published: 2021.02.26
Code: https://github.com/openai/CLIP
blog : https://openai.com/index/clip/
Paper: https://arxiv.org/pdf/2504.07104v1

OpenAI 블로그에서 이뻐서 퍼왔다.
2023년 GPT-4, LLaVA등 다양한 Large Multimodal Model (LMM)들이 발표된 VLM/LLM 들의 시초 연구라고할 수있다. 시간이 흘러서 한번 정리할 필요성이 있어서 글로 정리해보고자 한다.
제안 배경
나는 정보 글을 읽을 때 왜 이 글이 나왔는지에 대한 동기를 생각하면서 읽는다. CLIP 논문도 마찬가지이다. 왜 나왔을까?
NLP 발전에서 배우자
2017년 Transformer가 나오고 난 뒤, 자연어 처리는 비약적인 성장을 맞이하게 된다(내생각). RNN, LSTM의 변형과 Attention을 어떤식으로 처리하면 더 낫지라는 발상으로 진행되던 연구는 Transformer을 어떻게 효율적으로 변형시킬지로 패러다임이 바뀌면서 BERT, GPT가 나오게 된다. 이후 빅데이터로 학습한 사전학습 모델으로 또 한번 성장을 하게 된다.
나는 해당 CLIP 논문이 NLP가 사전학습 모델로 다양한 테스크에서 zero-shot / few-shot으로도 좋은 성능을 내는 것을 보고 vison에서도 똑같이 접근하여 이미지 분야에서의 범용모델을 제작한 것이라고 생각한다.
핵심 아이디어: 자연어를 레이블로 활용하자.
인터넷에 접속하면 SNS, News, 웹사이트에 수억 장의 이미지와 텍스트가 함께 존재한다. 이 텍스트는 사람이 직접 라벨링한 것은 아니지만, 대체로 이미지의 의미를 자연스럽게 설명한다. CLIP은 이것을 이용한다. 자연어 텍스트를 이용해 학습을 하고자 한다. 근데, 이걸 지도학습으로 진행하기엔 한계점이 존재한다.
지도학습의 문제점(CLIP이 sefl-supervised learning을 채택한 이유)
- 데이터 수집 측면
지도학습은 라벨링된 데이터가 고비용(라벨러가 작성함)이고 스케일 확장에 제한이 존재한다. 또한 새로운 테스크나 클래스가 등장할 때마다 다시 학습이 필요하다. 즉, 범용 모델을 만들기엔 고비용의 데이터를 끝도 없이 수집해야한다.
- 학습 측면
데이터를 수집한다고 지도학습의 문제가 해결되진 않는다. 데이터셋의 중심으로 학습을 진행하더라도 좋은 성능을 입증하려면 결국 특정 벤치마크에 최적화(overfitting) 되어 실제 현실 데이터에서 성능이 저하된다. 실제로 비전 모델을 사용하면, 도메인 갭으로 인한 성능 차이를 체감할 수 있다. 논문에서는 이러한 문제를 “벤치마크를 위한 모델 설계가 실제 일반화에는 불리하다”라고 지적한다.
- 데이터 측면
기존 이미지-텍스트 학습 방식은 소규모 캡션 데이터셋(COCO, Visual Genome 등)은 도메인이 협소하고 편향되어있다.
이런 부분이 CLIP에서는 Contrastive Learning을 제안한 이유가 된다.
CLIP의 목표
대규모 웹 이미지 -텍스트 쌍을 활용해, 자연어로 학습하는 범용 비전 모델을 만들어 보자.
- 사람 처럼 자연어 설명만으로 새로운 태스크에 대응할 수 있는 모델을 개발하자.
- 사전학습이후에도 별도의 학습없이 제로샷으로 다양한 테스크에 적용 가능한 모델을 만들자.
- 간단한 구조와 효율적인 학습을 통해 강력한 일반화 성능을 가진 모델을 만들어보자.
기여 사항
- 인터넷에 공개된 대규모 이미지-텍스트 쌍(4억 쌍)을 모아 WebImageText(WIT)라는 새로운 데이터셋을 구축함
- 이미지 인코더와 텍스트 인코더를 동시에 학습시켜 같은 표현 공간에서 이미지와 텍스트를 연관 짓는 CLIP 모델을 개발함
- 별도의 파인 튜닝 없이도 CLIP이 다양한 데이터셋에서 제로샷 분류 성능을 발휘함(특히 ImageNet 분류에서 학습 없이도 기존 ResNet-50 수준의 정확도를 달성함)
