많은 것을 깨달은 하루. 부트캠프 미션을 도저히 해결할 수가 없어서 쉬운 것부터 다시 했다. 우여곡절 끝에 타이타닉 생존자 예측 모델을 성공적으로 만들었다. 내가 왜 미션을 못했는지 대충 짐작 가는 부분이 있다. 딱 기다려라 곧 풀어주마.
학습시간 18:00~02:00(당일8H/누적210H)
◆ 오늘 깨달은 것
- 원핫인코딩 시
drop_first=True이 코드를 추가하면 자동으로 다중공선성을 없애준다.
- 데이터 스플릿 후에 스케일링을 진행해야 한다. 스케일링 시 훈련 데이터는 학습(fit)까지 해야하기 때문에
scaler.fit_transform(X_train)이 코드를 사용해야 한다.평가 데이터는 학습하면 안 되기 때문에scaler.transform(X_test)이 코드처럼fit_을 넣지 않는다.
- 다중공선성이라는 개념에 대해 알았다. 아래 코드를 이용해서 수치가 10 이하면 오케이라고 한다.
from statsmodels.stats.outliers_influence import variance_inflation_factor
X = X.astype(float) # 데이터를 float 타입으로 변환
pd.DataFrame(X.columns, columns=["Feature"])["VIF"] = [variance_inflation_factor(X.values, i) for i in range(X.shape[1])]
print(vif) # Variance Inflation Factor-
accuracy_scorelogr.score이 두 코드가 똑같은 역할을 한다. -
MSE같은 지표는 회귀 문제에서 사용하고, 오차행렬은 분류(이진&다중) 문제에서 사용한다.
◆ 머신러닝 공부
타이타닉 생존자 예측
1. 데이터 전처리
df = pd.read_csv('data/titanic.csv')
df.head() 천천히 해보자. 데이터를 보니 필요없는 문자열 컬럼은 제거하고, 성별과 승강장은 원핫인코딩 해야할 것 같다.
천천히 해보자. 데이터를 보니 필요없는 문자열 컬럼은 제거하고, 성별과 승강장은 원핫인코딩 해야할 것 같다.
df = df.drop(columns=['Name','Ticket','Cabin','PassengerId'])
df.dtypes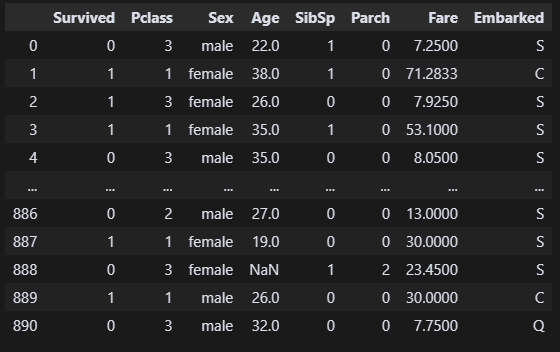
 필요한 열만 남았다. 타입도 바꿀 건 없어 보인다.
필요한 열만 남았다. 타입도 바꿀 건 없어 보인다.
df.isna().sum()
df['Age'].fillna(df['Age'].mode()[0], inplace=True)
df['Embarked'].fillna('S', inplace=True)
df.isna().sum()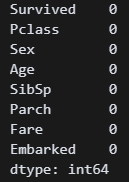 결측값을 빠르게 mode값으로 채웠다.
결측값을 빠르게 mode값으로 채웠다.
df = df.drop_duplicates()
df.duplicated().sum() 중복값도 빠르게 삭제.
중복값도 빠르게 삭제.
df_encode = pd.get_dummies(df, columns=['Sex', 'Embarked'], drop_first=True)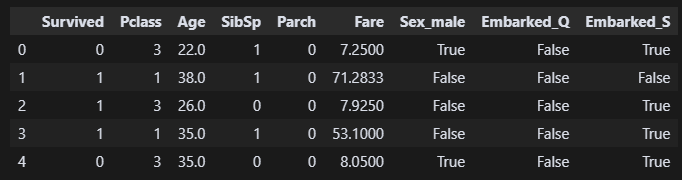 'Sex', 'Embarked' 두 컬럼에 대해 원핫인코딩을 진행했다.
