어렵다 어려워
학습시간 09:00~03:00(당일19H/누적1333H)
◆ 학습내용
목표
- Hugging Face transformers 라이브러리를 사용하여 문서 요약 모델 구현
- Transformer 기반 요약 모델(T5, BART 등) 구현
데이터
- JSON 파일 형태로 제공되며, 3종류(신문 기사, 사설, 법률)의 문서가 포함
- 전체 데이터를 모두 사용하거나 원하는 문서 종류를 선택하여 학습
- train_original_law.json & valid_original_law.json
가이드라인
- 문서 데이터를 로드하고, 불필요한 기호나 공백을 제거하는 등 전처리 작업을 수행
- 텍스트 길이를 확인하고, 모델 입력에 적합한 형식으로 변환
- Hugging Face의 transformers 라이브러리를 활용해 문서 요약을 수행
- 생성된 요약문과 원본 문서를 비교하여 ROUGE 등의 평가 지표를 사용해 요약 품질을 분석
- 테스트 문장에 대한 요약 결과를 출력하여 모델의 성능을 확인
1. EDA
이번에 받은 데이터는 train, valid로 이루어진 3쌍의 JSON 파일이다.
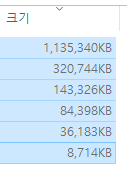
지난 미션 때보다 파일 용량이 더 크다. 어쩌면 전처리에 5시간을 부어야할지도 모른다는 뜻이다...
그렇다면 가장 용량이 적은 law 파일만 가지고 진행해 보아야겠다. 원하는 문서 종류를 선택할 수 있다고 했으니까! 법률 데이터를 학습한 자연어 모델이 궁금하기도 하고.
if 'google.cloud' in sys.modules:
from google.colab import drive; drive.mount('/content/drive')
import drive.MyDrive.develop.projects.autoconfig as config
config.directory('text-summarization')개발환경 및 경로설정을 먼저 했다.
train_dir = "data/train_original_law.json"
valid_dir = "data/valid_original_law.json"
def load_json(file_path):
with open(file_path, 'r', encoding='utf-8') as f:
data = json.load(f)['documents']
return data
load_json(train_dir)[0]파일 내부가 어떤 식으로 되어 있는지 먼저 확인해 보자.
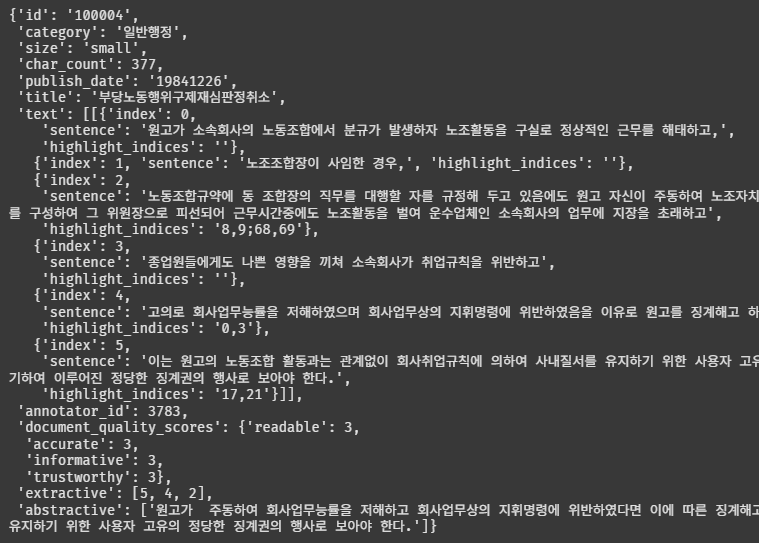
확실히 법률 관련 용어가 많이 들어가 있다. 한국어인데 이해가 안 되네 ㅋㅋㅋㅋ
근데 평소 보던 데이터와 다르게 text 데이터가 많다. 이걸로 문서 요약을 어떻게 한다는 거지...? index 노드와 abstractive 노드의 상관관계를 학습시키는 건가...?
