일주일간 진짜진짜진짜 힘들었다. 그래도 이번 미션 덕분에 여러 방면으로 비약적인 성장을 했다. 내일부터는 심화과정에 들어간다고 한다. 다시 화이팅 해보자!!! print("화이팅!")
학습시간 09:00~02:00(당일17H/누적513H)
◆ 학습내용
지금까지 만든 6개 모델을 비교할 차례다.
손실함수로 MSE를 사용했는데, 이거랑 조금 다른 지표로 평가를 해야하는 것 같다.
RMSE와 PSNR 등을 이용하라고 하는데, '등'에 속하는 게 뭐가 있는지 몰르겠다. 일단 저 두 개만 해봐야겠다.
근데 RMSE, PSNR이 뭐지...? 이게 뭔지부터 찾아봐야겠다.
1. RMSE & PSNR
(1) RMSE
MSE = Mean Square Error(평균 제곱 오차)
RMSE = Root Mean Square Error(평균 제곱근 오차)
아하! RMSE는 MSE랑 비슷한 거구만
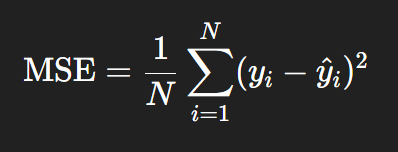
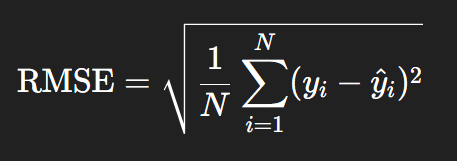 RMSE에는 수식 위에 모자처럼 덮은 게 있다.
RMSE에는 수식 위에 모자처럼 덮은 게 있다.
둘 다 수치가 낮을수록 좋은 거라고 한다. RMSE는 오차 폭이 클수록 더 민감하다는데,,, 무슨 소린지 잘모르겠다!
(2) PSNR
PSNR = Peak Signal-to-Noise Ratio(최대 신호 대비 잡음 비율)
얼마나 깨끗하게 복원했나를 데시벨 단위로 표현하는 것
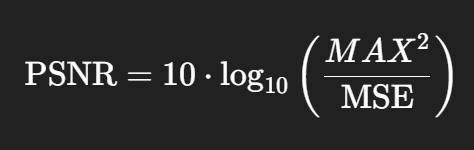
MSE(또는 RMSE)를 이용해, 신호 대비 노이즈 비율을 로그 스케일로 계산한다.
왜 굳이 로그를??
-> 인간의 청각, 시각은 로그적으로 인식되기 때문이라고 함
사람이 느끼는 품질과 꽤 잘 맞아서 딥러닝 기반 노이즈 제거, 압축 복원 모델 평가에 자주 쓰인다고 한다.
헐 내가 보는 세상이 로그였다니

즉, 셋은 모두 같은 정보를 다른 방식으로 표현한 것이라 볼 수 있다. MSE가 작으면 RMSE도 작고, PSNR은 커지는 구조다.
그렇다고 한다.
수식은 뭔 소린지 진짜 하나도 모르겠다 ㅠㅠ
(3) 코드로 표현
mse = np.mean((train_output - train_y) ** 2)
rmse = np.sqrt(mse)
psnr = 10 * math.log10(1.0 / (mse + 1e-8))
이렇게 생겼다고 한다. np.sqrt() 하면 제곱근을 구할 수 있다고 한다.
psnr 지표는 대충 저렇게 만든다고 한다. 꼭 정규화를 해서 써야한다고 한다.
흠 뭔 말인지 모르겠지만 수학 공식으로 보는 것보단 나은 듯하다.
2. 코드 생성
RMSE & PSNR 두 지표는 시각화와 동시에 출력되도록 만드려고 한다.
하지만 아직 내 실력으론 택도 없다.
전 멘토님이 시각화 관련은 생성형AI에게 최대한 맡기고 본질에 집중하라고 했다.
AI 엔지니어의 본질은 모델의 성능을 극한까지 끌어올리는 게 아닐까?
일단 코드부터 만들고 차근차근 흡수해야겠다.
도와줘요 지선생!!!


