아무것도 이해하지 못했다. 흐름 자체를 모르겠다... 망했다 ㅠㅠ
학습시간 09:00~03:00(당일18H/누적1497H)
◆ 학습내용
RAG 한눈에 보기
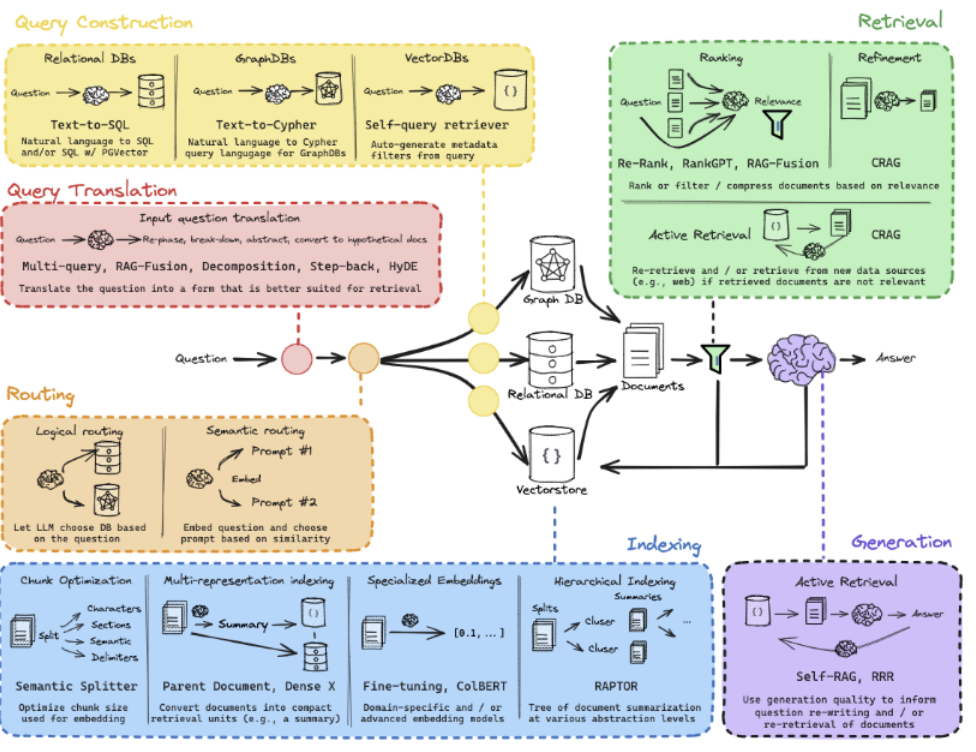
1. RAG
(1) 특징
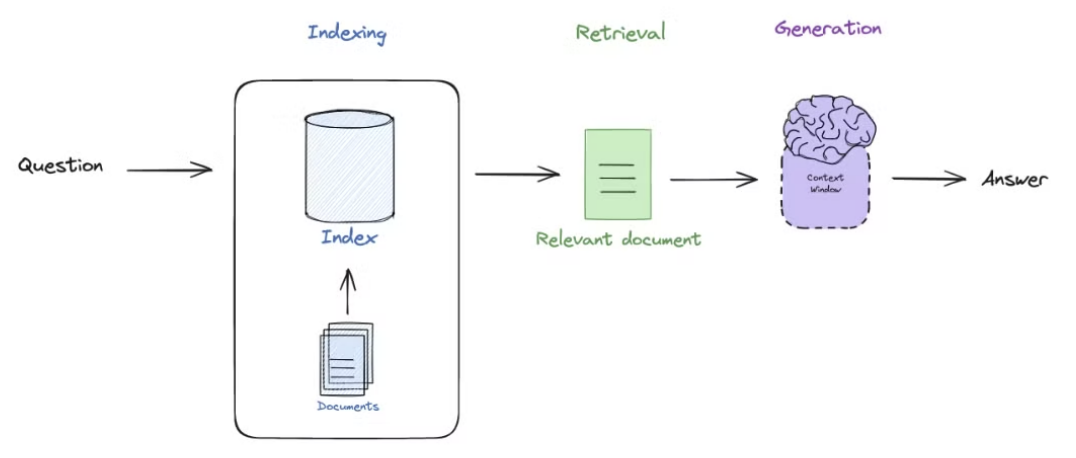
- 검색 증강 생성(Retrieval Augmented Generation)의 약자
- 대규모 언어 모델(LLM)이 외부 지식 베이스의 정보에 접근하여 답변을 생성하도록 하는 기술
- 환각(Hallucination) 현상을 극복하기 위해 제안되었음
- Indexing -> Retrieval -> Generation 순서로 진행
(2) Indexing
- RAG 파이프라인의 준비 단계
- 외부 문서를 LLM이 참조하기 좋은 형태로 가공하여 데이터베이스(주로 Vector DB)에 저장
- 사용자가 질문하기 전에 미리 한 번만 수행하면 되는 오프라인(Offline) 작업
- Load -> Split -> Embed -> Store 순서로 진행
- Load: PDF, TXT, HTML 등 다양한 포맷의 원본 문서를 불러옴
- Split: 문서를 작은 조각(Chunk)로 나눔. 길면 검색 효율 감소 & 짧으면 의미 파악이 어려움
- Embed: Chunk를 임베딩 모델을 사용하여숫자 벡터(Vector)로 변환
- Store: 벡터를 빠르게 검색할 수 있도록 벡터 DB에 저장
import torch
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import FAISS
# 1. Load (실제로는 PDF, TXT 파일 로더 사용)
documents = [
"RAG는 Retrieval-Augmented Generation의 약자입니다.",
"RAG는 LLM의 환각 현상을 줄이기 위해 외부 지식을 활용하는 기술입니다.",
"인덱싱은 문서를 벡터로 변환하여 벡터 DB에 저장하는 과정입니다.",
"검색 단계에서는 사용자 질문과 가장 유사한 문서를 벡터 DB에서 찾습니다.",
"생성 단계에서는 검색된 문서와 질문을 LLM에 함께 제공하여 답변을 만듭니다."
