LLM의 고질적 문제인 할루시네이션을 해결하는 다양한 방법을 알게 됐다. 확실히 최근 논문이라 어려운 부분이 많다. 이렇게 해도 할루시네이션을 완전 극복할 수 없다는 건 앞으로 발전할 여지가 많다는 뜻이겠지...!
학습시간 09:00~03:00(당일18H/누적1515H)
◆ 학습내용

Retrieval-Augmented Generation for Large Language Models: A Survey 논문
1. RAG의 역사
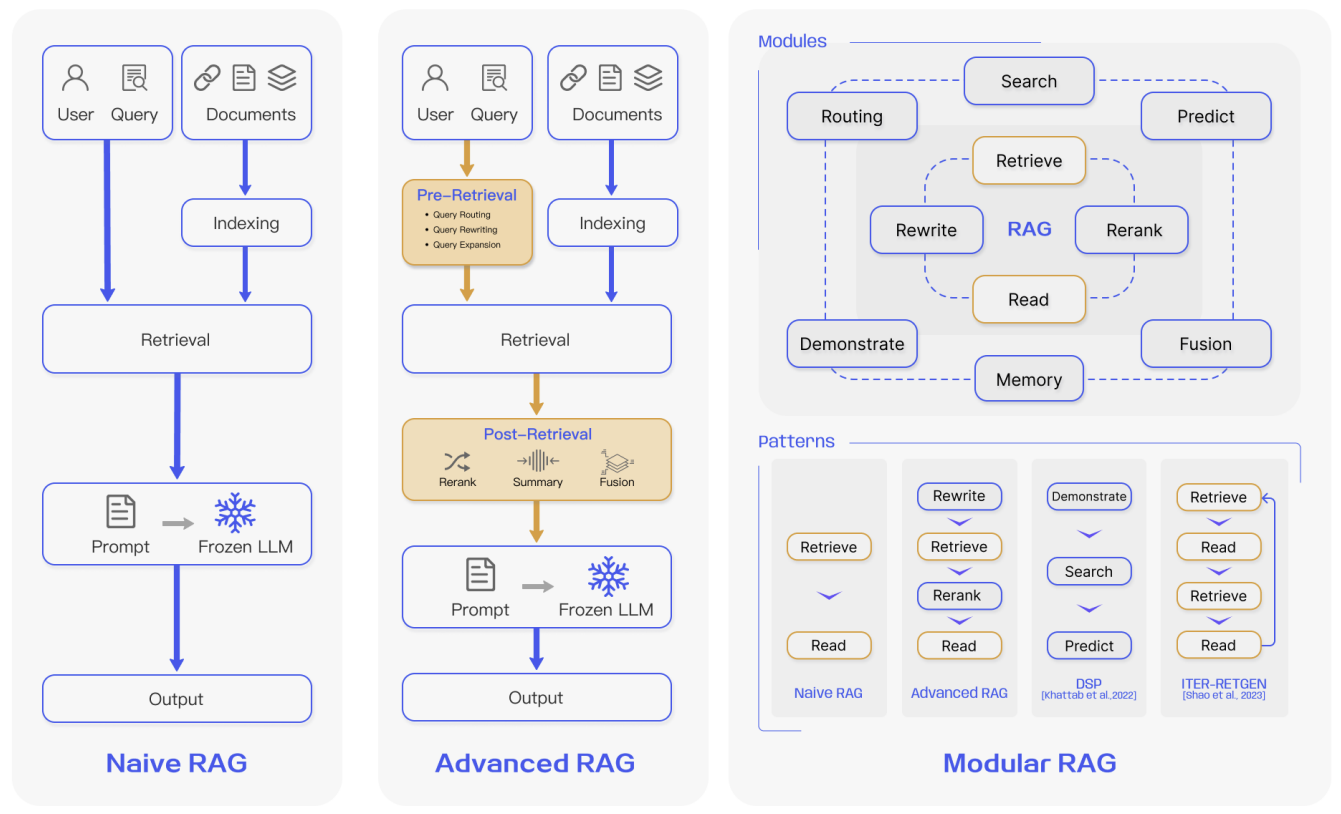
(1) Naive RAG
- '검색 후 읽기(Retrieve-Read)' 프레임워크를 따르는 초기 RAG 방식
- 색인, 검색, 생성의 전통적인 순차적 프로세스를 따름
- 검색 정확도 저하, 생성 시 환각, 비효율적인 정보 통합 등 여러 한계점에 직면
(2) Advanced RAG
- Naive RAG의 단점을 보완하기 위해 등장
- 검색 전(Pre-retrieval) 및 검색 후(Post-retrieval) 단계에 특정 최적화 전략을 도입하여 검색 품질을 향상
- 주요 전략으로 인덱싱 최적화, 쿼리 변환, 검색 결과 재정렬(reranking) 및 압축 등이 있음
(3) Modular RAG
- 기존 패러다임을 계승하며 높은 유연성과 적응성을 제공
- 검색, 라우팅, 메모리, 퓨전 등 다양한 기능 모듈을 도입하거나 교체하여 사용
- 순차적 프로세스를 넘어 반복적, 적응적 검색 등 다양한 패턴(Patterns)을 구현
2. RAG 접근 방식
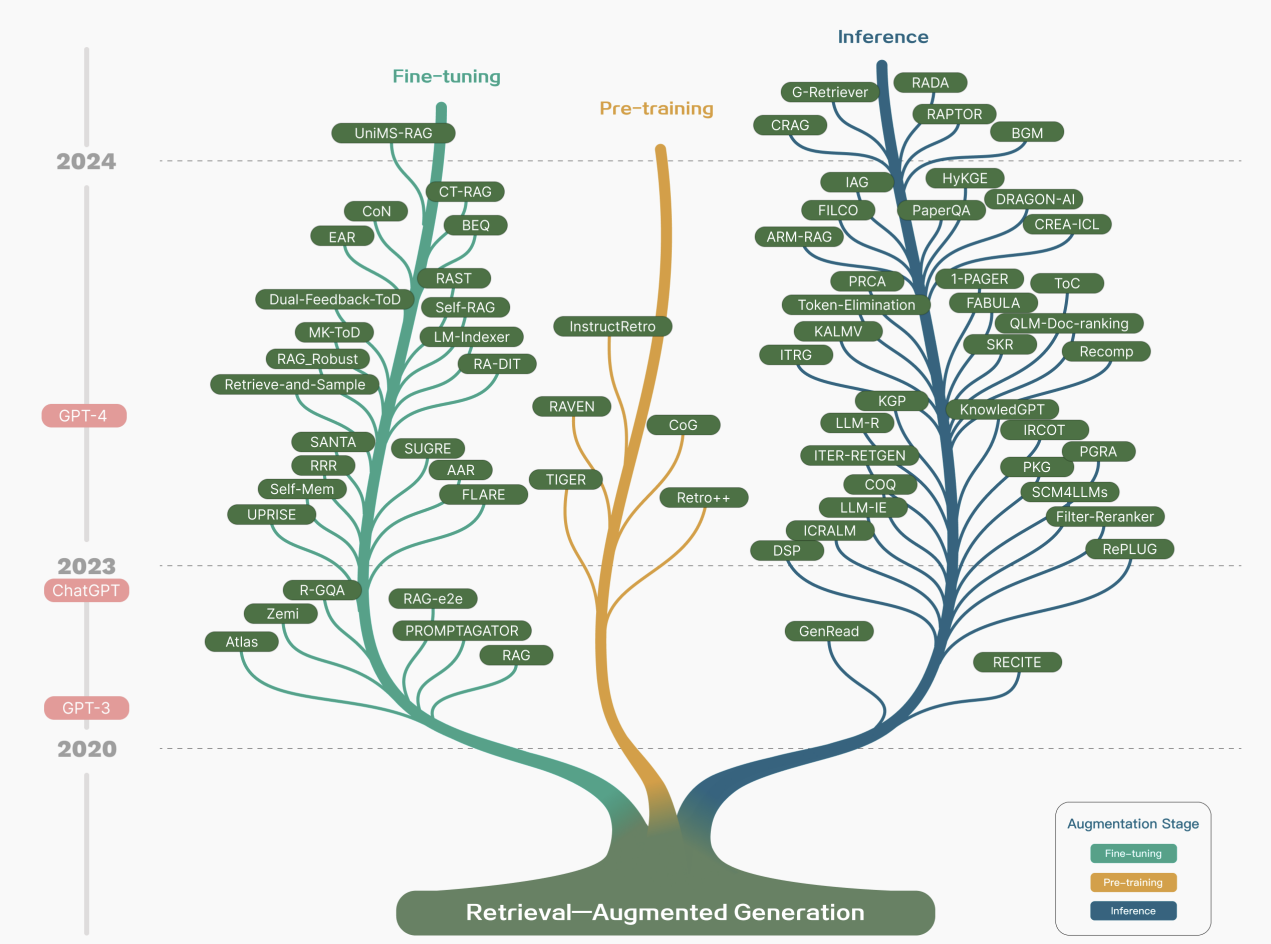
