왜 PEFT가 필요한지 알게 됐다.
학습시간 09:00~03:00(당일18H/누적1479H)
◆ 학습내용
리뷰 감성 분석 AI 구현하기!
지난 주에 이어 6번 부터 시작!
6. 모델 평가
지난 주 학습했던 두 모델을 평가할 차례다.

results 폴더에 잘 저장되어 있다!
# Full Fine Tunning 가중치 로드
fft_model_path = './results/fft/checkpoint-2890'
model_fft = AutoModelForSequenceClassification.from_pretrained(fft_model_path).to(device)
tokenizer = AutoTokenizer.from_pretrained(fft_model_path)
먼저 Full Fine Tunning 모델 가중치를 가져온다.
허깅페이스에서 모델 다운로드 받는 과정과 동일하다. 경로만 내껄로 바꿔주면 끝인 듯하다.
# PEFT LoRA 가중치 로드
base_model_path = "./model" # FacebookAI/xlm-roberta-base
lora_model_path = './results/lora/checkpoint-2890'
base_model = AutoModelForSequenceClassification.from_pretrained(base_model_path, num_labels=3, torch_dtype=torch.bfloat16)
model_lora = PeftModel.from_pretrained(base_model, lora_model_path).to(device)다음은 PEFT LoRA 모델 가중치를 가져온다.
LoRA 모델은 로드하는 게 살짝 까다롭다. 일단 튜닝시키기 전의 모델을 불러와야 한다. AutoModelForSequenceClassification 모듈로 베이스 모델을 가져오고, PeftModel 모듈로 그 위에 튜닝된 가중치를 덮어주어야 한다.
print(f"*"*100, "\n", {model_fft})
print(f"*"*100, "\n", {model_lora})잘 로드되었나 확인해 보자!
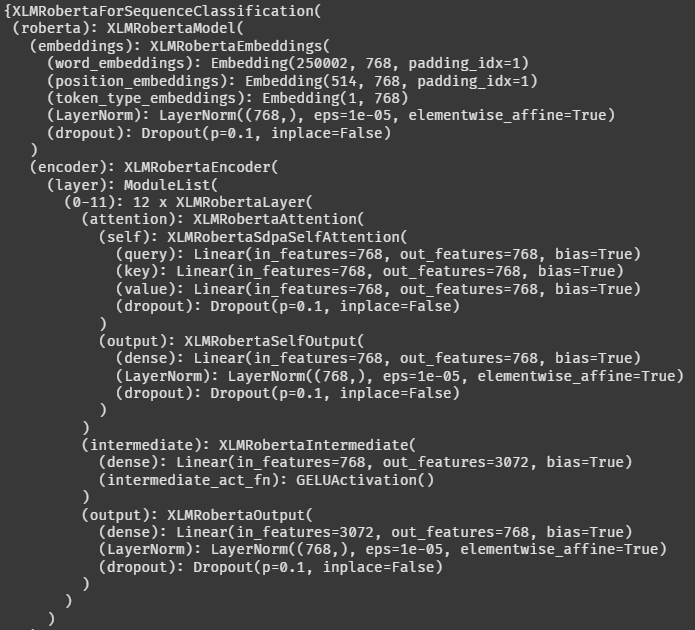
Full Fine Tunning 에서는 XLMRobertaModel이 로드됐다. facebook에서 가져온 모델 이름 그대로 출력되는 것 같다.