일단,, 어쩐 것을 위주로 살펴보면 좋을까?
category, size, char_count 이건 기본적으로 확인해야 할 것 같고,,,
document_quality_scores, accurate, informative, trustworthy, extractive 까지 살펴보면 좋을 것 같다!
print(f"데이터 수: Train {len(train_json)}, Valid {len(valid_json)}")
데이터 수: Train 24329, Valid 3004 가 나왔다. 7:3 비율 정도 되는 듯?
print("")
print("카테고리별 문서 수")
print(df['category'].value_counts())
plt.figure(figsize=(10, 6))
sns.countplot(x=df['category'], order=df['category'].value_counts().index)
plt.title('카테고리별 문서 수')
plt.show()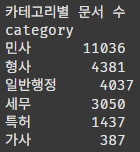
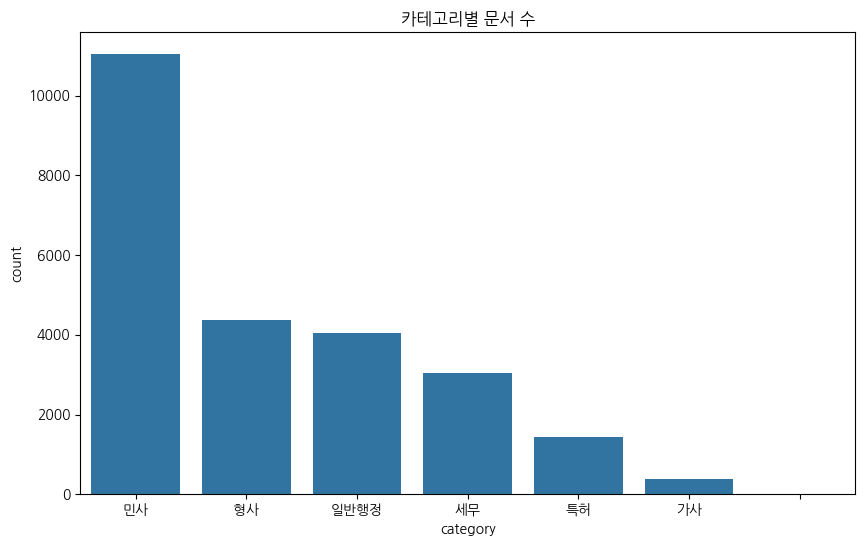
카테고리는 민사관련 법이 가장 많다.
print("크기별 문서 수")
print(df['size'].value_counts())
plt.figure(figsize=(10, 6))
sns.countplot(x=df['size'], order=df['size'].value_counts().index)
plt.title('문서 크기 분류별 개수')
plt.show()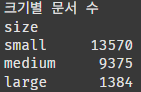
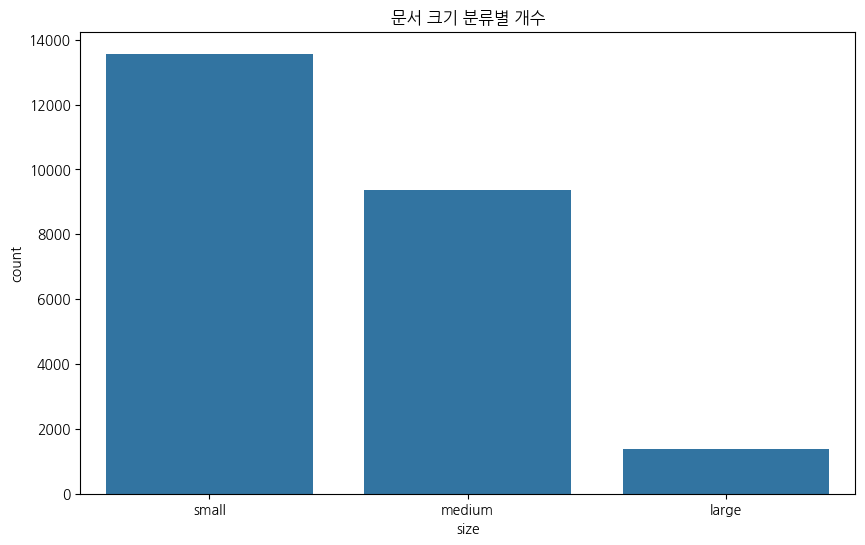
size가 small로 분류된 데이터가 가장 많다. 좋다고 해야할지...?
