다른 건 몰라도 이 논문만큼은 양치질하듯 들여다봐야겠다. 일단 주말까지 계속 업데이트 해야지!
학습시간 09:00~02:00(당일17H/누적1147H)
◆ 학습내용

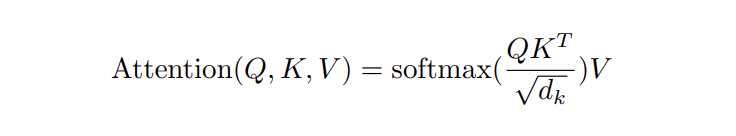
딥러닝 역사의 한 획을 그은 < Attention Is All You Need > 논문 탐구
핵심 키워드
| 항목 | 설명 | 구성 요소 | 주요 기능 |
|---|---|---|---|
| 인코더 | 입력 시퀀스를 연속적인 표현 시퀀스로 변환 | 인코더 스택 (N=6개 레이어) | 입력 문맥 정보 추출 및 변환 |
| 인코더 레이어 | 인코더 스택의 각 단위 레이어 | 멀티 헤드 어텐션, 피드포워드 네트워크 | 각 서브 레이어 후 잔차 연결 & 레이어 정규화 적용 |
| 디코더 | 인코더의 출력을 받아 타겟 시퀀스를 생성 | 디코더 스택 (N=6개 레이어) | 자동 회귀 방식으로 다음 토큰 예측 |
| 디코더 레이어 | 디코더 스택의 각 단위 레이어 | 마스크드 멀티 헤드 어텐션, 멀티 헤드 어텐션, 피드포워드 네트워크 | 각 서브 레이어 후 잔차 연결 & 레이어 정규화 적용, 디코더 셀프-어텐션 마스킹으로 미래 정보 접근 방지 |
| 멀티 헤드 어텐션 | 단일 어텐션 대신 여러 개의 어텐션 함수를 병렬 실행 | 쿼리(Q), 키(K), 값(V), 학습된 선형 투영 | 다양한 "표현 부분 공간"에서 정보 공동 집중 |
| 셀프 어텐션 | 단일 시퀀스의 다른 위치들을 연결하여 시퀀스 표현 계산 | Query, Key, Value (동일 소스) | 시퀀스 내의 원거리 의존성 모델링 |
| 스케일드 닷 프로덕트 어텐션 | Q와 K의 내적을 계산하고 sqrtd_k로 스케일링 후 소프트맥스 적용 | Q, K, V 행렬 | 내적 값의 크기 증가로 인한 기울기 소실 방지 |
| 피드포워드 네트워크 | 어텐션 결과의 각 위치에 독립적으로 동일하게 적용되는 완전 연결 네트워크 | 두 개의 선형 변환 + ReLU 활성화 | 차원: d_modeltod_fftod_model (512to2048to512) |
| 포지셔널 인코딩 | 모델에 순환/합성곱 없어 시퀀스 내 단어 순서 정보 주입 | 사인 및 코사인 함수 기반 | 훈련 시 접하지 않은 긴 시퀀스 길이로 외삽 가능성 |
1. 개요

기존 스퀀스 변환 모델은 순환 신경망(recurrent neural networks) & 합성곱 신경망(convolutional neural networks) 기반의 인코더 디코더 모델이었다.
이 논문의 트랜스포머(Transformer) 모델에서는 순환 & 합성곱을 완전히 제거하고 어텐션 메커니즘(attention mechanism)으로 인코더랑 디코더를 연결했다.
WMT 2014 영어-프랑스어 번역 작업에서는 GPU 8개로 3.5일 훈련해서 41.0 BLEU라는 최고 기록을 세웠다.
트랜스포머의 등장 이후 매우 많은 인공지능 모델들이 트랜스포머를 기본 구조로 채용했다. 이에 HuggingFace라는 트랜스포머 모델 전용 비즈니스까지 만들어졌다. 구글의 제미나이와 마찬가지로 OpenAI의 모델도 트랜스포머의 디코더 기능을 기반으로 발전시킨 자연어 생성 모델이다.
