이미지 생성이 간단한 작업이 아니었구나. 지금까지도 산 넘어 산이었는데, 엄청 큰 산을 만난 것 같다.
학습시간 09:00~02:00(당일17H/누적768H)
◆ 학습내용
1. Generative Modeling
(1) 생성 모델링이란?
-
주어진 데이터셋과 유사한 새로운 데이터를 생성하는 모델링 기법
-
데이터 분포를 학습하여 유사하지만 실제 존재하지 않는 샘플 생성
-
생성 모델:
P(x)를 모델링. 새로운 샘플 생성이 목적 -
판별 모델:
P(y|x)를 모델링. 입력의 클래스 예측이 목적
(2) 판별 모델
(Discriminative Model)
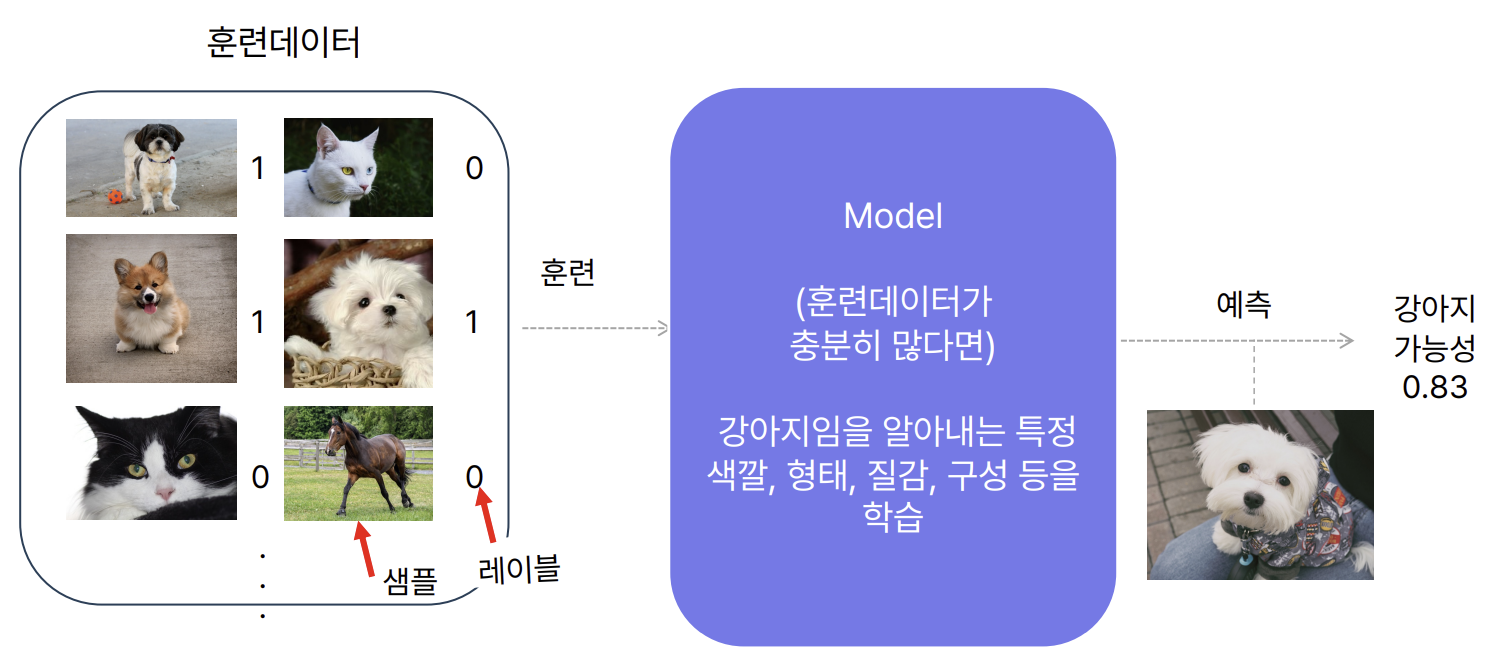
-
입력 샘플
x에 대해, 정답 레이블y의 확률 분포P(y|x)를 추정 -
입력값
x와 레이블y가 모두 필요 -
다양한 샘플과 정답쌍을 통해 클래스별 특징(색, 질감, 구조 등)을 학습
-
특정 입력
x에 대해y일 확률을 출력 (예: 강아지일 확률 0.83)
(3) 생성 모델
(Generative Model)
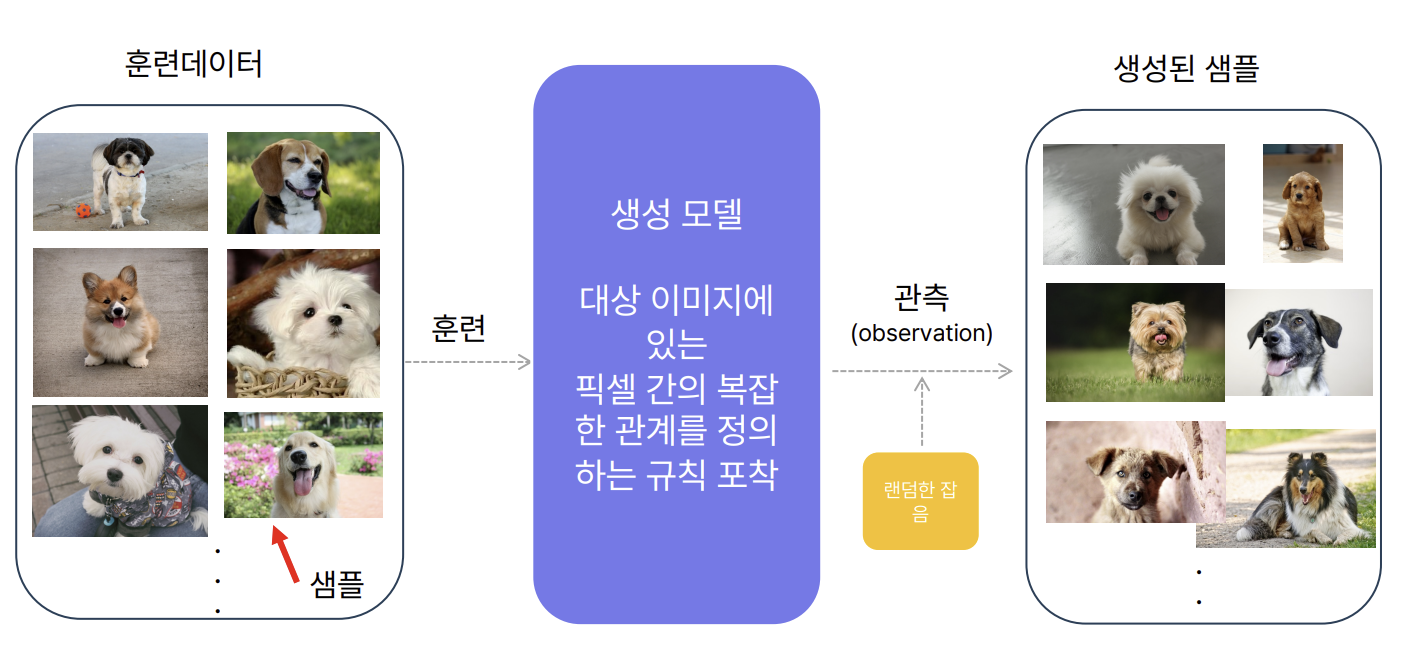
-
특정 샘플
x가 등장할 확률P(x)를 모델링 -
관측되지 않은 새로운 샘플을 생성하는 것이 목적
-