print("글자 수")
print(df['char_count'].describe())
plt.figure(figsize=(10, 6))
sns.histplot(df['char_count'], bins=50)
plt.title('문서 글자 수 분포')
plt.show()
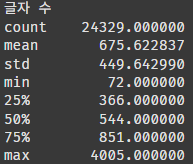
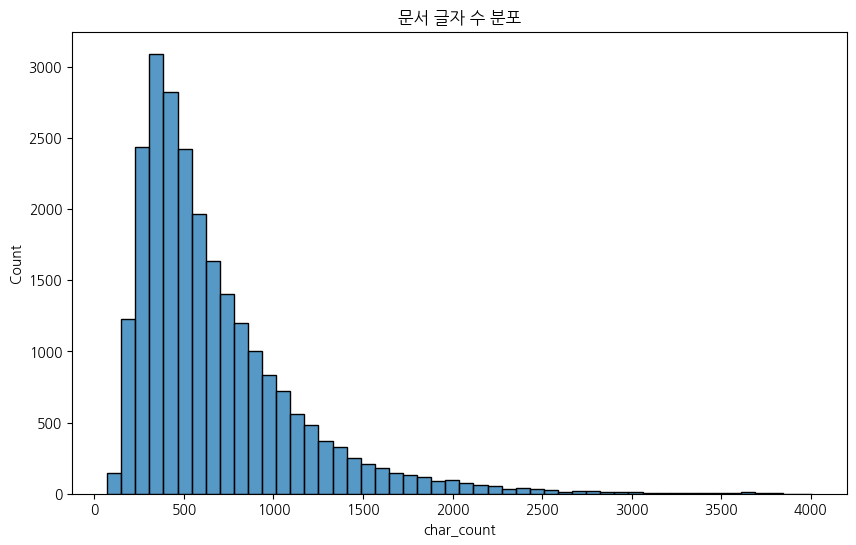
평균 675자다. small의 기준이 500자 정도인 것 같다.
print("발행 연도 분석")
df['publish_date'] = pd.to_datetime(df['publish_date'], format='%Y%m%d', errors='coerce')
df['publish_year'] = df['publish_date'].dt.year
plt.figure(figsize=(12, 6))
sns.histplot(df['publish_year'].dropna(), bins=50)
plt.title('문서 발행 연도 분포')
plt.show()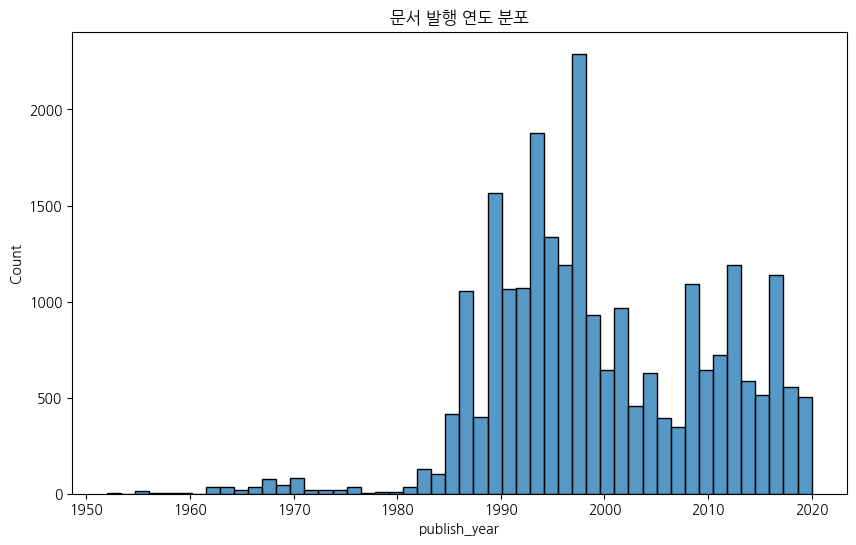
이건 재미로 확인해 봤다.