(1) Pre-training
- 모델의 기초 지식을 구축하는 단계부터 외부 정보를 통합
- 언어 모델을 처음부터 학습시킬 때 외부 데이터베이스를 참조하도록 설계
- 파라미터 자체에 외부 지식이 내재되어 정확한 기반을 가진 모델을 만들 수 있음
(2) Fine-tuning
- 이미 학습된 모델을 특정 작업이나 전문 분야에 맞게 최적화
- 일반 LLM을 특정 도메인(예: 법률, 의료)에 맞게 파인튜닝할 때 RAG를 사용
- 검색된 정보를 특정 작업의 맥락에 맞게 효과적으로 응답하는 방법을 학습
(3) Inference
- 질문에 답변하는 실시간 활용 단계에서 최신 정보나 특정 정보를 제공
- 가중치는 변경하지 않고 질문이 들어왔을 때 정보를 검색해서 프롬프트에 포함
- 학습 시점 이후의 최신 정보, 내부적으로 알지 못했던 지식에 대해서도 답변 가능
- ChatGPT 같은 LLM이 등장하면서 이 방식이 크게 주목받음
3. RAG 핵심 기술
(1) Retrieval 최적화
A. 검색 소스 및 단위
- 검색 소스: 초기 비정형 텍스트(위키피디아 등)에서 반정형(PDF), 정형(지식그래프) 데이터로 확장
- LLM 생성 콘텐츠: LLM이 직접 생성한 콘텐츠를 검색 소스로 활용하는 연구도 활발
- 검색 단위(Granularity): 토큰, 구, 문장, 명제(Proposition), 청크, 문서 등 작업에 따라 최적의 단위를 선택하는 것이 중요
B. Indexing 최적화
- 청킹 전략: 고정 크기 분할 외에 재귀적 분할, Small2Big(작은 단위로 검색, 큰 단위로 컨텍스트 제공) 등 사용