def visualize_train(model, index_list):
model.eval()
n = len(index_list)
plt.figure(figsize=(18, 4 * n))
plt.suptitle("Train Set Visualization", fontsize=18)
for i, idx in enumerate(index_list):
noisy = train_x[idx]
clean = train_y[idx]
padded_input, shape_info = pad_to_size(noisy, target_h, target_w)
padded_target, _ = pad_to_size(clean, target_h, target_w)
x = torch.tensor(padded_input).unsqueeze(0).unsqueeze(0).float().to(device)
y = torch.tensor(padded_target).unsqueeze(0).unsqueeze(0).float().to(device)
with torch.no_grad():
output = model(x).cpu().squeeze().numpy()
output_unpad = unpad(output, shape_info)
noisy_unpad = unpad(padded_input, shape_info)
clean_unpad = unpad(padded_target, shape_info)
output_tensor = torch.tensor(output_unpad).float()
clean_tensor = torch.tensor(clean_unpad).float()
mse_tensor = F.mse_loss(output_tensor, clean_tensor)
rmse_tensor = torch.sqrt(mse_tensor)
psnr_tensor = 10 * torch.log10(1.0 / (mse_tensor + 1e-8))
mse_val = mse_tensor.item()
rmse_val = rmse_tensor.item()
psnr_val = psnr_tensor.item()
plt.subplot(n, 3, 3*i+1)
plt.imshow(noisy_unpad, cmap='gray')
plt.title(f'Input(X) #{idx}')
plt.axis('off')
plt.subplot(n, 3, 3*i+2)
plt.imshow(clean_unpad, cmap='gray')
plt.title(f'Target(Y) #{idx}')
plt.axis('off')
plt.subplot(n, 3, 3*i+3)
plt.imshow(output_unpad, cmap='gray')
plt.title(f'Output(MODEL) #{idx}\n(RMSE={rmse_val:.4f}, PSNR={psnr_val:.2f} dB)')
plt.axis('off')
plt.tight_layout()
plt.show()꽤나 복잡한 코드가 나왔다.
내가 지정한 번호의 Train set 훈련 이미지, 정답 이미지, 복원 이미지를 동시에 출력하려고 해서 그런 것 같다.
이해가 안 되니까 변수 이름을 변경하면서 코드를 한 줄씩 뜯어봐야겠다.
def visualize_train(model, index_list):
model.eval()
n = len(index_list)
plt.figure(figsize=(18, 4 * n))
plt.suptitle("Train Set Visualization", fontsize=20)모델을 평가모드로 전환 -> 내가 기입한 인덱스 총 갯수만큼 플롯 생성
for i, idx in enumerate(index_list):
# Train x 이미지 불러오기
origin_x = train_x[idx]
# 이미지 전처리
padded_x, padded_x_shape = padding(origin_x, max_height, max_width)train set의 x 이미지를 가져와서 origin_x 로 저장한다. -> 그후 이미지 폴더 최대 사이즈만큼 패딩을 입힌다.
max_height, max_width는 padding() 함수 만들 때 같이 만들었던 get_max_size() 함수를 사용해서 나온 결과물이다.
# 텐서(4차원 배열)로 변환
tensor_x = torch.from_numpy(padded_x).unsqueeze(0).unsqueeze(0).float().to(device)
# 추론 후 2차원 배열로 변환
with torch.no_grad():
output_4d = model(tensor_x)
output_2d = output_4d.squeeze().cpu().numpy()패딩한 이미지를 4차원 배열 텐서로 만들어 준다.
.unsqueeze(0).unsqueeze(0) 이렇게 2회 들어가는 이유는 2차원 넘파이 배열을 4차원 텐서 배열로 바꿔주기 위함이다. 모델로 추론 하려면 4차원 텐서 배열이 필요하기 때문이다.
추론이 끝나면 다시 .squeeze().cpu().numpy() 를 사용해 2차원 넘파이 배열로 만들어준다. 시각화에는 2차원 넘파이 배열이 필요하고 GPU를 사용할 수 없기 때문이다.
# 이미지 후처리
unpadded_x = unpadding(padded_x, padded_x_shape)
unpadded_y = train_y[idx]
unpadded_output = unpadding(output_2d, padded_x_shape)train 이미지 = x
train_clean 이미지 = y
복원이미지 = output
이라 가정하고, 각각의 변수를 언패딩된 형태로 아래처럼 선언한다.
unpadded_x
unpadded_y
unpadded_output
# 평가 지표 계산
mse = np.mean((unpadded_output - unpadded_y) ** 2)
rmse = np.sqrt(mse)
psnr = 10 * math.log10(1.0 / (mse + 1e-8))그 후 평가 지표 계산용 변수를 만든다.
mse = (언패딩된 복원이미지 값 - 언패딩된 정답이미지 값) 이걸 제곱하고 평균으로 나눈 것
rsme = 이렇게 나온 mse를 np.sqrt()함수에 넣은 것
psnr = 10 * math.log10 라는 수식에 1.0 / (mse + 1e-8)를 곱한 것. 1e-8하는 이유는 최소 소수를 고정하기 위함이다.
# 시각화
plt.subplot(n, 3, 3*i+1)
plt.imshow(unpadded_x, cmap='gray')
plt.title(f'Train X #{idx}')
