해커톤 기획서를 후다닥 끝내고 미션을 시작했는데,,, 이거 내가 2년만 일찍 태어났다면 손도 못 댔을 것 같다.
학습시간 09:00~03:00(당일18H/누적1255H)
◆ 학습내용
한영 AI 번역기 모델 구현
어제 1~3에 이어 4부터 진행!
4. Seq2Seq(basic) 구현
시작하기 전에 Seq2Seq 모델이 뭔지부터 다시 공부해야할 것 같다.
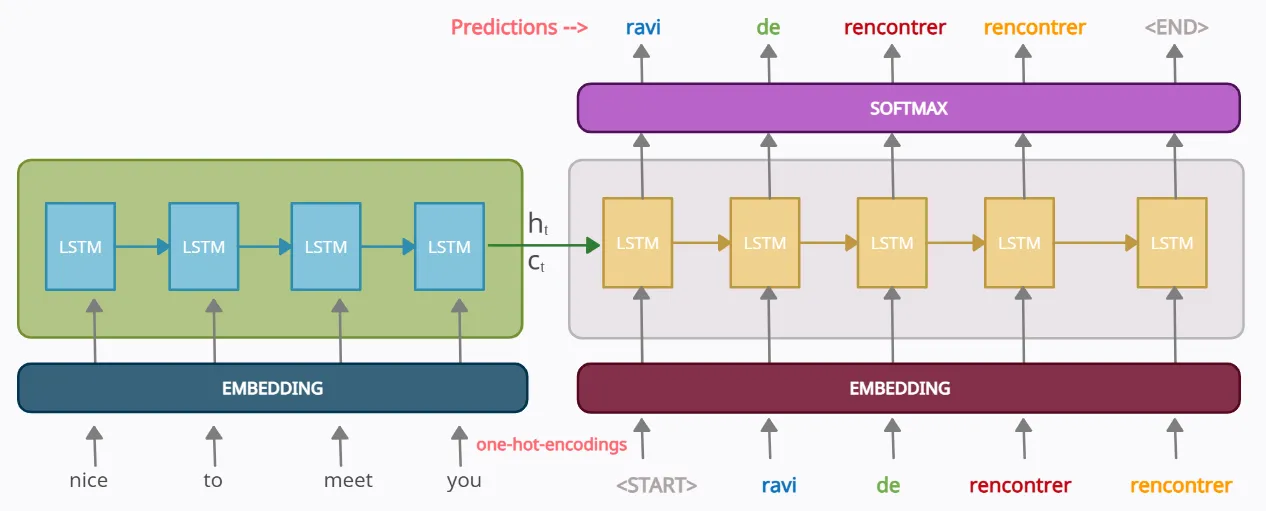
Seq2Seq 모델은 말 그대로 '하나의 시퀀스(Sequence, 연속된 데이터)'를 입력받아서 '다른 시퀀스'를 출력하는 모델이다.
NLP, Chatbot, Machine Translation, Text summarization, Speech to text에서 쓰이는 대표적인 모델이다.
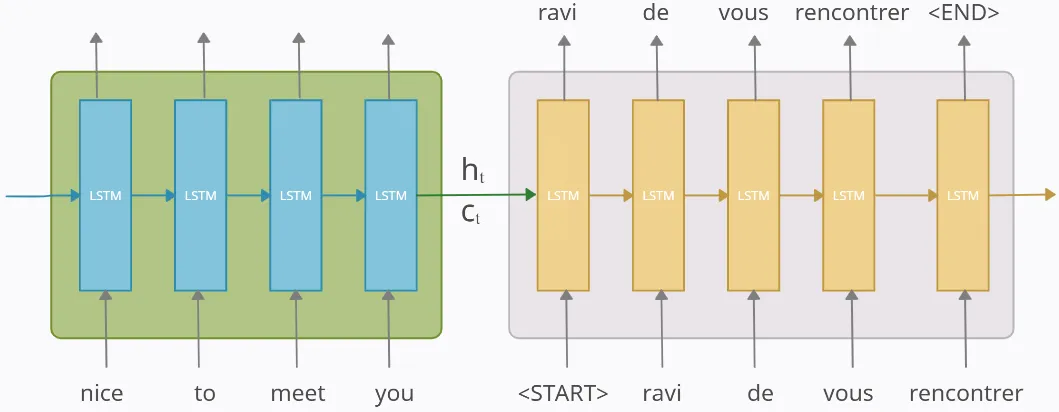
Seq2Seq 모델은 크게 두 부분, '인코더(Encoder)'와 '디코더(Decoder)'로 이루어져 있다. 둘 다 RNN(주로 LSTM이나 GRU)을 기반으로 만든다.