2. 인코더
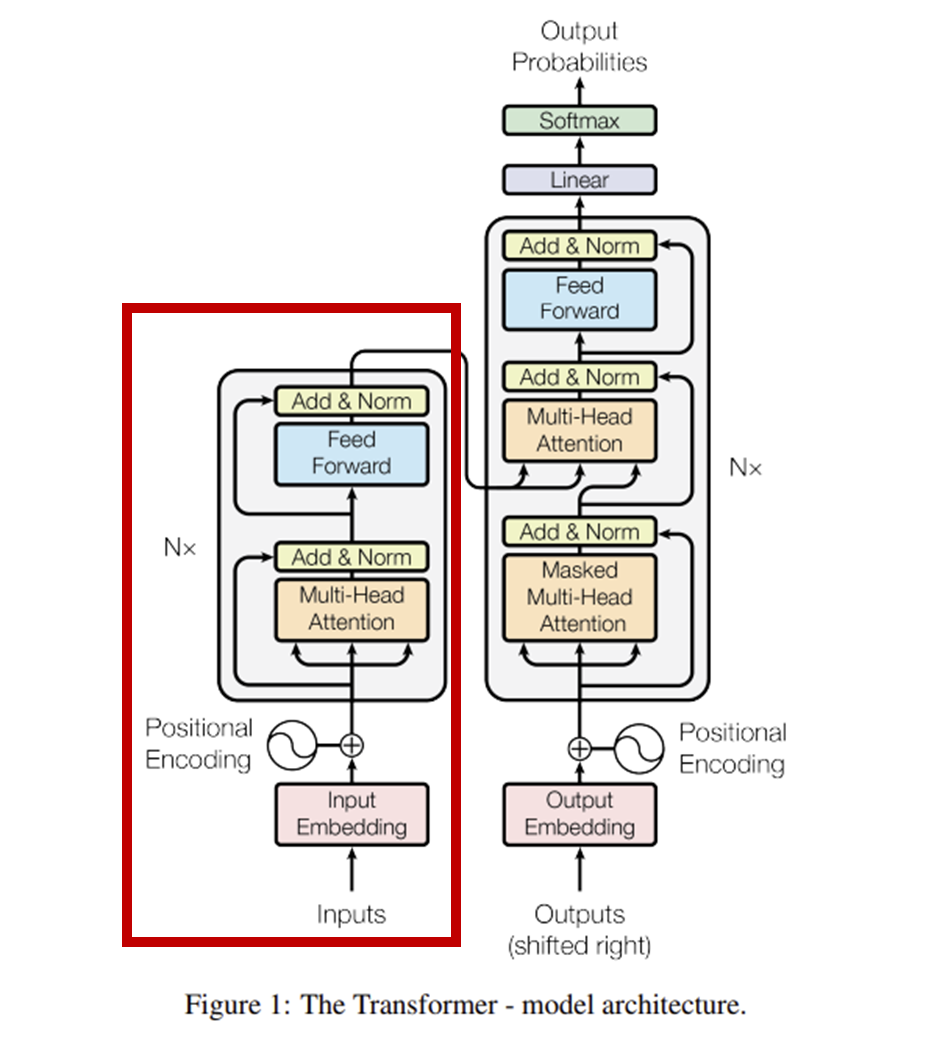

(1) 설명
- N개의 동일한 레이어를 쌓아 올린 구조
- 논문에서 N=6개 레이어 사용
- 각 레이어는 이전 레이어의 출력을 받아 더 복잡하고 추상적인 특징 추출
(2) 인코더 구조
- 두 개의 핵심 서브 레이어로 구성
- 각 서브 레이어는
잔차 연결(Residual Connection)과레이어 정규화(Layer Normalization)를 거침 - 잔차 연결: 입력에 서브 레이어의 출력을 더하는 방식
- 학습 안정성 높이고 기울기 소실 문제 완화
- 모든 서브 레이어와 임베딩 레이어의 출력 차원은 d_model=512로 통일
(3) 셀프 어텐션
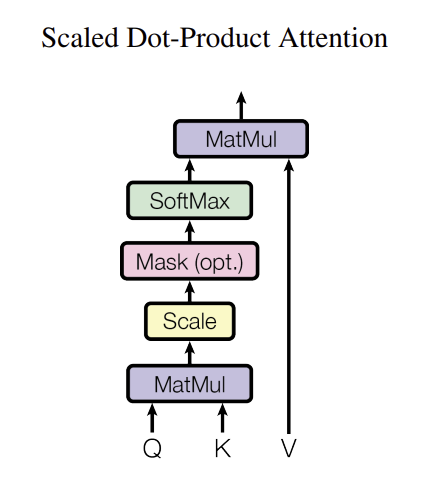
- 입력 시퀀스 내 단어 간 관계 및 영향도 파악 메커니즘
- 쿼리(Q), 키(K), 값(V) 세 가지 요소 사용
- 출력은 값들의 가중치 합으로 계산되며, 가중치는 쿼리와 해당 키의 호환성을 통해 결정
Scaled Dot-Product Attention방식 사용- Q, K, V 행렬을 사용하여 출력 행렬 계산
- 스케일링 인자 sqrtd_k는 d_k 값이 클 때 소프트맥스 함수의 기울기 소실 방지
(4) 멀티 헤드 어텐션
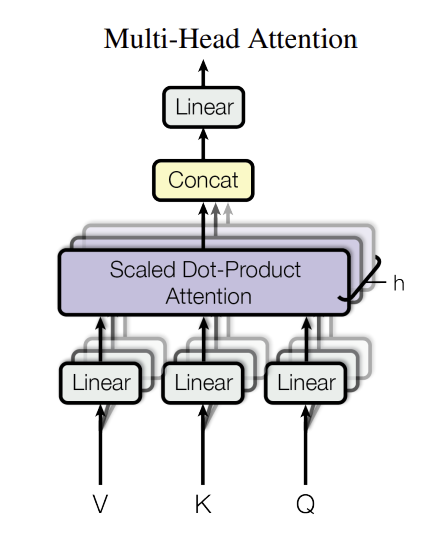

- 여러 개의 어텐션 함수를 병렬 실행
- 논문에서 h=8개 병렬 어텐션 레이어(헤드) 사용
- 각 헤드는 Q, K, V를 다른 학습된 선형 투영을 통해 다른 차원으로 변환 후 어텐션 함수 적용
- 다양한 "표현 부분 공간(representation subspaces)"에서 정보 공동 집중 가능
- 각 헤드 출력 연결 후 다시 선형 투영 거쳐 최종 결과 얻음
- 각 헤드 차원 축소로 총 계산 비용 단일 헤드 어텐션과 유사하게 유지
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, n_heads):
super().__init__()
self.d_model = d_model
self.n_heads = n_heads
self.head_dim = d_model // n_heads
self.wq = nn.Linear(d_model, d_model)
self.wk = nn.Linear(d_model, d_model)
self.wv = nn.Linear(d_model, d_model)
self.wo = nn.Linear(d_model, d_model)
def scaled_dot_product_attention(self, Q, K, V, mask=None):
scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.head_dim)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
attention_weights = torch.softmax(scores, dim=-1)
output = torch.matmul(attention_weights, V)
return output, attention_weights
def forward(self, Q, K, V, mask=None):
batch_size = Q.size(0)
Q = self.wq(Q).view(batch_size, -1, self.n_heads, self.head_dim).transpose(1, 2)
K = self.wk(K).view(batch_size, -1, self.n_heads, self.head_dim).transpose(1, 2)
V = self.wv(V).view(batch_size, -1, self.n_heads, self.head_dim).transpose(1, 2)
output, _ = self.scaled_dot_product_attention(Q, K, V, mask)
output = output.transpose(1, 2).contiguous().view(batch_size, -1, self.d_model)
output = self.wo(output)
return output(5) 피드포워드 네트워크
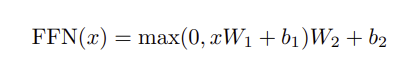
- 셀프 어텐션 서브 레이어 다음에 위치
- 특징: 각 위치에 대해 독립적으로 동일하게 적용되는 완전 연결 피드포워드 네트워크
- 구조: 두 개의 선형 변환과 그 사이에 ReLU 활성화 함수로 구성
- 차원: 입력 및 출력 차원 d_model=512, 내부 레이어 차원 d_ff=2048
- 해석: 커널 크기 1의 두 개 합성곱으로도 설명 가능
class PositionwiseFeedForward(nn.Module):
def __init__(self, d_model, d_ff):
super(PositionwiseFeedForward, self).__init__()
self.linear1 = nn.Linear(d_model, d_ff)
self.relu = nn.ReLU()
self.linear2 = nn.Linear(d_ff, d_model)
def forward(self, x):
return self.linear2(self.relu(self.linear1(x)))
(6) 포지셔널 인코딩
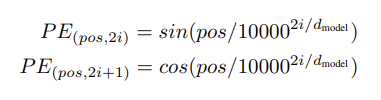
- 모델에 순환/합성곱 없어 시퀀스 내 단어 순서 정보 주입 필요
- 역할: 입력 임베딩에 "위치 인코딩" 추가하여 시퀀스의 순서 정보 제공
