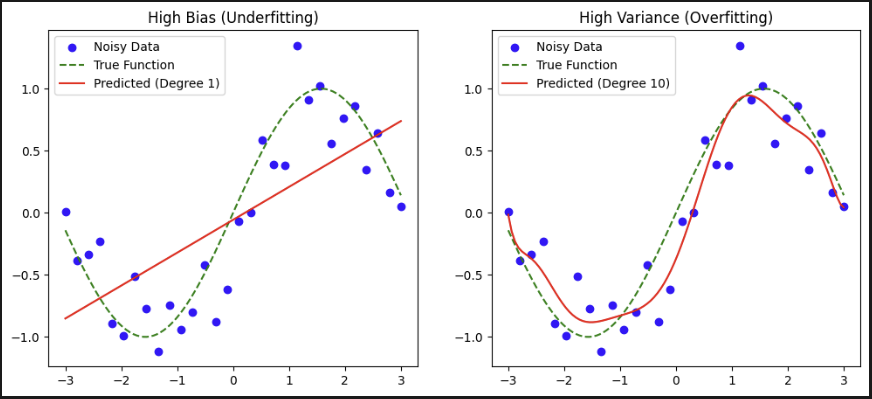
(2) 두 개념의 관계
편향과 분산은 서로 상충(trade-off)하는 관계다. 편향을 낮추면 복잡한 모델이 되어 분산이 커질 수 있고, 분산을 낮추면 단순한 모델이 되어 편향이 커질 수 있다. bias의 감소와 variance의 증가가 같아지는 최적의 지점을 찾는 것이 중요하다.
4. K-폴드 교차 검증에서 K의 값을 선택할 때 고려해야 할 점은 무엇인가요?
(1) K-폴드의 역할
K-폴드 교차 검증을 사용하면 데이터를 여러 개의 폴드로 나누어 학습과 검증을 반복하여 모델을 평가할 수 있다.
- 예시(K-폴드 교차 검증이 필요한 코드)
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
import numpy as np
# 데이터 생성 (매우 적은 샘플, 과장된 분포)
np.random.seed(42)
X = np.array([[1], [2], [3], [100], [101], [102], [200], [201], [202], [1000]]) # 극단적인 값 포함!
y = np.array([2, 4, 6, 200, 202, 204, 400, 402, 404, 2000]) # y = 2X로 설정 (완벽한 선형 관계)
# 단순 Train/Test Split (큰 문제!)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 선형 회귀 모델 훈련 및 예측
model = LinearRegression()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
# 결과 출력
print("단순 분할 결과")
print(f"MSE: {mean_squared_error(y_test, y_pred):.4f}")
print(f"테스트 샘플: {X_test.squeeze()}")
 이 코드는 데이터가 편향될 가능성이 크다. 훈련/테스트 나누는 방식에 따라 결과가 천차만별이므로, K-폴드 교차 검증이 필요하다.
이 코드는 데이터가 편향될 가능성이 크다. 훈련/테스트 나누는 방식에 따라 결과가 천차만별이므로, K-폴드 교차 검증이 필요하다.
(2) K값이 작을 때
K-폴드 교차 검증에서 K의 값을 선택할 때 고려해야 할 점
K값이 작을 때 (예: K=3~5): 훈련 데이터가 많아져 모델이 잘 학습되지만, 검증 데이터가 적어 평가가 불안정할 수 있다.
- 예시
from sklearn.model_selection import KFold, cross_val_score
# K=2 (극단적인 상황)
kf = KFold(n_splits=2, shuffle=True, random_state=42)
model = LinearRegression()
# K-폴드 교차 검증 수행
mse_scores = -cross_val_score(model, X, y, cv=kf, scoring='neg_mean_squared_error')
print("K=2 교차 검증 결과")
print(f"각 Fold별 MSE: {mse_scores}")
print(f"평균 MSE: {mse_scores.mean():.4f}")
 이 코드는 훈련 데이터가 50%씩이라 학습은 괜찮지만, 평가 데이터가 너무 적다. 한 번의 분할에서 극단적인 값이 포함되면 결과가 심하게 왜곡될 수 있기에 K값을 재설정할 필요가 있다.