- 메타데이터 활용: 페이지 번호, 파일명, 날짜 등의 메타데이터를 첨부하여 필터링하거나 가중치 부여
- 구조적 인덱스: 문서 간 계층 구조나 지식 그래프(KG)를 활용하여 인덱스를 구축, 검색 효율성 및 정확도 향상
C. Query 최적화
- 쿼리 확장(Expansion): 단일 쿼리를 여러 하위 쿼리로 확장하거나, 검증 단계를 추가해 환각 감소
- 쿼리 변환(Transformation): LLM을 사용해 사용자의 원본 쿼리를 검색에 더 적합한 형태로 재작성(Rewrite)하거나, 가상의 답변(HyDE)을 생성해 활용
- 쿼리 라우팅(Routing): 쿼리의 특성에 따라 메타데이터 또는 의미 기반으로 최적의 RAG 파이프라인으로 안내
D. Embedding
- 모델 선택: 최신 임베딩 모델(BGE, Voyage 등)을 사용하며, 특정 작업에 더 적합한 모델을 선택하는 것이 중요
- 임베딩 파인튜닝: 특정 도메인(의료, 법률 등) 데이터셋으로 임베딩 모델을 파인튜닝하여 성능 극대화
(2) Generation 최적화
A. 컨텍스트 큐레이션(Context Curation)
- 재정렬(Reranking): 검색된 문서 청크들을 다시 정렬하여 가장 관련성 높은 정보를 프롬프트의 앞이나 뒤에 배치
- 컨텍스트 압축/선택: 불필요한 토큰을 제거하거나(LongLLMLingua), 정보 추출기를 학습시켜 핵심 정보만 남겨 노이즈를 줄임
B. LLM 파인튜닝
- 지식 주입: 특정 도메인에 대한 데이터가 부족할 경우 파인튜닝을 통해 지식 보충
- 입출력 조정: 특정 데이터 형식에 적응하거나, 지시된 스타일로 응답을 생성하도록 모델의 동작 조정
