에러 고치다가 하루가 끝났다...
학습시간 09:00~02:00(당일17H/누적684H)
◆ 학습내용
SSD 모델로 강아지 고양이 얼굴 탐지하기.
어제(1번~5번)에 이어 6번 부터 진행!
6. 데이터 스플릿
train_ids, val_ids = train_test_split(parser.xmls, test_size=0.2, random_state=42)
train_dataset = PetDataset(parser, train_ids, transform=transform)
val_dataset = PetDataset(parser, val_ids, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=8, shuffle=True, collate_fn=lambda x: tuple(zip(*x)))
val_loader = DataLoader(val_dataset, batch_size=8, shuffle=False, collate_fn=lambda x: tuple(zip(*x)))
어제 만든 파서 클래스와 데이터셋 클래스를 이용해 스플릿했다.
평소와 다른 점은 람다 함수를 사용했다는 것.
람다는 약간 생소했는데, 이번 코드 작성하면서 어느정도 이해가 됐다.
# 1번 사용법(람다 X)
def collator(batch):
return tuple(zip(*batch))
collate_fn=collator
# 2번 사용법(람다 O)
collate_fn=lambda x: tuple(zip(*x))
강사님은 DataLoader를 위해 함수를 하나 새롭게 만들었는데, 위 두 개의 코드가 정확히 같은 기능을 한다.
함수명 대체
collator(batch): == lambda x:
파라미터명 대체
tuple(zip(batch)) == tuple(zip(x))
여기서 lambda가 함수명을 대체하는 것이고, x가 괄호 안에 들어간 파라미터(batch)를 대체하는 것이다.
딱 1회만 사용할 간단한 함수라면 확실히 람다 함수가 가독성이 좋은 것 같다.
7. Train set 시각화
일단 이미지와 얼굴좌표가 잘 매핑되어 있는지 확인해야 한다.
import matplotlib.pyplot as plt
import matplotlib.patches as patches
import random
img, bboxes = train_dataset[random.randint(0, len(train_dataset)-1)]
plt.figure(figsize=(6,6))
plt.imshow(img.permute(1,2,0))
ax = plt.gca()
for bbox in bboxes:
xmin, ymin, xmax, ymax = bbox
rect = patches.Rectangle((xmin, ymin), xmax - xmin, ymax - ymin,
linewidth=2, edgecolor='red', facecolor='none')
ax.add_patch(rect)
plt.title("Image + BBOX")
plt.axis('off')
plt.show()처음 보는 gca(), patches.Rectangle() 함수를 이용해서 시각화 코드를 만들었다.

??? 근데 뭔가 이상하다? BBOX도 이상한 곳에 찍혔고, Warning까지 떴다.
WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-2.117904..2.64].
아 정규화를 해서 뜬 경고인 것 같다.
transform = v2.Compose([
v2.Resize((300, 300)),
v2.ToImage(),
v2.ToDtype(torch.float32, scale=True),
# v2.Normalize(mean= [0.485, 0.456, 0.406],
# std=[0.229, 0.224, 0.225])
])노말라이즈 부분 잠깐 주석처리... ㅎㅎ

이제 경고는 안 뜬다. 근데 BBOX가 이상한 곳에 찍혀있다.
뭐가 잘못된 거지????