라벨이 없는 단일 클래스 샘플을 기반으로 학습
-
픽셀 간 규칙을 학습하여 새로운 이미지 생성
-
랜덤 잡음 입력 → 데이터 생성
-
단순한 평균값 계산은 생성이 아니라 요약에 불과함
-
진정한 생성 모델은 ‘규칙 기반 샘플링’이 가능해야 함
2. 표현 학습 & 잠재 공간
(1) 표현 학습
(Representation Learning)

-
원본 데이터의 고차원 복잡성을 낮은 차원 공간에서 의미 있게 표현하는 기법
-
모델이 스스로 중요한 특징(feature)을 추출하여 더 효과적인 학습 가능
-
표현은 사람이 설계하지 않고 자동으로 학습
-
잠재 공간의 좌표처럼 간결한 구조로 표현 가능
-
좌표만으로도 유사 이미지를 그릴 수 있을 정도의 정보 포함
-
픽셀 단위의 수치 나열 (예: 540x720 RGB값)
-
사람 얼굴 묘사: “안경을 썼고, 웃고 있으며, 마른 체격”
(2) 잠재 공간
(Latent Space)
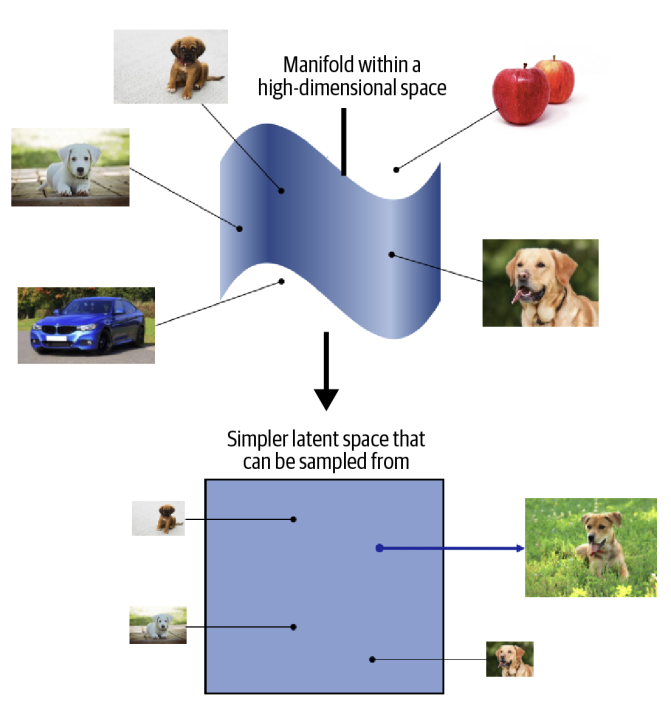
-
대부분의 생성 모델은 잠재공간 개념을 기반으로 작동
-
고차원 데이터에서 의미 있는 특징을 추출하여 저차원 잠재공간에 매핑한 뒤, 이 공간에서 샘플링 후 복원
-
관측된 데이터의 분포를 학습하고, 이 분포를 통해 유사하지만 새로운 데이터를 생성하는 것이 목적