'Sex', 'Embarked' 두 컬럼에 대해 원핫인코딩을 진행했다. drop_first=True 이 코드를 추가하면 자동으로 필요없는 열을 삭제해서 다중공선성을 없애준다고 한다.
sns.heatmap(df_encode.corr(), annot=True, fmt='.1f')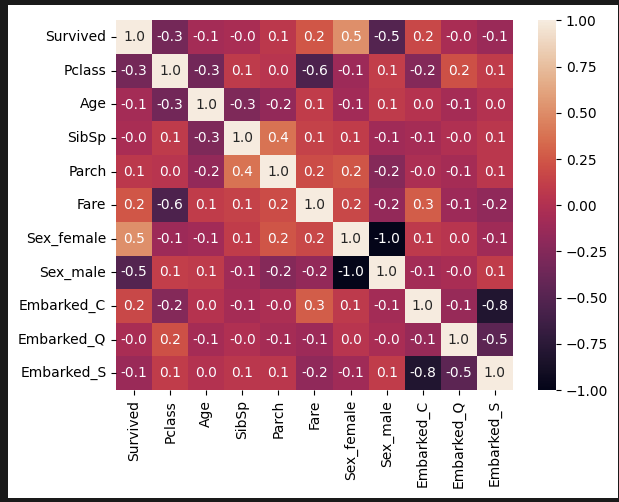 히트맵 한 번만 보고 머신러닝 들어가야지. 상관관계 분석하는 게 목적이 아니라서 따로 디자인 셋팅은 안 했다. 그래도 뭐 나쁘지 않은 듯하다. 좌석 클래스와 성별에 따라 생존율이 결정되는 듯하다.
히트맵 한 번만 보고 머신러닝 들어가야지. 상관관계 분석하는 게 목적이 아니라서 따로 디자인 셋팅은 안 했다. 그래도 뭐 나쁘지 않은 듯하다. 좌석 클래스와 성별에 따라 생존율이 결정되는 듯하다.
- 다중공선성이라는 개념에 대해 알았다. 아래 코드를 이용해서 수치가 10 이하면 오케이라고 한다.
from statsmodels.stats.outliers_influence import variance_inflation_factor
X = X.astype(float) # 데이터를 float 타입으로 변환
pd.DataFrame(X.columns, columns=["Feature"])["VIF"] = [variance_inflation_factor(X.values, i) for i in range(X.shape[1])]
print(vif) # Variance Inflation Factor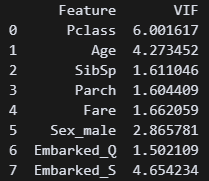 수치가 괜찮아 보인다! 다음 단계로 가자!
수치가 괜찮아 보인다! 다음 단계로 가자!
2. 데이터 스플릿
X = df_encode.drop(columns=['Survived'])
y = df_encode['Survived']머신러닝을 위해 원핫인코딩한 df를 X와 y로 나눴다. 이번엔 제발 성공해야할 텐데..! 다음은 스케일링 후 데이터 스플릿이었던가??
 엥? 스케일링을 왜 먼저 하지?
엥? 스케일링을 왜 먼저 하지?

 와,, 나 여기서 엄청난 깨달음을 얻었다.
와,, 나 여기서 엄청난 깨달음을 얻었다.
훈련 데이터는 학습(fit)까지 해야하기 때문에 scaler.fit_transform(X_train) 이 코드를 사용해야 한다.
평가 데이터는 학습하면 안 되기 때문에 scaler.transform(X_test) 이 코드처럼 fit_을 넣지 않는다.
미션 문제 평가용 데이터 스코어가 0.0이 나온 실마리가 잡힌 것 같다.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=20, stratify=y)데이터 스플릿을 먼저 진행했다. stratify=y 이 코드는 처음 보는데, 데이터의 비율을 고루 맞추어 학습&평가를 더 잘 할 수 있게 한다고 한다.
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
X_train_scl = ss.fit_transform(X_train)
X_test_scl = ss.transform(X_test)
X_train_scl.shape, y_train.shape, X_test_scl.shape, y_test.shape 스플릿, 스케일링 후 차원 확인까지 했다. 독립변수가 8차원이다.
스플릿, 스케일링 후 차원 확인까지 했다. 독립변수가 8차원이다.
3. 모델 학습
이제 모델을 정할 차례인데, 이진 분류니까 로지스틱회귀를 하는 게 맞겠지?

 지선생에게 물어보니 로지스틱 회귀를 하면 될 것 같다. 결정 트리와 랜덤 포레스트 머시기는 아직 안 배웠으니... 혹시 이거 다음 주에 배우나? 벌써 무섭다.