근데 생각해 보니까 법률이라서 오히려 연도가 굉장히 중요하지 않나 싶다. 시대가 흐르면서 법이 바뀌기도 하니까... 법을 모르니까 데이터를 판단할 수가 없네.
print("문서 품질 점수 분포")
quality_cols = ['readable', 'accurate', 'informative', 'trustworthy']
plt.figure(figsize=(16, 4))
for i, col in enumerate(quality_cols, 1):
plt.subplot(1, 4, i)
sns.countplot(x=df[col])
plt.title(f'{col} 점수 분포')
plt.tight_layout()
plt.show()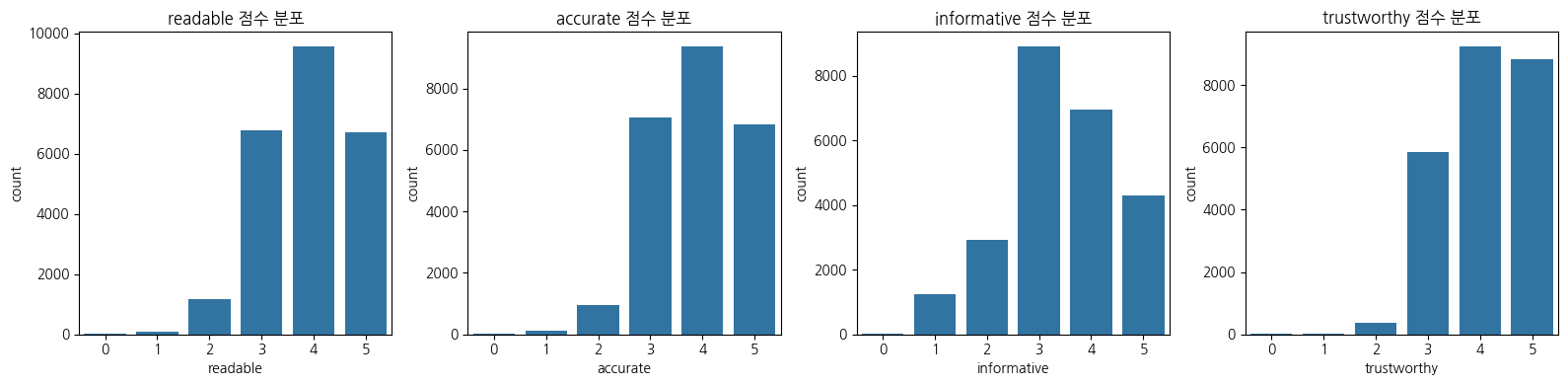
가독성, 정확성, 정보성, 신뢰성에 대한 점수다. 은근히 1~2점인 데이터가 있다.
일반적인 머신러닝이면 이상치로 생각하고 제거했을 것 같은데,, 자연어 학습이라 살려둬야 하는 건지 잘 모르겠다. 안 좋은 데이터가 뭔지도 함께 학습시키면 기준을 잡아줄 수 있는 거려나..!?
일단 포함해서 학습해 봐야지..
2. Hugging Face
허깅페이스에서 트랜스포머를 사용하라고 하는데 무슨 말인지 모르겠다...
허깅페이스가 뭔지부터 공부해 보자...!