-
샘플 x를 관측할 확률 P(x)를 추정하는 것이 생성 모델링의 핵심 프레임워크
-
표현 학습은 원본 데이터로부터 의미 있는 특징을 추출하는 과정
-
잠재공간은 이러한 특징들이 구조적으로 매핑되는 공간
-
따라서 잠재공간은 단순한 축소 공간이 아니라, 생성 모델이 작동하는 주 무대라고 할 수 있음
3. 생성 모델링 종류
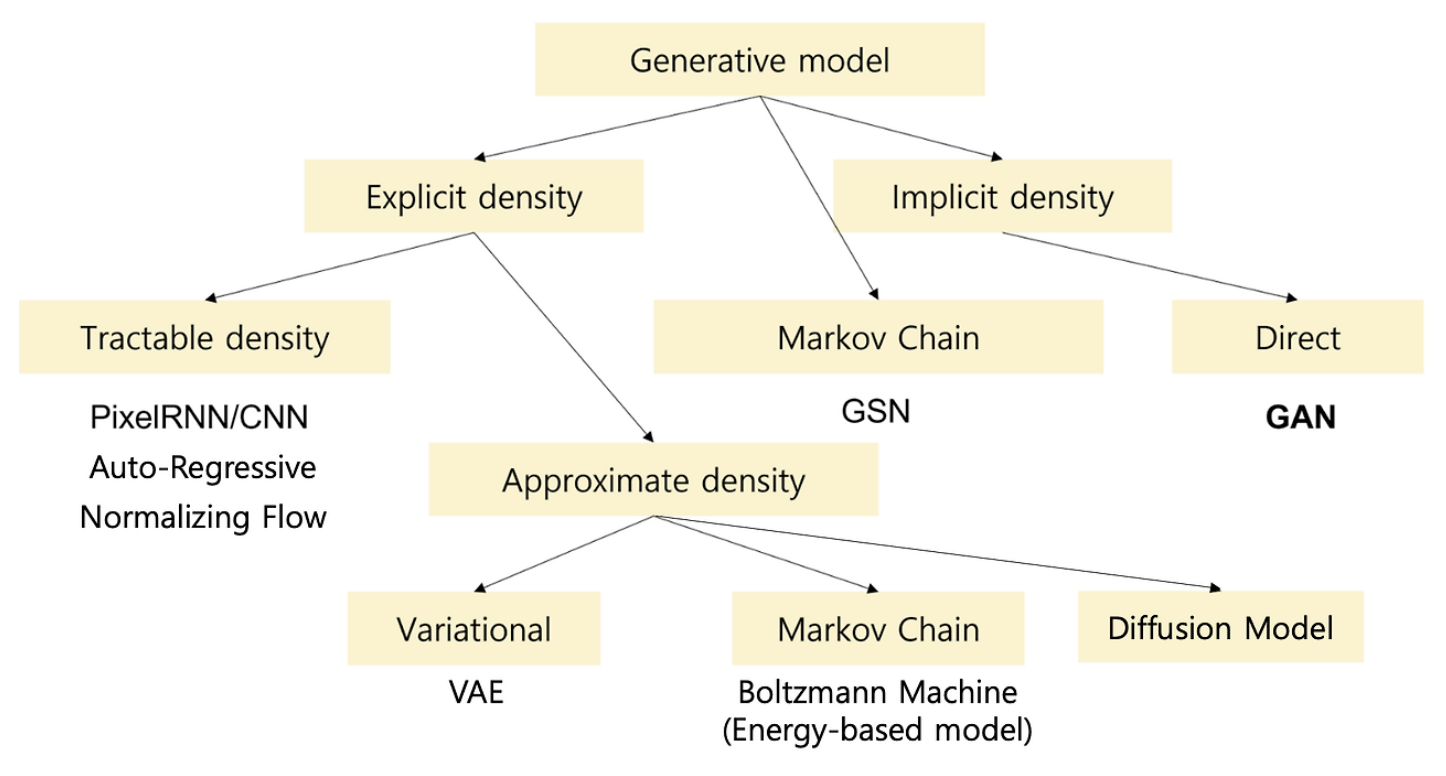
| 모델 | 분포 정의 | 확률 계산 | 생성 구조 / 접근 방식 | 비고 |
|---|---|---|---|---|
| PixelRNN / CNN | Explicit | Tractable | Auto-Regressive | 순차적 픽셀 예측 |
| Auto-Regressive | Explicit | Tractable | 조건부 확률 기반 생성 | NLP/시계열에서도 사용 |
| Normalizing Flow | Explicit | Tractable | 가역적 확률변환 구조 | 복잡한 분포 정밀 모델링 |
| VAE | Explicit | Approximate | Variational (잠재 분포 추정) | 확률 기반 AE |
