컴퓨터 비전의 역사가 생각보다 깊은 것 같다. 신기하게도 이틀 전 U-Net 논문에서 봤던 스킵커넥션과 보틀넥을 다뤘다. 논문을 보고 모델을 구현해 보니까 다른 논문도 살짝 감이 오는 것 같다. 재밌네 이거!!
학습시간 09:00~02:00(당일17H/누적530H)
◆ 오늘의 깨달음
- 스킵커넥션과 보틀넥을 사용한 대표 모델 ResNet vs U-Net 차이점
| 항목 | ResNet | U-Net |
|---|---|---|
| 발표 연도 | 2015 (Microsoft Research) | 2015 (독일 의료영상 연구팀) |
| 주요 분야 | 이미지 분류 (Classification) | 이미지 세그멘테이션 (Segmentation) |
| 핵심 구조 | Residual Block + Skip Connection | Encoder-Decoder + Skip Connection |
| 특징 | 깊은 구조도 안정적으로 학습 가능 | 픽셀 단위의 정밀한 위치 복원 가능 |
| 스킵 커넥션 위치 | 네트워크 내부의 R Block 단위 | 인코더 ↔ 디코더 사이 |
| 스킵 커넥션 방식 | y = F(x) + x 형태의 덧셈 기반 연결 | 인코더와 디코더 Concatenate |
| 스킵 커넥션 목적 | Gradient 소실 방지 및 안정적 학습 흐름 제공 | 해상도 손실 보완, 원본 위치 정보 보존 |
| 보틀넥 위치 | 있음 (ResNet-50, 101 등) | 있음 (네트워크 중심부, 업샘플링 직전) |
| 보틀넥 방식 | 1x1 → 3x3 → 1x1 Conv (채널 압축-변환-복원) | MaxPool + Conv 조합 |
| 보틀넥 목적 | 연산량 감소 및 깊이 확장 | 특성 압축 및 디코더 입력으로 전달 |
◆ 학습내용
1. 컴퓨터 비전
(1) 컴퓨터 비전의 역사
- 초기(1962~1982): 경계 검출, Hough Transform, Marr의 비전 이론
- 기계학습 기반(1990~2012): SIFT, HOG, Viola-Jones, SVM, ImageNet
- 딥러닝 시대(2012~): AlexNet → VGG → ResNet → ViT → CLIP, DALL-E
- 현재: 자율주행, 의료, AR/VR, 멀티모달로 확장
(2) 주요 응용 분야
- 자율주행: 객체 탐지 + 세그멘테이션 (Tesla, Waymo)
- 의료영상 분석: 질병 탐지, 안과 이미지 분석
- 얼굴 인식: Face ID, 공항 보안
- AR/VR: SLAM, 3D 재구성 (Pokémon GO)
- 멀티모달 AI: CLIP, DALL-E 등 이미지-텍스트 융합
(3) 이미지 구조와 특징
- 픽셀과 채널: Grayscale(L채널), RGB(알파채널 존재), HSV 등
- 포맷: JPEG(손실), PNG(무손실), BMP(비압축), TIFF(고해상)
- 고차원성: 3D 텐서 구조 (W×H×C)
- 공간적 연속성: 인접 픽셀 유사도, CNN의 핵심 전제
- 데이터 왜곡: 회전·밝기·노이즈 등을 대비해 증강 학습 필요
- 사람과 컴퓨터 시각 차이: 컴퓨터는 픽셀 단위 분석
(4) 이미지 통계적 특징
- 히스토그램 분석: 밝기, 대비, 노출 정보 분석 후 평활화(Histogram Equalization)
- 텍스처 분석: GLCM(픽셀간 관계), LBP(주변 픽셀 밝기) 등
- 주파수 특성: 저주파(윤곽 특징), 고주파(엣지 특징)
- 왜곡 해결법: 정규화 + 증강
(5) 전처리와 증강
- 전처리 기법: 크기, 색상 채널, 노이즈, 밝기, 정규화, 크롭
- 증강 기법: 회전, 크롭, 플립, 확대, 밝대색채명 조정, 노이즈, 왜곡, 일부 삭제, 혼합
(6) 이미지 처리 파이프라인
- 단계: 로딩 → 전처리 → 증강 → 배치 생성 → 로딩 최적화
- 최적화: 멀티프로세스, 캐싱, prefetching
- 실무: 대규모 학습, 실시간 처리에 필수
2. 전이학습
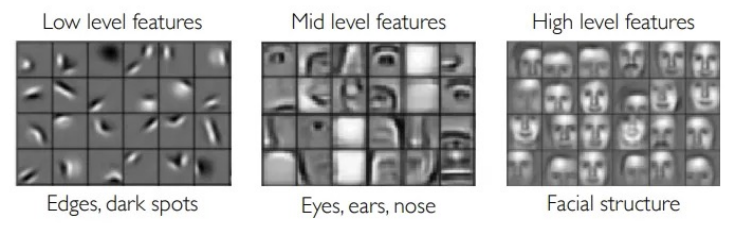
전이학습이 가능한 이유 = Low Level Features!