plt.axis('off')
plt.subplot(n, 3, 3*i+2)
plt.imshow(unpadded_y, cmap='gray')
plt.title(f'Train Y #{idx}')
plt.axis('off')
plt.subplot(n, 3, 3*i+3)
plt.imshow(unpadded_output, cmap='gray')
plt.title(f'Train Output #{idx}\n(RMSE={rmse:.4f}, PSNR={psnr:.2f} dB)')
plt.axis('off')
plt.tight_layout()
plt.show()플롯 생성 용 코드다. 이건 뭐 딱히 특별한 게 없어 보인다.
 오케이 일단 문제없이 잘 작동한다.
오케이 일단 문제없이 잘 작동한다.
# Test 데이터 시각화
def visualize_test(model, index_list):
model.eval()
n = len(index_list)
plt.figure(figsize=(12, 4 * n))
plt.suptitle("Test Set Visualization", fontsize=20)
for i, idx in enumerate(index_list):
# Test x 이미지 불러오기
origin_x = test_x[idx]
# 이미지 전처리
padded_x, padded_x_shape = padding(origin_x, max_height, max_width)
# 텐서(4차원 배열)로 변환
tensor_x = torch.from_numpy(padded_x).unsqueeze(0).unsqueeze(0).float().to(device)
# 추론 후 2차원 배열로 변환
with torch.no_grad():
output_4d = model(tensor_x)
output_2d = output_4d.squeeze().cpu().numpy()
# 이미지 후처리
unpadded_x = unpadding(padded_x, padded_x_shape)
unpadded_output = unpadding(output_2d, padded_x_shape)
# 시각화
plt.subplot(n, 2, 2*i+1)
plt.imshow(unpadded_x, cmap='gray')
plt.title(f'Test X #{idx}')
plt.axis('off')
plt.subplot(n, 2, 2*i+2)
plt.imshow(unpadded_output, cmap='gray')
plt.title(f'Test Output #{idx}')
plt.axis('off')
plt.tight_layout()
plt.show()
테스트 이미지 시각화를 위한 코드도 추가로 만들었다.
테스트는 정답 이미지가 없기 때문에 Y플롯도 없고 평가지표도 계산할 수 없다.
3. 모델 비교
모델을 비교하려고 실행했더니 하루가 지나서 학습했던 메모리가 다 날아갔다.
 휴 모델을 저장해놔서 다행이다. 또 30분 넘게 기다릴 뻔했다.
휴 모델을 저장해놔서 다행이다. 또 30분 넘게 기다릴 뻔했다.
def process(p):
if p == 'train':
e = 20
train_model(model1, train_loader, epochs=e, save_dir='./model/AE_model1.pth')
train_model(model2, train_loader, epochs=e, save_dir='./model/AE_model2.pth')
train_model(model3, train_loader, epochs=e, save_dir='./model/AE_model3.pth')
train_model(model4, train_loader, epochs=e, save_dir='./model/AE_model4.pth')
train_model(model5, train_loader, epochs=e, save_dir='./model/AE_model5.pth')
train_model(model6, train_loader, epochs=e, save_dir='./model/AE_model6.pth')
elif p == 'load':
model1.load_state_dict(torch.load('./model/AE_model1.pth', map_location=device))
model2.load_state_dict(torch.load('./model/AE_model2.pth', map_location=device))
model3.load_state_dict(torch.load('./model/AE_model3.pth', map_location=device))
model4.load_state_dict(torch.load('./model/AE_model4.pth', map_location=device))
model5.load_state_dict(torch.load('./model/AE_model5.pth', map_location=device))
model6.load_state_dict(torch.load('./model/AE_model6.pth', map_location=device))
else:
pass
process('load')가중치를 로드하기 위한 함수를 만들었다.
process('train') 하면 전체 모델을 20에폭만큼 돌리고, process('load') 하면 저장된 pth파일을 전부 로드한다.
논리 함수 사용할 때가 제일 재밌다. 사무실에서 밤새도록 야근하며 엑셀 다루던 시절이 생각난다.
visualize_train(model1, [105, 131])
visualize_test(model1, [5, 57])
visualize_train(model2, [105, 131])
visualize_test(model2, [5, 57])
visualize_train(model3, [105, 131])
visualize_test(model3, [5, 57])
visualize_train(model4, [105, 131])
visualize_test(model4, [5, 57])
visualize_train(model5, [105, 131])
visualize_test(model5, [5, 57])
visualize_train(model6, [105, 131])
visualize_test(model6, [5, 57])6개 모델을 돌면서 시각화를 해보자!
모델별 정확한 성능 비교를 위해 특정 번호의 이미지만 평가하려고 한다.
개인적으로 가장 복원이 까다로웠던 '부장님이 구겨놓은 듯한 이미지'를 선택했다.
(1) Model 1 (Linear + ReLU)