하나만 그런 게 아니고 전부다 박스가 이상한 곳에 있다.
그렇다면 이건 아예 매핑이 잘못되었다는 뜻이다.
처음 만들어본 파서 클래스가 틀렸나...?
.....ㅠㅠ
- 이미지만 resize하면 bbox랑 위치 어긋남
- 이미지 + bbox 같이 변형하려면 Albumentations 사용
원인을 발견한 것 같다. 아무래도 SSD 300 모델 인풋사이즈에 맞게 resize한 게 문제가 된 것 같다.
하긴, 상식적으로 생각해도 그렇다. 원본 이미지에 맞게 좌표가 찍혀있는데, 좌표는 냅두고 이미지 크기만 변경하면 기존 찍혀있던 좌표가 새로운 이미지를 제대로 인식하지 못하는 게 맞지.
Albumentations 사용하라고 하는데 이게 뭐지? 이것도 처음 본다.
오늘 왜 이렇게 처음 보는 게 많은 거니...
8. Albumentations에 관하여
(1) 코드 구조
조금 찾아보다가 이건 제대로 이해하고 넘어가야할 것 같아서 챕터를 나눴다.
일단 라이브러리를 호출해야 한다.
!pip install albumentations
import albumentations as A
from albumentations.pytorch import ToTensorV2albumentations은 주로 A로 정의하는 듯하다. 이 라이브러리의 ToTensorV2 라는 함수가 필요하다. 윽 이것도 처음 본다.
게다가 코드 예시를 보니 transform 변수 안에 들어가는 파라미터도 다르다고 한다.
# torchvision.transforms.v2 코드 예시
transform = v2.Compose(
[
v2.Resize(...),
v2.ToImage(),
v2.ToDtype(torch.float32, scale=True),
v2.Normalize(...)
]
)
# albumentations 코드 예시
transform = A.Compose(
[
A.Resize(...),
A.Normalize(...),
ToTensorV2()
], bbox_params=... # ← 새로운 부분
)지금 나는 v2.Compose 형식으로 하고 있는데, BBOX가 있을 때는 A.Compose를 사용해야 한다. 그리고 bbox_params 라는 파라미터까지 추가로 붙여줘야 한다.
bbox_params=A.BboxParams(format='pascal_voc', label_fields=['labels']))
보통 bbox_params은 이런 느낌이라고 한다. 근데 이 format='' 부분이 데이터셋마다 바뀌는 것 같다.
format이란 BBOX를 나타내는 방식이다.
아하 그렇군.
현재 내가 하고 있는 Oxford-IIIT Pet Dataset의 xml에서는 BBOX 좌표가 xmin 101, ymin 35, xmax 231, ymax 130 이렇게 적혀 있다.
이게 pascal_voc format이라고 한다.
또 어떤 포맷이 있는지 찾아보자.
(2) format 종류
주로 사용하는 포맷은 3가지 종류가 있고, 아래와 같다.
A. format='pascal_voc'
(xmin, ymin)
●───────────────┐
│ │
│ object │
│ │
└───────────────●
(xmax, ymax)
포맷: [xmin, ymin, xmax, ymax]
예시: [30, 60, 150, 180]
→ 좌상단, 우하단 (픽셀 절대좌표)
B. format='yolo'
▲ ↓ height
│
→ width │
◀────────●────────▶
│ object
│
▼
중심 좌표 (x_center, y_center)
포맷: x_center, y_center, width, height
예시: [0.30, 0.40, 0.40, 0.40]
→ 중심, 폭, 높이 (비율 0~1)
비율 구하는 공식은 아래와 같음
만약 300*300 이미지 BBOX의 좌상단 우하단 좌표가 아래와 같다면
좌표: xmin 30, ymin 60, xmax 150, ymax 180
- 중심 좌표 계산
x_center = (xmin + xmax) / 2 = (30 + 150) / 2 = 90
y_center = (ymin + ymax) / 2 = (60 + 180) / 2 = 120