- 구조: 포지셔널 인코딩은 임베딩과 동일한 차원(d_model)을 가져 직접 합산 가능
- 방식: 다양한 주파수의 사인/코사인 함수 사용
pos는 위치,i는 차원
- 장점: 훈련 시 접하지 않은 더 긴 시퀀스 길이로의 외삽 가능성 학습된 포지셔널 임베딩과 유사한 결과
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
return x + self.pe[:, :x.size(1)].to(device)(7) 인코더 & 임베딩
class EncoderLayer(nn.Module):
def __init__(self, d_model, n_heads, d_ff, dropout_rate):
super(EncoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, n_heads)
self.norm1 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout_rate)
self.feed_forward = PositionwiseFeedForward(d_model, d_ff)
self.norm2 = nn.LayerNorm(d_model)
self.dropout2 = nn.Dropout(dropout_rate)
def forward(self, x, mask):
attn_output = self.self_attn(x, x, x, mask)
x = self.norm1(x + self.dropout1(attn_output))
ff_output = self.feed_forward(x)
x = self.norm2(x + self.dropout2(ff_output))
return x
class Encoder(nn.Module):
def __init__(self, vocab_size, d_model, n_layers, n_heads, d_ff, dropout_rate, max_seq_len):
super(Encoder, self).__init__()
self.embedding = nn.Embedding(vocab_size, d_model)
self.pos_encoding = PositionalEncoding(d_model, max_seq_len)
self.dropout = nn.Dropout(dropout_rate)
self.layers = nn.ModuleList([
EncoderLayer(d_model, n_heads, d_ff, dropout_rate)
for _ in range(n_layers)
])
self.norm = nn.LayerNorm(d_model)
def forward(self, src, src_mask):