- 초기 레이어에서 학습된 Edge, Color, Texture 같은 기본 시각 특성들은 대부분의 이미지에서 공통적임
- 따라서 기존 모델이 학습한 저수준 특징을 다른 작업에 재사용할 수 있음
(1) 전이학습의 필요성
- 데이터 부족 해결
- 딥러닝은 대규모 데이터 필요 → 전이학습은 적은 데이터로도 높은 성능 가능
- 의료, 위성, 제조 등 특수 도메인에 특히 유리
- 학습 시간 단축
- 가중치 초기화를 하지 않고 사전학습된 값을 사용함으로써 빠른 수렴 가능
- 성능 개선
- 사전 학습 모델이 일반적인 Feature(모서리, 형태 등)를 학습했기 때문에 새로운 문제에도 효과적
- 자원 효율성
- 고성능 GPU 없이도 괜찮은 성능 도달 가능
- 특히 Edge Device나 모바일 환경에서 유용
(2) 전이학습의 종류
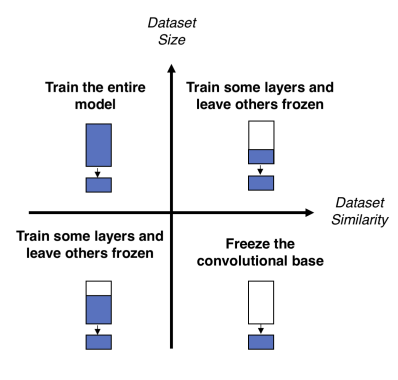
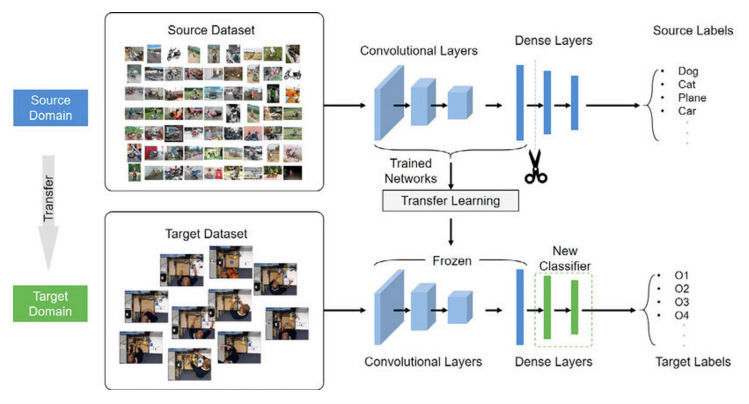
A. Feature Extraction (특징 추출)
- 사전 학습된 모델의 전체 또는 일부 Layer를 고정(freeze)
- *분류기(FC Layer)**만 새로운 데이터에 맞게 학습
- 주로 데이터가 적을 때 사용
- 장점: 빠르고 안정적, 과적합 위험 낮음
- 단점: 표현력이 제한될 수 있음
B. Fine-Tuning (미세 조정)
- 사전 학습된 모델의 일부 Layer를 학습 가능하게 설정
- 특정 Layer 이하를 freeze, 나머지는 재학습
- 주로 데이터가 많고 복잡한 문제에 사용
- 장점: 새로운 데이터셋에 최적화된 성능
- 단점: 시간이 오래 걸리고 과적합 주의 필요
(3) 전이학습의 장점과 한계