- 폭 높이 계산
width = xmax - xmin = 150 - 30 = 120
height = ymax - ymin = 180 - 60 = 120
- 비율 계산
x_center = 90 / 300 = 0.30
y_center = 120 / 300 = 0.40
width = 120 / 300 = 0.40
height = 120 / 300 = 0.40
흠... ㅎㅎ YOLO 포맷은 평생 만나지 않았으면 좋겠네 ^^
C. format='coco'
(x, y) → width
●───────────────┐ ↓ height
│ │
│ object │
│ │
└───────────────┘
포맷: [x, y, width, height]
예시: [30, 60, 120, 120]
→ 좌상단, 폭, 높이 (픽셀 절대좌표)
코코 포맷이 제일 이해하기 쉽고 간편한 것 같다.
9. Train set 시각화(재시도)
import albumentations as A
from albumentations.pytorch import ToTensorV2
transform = A.Compose([
A.Resize(300, 300),
A.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
ToTensorV2()
], bbox_params=A.BboxParams(format='pascal_voc', label_fields=['labels']))
albumentations 라이브러리를 사용해서 코드를 약간 변경했다.
label_fields=['labels'] 이부분은 내 마음대로 이름을 지정해도 괜찮다고 함.
다시 시각화 돌려보자.
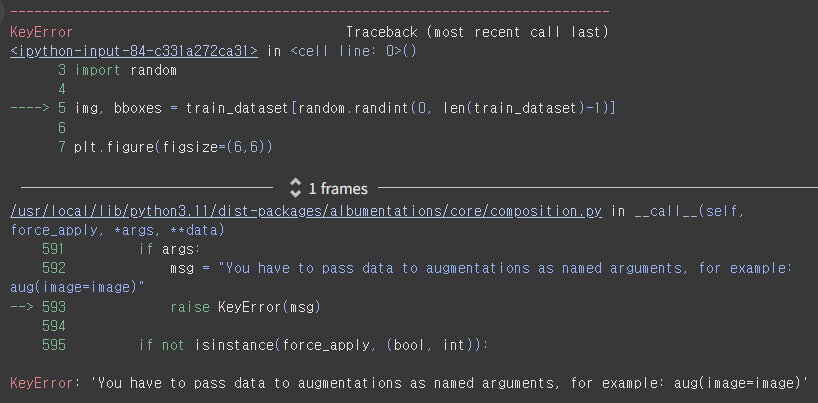
ㅎㅎ 에러가 떴다.
그래, 차라리 다행이다. 불확실한 상황에서 에러 없이 돌아가는 것보단 낫다.
적어도 에러가 뜨면 어디가 문제인지 알 수 있으니까.
----> 5 img, bboxes = train_dataset[random.randint(0, len(train_dataset)-1)]
이 부분이 문제라고 한다. 변수 선언 혹은 라벨링이 안 되어 있는 것 같은데,,,
아무래도 transform만 A.Compose로 변경해서는 해결할 수 없는 문제인 듯하다.
class PetDataset(Dataset):
def __init__(self, parser, img_ids, transform=None, label_map=None):
self.parser = parser
self.img_ids = img_ids
self.transform = transform
self.label_map = label_map or {'cat': 0, 'dog': 1}
def __len__(self):
return len(self.img_ids)
def __getitem__(self, idx):
img_id = self.img_ids[idx]
image = self.parser.get_img(img_id)
bbox_label_pairs = self.parser.get_bboxes(img_id)
bboxes = [b for b, _ in bbox_label_pairs]
labels = [self.label_map[lbl] for _, lbl in bbox_label_pairs]
if self.transform:
transformed = self.transform(
image=np.array(image),
bboxes=bboxes,
labels=labels
)
image = transformed['image']
bboxes = torch.tensor(transformed['bboxes'], dtype=torch.float32)
labels = torch.tensor(transformed['labels'], dtype=torch.int64)
target = {
'boxes': bboxes,
'labels': labels
}
return image, targetDataset 코드를 수정했다. __getitem__ transform 부분에 좌표와 라벨 정보를 추가했다.