| Boltzmann Machine | Explicit | Approximate | Markov Chain 기반 샘플링 | 에너지 기반 모델 |
| Diffusion Model | Explicit | Approximate | 점진적 노이즈 제거 | 최근 이미지 생성 강자 |
| GSN | Implicit | - | Markov Chain 기반 전이 구조 | 확률 흐름 사용 |
| GAN | Implicit | - | Direct 샘플링 | 생성자-판별자 대립 학습 |
4. VAE
(Variational AutoEncoder)
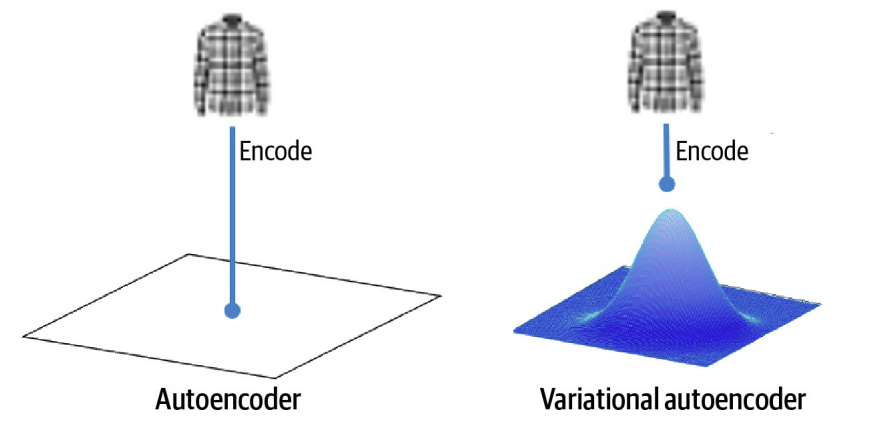
(1) 개념 및 원리
- AutoEncoder를 기반으로 한 확률 생성 모델
- 입력을 평균(μ)과 표준편차(σ)로 구성된 정규분포로 인코딩
- 해당 분포에서 샘플링한 z값으로 새로운 데이터 생성 가능
(2) 주요 구성 요소
A. 인코더
- 입력 데이터를 잠재 공간의 정규분포로 매핑
- 평균과 표준편차를 예측함
B. 디코더
- 샘플링된 z값으로부터 원본과 유사한 데이터를 복원
- 이미지, 텍스트 등 다양한 데이터 복원이 가능
(3) 기술적 특징
- 재파라미터화 트릭 사용: z = μ + σ·ε (ε ~ N(0,1))
- 샘플링 과정에서도 역전파 가능하게 함
(4) 손실 함수 구성