장점
- 적은 데이터로도 높은 정확도
- 빠른 학습 시간
- 다양한 데이터에 대해 일반화 가능
- 다양한 구조(ResNet, VGG 등)에 적용 가능
한계
- 도메인 차이 문제: 기존 학습 데이터와 새로운 데이터가 너무 다르면 성능 저하
- 고정된 표현 한계: Feature Extraction은 기존 특성에 의존함
- 데이터 품질 의존: Pretrained Model의 원본 데이터 품질이 낮으면 한계 발생
3. 다양한 CNN 종류
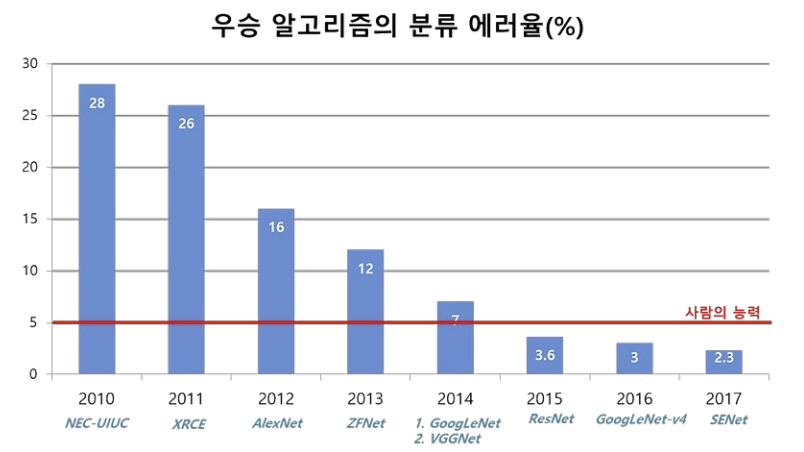
(1) AlexNet
- 발표: 2012, ILSVRC 우승
- 기존 CNN 구조에 ReLU, Dropout, GPU 병렬처리 도입
- 학습률: 0.01, 모멘텀 0.9, Dropout 0.5, weight decay 5e-4
- 주요 기여:
- ReLU 도입 → 비선형성 강화, 학습 속도 향상
- Data Augmentation 도입
- 2개의 GPU 사용 → 연산 분산
- CNN 구조를 대중화시킨 결정적 사건
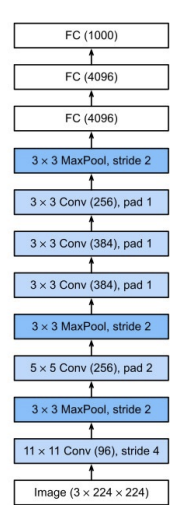
(2) VGG Net
- 발표: 2014, VGG16, VGG19 등
- 3x3 Conv 필터 반복 사용 → 깊이 증가
- 간단한 구조지만 매우 효과적
- 특징:
- 모든 Conv Layer는 동일한 필터 구조
- 층이 깊을수록 더 복잡한 특징 학습 가능
- Transfer Learning에 널리 사용됨
- 학습 세팅:
- Optimizer: SGD, momentum 0.9, Dropout 0.5
- 초기 학습률 0.01 → plateau 시 1/10로 감소
- Batch size 256