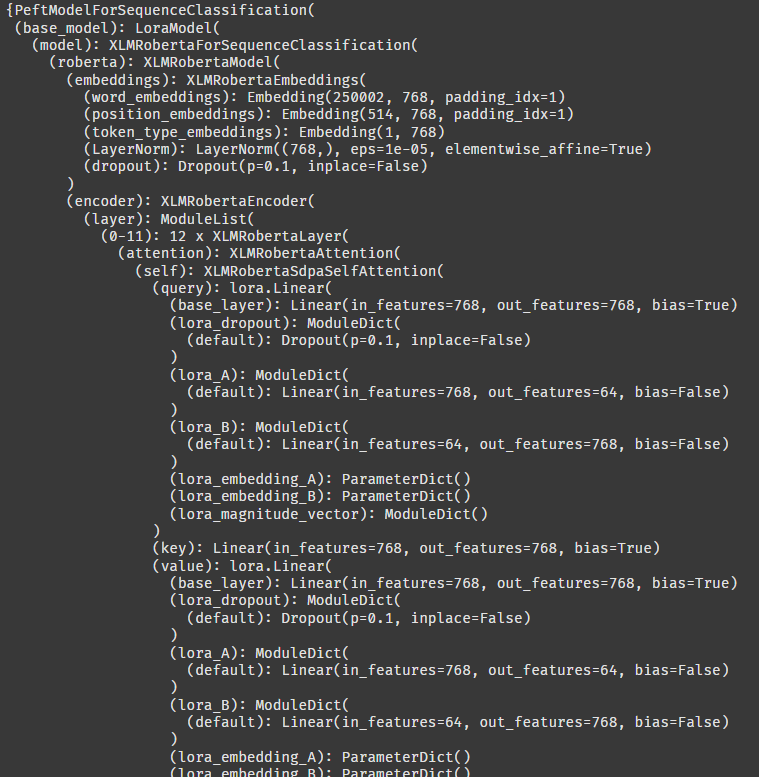
PEFT LoRA 에서는 LoraModel이라는 클래스 안에 XLMRobertaModel이 있는 것으로 보인다.
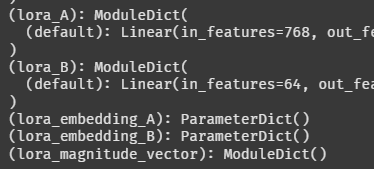
Full Fine Tunning 보다 모델 구조가 길어졌다. 아무래도 이건 이미지에서 보이는 것처럼 LoRA 구조가 베이스 모델에 추가되었기 때문인 것 같다.
""" 평가용 Arguments 설정 """
eval_args = TrainingArguments(
output_dir='./results/eval',
per_device_eval_batch_size=512,
report_to="none"
)평가를 위해 argument를 다시 설정해줬다. 배치는 동일하게 했다. 딱히 설정이랄 게 없는 것 같은데,,, 이게 꼭 필요한 건지 잘 모르겠다.
""" Full Fine Tuning 모델 평가 """
trainer_fft = Trainer(
model=model_fft,
args=eval_args,
eval_dataset=tokenized_test_dataset,
compute_metrics=compute_metrics
)
fft_metrics = trainer_fft.evaluate()
fft_metrics['model'] = 'Full Fine Tuning'
""" PEFT LoRA 모델 평가 """
trainer_lora = Trainer(
model=model_lora,
args=eval_args,
eval_dataset=tokenized_test_dataset,
compute_metrics=compute_metrics
)
lora_metrics = trainer_lora.evaluate()
lora_metrics['model'] = 'PEFT LoRA'FFT, PEFT를 평가 후에 metric['모델명']으로 저장했다. 이대로 호출하면 될듯!
""" 평가 실행 """
results_df = pd.DataFrame([fft_metrics, lora_metrics])
results_df = results_df.set_index('model')
print("\n[ 모델 성능 평가 ]")
print(results_df[['eval_loss', 'eval_accuracy', 'eval_f1']])로스, 정확도, f1 스코어로 평가해 보자.
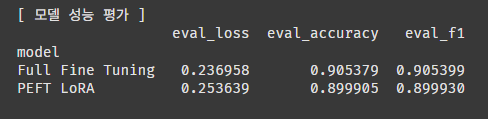
두둥탁! 정확도에서 0.5% 정도 차이가 나지만, 사실 이정도면 수치적으로는 성능 차이가 없다고 봐도 무방할 것 같다.
그럼 신규 텍스트를 입력값으로 주어도 감성을 잘 분류할지 테스트해 봐야겠다.
def predict_sentiment(model, tokenizer, text):
model.eval()
inputs = tokenizer(text, return_tensors="pt", padding=True, truncation=True, max_length=128).to(device)
with torch.no_grad():
outputs = model(**inputs)
probs = F.softmax(outputs.logits, dim=-1)
prediction = torch.argmax(probs, dim=-1).item()
labels = ['부정', '중립', '긍정']
return labels[prediction], probs.cpu().numpy()[0]신규 텍스트 예측용 함수를 하나 만들었다.