x = self.embedding(src) * math.sqrt(self.embedding.embedding_dim)
x = self.pos_encoding(x)
x = self.dropout(x)
for layer in self.layers:
x = layer(x, src_mask)
return self.norm(x)3. 디코더
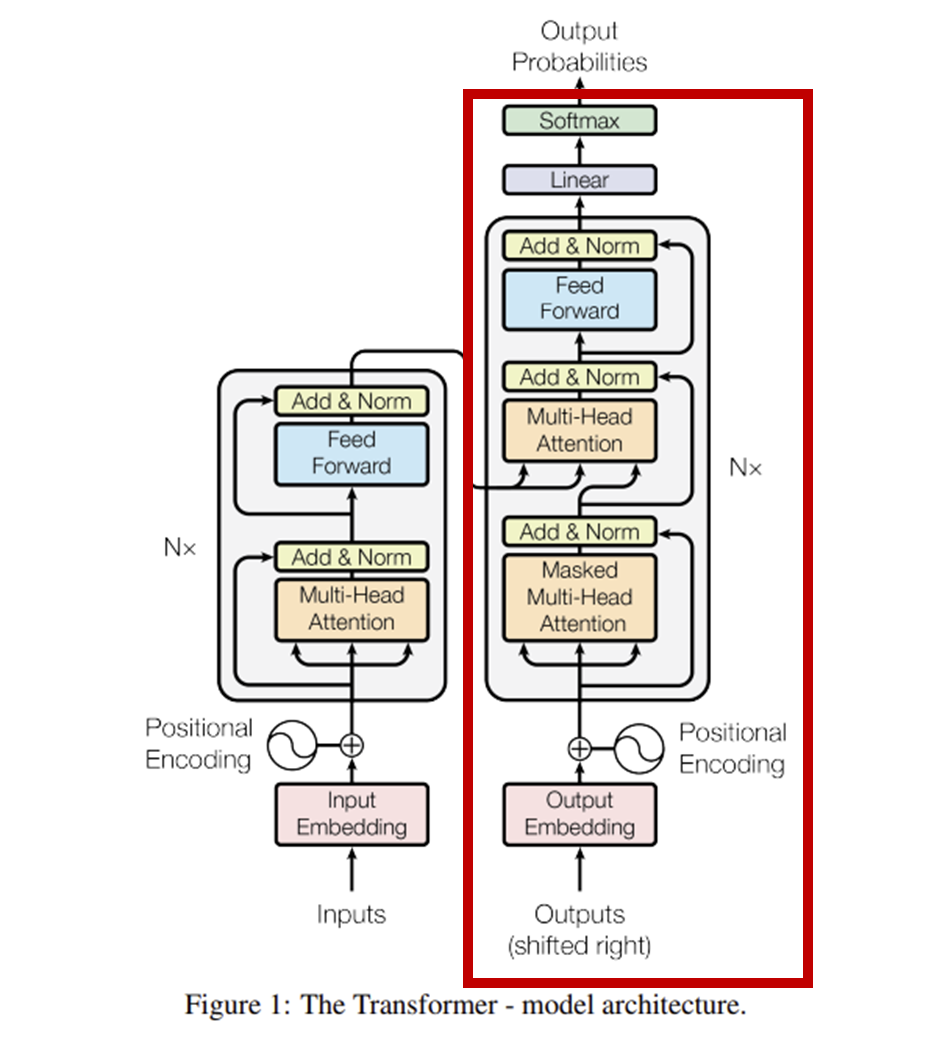

(1) 설명
- 디코더는 인코더에서 생성된 문맥 정보를 바탕으로 타겟 시퀀스(예: 번역된 문장)를 한 번에 한 단어씩 생성하는 역할
- 자동 회귀(Auto-regressive) 방식으로 작동, 즉 이전에 생성된 단어들을 다음 단어 예측을 위한 추가 입력으로 사용
(2) 디코더 스택 구조
- 인코더와 마찬가지로 N개의 동일한 레이어를 쌓아 올린 구조
- 논문에서는 N=6개 레이어 사용
- 각 디코더 레이어는 인코더 레이어와 다르게 세 개의 핵심 서브 레이어로 구성
- 각 서브 레이어는
잔차 연결(Residual Connection)과레이어 정규화(Layer Normalization)를 거침 - 잔차 연결: 입력에 서브 레이어의 출력을 더하는 방식
- 학습 안정성 높이고 기울기 소실 문제 완화
- 모든 서브 레이어와 임베딩 레이어의 출력 차원은 dmodel=512로 통일
class DecoderLayer(nn.Module):
def __init__(self, d_model, n_heads, d_ff, dropout_rate):
super(DecoderLayer, self).__init__()
self.masked_self_attn = MultiHeadAttention(d_model, n_heads)
self.norm1 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout_rate)
self.encoder_decoder_attn = MultiHeadAttention(d_model, n_heads)
self.norm2 = nn.LayerNorm(d_model)
self.dropout2 = nn.Dropout(dropout_rate)
self.feed_forward = PositionwiseFeedForward(d_model, d_ff)
self.norm3 = nn.LayerNorm(d_model)
self.dropout3 = nn.Dropout(dropout_rate)
def forward(self, x, enc_output, trg_mask, src_mask):
masked_attn_output, _ = self.masked_self_attn(x, x, x, trg_mask)
x = self.norm1(x + self.dropout1(masked_attn_output))