인코더는 입력 문장을 읽어서 모든 정보를 벡터로 압축한다. 이 벡터를 컨텍스트 벡터라고 한다.
디코더는 인코더가 만든 컨텍스트 벡터와 SOS 토큰을 받아서 첫 단어를 예측하고, EOS 토큰이 나올 때까지 과정을 반복한다.
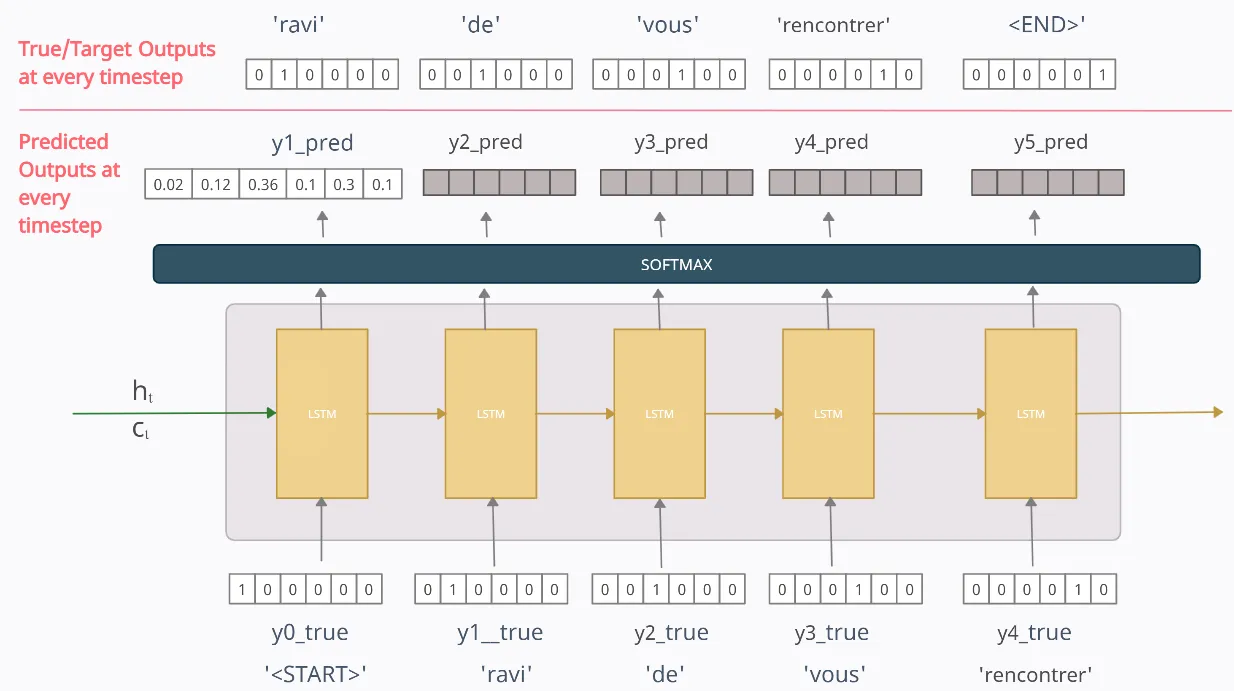
각 단어의 예측은 softmax 함수로 이루어진다. 다음 나올 단어의 확률을 나타내기 위함이다.
근데 Seq2Seq 모델은 치명적인 단점이 있다. 바로 문장이 길든 짧든 컨텍스트 벡터를 고정시켜야 한다는 점이다.