- 리트리버와 정렬: 리트리버와 생성기 간의 선호도를 일치시키기 위해 공동으로 파인튜닝
(3) Augmentation
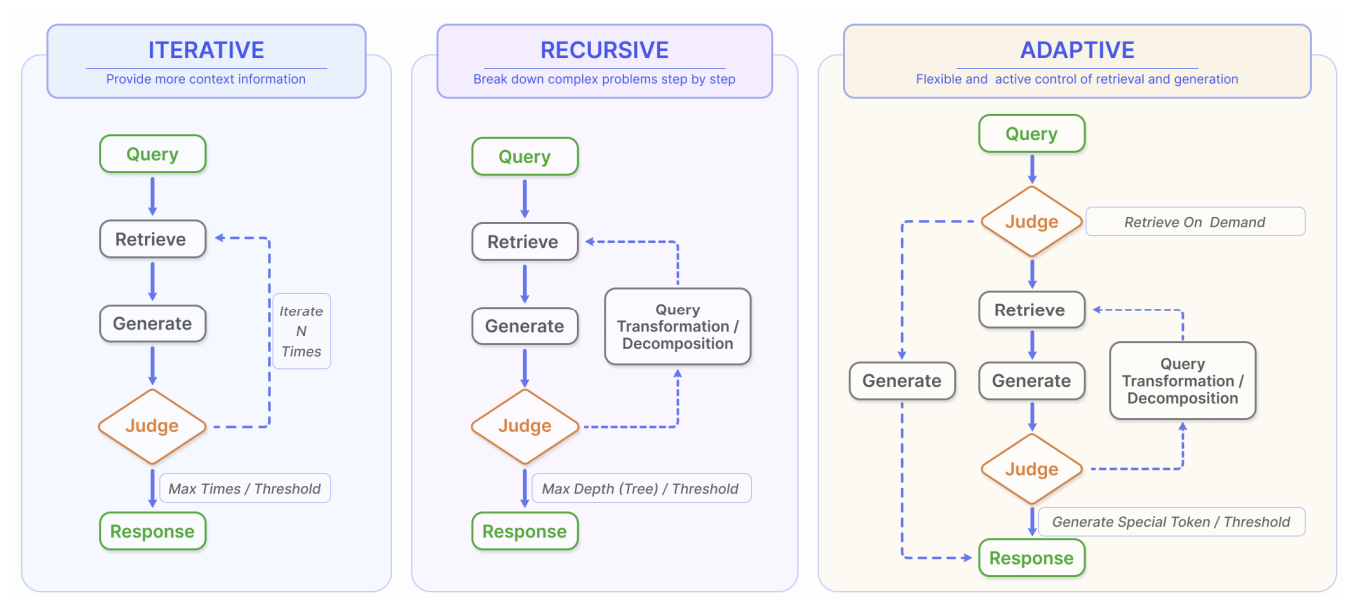
- Iterative Retrieval: 초기 검색 및 생성 후, 그 결과를 바탕으로 다시 지식 베이스를 검색하는 과정을 반복
- Recursive Retrieval: 복잡한 문제를 하위 문제로 분해하고, 각 단계의 검색 결과를 바탕으로 쿼리를 정제하며 점진적으로 해결
- Adaptive Retrieval: LLM이 스스로 검색이 필요한 순간과 내용을 판단하여 능동적으로 검색을 수행 (e.g., Self-RAG)
3. RAG 평가 및 전망
(1) RAG 평가
A. 평가 대상 및 항목
- 주요 평가 대상: 검색 품질(Retrieval Quality)과 생성 품질(Generation Quality)
- 품질 점수: 컨텍스트 관련성, 답변의 충실성(Faithfulness), 답변의 관련성 등 3가지 품질 점수로 평가
- 필수 능력: 노이즈 강건성, 부정확한 정보에 대한 답변 거부 능력, 정보 통합 능력, 반사실적(Counterfactual) 강건성 등 4가지 능력을 평가
B. 평가 벤치마크 및 도구
- 벤치마크: RGB, RECALL, CRUD 등 RAG 모델의 핵심 능력을 종합적으로 평가하기 위한 벤치마크가 제안됨
- 자동화 도구: RAGAS, ARES, TruLens와 같이 LLM을 심판(judge)으로 사용하여 품질 점수를 자동으로 평가하는 도구들이 개발됨
(2) 미래 전망
A. 주요 도전 과제