enc_dec_attn_output, _ = self.encoder_decoder_attn(x, enc_output, enc_output, src_mask)
x = self.norm2(x + self.dropout2(enc_dec_attn_output))
ff_output = self.feed_forward(x)
x = self.norm3(x + self.dropout3(ff_output))
return x(3) 마스크드 멀티 헤드 어텐션
- 디코더의 첫 번째 서브 레이어
- 인코더의 셀프-어텐션과 동일하지만 '마스킹(Masking)' 기능 추가
- 마스킹의 목적: 현재 예측하려는 위치 이후의 단어들을 미리 보지 못하게 함
- 예측하려는 위치 i의 결과가 i보다 작은 위치의 알려진 출력에만 의존하도록 보장
- 이를 통해 '좌측 정보 흐름 방지(prevent leftward information flow)' 구현
- 쿼리(Q), 키(K), 값(V) 모두 이전 디코더 레이어의 출력 사용
# MultiHeadAttention 클래스 내 scaled_dot_product_attention 메서드에 마스킹 로직 포함
# (해당 코드는 인코더 파트에서 이미 제공되었으므로 여기서는 생략, 필요시 추가)
# 마스킹 로직: scores = scores.masked_fill(mask == 0, -1e9)(4) 디코더 멀티 헤드 어텐션
- 디코더의 두 번째 서브 레이어
- 인코더와 디코더를 연결해주는 핵심 부분
- 쿼리(Q)는 이전 디코더 레이어의 출력에서 옴
- 키(K)와 값(V)은 인코더 스택의 출력에서 옴 (인코더의 메모리)
- 이를 통해 디코더의 각 위치가 입력 시퀀스(인코더 출력)의 모든 위치를 참조 가능
- 기존 시퀀스-투-시퀀스 모델의 일반적인 인코더-디코더 어텐션 메커니즘과 유사
# DecoderLayer 클래스 내 forward 메서드에서 encoder_decoder_attn 사용 부분
# enc_output이 K와 V로 사용됨
# (해당 코드는 위에 DecoderLayer 정의 시 포함되었으므로 여기서는 생략)(5) 피드포워드 네트워크
- 디코더의 세 번째 서브 레이어
- 셀프-어텐션 서브 레이어 다음에 위치
- 특징: 각 위치에 대해 독립적으로 동일하게 적용되는 완전 연결 피드포워드 네트워크
- 구조: 두 개의 선형 변환과 그 사이에 ReLU 활성화 함수로 구성
- 차원: 입력 및 출력 차원 dmodel=512, 내부 레이어 차원 dff=2048
# PositionwiseFeedForward 클래스 인코더 파트에서 이미 생성
(6) 임베딩 및 포지셔널 인코딩
- 임베딩: 출력 토큰(단어)을 dmodel 차원의 벡터로 변환하는 데 학습된 임베딩 사용