그래서 문장이 길어길수록 앞부분의 정보가 소실된다. RNN계열 모델을 쓰기 때문에 어쩔 수 없는 문제다.
그래서 나온 게 Attention 이다!
일단 모델부터 구현해 보자.
이번에 구현해야할 모델은 GRU 기반 Seq2Seq 모델이다.
인코더, 디코더, 둘을 합칠 몸통을 만들어야 한다.
논문을 보고 이해할 시간은 없어서,, 일단 복붙을 해오자.
class Encoder(nn.Module):
def __init__(self, input_dim, emb_dim, hid_dim, n_layers, dropout):
super().__init__()
self.embedding = nn.Embedding(input_dim, emb_dim)
self.rnn = nn.GRU(emb_dim, hid_dim, n_layers, dropout=dropout)
self.dropout = nn.Dropout(dropout)
def forward(self, src):
embedded = self.dropout(self.embedding(src))
outputs, hidden = self.rnn(embedded)
return hidden먼저 인코더 클래스다.
nn.Embedding() 으로 인풋 단어를 벡터로 변환한다.
nn.GRU() 시계열 모델을 불러와서 적용해 준다. 근데 난 LSTM으로 하고 싶은데 왜 GRU로 지정을 해준 건지 모르겠다. 요즘은 LSTM 말고 안 쓴다고 하던데,,, 게이트가 하나 적어서 난이도가 조금 낮은가..?
마지막으로 nn.Dropout() 드롭아웃을 적용하고 순전파를 진행한다. 0.2~0.5 중에 뭘 넣을지 고민해 봐야겠다.
class Decoder(nn.Module):
def __init__(self, output_dim, emb_dim, hid_dim, n_layers, dropout):
super().__init__()
self.output_dim = output_dim
self.embedding = nn.Embedding(output_dim, emb_dim)
self.rnn = nn.GRU(emb_dim + hid_dim, hid_dim, n_layers, dropout=dropout)
self.fc_out = nn.Linear(hid_dim, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, input, hidden, context):
input = input.unsqueeze(0)
embedded = self.dropout(self.embedding(input))
emb_con = torch.cat((embedded, context.unsqueeze(0)), dim=2)
output, hidden = self.rnn(emb_con, hidden)
prediction = self.fc_out(output.squeeze(0))
return prediction, hidden다음은 디코더다. 인코더에서 생성된 벡터를 기반으로 새로운 단어를 생성한다.
nn.Embedding() 을 똑같이 사용하는데, 인코더에서는 input_dim을 인자로 받고, 디코더에서는 output_dum을 인자로 받는다.
이후 똑같이 GRU 모델을 불러온다. 인코더와 다른 점은 n_layers 인자로 레이어 수를 바꿀 수 있다는 것과, nn.Linear() 전결합 층을 추가한다는 것이다. 이유를 찾아보니 가장 확률이 높은 단어를 고르기 위함이라고 한다.
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, device):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.device = device
def forward(self, src, trg, teacher_forcing_ratio=0.5):
batch_size = trg.shape[1]
trg_len = trg.shape[0]
trg_vocab_size = self.decoder.output_dim
outputs = torch.zeros(trg_len, batch_size, trg_vocab_size).to(self.device)
context = self.encoder(src)
hidden = context
input = trg[0,:]
for t in range(1, trg_len):
output, hidden = self.decoder(input, hidden, context[-1])
outputs[t] = output
teacher_force = torch.rand(1) < teacher_forcing_ratio
top1 = output.argmax(1)
input = trg[t] if teacher_force else top1
return outputs다음은 대망의 몸통이다. 인자에 encoder, decoder가 있다. 둘을 연결시킨다는 뜻이다.
아차 그리고 나는 지금까지 device를 글로벌 변수로 지정했기 때문에 계속 빼는 습관이 있었는데, 이게 나중에 여러 팀과 협업하려면 개인의 GPU환경이 달라서?? 넣어주는 게 좋다고 한다.
순전파 함수 인자로 src, trg, teacher_forcing_ratio이 있다. src는 한국어 문어, trg은 영어 문장이다.