지선생에게 물어보니 로지스틱 회귀를 하면 될 것 같다. 결정 트리와 랜덤 포레스트 머시기는 아직 안 배웠으니... 혹시 이거 다음 주에 배우나? 벌써 무섭다.
from sklearn.linear_model import LogisticRegression
logr = LogisticRegression()
logr.fit(X_train_scl, y_train) 로지스틱 회귀 모델을 선택 후 학습시켰다. 뭐가 나왔으니 잘 된 거겠지..?
로지스틱 회귀 모델을 선택 후 학습시켰다. 뭐가 나왔으니 잘 된 거겠지..?
y_pred = logr.predict(X_test_scl)예측 코드를 넣었다. 제발 잘 예측해주렴 ㅠㅠ!!
4. 모델 평가
이제 뭘로 평가하면 좋을까..! 지선생에게 물어보자!
 알려준 대로 해봐야지.
알려준 대로 해봐야지.
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
print("Accuracy:", accuracy_score(y_test, y_pred))
print("Confusion Matrix:\n", confusion_matrix(y_test, y_pred))
print("Classification Report:\n", classification_report(y_test, y_pred))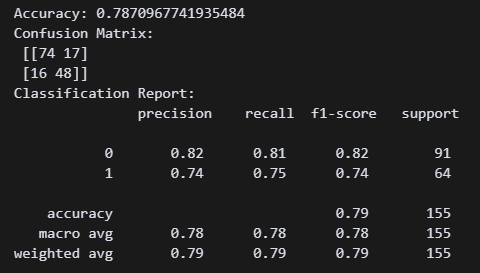 오 뭔가 강의 때 배웠던 지표가 쭉 나온다. 이렇게 간단하게 나오는 거였냐고!!!
오 뭔가 강의 때 배웠던 지표가 쭉 나온다. 이렇게 간단하게 나오는 거였냐고!!!
근데 score()함수는 언제 사용하는 거지?
 엇 그럼
엇 그럼 accuracy_score logr.score 이 두 코드가 똑같은 역할이라는 뜻인가?
 아!! 두 코드는 정확히 같은 역할을 한다. 새로운 깨달음이다. 간단하게 보고 싶을 때만 score를 사용하면 되는 거구만.
아!! 두 코드는 정확히 같은 역할을 한다. 새로운 깨달음이다. 간단하게 보고 싶을 때만 score를 사용하면 되는 거구만.
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
y_pred_train = logr.predict(X_train_scl)
print("Accuracy_train:", accuracy_score(y_train, y_pred_train))
print("Accuracy_test:", accuracy_score(y_test, y_pred))
print("Confusion Matrix:\n", confusion_matrix(y_test, y_pred))
print("Classification Report:\n", classification_report(y_test, y_pred))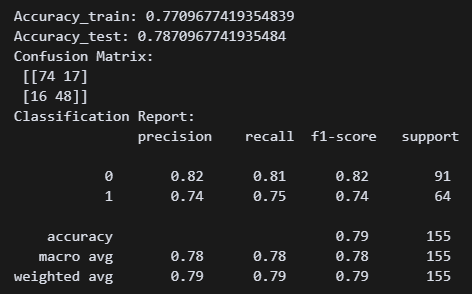 train셋과 test셋 정확도를 보기 위해 y_pred_train 변수를 만들어 줬다. 강의 때 배운 오차행렬부터 precision, recall, f1-score 점수까지 싹 다 나온다.
train셋과 test셋 정확도를 보기 위해 y_pred_train 변수를 만들어 줬다. 강의 때 배운 오차행렬부터 precision, recall, f1-score 점수까지 싹 다 나온다.
근데 왜 0과 1 두 개로 나누어져 있는 거지??
 아! 모델이 예측할 확률을 각각 나타내는 거였다.
아! 모델이 예측할 확률을 각각 나타내는 거였다.
근데 MSE 평균제곱오차 인가? 그것도 배웠는데 그걸 사용하면 안 되는 건가?
 아!! 오차행렬은 분류에서 사용, MSE는 회귀에서 사용하는 것이다. 또 다른 깨달음이다. 오늘 엄청 많은 것을 깨닫네!
아!! 오차행렬은 분류에서 사용, MSE는 회귀에서 사용하는 것이다. 또 다른 깨달음이다. 오늘 엄청 많은 것을 깨닫네!