- 재구성 손실: 입력과 복원값의 차이 (예: MSE)
- 정규화 손실: 잠재 분포가 N(0, I)에 가깝도록 KL Divergence 적용
(5) 장점 및 한계
- 연속적이고 해석 가능한 잠재 공간 형성
- 새로운 샘플 생성 가능
- 단점: 재구성 품질이 낮고, KL 손실과 균형 조절 필요
5. GAN
(Generative Adversarial Network)
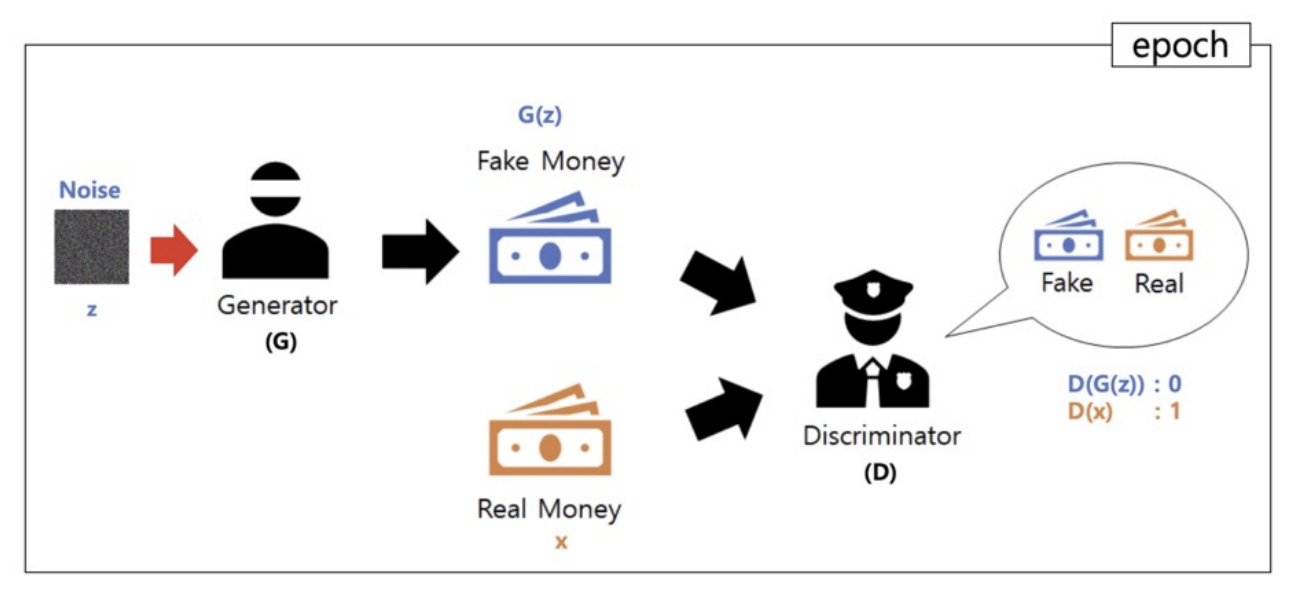
(1) 개념 및 원리
- 생성자(G)와 판별자(D)가 서로 경쟁하며 학습하는 생성 모델
- G는 가짜 데이터를 만들고, D는 진짜/가짜를 구분함
(2) 학습 구조
A. 생성자 (G)
- 랜덤 노이즈 벡터 z로부터 현실적인 데이터 생성
B. 판별자 (D)
- 입력 데이터가 실제(real)인지 생성(fake)인지 판단
(3) 손실 함수
- Minimax 형태의 경쟁 구조
- 생성자: D(G(z))가 1에 가깝도록 학습
- 판별자: D(x)는 1, D(G(z))는 0이 되도록 학습
(4) 장점 및 한계
- 장점: 매우 현실적인 이미지 생성 가능
- 한계: 학습 불안정, 모드 붕괴, 손실 모니터링 어려움
6. DCGAN
(Deep Convolutional GAN)
(1) 개념 및 목적