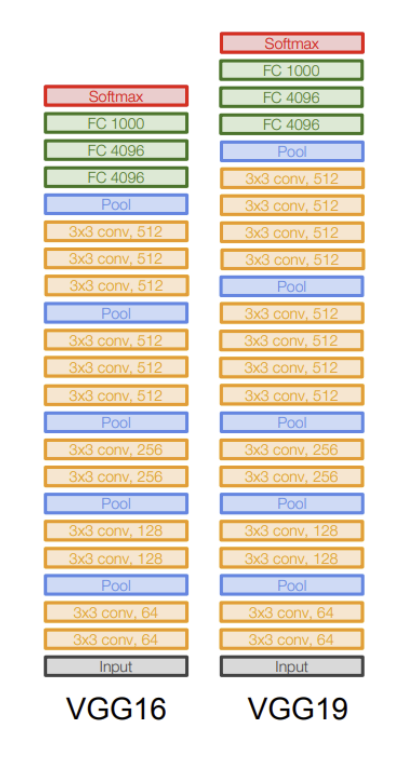
(3) GoogLeNet (Inception V1)
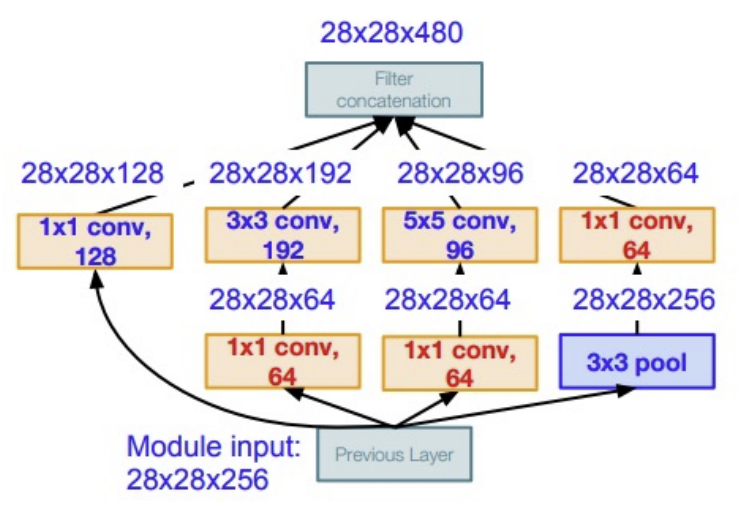
- 발표: 2014, ILSVRC 우승
- Inception Module 도입
- 다양한 필터 크기(1x1, 3x3, 5x5) + Pooling을 병렬로 구성
- 연산 효율성과 성능 동시 확보
- 특징:
- Global Average Pooling으로 FC 계층 대체
- Auxiliary Classifier로 학습 안정성 확보
- 파라미터 수 약 6.8M (AlexNet 대비 1/12)
- 깊이: 22 레이어
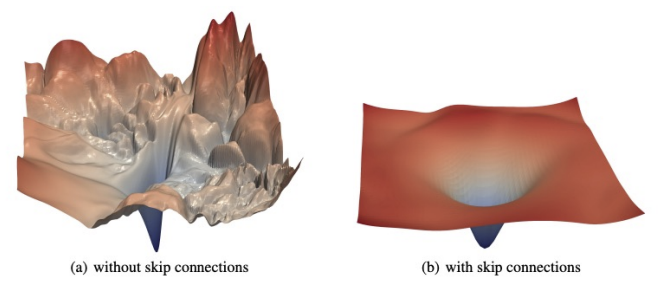
(4) ResNet
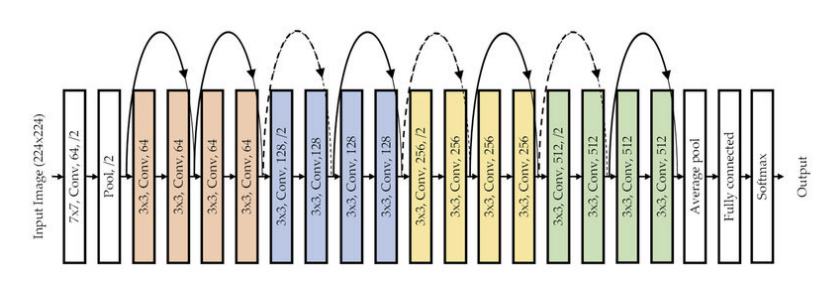
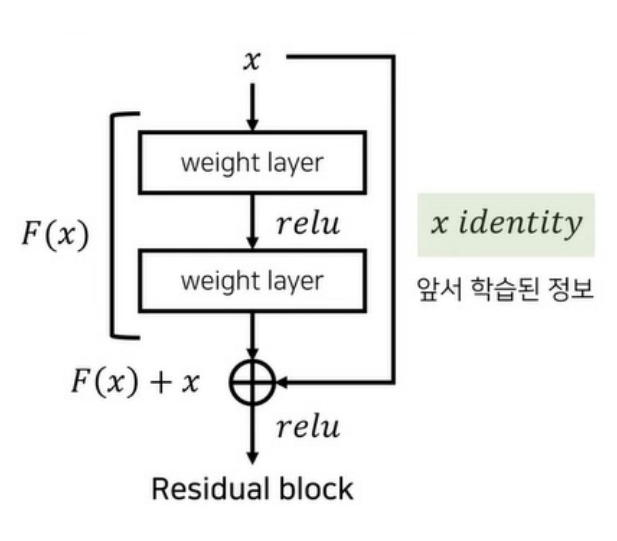
- 발표: 2015, ILSVRC 우승
- 핵심 개념: Residual Learning(잔차 학습)
y = F(x) + x→ identity mapping 학습 용이- Skip Connection으로 Gradient Vanishing 해결
- 다양한 구조:
- ResNet18, 34, 50, 101, 152
- Bottleneck 구조: 1x1 → 3x3 → 1x1 (차원 축소 → 복원)
- 학습 세팅:
- BatchNorm, Xavier 초기화
- Optimizer: SGD(momentum 0.9)
- Learning rate: 0.1 → 정체 시 감소
- Dropout 사용 안 함
4. XAI
-