이 코드는 훈련 데이터가 50%씩이라 학습은 괜찮지만, 평가 데이터가 너무 적다. 한 번의 분할에서 극단적인 값이 포함되면 결과가 심하게 왜곡될 수 있기에 K값을 재설정할 필요가 있다.
(3) K값이 클 때
K값이 클 때 (예: K=10 이상): 검증 데이터가 많아져 평가가 안정적이지만, 훈련 데이터가 적어질 가능성이 있어 성능이 떨어질 수 있다.
- 예시
# K=8 (안정적인 상황)
kf = KFold(n_splits=8, shuffle=True, random_state=42)
# K-폴드 교차 검증 수행
mse_scores = -cross_val_score(model, X, y, cv=kf, scoring='neg_mean_squared_error')
print("K=8 교차 검증 결과")
print(f"각 Fold별 MSE: {mse_scores}")
print(f"평균 MSE: {mse_scores.mean():.4f}")
 이 코드는 검증 데이터가 충분히 모델 학습이 잘 이루어지고, 극단적인 데이터에도 영향을 덜 받는다.
이 코드는 검증 데이터가 충분히 모델 학습이 잘 이루어지고, 극단적인 데이터에도 영향을 덜 받는다.
(4) 일반적인 선택 기준
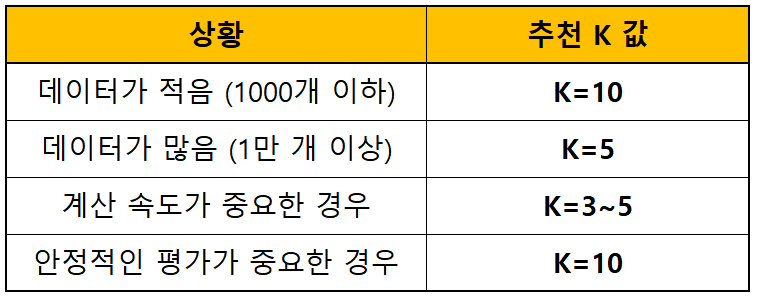
K-폴드 교차 검증에서 K 값을 정할 때는 데이터의 크기, 모델의 일반화 성능, 계산 비용 등을 고려해야 한다. 일반적으로 5~10 사이의 값을 가장 많이 사용하지만, 데이터 특성에 따라 달라질 수 있다.
A. 데이터 크기를 고려
데이터가 작을 때 → K 값을 크게 (ex. K=10)
- 데이터가 적으면 훈련 데이터도 최대한 많이 활용해야 함
- 검증 데이터가 충분해야 평가가 안정적
데이터가 클 때 → K 값을 작게 (ex. K=5)
- 데이터가 많으면 작은 K 값으로도 충분히 일반화 가능
- K가 클수록 계산량이 많아져 속도가 느려질 수 있음
B. 모델 성능 고려
K 값이 작으면 (ex. K=2~5)
- 훈련 데이터가 많아져 모델이 더 잘 학습됨
- BUT, 검증 데이터가 적어 평가가 불안정할 수 있음
K 값이 크면 (ex. K=10 이상)
- 검증 데이터가 많아져 평가가 안정적
- BUT, 훈련 데이터가 줄어들어 모델 학습이 부족할 가능성이 있음
K=5~10이 적절한 이유
- 적절한 균형을 맞추면서도 계산 비용이 너무 크지 않기 때문!