- GAN 구조에 CNN 기반 네트워크를 도입한 확장 모델
- 안정적인 학습과 고품질 이미지 생성을 목표로 함
(2) 구조적 제약
A. Pooling 미사용
- Stride convolution으로 다운/업 샘플링 수행
B. Batch Normalization
- 각 층 입력의 분포를 정규화하여 학습 안정성 향상
C. Fully Connected Layer 제거
- 공간 정보 보존 및 파라미터 수 절감
(3) 네트워크 구성
A. Generator
- 노이즈 z를 ConvTranspose 연산으로 점진적으로 해상도 증가
- 출력층에는 Tanh 활성화 함수 사용
B. Discriminator
- 입력 이미지에 Conv → Flatten → Sigmoid 구성
- LeakyReLU 활성화 함수 사용
(4) 장점
- 이미지 품질 및 해상도 개선
- 학습 안정화
- 표현 학습에 활용 가능
7. cGAN
(Conditional GAN)
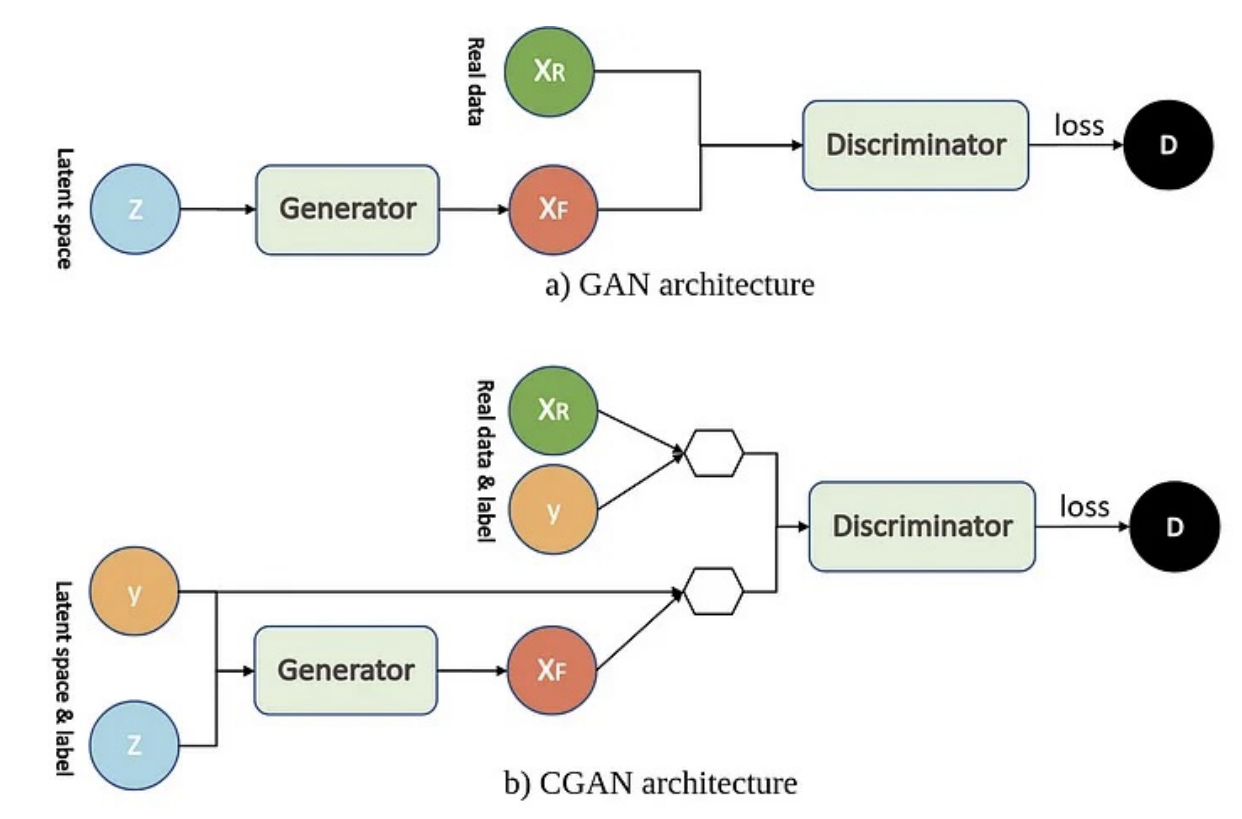
(1) 개념 및 구조
- 조건 기반 생성이 가능한 GAN의 확장형
- 클래스 라벨, 텍스트 등 조건 정보를 G와 D에 함께 입력
(2) 입력 구조
A. Generator
- z와 y를 결합하여 조건에 맞는 가짜 샘플 생성