중요한 건 teacher_forcing_ratio 인데, 이게 약간 뭐랄까,, dropout의 반대 버전이라고 보면 될 것 같다. 0.5로 설정하면 50% 확률로 정답을 보여주면서 훈련시킨다.
초기에는 비율을 높이고 안정적으로 학습하는 게 좋다. 하지만 너무 높으면 안 됨! 과적합!! 과적합 주의!!
모델이 2개니까 다음 모델까지 만들고 객체를 만들어야겠다.
5. Seq2Seq(attention) 구현
이번에 구현해야할 모델은 GRU 기반 Seq2Seq 모델에 Attention을 추가하는 것이다.
필요한 클래스는 어텐션, 인코더, 디코더, 둘을 합칠 몸통이다.
Bahdanau와 Loung이 대표적인 어텐션이라고 하는데, 근본인 Bahdanau를 다루어 보는 게 맞는 것 같다.
일단 Bahdanau Attention에 대해 공부를 먼저 해보자.
한 블로거님의 포스팅에서 찾은 이미지다. 논문을 보면서 직접 구현해보신 것 같다. 개인적으로 이 이미지가 Bahdanau Attention을 가장 잘 설명하는 이미지가 아닌가 싶다.
단어 간 상관관계를 통해 중요한 단어를 확인하는 것. 나 또한 데이터프레임 실습할 때 상관관계를 먼저 들여다 보면 나만의 가설을 세울 수 있었다. 언어 학습에서도 비슷한 맥락인 것 같다.
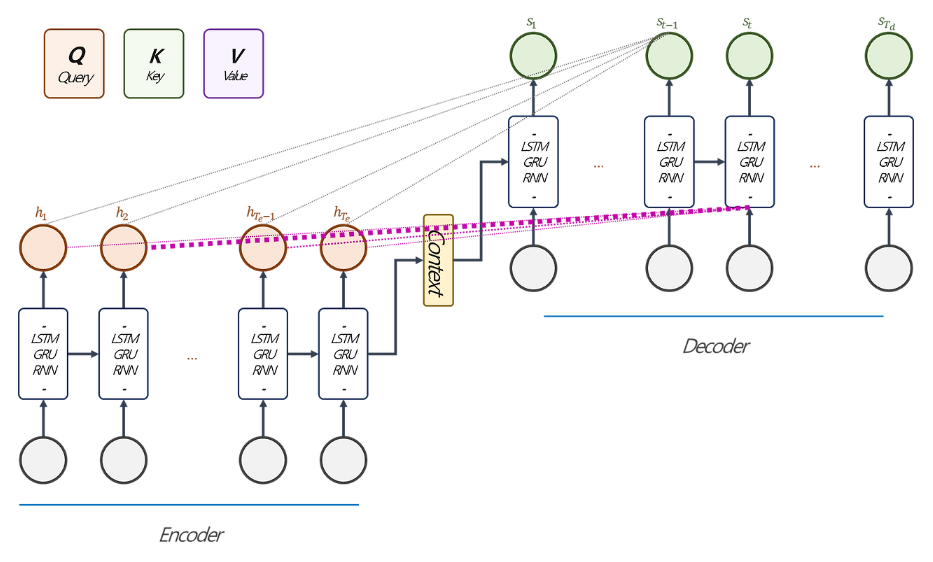
전반적인 구조는 이런 느낌이다. 쉽게 말해, 인코더의 정보가 디코더의 각 단어마다 들어가는 구조다. 여기서 Q, K, V가 어텐션 계수를 만드는 데 핵심 역할을 한다.