- 긴 컨텍스트(Long Context)와의 관계: LLM의 컨텍스트 길이가 늘어남에 따라, RAG의 역할과 상호작용 방식에 대한 새로운 연구 필요
- 강건성(Robustness): 검색된 정보에 노이즈나 모순이 있을 때 RAG 시스템이 얼마나 안정적으로 작동하는지에 대한 연구 필요
- 하이브리드 접근법: RAG와 파인튜닝을 어떻게 최적으로 결합할 것인지가 중요한 연구 주제
B. 생태계 확장
- 프로덕션 환경(Production-Ready): 검색 효율성, 데이터 보안 등 실제 상용 환경에서의 문제 해결이 중요
- 기술 스택 발전: LangChain, LlamaIndex 같은 프레임워크와 다양한 특화 도구들이 등장하며 생태계가 빠르게 성장 중
- 다중 모달(Multi-modal) RAG: 텍스트를 넘어 이미지, 오디오, 비디오, 코드 등 다양한 데이터 양식을 처리하는 방향으로 확장
4. 문제
대규모 언어 모델(LLM)이 환각, 오래된 지식, 불투명한 추론 과정과 같은 문제에 직면할 때, RAG(Retrieval-Augmented Generation)가 어떻게 이러한 문제들을 해결하는 유망한 솔루션으로 부상했는지 설명하세요.
- 외부 데이터베이스로부터 최신 지식을 통합하여 LLM의 정보가 낡은 문제를 해결
- 검색된 외부 근거를 참조함으로써 사실과 다른 내용 생성을 효과적으로 줄여 환각 현상을 완화
- 외부 데이터 소스를 명시적으로 참조하기 때문에 생성된 답변의 정확성과 신뢰성을 높이고 추론 과정의 투명성을 확보
RAG가 LLM의 본질적인 지식과 외부 데이터베이스의 방대하고 동적인 저장소를 어떻게 시너지 효과를 내어 통합하는지 설명하세요.