그럼 이진 분류에서만 쓰나? 다중 분류면 못 쓰는 건가?
 오케이. 이걸로 확실해졌다.
오케이. 이걸로 확실해졌다.
5. 예측 시각화
이제 예측한 결과를 시각화하고 싶은데, 간단하고 좋은 방법이 없을까?
 러닝 커브라는 그래프를 알려줬다.
러닝 커브라는 그래프를 알려줬다.
from sklearn.model_selection import learning_curve
train_sizes, train_scores, test_scores = learning_curve(logr, X, y, cv=5)
# 평균 정확도 계산
train_mean = train_scores.mean(axis=1)
test_mean = test_scores.mean(axis=1)
# 그래프 그리기
plt.figure(figsize=(10, 7))
plt.plot(train_sizes, train_mean, color='blue', label='Train Accuracy')
plt.plot(train_sizes, test_mean, color='red', label='Test Accuracy')
plt.title('Learning Curve')
plt.xlabel('Training Size')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
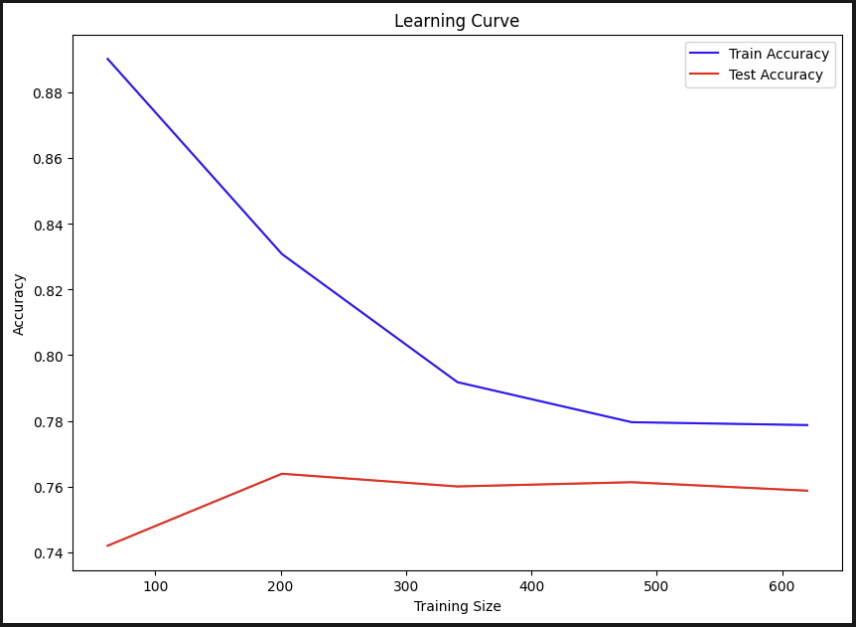 모델이 train셋과 test셋의 X값을 학습하는 과정이 보인다. train셋의 예측 정확도가 점점 낮아지긴 하지만 두 데이터가 비슷한 곳에 수렴하는 것을 보면 잘 되었다는 증거로 보인다.
모델이 train셋과 test셋의 X값을 학습하는 과정이 보인다. train셋의 예측 정확도가 점점 낮아지긴 하지만 두 데이터가 비슷한 곳에 수렴하는 것을 보면 잘 되었다는 증거로 보인다.
learning_curve 함수에서는 train 데이터와 test 데이터를 분석하여 자동으로 X와 y로 매핑해준다. 따라서 변수명을 맞출 필요가 없다. 완전 짱이잖아 이거?
6. 기타
이제 여기서 끝내면 되는 걸까? 내가 더 해야하는 건 없는 걸까?
 지선생께서 그냥 보내줄 순 없다고 한다.
지선생께서 그냥 보내줄 순 없다고 한다.
 아! 그래 들어봤다. 하이퍼 파라미터!! 그리드 서치와 교차 검증도 이 단계에서 하는 거였구만? 일단 모델 구현이 먼저니까 모델 성능 향상하는 부분은 실력을 더 쌓아서 시도해 봐야겠다.
아! 그래 들어봤다. 하이퍼 파라미터!! 그리드 서치와 교차 검증도 이 단계에서 하는 거였구만? 일단 모델 구현이 먼저니까 모델 성능 향상하는 부분은 실력을 더 쌓아서 시도해 봐야겠다.
로지스틱 회귀 성공적..! 고마워요 지선생!