(2) Model 2 (CNN + ReLU)

(3) Model 3 (CNN + LeakyReLU)

(4) Model 4 (Model 3 + BatchNorm + OutConv)

(5) Model 5 (Model 4 + DoubleConv)

(6) Model 6 (U-Net)

(7) 요약
| Model | 구조 | Loss | RMSE | PSNR |
|---|---|---|---|---|
| Model 1 | Linear + ReLU | 0.0896 | 0.2875 | 10.83 |
| Model 2 | CNN + ReLU | 0.0402 | 0.2101 | 13.55 |
| Model 3 | CNN + LeakyReLU | 0.0220 | 0.1689 | 15.45 |
| Model 4 | Model 3 + BatchNorm + OutConv | 0.0138 | 0.1381 | 17.19 |
| Model 5 | Model 4 + DoubleConv | 0.0098 | 0.1144 | 18.84 |
| Model 6 | U-Net | 0.0008 | 0.0336 | 29.48 |
-
모델1: 텍스트를 전혀 인식하지 못함
-
모델2: 텍스트를 인식하나 흐릿함
-
모델3: 고딕 폰트는 어느정도 인식하나, cursive 폰트를 잘 인식하지 못함
-
모델4: 3번 모델보다 cursive 폰트를 잘 인식하나, 일부 뭉개짐 현상 남아있음
-
모델5: 4번 모델보다 cursive 폰트를 잘 인식하나, 자간이 좁은 부분에 뭉개짐 현상이 여전히 남아있음
-
모델6: 텍스트를 완벽하게 인식함
휴,, 이번 미션도 어찌어찌 완료다.