]
# 2. Split
text_splitter = CharacterTextSplitter(chunk_size=300, chunk_overlap=20)
docs = text_splitter.create_documents(documents)
# 3. Embed
model_name = "jhgan/ko-sbert-nli"
model_kwargs = {'device': 'cuda' if torch.cuda.is_available() else 'cpu'}
encode_kwargs = {'normalize_embeddings': True}
embedding_model = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)
# 4. Store
vector_db = FAISS.from_documents(docs, embedding_model)
vector_db.save_local("my_faiss_index")(3) Retrieval
- 사용자가 질문을 던졌을 때 가장 관련 있는 정보를 벡터 DB에서 실시간으로 찾아내는 과정
- Query Embedding -> Similarity Search -> Return Chunks 순서로 진행
- Query Embedding: 사용자의 질문을 임베딩 모델을 사용하여 벡터로 변환
- Similarity Search: 질문 벡터와 저장 문서 벡터의 유사도 계산
- Return Chunks: 유사도가 가장 높은 문서 조각(Chunk) 반환
import torch
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import FAISS
# 1. 인덱싱 단계에서 사용한 임베딩 모델과 동일한 모델 로드
model_name = "jhgan/ko-sbert-nli"
model_kwargs = {'device': 'cuda' if torch.cuda.is_available() else 'cpu'}
encode_kwargs = {'normalize_embeddings': True}
embedding_model = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)
# 2. 저장해둔 벡터 DB 로드
vector_db = FAISS.load_local("my_faiss_index", embedding_model, allow_dangerous_deserialization=True)
# 3. 사용자 질문에 대해 유사도 검색 수행
user_query = "RAG가 뭐야?"
retrieved_docs = vector_db.similarity_search(user_query, k=2) # 가장 유사한 2개 문서 검색
# 검색 결과 확인
print(f"\n 사용자 질문: {user_query}")
print("검색된 문서:")
for i, doc in enumerate(retrieved_docs):
print(f" [{i+1}] {doc.page_content}")(4) Generation
- RAG 파이프라인의 마지막 단계
- Retrieval 단계에서 찾은 정보와 사용자의 질문을 LLM에 전달하여 답변을 만들어내는 과정
- Prompting -> Generation 순서로 진행
- Prompting: 템플릿에 맞게 조합하여 LLM에게 전달할 프롬프트를 만듦
- Generation: 프롬프트를 바탕으로 답변을 새롭게 생성
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
# 1. 답변 생성을 위한 실제 LLM 로드 (google/gemma-2b-it)
model_id = "google/gemma-2b-it"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="auto",
torch_dtype=torch.bfloat16
)
# 2. 검색된 문서를 하나의 '문맥(Context)'으로 결합
context = "\n".join([doc.page_content for doc in retrieved_docs])
# 3. LLM에게 지시할 프롬프트 템플릿 정의
chat_template = [
{
"role": "user",
"content": f"""너는 주어진 정보를 바탕으로 질문에 대답하는 AI야. 반드시 아래 '정보' 안에서만 사실에 기반하여 답변해줘.
### 정보:
{context}
### 질문:
{user_query}
""",
}
]
# 모델의 채팅 템플릿에 맞게 프롬프트 가공
prompt = tokenizer.apply_chat_template(
chat_template,
tokenize=False,
add_generation_prompt=True
)
# 4. LLM을 호출하여 답변 생성
generator = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
)
outputs = generator(
prompt,
max_new_tokens=256, # 생성할 최대 토큰 수
do_sample=True,
temperature=0.3, # 높을수록 창의적인 답변 생성
)
# 생성 결과 확인
print(f"\n사용자 질문: {user_query}")
print(f"\n참조한 문맥:\n{context}")
# 프롬프트를 제외한 순수 답변만 출력
final_answer = outputs[0]['generated_text'][len(prompt):]
print(f"\n최종 답변:\n{final_answer.strip()}")
AI Engineer