- LLM의 내재된 파라미터 지식과 외부 데이터베이스의 동적인 정보를 결합하여 답변 생성
- 사용자 질문과 검색된 외부 문서를 결합하여 포괄적인 프롬프트를 구성하고 이를 LLM에 전달
- 작업에 따라 LLM이 내재된 지식을 활용하거나, 제공된 외부 문서 내의 정보로 답변을 제한하도록 조절 가능
논문에서 언급된 RAG 패러다임의 세 가지 주요 진행 단계는 무엇이며, 각 단계는 어떤 특징을 가지나요?
- Naive RAG: '검색-읽기'의 전통적 프로세스를 따르는 초기 단계로, 색인, 검색, 생성의 단순한 구조를 가짐
- Advanced RAG: Naive RAG의 한계를 극복하기 위해 검색 전후(pre/post-retrieval) 최적화 전략을 도입하여 검색 품질을 향상
- Modular RAG: 검색, 재작성, 재정렬 등 다양한 기능 모듈을 도입하고, 반복적 또는 적응적 검색 같은 유연한 파이프라인 구성이 가능
RAG 프레임워크의 삼자(tripartite) 기반을 구성하는 세 가지 핵심 요소는 무엇이며, 이 요소들이 RAG 시스템에서 어떤 역할을 하는지 간략하게 설명하세요.
- 검색(Retrieval): 사용자 쿼리를 기반으로 외부 지식 소스에서 관련 정보를 효율적으로 찾아내는 역할
- 생성(Generation): 검색된 정보와 원본 쿼리를 바탕으로 LLM이 최종 답변을 논리적으로 구성하고 생성하는 역할
- 증강(Augmentation): 검색 및 생성 과정을 최적화하는 기술들로, 반복적 검색이나 적응형 검색 등 다양한 전략을 통해 시스템 전체의 성능을 향상
Naive RAG의 전통적인 프로세스인 ‘색인(indexing)’, ‘검색(retrieval)’, ‘생성(generation)’ 각각의 단계를 간략하게 설명하고, 이 과정에서 어떤 주요 문제점들이 발생하는지 언급하세요.
- 색인: 원본 데이터를 정리 및 분할하여 벡터로 변환하고 벡터 데이터베이스에 저장
- 검색: 사용자 질문을 벡터로 변환한 후, 데이터베이스에서 의미적으로 가장 유사한 상위 K개의 청크를 검색
- 생성: 검색된 청크와 원본 질문을 프롬프트로 결합하여 LLM이 최종 답변을 생성하며, 이 과정에서 낮은 검색 정확도, 환각, 정보 통합의 어려움 등 문제 발생
RAG에서 검색(Retrieval) 소스의 유형은 초기 텍스트에서 어떻게 확장되었으며, LLM이 생성한 콘텐츠를 검색 소스로 활용하는 최근 연구 동향은 무엇인가요?
- 초기에는 비정형 텍스트 위주였으나, 이후 PDF와 같은 반정형 데이터와 지식 그래프(KG) 같은 정형 데이터로 확장
- 최근에는 외부 정보의 한계를 극복하기 위해 LLM의 내부 지식을 활용하는 연구가 진행
- LLM 자체가 생성한 콘텐츠를 검색 소스로 사용하며, 이는 LLM의 사전 학습 목표와 더 잘 부합하여 더 정확한 답변을 유도 가능
검색 세분성(Retrieval Granularity)은 검색 결과와 다운스트림 태스크 성능에 어떤 영향을 미치며, 텍스트에서 검색 세분성의 범위는 어떻게 되나요?
- 세분성이 너무 굵으면(coarse-grained) 불필요한 노이즈가 포함될 수 있고, 너무 잘면(fine-grained) 의미적 무결성을 해칠 수 있음
- 적절한 검색 세분성을 선택하는 것은 검색 및 다운스트림 태스크의 성능을 향상시키는 간단하고 효과적인 전략
- 텍스트에서의 검색 세분성은 토큰(Token), 구(Phrase), 문장(Sentence), 명제(Proposition), 청크(Chunks), 문서(Document) 등 다양함

AI Engineer