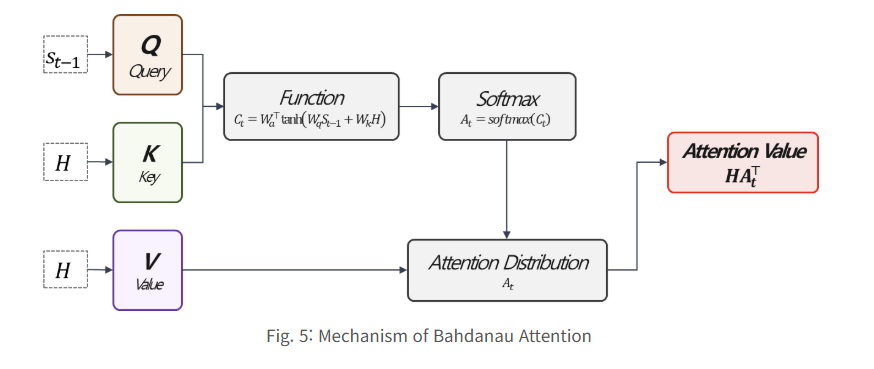
Q, K, V는 이런 매커니즘으로 작동한다. 먼저 쿼리와 키를 합친 후에 하이퍼볼릭탄젠트를 거친다. 이후 소프트맥스로 확률을 뽑아내고, 이를 벨류와 곱하면 어텐션 계수를 얻을 수 있다.
Q, K, V를 쉽게 비유하자면,
- 내가 현재 원하는 정보(Q)를 찾기 위해 도서관에 간다
- 원하는 정보의 키워드를 검색해서 모든 책 제목(K)을 훑어본다
- 원하는 정보가 담겨 있을만한 책을 골라서 내용(V)을 읽는다
Seq2seq 구조에서 Query는 Decoder의 Hidden State고, Key는 Encoder의 Hidden State다.
왠지 강의에서 들었던 내용이 새록새록 떠오르는 것 같기도 하다.
그럼 코드로 살펴보자!
class AttnEncoder(nn.Module):
def __init__(self, input_dim, emb_dim, enc_hid_dim, dec_hid_dim, dropout):
super().__init__()
self.embedding = nn.Embedding(input_dim, emb_dim)
self.rnn = nn.GRU(emb_dim, enc_hid_dim, bidirectional=True)
self.fc = nn.Linear(enc_hid_dim * 2, dec_hid_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, src):
embedded = self.dropout(self.embedding(src))
outputs, hidden = self.rnn(embedded)
hidden = torch.tanh(self.fc(torch.cat((hidden[-2,:,:], hidden[-1,:,:]), dim=1)))
return outputs, hidden먼저 인코더다. 전 모델과 다 비슷한데, bidirectional라는 게 추가되어 있다. 이건 양방향 학습을 위한 것인데, 문장을 좌우 & 우좌 한번씩 읽어서 문맥 정보를 더 제대로 파악하기 위함이다.
문맥을 2회 읽으면 인풋값도 2배가 되는데, 이를 nn.Linear() 에서 컨트롤 해준다. 2배로 들어온 enc_hid_dim 값을 적절한 dec_hid_dim 값으로 변환하는 것이다.
class BahdanauAttention(nn.Module):
def __init__(self, enc_hid_dim, dec_hid_dim):
super().__init__()
self.attn = nn.Linear((enc_hid_dim * 2) + dec_hid_dim, dec_hid_dim)
self.v = nn.Linear(dec_hid_dim, 1, bias=False)
def forward(self, hidden, encoder_outputs):
batch_size = encoder_outputs.shape[1]
src_len = encoder_outputs.shape[0]
hidden = hidden.unsqueeze(1).repeat(1, src_len, 1)
encoder_outputs = encoder_outputs.permute(1, 0, 2)
energy = torch.tanh(self.attn(torch.cat((hidden, encoder_outputs), dim=2)))
attention = self.v(energy).squeeze(2)
return F.softmax(attention, dim=1)다음은 대망의 어텐션 클래스다.
이 클래스의 목적은 단 하나다. "그래서, 수많은 인코더 값 중에서 뭘 봐야 하는데?"
먼저 self.attn에 nn.Linear() 레이어가 있다. 이건 아까 이미지에서 보았던 하이퍼볼릭탄젠트로 보내기 전 Q와 K를 합쳐주는 부분이다.
아까 Seq2seq 구조에서 Key는 Encoder의 Hidden State고, Query는 Decoder의 Hidden State라고 했다.
양방향 학습을 했으니 Key (enc_hid_dim * 2)이 되고, Query는 dec_hid_dim 그대로 넣어주면 된다.
hidden = hidden.unsqueeze(1).repeat(1, src_len, 1) 를 하면 [배치, 길이, 차원]이 된다.