- 포지셔널 인코딩: 인코더와 동일하게 시퀀스의 순서 정보를 모델에 주입하기 위해 사용
- 임베딩 벡터에 포지셔널 인코딩을 더함
- 논문에서는 인코더와 디코더의 두 임베딩 레이어와 사전-소프트맥스 선형 변환 사이에 동일한 가중치 행렬을 공유
# PositionalEncoding 클래스 인코더 파트에서 이미 생성)
class Decoder(nn.Module):
def __init__(self, vocab_size, d_model, n_layers, n_heads, d_ff, dropout_rate, max_seq_len):
super(Decoder, self).__init__()
self.embedding = nn.Embedding(vocab_size, d_model)
self.pos_encoding = PositionalEncoding(d_model, max_seq_len)
self.dropout = nn.Dropout(dropout_rate)
self.layers = nn.ModuleList([
DecoderLayer(d_model, n_heads, d_ff, dropout_rate)
for _ in range(n_layers)
])
self.linear = nn.Linear(d_model, vocab_size) # 최종 선형 계층
def forward(self, trg, enc_output, trg_mask, src_mask):
x = self.embedding(trg) * math.sqrt(self.embedding.embedding_dim)
x = self.pos_encoding(x)
x = self.dropout(x)
for layer in self.layers:
x = layer(x, enc_output, trg_mask, src_mask)
output = self.linear(x)
return output(7) 최종 선형 및 소프트맥스
- 디코더 스택의 마지막 출력은 최종 선형 변환을 거침
- 그 후 소프트맥스 함수를 통해 다음 토큰에 대한 예측 확률로 변환
- 이 예측 확률을 기반으로 가장 가능성 높은 다음 단어를 선택하여 번역 결과 생성
# Decoder 클래스 내 forward 메서드 마지막 부분
# (위에 Decoder 클래스 정의 시 포함되었으므로 여기서는 생략)
# output = self.linear(x)4. 성능
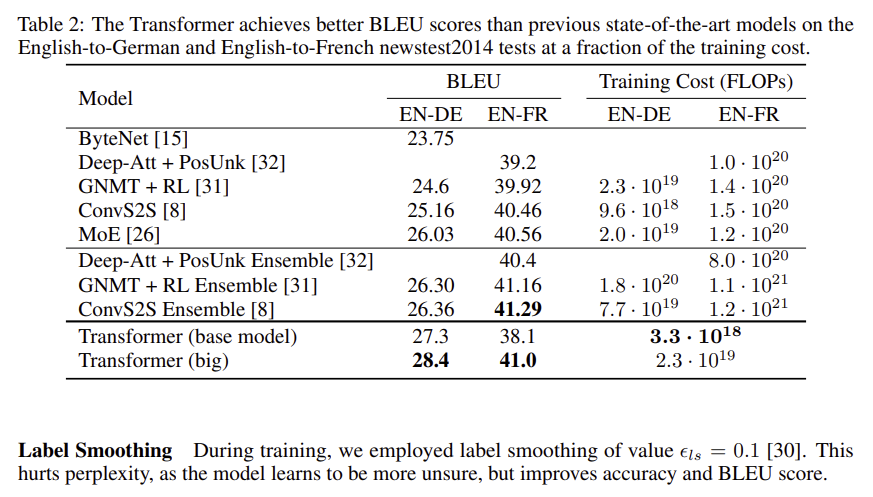
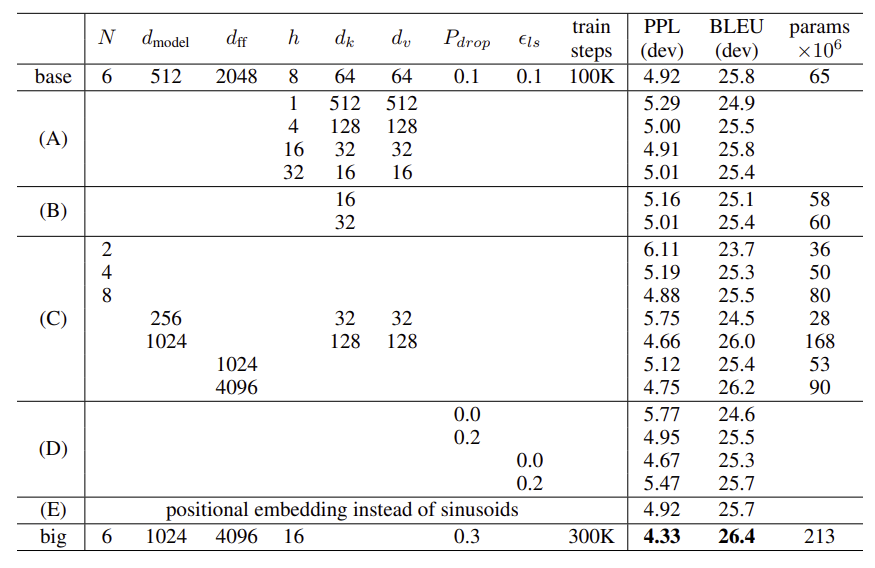

The code we used to train and evaluate our models is available at https://github.com/tensorflow/tensor2tensor.

AI Engineer