C. 계산 비용 고려 (속도 vs. 정확도)
- K가 크면 → 정확한 평가 가능 BUT 계산량이 커짐
- K가 작으면 → 빠르게 결과를 얻을 수 있음 BUT 평가가 불안정할 수 있음
- 딥러닝 같은 대규모 데이터셋에서는 K=5를 많이 사용
- 작은 데이터셋에서는 K=10을 선호
◆ 해설
1. 지도 학습과 비지도 학습의 차이는 무엇인가요?
- 지도 학습은 입력 데이터와 해당 정답 레이블을 함께 사용하여 모델을 학습시키는 방식입니다. 이를 통해 모델은 주어진 입력에 대해 올바른 출력을 예측할 수 있도록 학습합니다. 예를 들어, 사진에 있는 물체를 분류하는 것이 지도 학습의 예입니다.
- 반면, 비지도 학습은 레이블이 없는 데이터를 사용하여 모델이 데이터 내 숨겨진 패턴이나 구조를 스스로 파악하도록 합니다. 이 방식은 데이터의 그룹화, 연관성 발견 등에 주로 사용됩니다. 예를 들어, 고객 데이터를 분석하여 비슷한 소비 성향을 가진 그룹을 찾는 것이 비지도 학습의 예가 될 수 있습니다.
2. 손실 함수(loss function)란 무엇이며, 왜 중요한가요?
- 손실함수는 머신러닝 모델의 예측값과 실제값 사이의 차이를 수치적으로 나타내는 함수입니다. 이 함수의 값(손실)을 최소화하는 것이 모델 학습의 주요 목표입니다. 손실함수를 통해 모델의 성능을 평가하고, 이를 통해 모델이 데이터를 얼마나 잘 예측하는지 파악할 수 있습니다. 따라서, 손실함수는 모델의 학습 방향을 결정짓는 중요한 역할을 합니다.
3. 모델 학습 시 발생할 수 있는 편향과 분산에 대해 설명하고, 두 개념의 관계에 대해 설명해 주세요.
- 편향과 분산은 Trade-off 관계에 있습니다. 즉, 하나를 줄이면 다른 하나가 증가하는 경향이 있습니다. 모델의 성능을 최적화하려면 이 둘 사이의 균형을 잘 맞춰야 합니다.
- 고편향, 저분산: 너무 단순한 모델로 인해 데이터의 복잡한 패턴을 제대로 학습하지 못해 편향이 높아지지만, 예측의 일관성은 유지됩니다.
- 저편향, 고분산: 매우 복잡한 모델로 인해 학습 데이터에 과적합하여 분산이 높아지지만, 훈련 데이터에 대해서는 매우 정확한 예측을 할 수 있습니다.
4. K-폴드 교차 검증에서 K의 값을 선택할 때 고려해야 할 점은 무엇인가요?
- K-폴드 교차 검증에서 K의 값을 선택할 때는 데이터셋의 크기, 계산 비용(리소스), 분산과 편향의 균형, 데이터의 특성 등을 종합적으로 고려해야 합니다. 일반적으로 5-폴드나 10-폴드 교차 검증이 많이 사용됩니다.
- 데이터셋의 크기가 크면 k의 값을 상대적으로 작은 값으로 설정해도 충분합니다. (5 정도)
- k 값이 클 수록 각 폴드에 대해 모델을 더 많이 학습시켜야하므로 계산에 필요한 비용이 증가합니다. k 값이 작을 수록 계산 비용이 줄어들지만, 모델 평가의 변동성이 커질 수 있습니다.
- k 값이 클 수록 모델의 분산이 줄어들고, 더 정확한 평가가 가능하지만 편향(bias)는 증가할 수 있습니다. 반대로 k 값이 작을 수록 모델의 편향은 줄어들지만 모델 평가의 신뢰도를 떨어뜨릴 수 있습니다.
- 데이터가 균형 잡혀 있는 경우 어떤 k값을 사용해도 비교적 일관된 결과를 얻을 수 있습니다. 다만 데이터가 불균형한 경우 각 폴드에 모든 클래스가 충분히 포함되도록 신중하게 k값을 선택해야 합니다.