새로 들어오노 텍스트를 토큰화한 뒤 패딩을 입히고 로드했던 모델 가중치를 사용해서 에측을 진행한다. 최종 출력은 소프트맥스로 바꿔서 라벨 3개에 대한 확률을 계산해 준다.
""" 신규 텍스트 입력 """
sample_text = "처음에는 괜춘 근데 갈수록 별로네요 ㅠㅠ"신규 텍스트를 뭐로 할까 고민하다가,,, 대충 헷갈릴 것 같은 문장을 넣어봤다. 과연 '괜춘' 이라는 단얼르 잘 인식할까? '갈수록' 별로라는 건 처음에는 괜찮았다는 뜻인데, 이 숨겨진 뜻을 잘 캐치할까?
# Full Fine Tuning 모델 예측
fft_prediction, fft_probs = predict_sentiment(model_fft, tokenizer, sample_text)
print("[ Full Fine Tuning 모델 예측 ]")
print(f"리뷰: {sample_text}")
print(f"예측: {fft_prediction}")
print(f"확률 (부정, 중립, 긍정): {fft_probs}\n")먼저 FFT 예측 실행!
헉? 에러가 떴다. BFloat16 형태는 지원하지 않는다고 한다.
아! 내가 이번에 BFloat16으로 모델을 불러와서 그렇구나. 지원하지 않으면 어떡하지?? 처음부터 학습을 다시 돌려야하나?
return labels[prediction], probs.cpu().float().numpy()[0]찾아보니 float()을 넣어서 다시 형태를 변경해주면 된다고 한다. 현재 numpy 버전에 bfloat 타입이 업데이트 되어 있지 않아서 발생하는 문제라고 한다.
오케이 다시 실행해 보자!

결과가 잘 나왔다.
부정일 확률이 약 85%다. 잘 맞춘 것 같다!!
# PEFT LoRA 모델 예측
lora_prediction, lora_probs = predict_sentiment(model_lora, tokenizer, sample_text)
print("[ PEFT LoRA 모델 예측 ]")
print(f"리뷰: {sample_text}")
print(f"예측: {lora_prediction}")
print(f"확률 (부정, 중립, 긍정): {lora_probs}")LoRA 모델로도 예측해 보자!

부정일 확률이 약 67%다. 아마도 '처음에는 괜춘' 이라는 단어에 더 많은 가중치를 준 것이 아닐까 생각해 본다.
사실 어떤 모델이 더 정확하다고 판단할 수는 없을 것 같다. 부정적인 리뷰이긴 하지만, 처음에는 괜찮았다는 점에서 회생의 여지가 있는 사용자이기 때문이다. 그럼 부정 확률을 67%로 예측한 LoRA 모델이 조금 더 가까운 정답일 테다. 엔지니어의 생각에 따라 그 반대가 될 수도 있을 것이고.
7. 모델 비교
두 모델을 여러 방면에서 비교해 보자.
| 항목 | Full Fine Tuning | PEFT LoRA |
|---|---|---|
| 학습 속도 (10에폭, 512배치) | 17:30 | 20:00 |
| 모델 구조 | Base Model 동일 | Base Model 이상 |
| model.safetensors 용량 | 530MB | 10MB |
| optimizer.pt 용량 | 1030MB | 20MB |
| tokenizer.json 용량 | 16MB | 16MB |
| eval_loss | 0.236958 | 0.253639 |
| eval_accuracy | 0.905379 | 0.899905 |
| eval_f1 | 0.905399 | 0.899930 |
신규 텍스트 예측
- 리뷰: 처음에는 괜춘 근데 갈수록 별로네요 ㅠㅠ
- Full Fine Tuning 부정 85% & 중립 15%
- PEFT LoRA 부정 67% & 중립 32%
결과적으로, 정확도가 유의미하게 차이나지 않는 PEFT 방식이 모델 용량 대비 엄청난 이점이 있다.
특히나 모델을 서버에 여러 개 올려두어야 하는 상황을 고려하면 PEFT 말고는 선택폭이 없지 않을까 생각해 본다.
앞으로 LLM 파라미터 수가 지금보다 100배 늘어난다 해도 PEFT를 하면 1GB 정도 수준일 테니,,, 여기에 양자화까지 하면 더 줄어들겠지? 엄청난 기술이다 정말.
어쨌든 이번 미션도 무사히 완료!