으아~! 또 에러다. 이번엔 값 개수가 안 맞는 것 같다.
def get_bboxes(self, img_id):
tree = ET.parse(os.path.join(self.ann_dir, img_id + '.xml'))
root = tree.getroot()
results = []
for obj in root.findall('object'):
bbox = obj.find('bndbox')
coords = [int(bbox.find(t).text) for t in ['xmin','ymin','xmax','ymax']]
label = obj.find('name').text
results.append((coords, label))
return resultsget_bboxes() 함수 부분에 빠진 게 있었나 보다.

그렇다. 오브젝트 노드에서 'name' 정보를 가져와야 냥냥인지 멍멍인지 구분이 가능한 것이다.
def visualize_sample(dataset):
img, target = dataset[random.randint(0, len(dataset)-1)]
bboxes = target['boxes']
plt.figure(figsize=(6,6))
plt.imshow(img.permute(1,2,0))
ax = plt.gca()
for bbox in bboxes:
xmin, ymin, xmax, ymax = bbox.tolist()
rect = patches.Rectangle((xmin, ymin), xmax - xmin, ymax - ymin,
linewidth=2, edgecolor='red', facecolor='none')
ax.add_patch(rect)
plt.title("Image + BBOX")
plt.axis('off')
plt.show()
visualize_sample(train_dataset)변경하는 김에 시각화 코드를 함수 형태로 바꿨다.
정규화를 잠깐 풀고 다시 실행해보자.


오 드디어 나왔다..!
쭉 보니 Train set 좌표는 잘 매핑된 것 같다.
이제 모델과 앵커를 정의할 차례다.
산넘어 산이네 정말.
10. 모델 생성
이번에 내가 선택한 모델은 SSD 300이다.
파이토치 공홈에서 링크 찾음
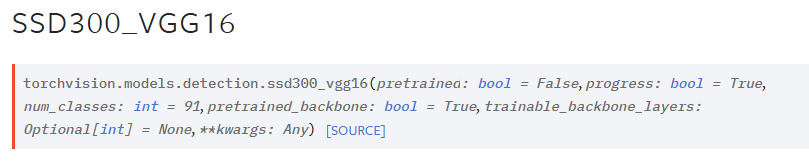
이걸 코드블럭에 복붙하면,
torchvision.models.detection.ssd300_vgg16(
pretrained = False,
progress = True,
num_classes = 91,
pretrained_backbone = True,
trainable_backbone_layers = None,
**kwargs: Any
)이런 형태가 된다.

각 파라미터가 어떤 역할을 하는지도 나와있어서 한번 읽어봤다.
흠,,, 뭔가 설정해야할 게 많은 것 같네...
from torchvision.models.detection import ssd300_vgg16
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model_SSD300 = ssd300_vgg16(pretrained=True)
model_SSD300.to(device)
model_SSD300모르겠고 일단 어떻게 생겼는지 함 보자 ^^
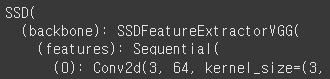

뭐가 엄청 길게 나오긴 했는데, 핵심 구조는 backbone과 head인 것 같다.
전이학습 때 배운 ResNet 구조로 비교해 보면,
backbone == features
head == classifier
일 것이다. 아마도!?

근데 이건 또 뭐지? 모델 안에 transform이 정의되고 있고 그 안에 정규화 수치가 들어가 있다.
그럼 내가 정의한 transform에서 정규화할 필요가 없다는 뜻인가? 심지어 내가 찾은거랑 수치도 다르네.
transform = A.Compose([
A.Resize(300, 300),
ToTensorV2()
], bbox_params=A.BboxParams(format='pascal_voc', label_fields=['labels']))일단 내 정규화 코드는 삭제...
다음은 앵커를 정의할 차례다.
backbone.out_channels = 512
anchor_generator = rpn.AnchorGenerator(
sizes = ((32, 64, 128, 256, 512),),
aspect_ratios = ((0.5, 1.0, 2.0),))
roi_pooler = ops.MultiScaleRoIAlign(
featmap_names = ["0"],
output_size = (7, 7),
sampling_ratio = 2
)
model = FasterRCNN(
backbone = backbone,
num_classes = 3,
rpn_anchor_generator = anchor_generator,
box_roi_pool = roi_pooler
).to(device)강사님은 이런 식으로 앵커를 정의하고 모델을 호출했다.
torchvision.models.detection.ssd300_vgg16(
pretrained = False,
progress = True,
num_classes = 91,
pretrained_backbone = True,
trainable_backbone_layers = None,
**kwargs: Any
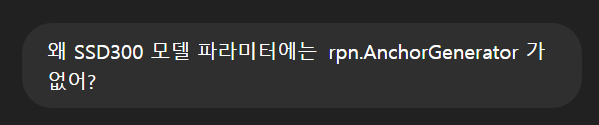
)근데 SSD300 파라미터에는 rpn_anchor_generator 라는 파라미터가 없다.
그럼 앵커를 어떻게 정의하지????
내가 직접 만들어야하나??????
모델 안에 앵커가 들어가 있나??