XAI(설명 가능한 인공지능, eXplainable AI)는 인공지능 모델이 내린 결정이나 예측의 이유를 사람이 이해할 수 있도록 설명하는 기술과 방법
-
모델의 "블랙박스" 특성을 해소하여, 왜 특정 결과가 도출되었는지, 어떤 요인이 영향을 미쳤는지를 명확하게 보여줌으로써 신뢰성과 투명성을 높이는 것이 목표
-
사후 해석(post-hoc interpretation): 모델 학습 후, 예측 결과를 해석하는 방법(CAM, Grad-CAM, LIME, SHAP 등)
-
모델 자체 해석(ante-hoc interpretability): 처음부터 해석 가능한 모델을 설계하는 방법
(1) CAM (Class Activation Mapping)

- 구조: 마지막 Conv Layer + Global Average Pooling (GAP) 필요
- 특정 클래스가 활성화된 영역을 시각화
- 해석 방식:
Feature map * 학습된 클래스 가중치의 선형 결합 - 장점:
- 구조가 단순함 (GAP만 도입하면 됨)
- 해석 직관적
- 단점:
- GAP가 없는 모델에는 적용 불가
- 기존 구조 변경이 필요함
(2) Grad CAM (Gradient-weighted CAM)

- Gradient를 활용해 주목 영역 시각화
- 기존 CAM의 단점 보완
- 어떤 모델이든 마지막 Conv Layer만 있으면 사용 가능
- 장점:
- 구조 독립적 적용
- 의사 결정 근거 시각화 가능
- 디버깅/오류 진단 도구로 활용
- 단점:
- 역전파 기반 → 연산 복잡도 증가
- ReLU 적용으로 음의 기여 무시 (부정 영역 해석 불가)
- Gradient 노이즈에 민감할 수 있음
이론은 언제나 어렵다.

AI Engineer