이와 연산하기 편하도록 encoder_outputs = encoder_outputs.permute(1, 0, 2) 코드를 통해 [배치, 길이, 차원]로 변경해 주는 것이다.
이를 하이퍼볼릭탄젠트에 통과시키고 소프트맥스로 돌린다.
후 어렵다 어려워.
class AttnDecoder(nn.Module):
def __init__(self, output_dim, emb_dim, enc_hid_dim, dec_hid_dim, dropout, attention):
super().__init__()
self.output_dim = output_dim
self.attention = attention
self.embedding = nn.Embedding(output_dim, emb_dim)
self.rnn = nn.GRU((enc_hid_dim * 2) + emb_dim, dec_hid_dim)
self.fc_out = nn.Linear((enc_hid_dim * 2) + dec_hid_dim + emb_dim, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, input, hidden, encoder_outputs):
input = input.unsqueeze(0)
embedded = self.dropout(self.embedding(input))
a = self.attention(hidden, encoder_outputs)
a = a.unsqueeze(1)
encoder_outputs = encoder_outputs.permute(1, 0, 2)
weighted = torch.bmm(a, encoder_outputs)
weighted = weighted.permute(1, 0, 2)
rnn_input = torch.cat((embedded, weighted), dim=2)
output, hidden = self.rnn(rnn_input, hidden.unsqueeze(0))
assert (output == hidden).all()
embedded = embedded.squeeze(0)
output = output.squeeze(0)
weighted = weighted.squeeze(0)
prediction = self.fc_out(torch.cat((output, weighted, embedded), dim=1))
return prediction, hidden.squeeze(0)이번엔 디코더다. 어텐션 하나 들어갔다고 코드가 이렇게 난폭하게 변하다니...
init 부분엔 특이사항이 없다. 위에서 설명했던 내용이 똑같이 들어가 있다.
a를 어텐션 계수라 가정하고 진행한다. encoder_outputs의 차원 순서를 맞춘 후에 torch.bmm() 함수로 곱해준다.
사실 mulmat이랑 무슨 차이인지 정확히 이해는 못했는데, mulmat은 2차원 곱셈이고, bmm은 3차원(배치 단위) 곱셈인 것 같다.
assert (output == hidden).all()는 GRU 레이어가 1개일 때, 마지막 타임스텝의 output과 hidden이 같다는 걸 확인하는 디버깅용 코드라고 한다.
마지막으로 output, weighted, embedded 3개를 concatenate한 후, nn.Linear()를 통과시켜 최종 단어를 예측한다.
class AttnSeq2Seq(nn.Module):
def __init__(self, encoder, decoder, device):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.device = device
def forward(self, src, trg, teacher_forcing_ratio=0.5):
batch_size = src.shape[1]
trg_len = trg.shape[0]
trg_vocab_size = self.decoder.output_dim
outputs = torch.zeros(trg_len, batch_size, trg_vocab_size).to(self.device)
encoder_outputs, hidden = self.encoder(src)
input = trg[0,:]
for t in range(1, trg_len):
output, hidden = self.decoder(input, hidden, encoder_outputs)
outputs[t] = output
teacher_force = torch.rand(1) < teacher_forcing_ratio
top1 = output.argmax(1)
input = trg[t] if teacher_force else top1
return outputs이제 몸통이다. 힘들다 힘들어...
정말 다행스럽게도 몸통 부분은 기본 Seq2Seq와 거의 똑같다.
차이점이 딱 2개 있는데,
기본 버전은 인코더 호출 시에 context = self.encoder(src)로 요약본 하나만 받지만, 어텐션 버전은 encoder_outputs, hidden = self.encoder(src)로 원본까지 받는다는 것이다.
디코더 호출 부분에서도 self.decoder(..., encoder_outputs)에 매번 출력 시 원본 전체를 함께 넘겨준다.
쉽게 말해, 기본 버전은 요약본만 보고 어텐션 버전은 요약본과 원본을 함께 보는 것이다. 그러니 계산비용은 높아져도 성능이 더 좋을 수밖에!