모델 내부에 anchor_generator 라는 코드가 있다. 이건가? 뭐지...
도대체 뭐가 어떻게 된 거냐!!!!!
도와줘요 지선생,,,



zzㅋㅋㅋㅋㅋㅋㅋㅋ
SSD는 이걸 자동으로 해버린다구!?!?
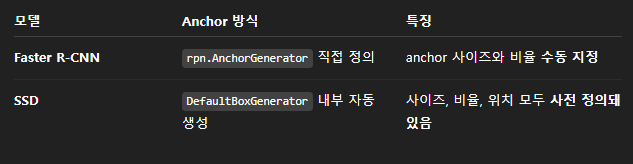
- SSD는 RPN 없이, 모든 위치에서 고정된 anchor(default box)를 기준으로 바로 클래스 + bbox offset을 예측함
아 살짝 감이 잡힌다.
나는 그냥 모델 내부에 하드코딩된 앵커를 가져다 쓰기만 하면 되는 것 같다.
model_SSD300 = ssd300_vgg16(
pretrained = True,
num_classes = 3,
pretrained_backbone = True,
trainable_backbone_layers = None,
).to(device)자! 그럼 다시 모델을 불러와보자!!
클래스만 91개에서 3개로 변경했다.(개+고양이+배경)
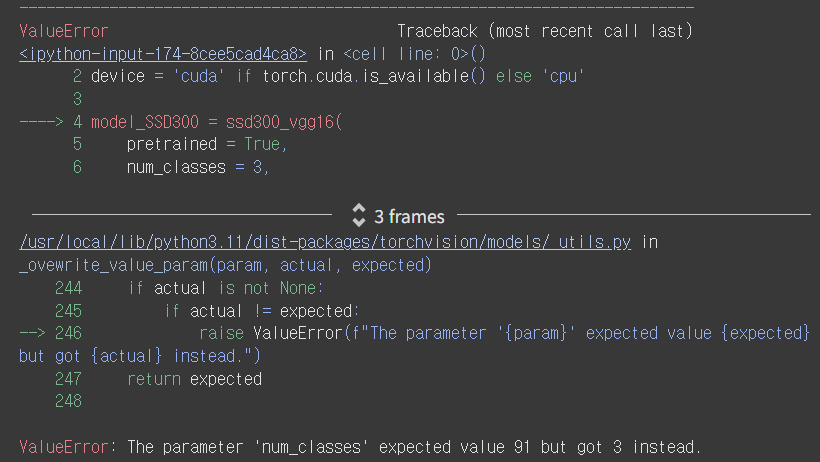
ㅠㅠ 또 왜요?? 저한테 왜 그러시는 거예요 정말...
num_classes에 91이 와야하는데 3이 와서 문제가 됐다고 한다.
????? 그럼 클래스 수를 어떻게 변경하라는 거야?
오늘 진짜 갈수록 태산이네.
도와줘요 지선생,,,,