B. Discriminator
- 데이터와 조건 y가 일치하는지 여부를 판별
(3) 목적 함수
- 조건 정보 y를 포함한 Minimax 손실 구조
- G: D(G(z|y))를 1로 만들도록 학습
- D: 진짜/가짜 + 조건 일치 여부 판단
(4) 장점 및 한계
- 장점: 속성 제어 가능, 다양한 응용 가능
- 한계: 조건 결합 방식의 복잡성, GAN의 불안정성 유지
8. Pix2Pix
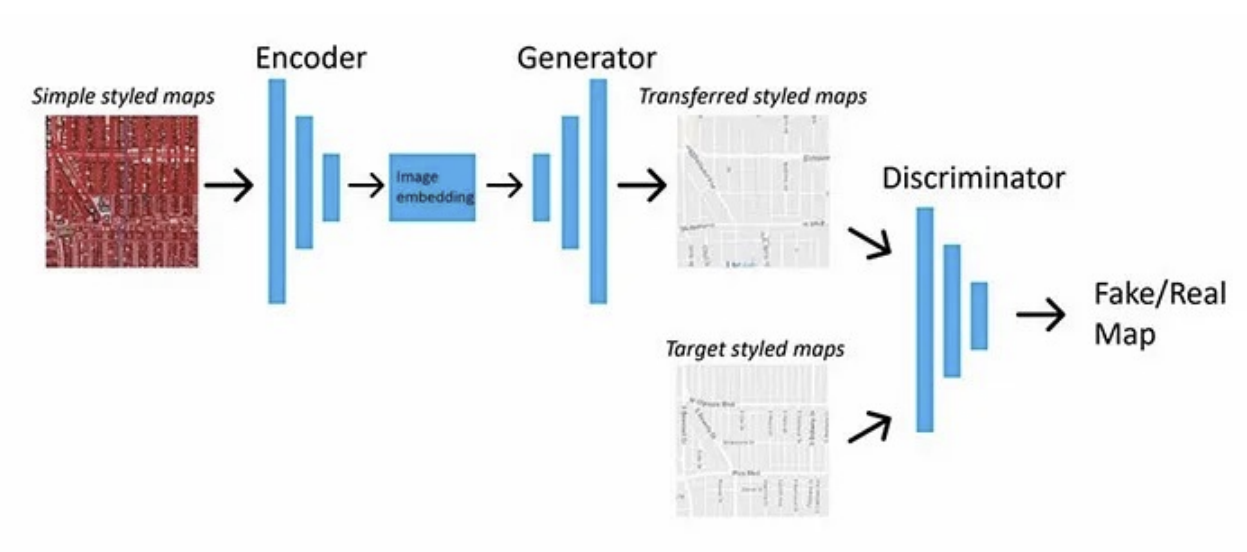
(1) 개념 및 응용
- 이미지-투-이미지 변환 문제 해결을 위한 cGAN 기반 모델
- 예: 스케치 → 사진, 라벨맵 → 현실 이미지 등
(2) 주요 구조
A. Generator
- U-Net 구조
- 인코더-디코더 연결 시 Skip Connection 사용
B. Discriminator
- PatchGAN 구조: 전체 이미지 대신 패치 단위 판별
(3) 손실 함수 구성
- Adversarial Loss: D를 속이기 위한 생성자 학습
- L1 Loss: 출력 이미지와 정답 이미지 간의 픽셀 차이 최소화
(4) 장점 및 한계
- 장점: 고해상도, 세밀한 변환 가능, 손실 자동 학습
- 한계: 학습 불안정, 결정론적 출력, 조건 복잡도에 따라 품질 저하