(1) 기본 개념
A. 정의
- 단순한 라이브러리가 아닌, AI 개발자를 위한 통합 생태계(Ecosystem)
- 자연어 처리(NLP)에서 시작하여 컴퓨터 비전, 오디오, 강화학습 등 AI 전 분야로 확장
- 최신 AI 모델, 데이터셋, 데모 앱을 공유하고 협업하는 오픈소스 허브 플랫폼
B. 비전과 미션
- AI의 민주화 (Democratization of AI): 소수의 기술 기업이 독점하던 최첨단 AI 기술을 누구나 쉽게 사용할 수 있도록 공개
- 재현 가능하고 책임감 있는 AI (Reproducible & Responsible AI): 모델 카드, 데이터셋 카드 등을 통해 모델과 데이터의 투명성을 높이고, 누구나 연구 결과를 쉽게 재현하도록 지원
- 협업 중심의 생태계 구축: 전 세계 연구자, 개발자들이 지식과 결과물을 공유하며 함께 발전하는 커뮤니티 조성
C. 이름의 유래
- 포옹하는 얼굴 이모지(🤗)에서 영감을 받음
- 기술과 사용자를 친근하게 연결하고, AI를 보다 따뜻하고 접근하기 쉬운 존재로 만들려는 의도 내포
- 실제 라이브러리나 공식 문서에서도 이모지를 적극적으로 사용하는 문화
(2) Transformers
A. 주요 기능
- 파이프라인(Pipeline): AI 모델의 복잡한 과정을 추상화하여 단 몇 줄의 코드로 특정 태스크(감성 분석, 번역 등)를 수행하게 하는 최고 수준의 API
- AutoClasses (
AutoTokenizer,AutoModel, 등): 모델 아키텍처를 몰라도 체크포인트 이름만으로 적절한 토크나이저와 모델 클래스를 자동으로 로드하는 스마트 기능 - 모델링 유틸리티: 사전 훈련된 모델을 로드하고, 특정 작업에 맞게 미세조정(Fine-tuning)하며, 손쉽게 저장하고 공유할 수 있는 포괄적인 도구 모음
B. 지원 아키텍처
- 텍스트(NLP):
BERT,GPT,T5,BART등 수백 가지 트랜스포머 기반 모델 - 이미지(Vision):
ViT(Vision Transformer),DETR,CLIP,Stable Diffusion - 오디오(Audio):
Whisper,Wav2Vec2,HuBERT - 멀티모달(Multi-modal): 텍스트, 이미지, 오디오를 동시에 처리하는 모델
(pipeline을 이용한 제로샷 분류 코드 예시)
from transformers import pipeline
classifier = pipeline("zero-shot-classification", model="facebook/bart-large-mnli")
sequence_to_classify = "이 옷은 내 스타일이 아니야"
candidate_labels = ['패션', '음식', '정치', '스포츠']
result = classifier(sequence_to_classify, candidate_labels)
(3) Datasets
A. 핵심 특징
- Apache Arrow 포맷 기반: 데이터를 메모리에 올릴 때 제로-카피(Zero-copy) 읽기를 지원하여 극도로 빠른 데이터 로딩 및 처리 속도 보장
- 스트리밍(Streaming): 수백 기가바이트(GB)의 대용량 데이터셋도 전체를 다운로드하지 않고, 필요한 만큼 실시간으로 스트리밍하여 사용 가능 (메모리 절약)
- 메모리 매핑(Memory-mapping): 실제 데이터를 디스크에 저장한 채로 메모리에 있는 것처럼 접근하여, RAM 용량을 초과하는 데이터셋도 원활하게 처리
B. 주요 기능
- 통합된 로딩 스크립트:
load_dataset함수 하나로 허브에 있는 수만 개의 데이터셋은 물론, 로컬 파일(CSV, JSON, 텍스트 등)까지 동일한 방식으로 로드 - 강력한 전처리:
map,filter,shuffle등 직관적인 함수를 통해 대규모 데이터셋을 병렬로 빠르게 전처리
(데이터셋 로드 및 전처리 코드 예시)
from datasets import load_dataset
# SQuAD 데이터셋 로드 (스트리밍 모드)
squad_dataset = load_dataset("squad", split="train", streaming=True)
# 데이터셋의 첫 5개 샘플 확인
for i, example in enumerate(squad_dataset):
if i == 5:
break
(4) Tokenizers
A. 역할과 중요성
- 자연어(텍스트)를 AI 모델이 이해하고 처리할 수 있는 숫자 시퀀스(토큰 ID)로 변환하는 필수적인 전처리 과정
- 어떤 토크나이저를 사용하느냐에 따라 모델의 성능이 크게 달라질 수 있음
B. 주요 알고리즘
- BPE (Byte-Pair Encoding): 가장 빈번하게 등장하는 문자 쌍을 하나의 새로운 문자로 병합해 나가는 방식
- WordPiece: BPE와 유사하지만, 병합 시 데이터의 우도(Likelihood)를 기준으로 가장 높이는 쌍을 선택 (BERT에서 사용)
- SentencePiece: 텍스트를 공백 기준으로 나누지 않고, 모든 텍스트를 유니코드 문자로 취급하여 언어 종속성을 없앤 방식 (다국어 처리에 유리)
(AutoTokenizer 코드 예시)
from transformers import AutoTokenizer
# 한국어 BERT 모델의 토크나이저 로드
tokenizer = AutoTokenizer.from_pretrained("klue/bert-base")
# 텍스트 토큰화
text = "허깅페이스는 정말 강력한 도구입니다."