ㅋㅋㅋㅋ 이딴 거 없다니,,,
암튼 지선생 말에 따르면, SSD 모델은 클래스 분류하는 레이어가 마지막 레이어 하나에 몰빵되어 있지 않다고 한다.
그래서 ResNet이나 DenseNet 처럼 단순히 파라미터값 하나만 변경해서 사용할 수가 없는 것이다.
그럼 난 이제 뭘 해야하지???
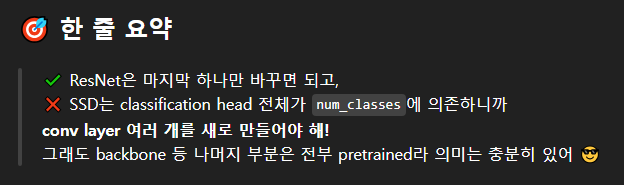
그렇다. 나는 이제부터 head 부분을 새로 만들어야 하나 보다.
그래도 backbone은 그대로 사용할 수 있는 것 같아서 다행이다.
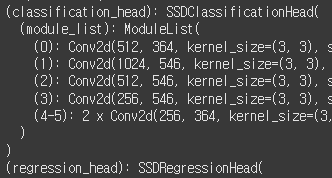
근데 head 부분도 classification head가 있고 regression head가 있다. 둘 다 만들어야 하는 건가??
| Head 종류 | 출력 수 계산법 | 왜 건드리는지? |
|---|---|---|
| classification_head | num_anchors × num_classes | 클래스 수에 따라 바뀜 → 수정 필요! |
| regression_head | num_anchors × 4 | BBOX 꼭지점 수 → 수정 불필요! |
아하 그렇구만
classification_head 분류할 클래스 수에 맞게 변경해야 한다.
regression_head 는 BBOX의 꼭지점 수이기 때문에 언제나 4로 고정이다.
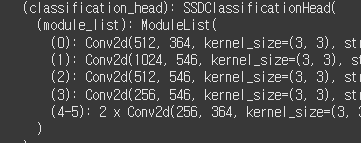
모델 정보를 다시 보자. classification_head에 6개의 conv 레이어가 있다.
(512, 364)에서 왼쪽 껀 인채널일 텐데, 오른쪽 꺼는 뭐지?
아웃채널 아닌가?
아웃채널이라면 수치가 왜 저렇지??
SSD 모델 classification_head의 아웃풋 채널 수 공식
num_anchors_per_location × num_classes
이라고 한다.
클래스는 91개니까 앵커수만 구하면 되는데,,,
model.anchor_generator.num_anchors_per_location()num_anchors_per_location() 함수를 쓰면 된다고 한다.

나왔다!
앵커는 총 30개고, 6개 레이어에 분포되어 있다. 조금 더 보기좋게 확인해 보면,
for idx, n in enumerate(model.anchor_generator.num_anchors_per_location()):
print(f"Layer {idx+1} = {n} anchors")
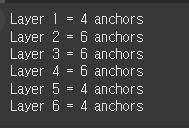
레이어 별로 앵커 수가 지정되어 있다.
(0): Conv2d(512, 364, .....
(1): Conv2d(1024, 546, .....
(2): Conv2d(512, 546, .....
(3): Conv2d(256, 546, .....
(4): Conv2d(256, 364, .....
(5): Conv2d(256, 364, .....
아웃풋 채널에 방금 구한 앵커 수를 나누어 보자.
364 / 4 = 91
546 / 6 = 91
546 / 6 = 91
546 / 6 = 91
364 / 4 = 91
364 / 4 = 91
아웃채널에 앵커 수를 나누니까 모든 레이어에서 91이 나온다. 이건 이 모델의 클래스 수다.
이제 아웃채널 수치가 이해된다.
그렇다면 역산을 해서, 나는 클래스가 3개니까 (앵커 수 x 3)한 값을 아웃채널 자리에 넣으면 된다는 소리다.
my_classification_head = nn.ModuleList([
nn.Conv2d(512, 4*3, 3, 1, 1),
nn.Conv2d(1024, 6*3, 3, 1, 1),
nn.Conv2d(512, 6*3, 3, 1, 1),
nn.Conv2d(256, 6*3, 3, 1, 1),
nn.Conv2d(256, 4*3, 3, 1, 1),
nn.Conv2d(256, 4*3, 3, 1, 1),
])오케이 classification_head 완성이다. 이걸 모델에 붙여보자.
이번엔 제발 잘 되기를...!
model_SSD300.head.classification_head.module_list = my_classification_head
model_SSD300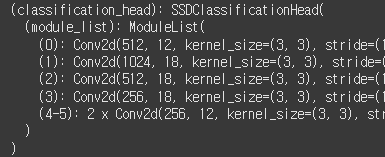
하... 드디어 들어갔다!! ㅠㅠㅠ 감사합니다
이제 드디어 드디어 학습을 돌릴 차례인데, 하루가 다 끝났다.
^^.. 뭐 하루종일 에러만 보다가 끝났네.
이번 주말은 힘든 주말이 되겠구만....