encoded_input = tokenizer(text)
# 원래 텍스트로 디코딩
decoded_text = tokenizer.decode(encoded_input["input_ids"])
(5) Accelerate
A. 목적
- 단 몇 줄의 코드 추가만으로 기존의 파이토치(PyTorch) 학습 코드를 다중 GPU, TPU, 또는 혼합 정밀도(Mixed Precision) 환경에서 실행할 수 있도록 변환
- 복잡한 분산 처리 설정(NCCL, DDP 등)을 직접 다루지 않아도 되게끔 추상화
B. 사용법
Accelerator객체를 생성하고, 학습 루프 시작 전에 모델, 옵티마이저, 데이터 로더를accelerator.prepare()메서드로 감싸기- 기존의
loss.backward()대신accelerator.backward(loss)를 사용
(Accelerate 코드 예시)
from accelerate import Accelerator
import torch
# 가상의 모델과 데이터로더
model = torch.nn.Linear(10, 2)
optimizer = torch.optim.Adam(model.parameters())
dataloader = [torch.randn(8, 10) for _ in range(10)]
# Accelerator 초기화 및 준비
accelerator = Accelerator()
model, optimizer, dataloader = accelerator.prepare(model, optimizer, dataloader)
# 학습 루프 (기존 코드와 거의 동일)
for batch in dataloader:
optimizer.zero_grad()
output = model(batch)
loss = output.sum()
accelerator.backward(loss)
optimizer.step()
(6) 모델 허브
A. 모델 검색 및 필터링
- 태스크 필터:
Text Classification,Image-to-Text,Text-to-Speech등 20가지가 넘는 세부 태스크로 원하는 기능의 모델을 정확히 필터링 - 라이브러리 필터:
PyTorch,TensorFlow,JAX,Safetensors등 특정 프레임워크나 모델 형식으로 검색 - 데이터셋 및 언어 필터: 특정 데이터셋으로 학습된 모델이나, 한국어 등 특정 언어를 지원하는 모델 검색
B. 모델 카드 (Model Card)
- 모델 세부 정보: 모델 아키텍처, 학습 설정(하이퍼파라미터), 학습에 사용된 데이터 등
- 사용법:
pipeline이나AutoClass를 이용한 구체적인 코드 예시 제공 - 편향, 한계 및 윤리적 고려사항: 모델이 가질 수 있는 사회적 편향성이나 잠재적 위험, 의도된 사용 범위와 그렇지 않은 범위를 명시하여 책임감 있는 사용 유도
| 활용 수준 | 활동 내용 |
|---|---|
| 초급 | 관심 있는 태스크의 모델을 검색하고, 온라인 추론 API로 성능 테스트 |
| 중급 | pipeline으로 모델을 불러와 사용하고, 모델 카드를 읽으며 모델의 특징 파악 |
| 고급 | 자신의 목적에 맞게 모델을 파인튜닝하고, 결과를 커뮤니티에 다시 공유 |