- CLIP의 사전 학습 모델 가중치와 코드를 공개하여 확장 연구를 할 수 있도록 하였음
방법론
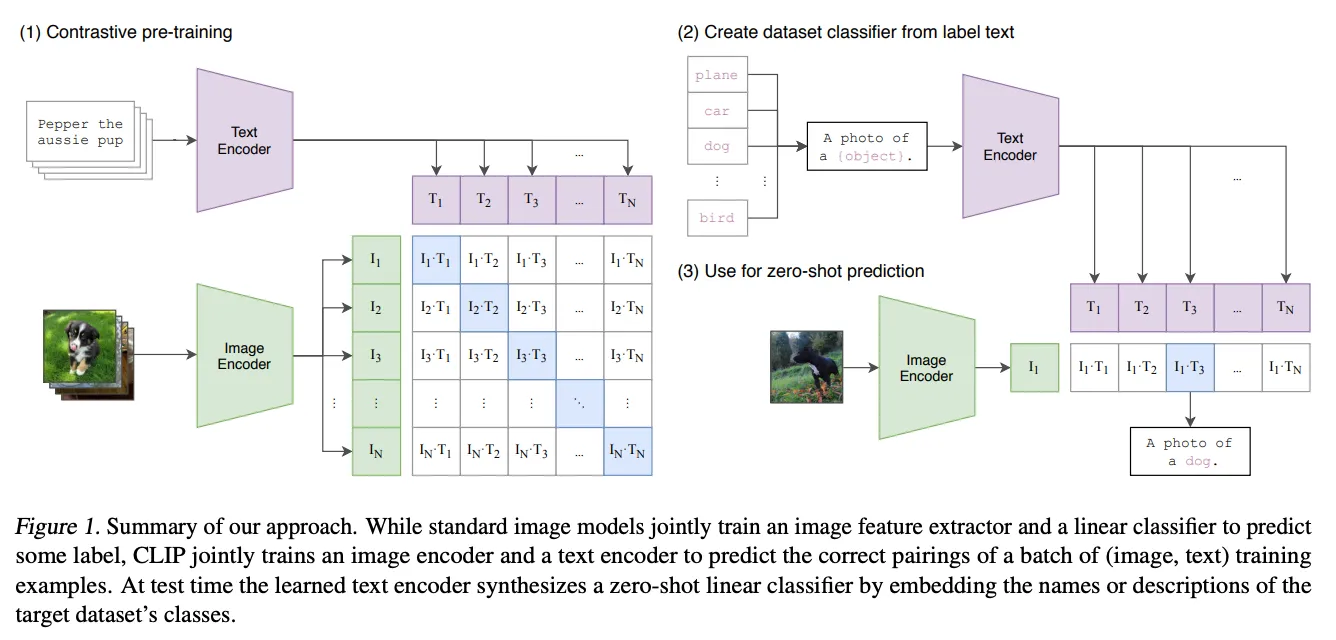
모델구조
크게 이미지 인코더와 텍스트 인코더, 멀티 임베딩으로 구성된다. 두 인코더가 출력하는 표현을 같은 차원의 다중모달 임베딩 공간으로 매핑합니다.
텍스트 인코더 코드(실험: 12개 레이어, 512차원 폭, 8개 어텐션 헤드, 사전학습 없음)
텍스트 인코더는 Transformer Decoder 부분만을 사용한 GPT-like 형태로 구축되었다.
인코더는 토크나이즈된 문장(BPE tokenizing)을 입력으로 받아 문장 전체를 대표하는 임베딩 벡터를 생성한다.
각 토큰의 컨텍스트를 고려한 자기 어텐션 메커니즘으로 문장 임베딩을 산출하며, 최종 텍스트 표현은 EOS 토큰의 출력 위치의 임베딩(문장 전체의 임베딩)을 취합니다.
이미지 인코더 코드(Encoder Only Model)
이미지를 patch 단위로 나눈 후, 각 patch를 transformer로 처리하여 이미지 전체를 표현하는 하나의 임베딩 벡터를 생성한다.즉, Transformer Encoder 구조 를 차용하여 이미지를 문장처럼 처리(ViT)합니다.
실험에서는 ResNet, EfficientNet, ViT 의 다양한 모델 아키텍처와 다양한 사이즈를 가진 백본을 통해 모델 규모와 구조에 따른 표현력 차이와 스케일 업 효과를 분석했습니다.
여기서 하나 의문점이 든다. 굳이 [EOS] 토큰 위치의 임베딩을 사용하는 것은, 결국 Encoder-Only 모델의 CLS 토큰을 사용하는 것과 마찬가지 일텐데 왜 Decoder-Only 모델을 텍스트 인코더 모델에 사용했을까?
내 생각은…
우선, BERT는 문장 임베딩을 만들 수는 있지만, 토큰 임베딩을 생성하기 위해 고안된 모델이다.
웹 데이터 특성 상, 이미지의 캡션은 하나의 토큰(또는 단어)로 나타낼 수 없다. 이 때문에 인코더 모델을 사용하지 않은 것으로 볼 수 있다.
반대로, 디코더 온리 모델에서 EOS의 위치에 존재하는 임베딩은 이전 토큰 전부를 보고 나서 생성된 임베딩으로 문장 전체의 정보를 담고 있다고 생각할 수 있다.(보장할 순 없을 것 같다)
이래서 디코더 온리 모델을 선택한 게 아닌가라는 생각과 기업간의 자존심 싸움 떄문인가라는 생각을 하게 되었다.
멀티모달 임베딩 공간
이미지 인코더와 텍스트 인코더는 각각 Linear projection 레이어를 통해 공통 임베딩 공간에 매핑된다.
논문에서는 SimCLR에서 쓰이는 비선형 MLP 투사를 사용하지 않고, 간단한 선형층만 사용했는데, 이는 거대한 데이터셋으로 학습할 경우 비선형 투사가 오히려 불필요한 복잡성을 초래할 수 있다고 판단했기 때문이다.
#CLIP의 forward 부분
def forward(self, image, text):
image_features = self.encode_image(image)
text_features = self.encode_text(text)
# normalized features
image_features = image_features / image_features.norm(dim=1, keepdim=True)
text_features = text_features / text_features.norm(dim=1, keepdim=True)
# cosine similarity as logits
logit_scale = self.logit_scale.exp()
logits_per_image = logit_scale * image_features @ text_features.t()
logits_per_text = logits_per_image.t()
# shape = [global_batch_size, global_batch_size]
return logits_per_image, logits_per_text실제 코드를 보면, 이미지와 텍스트의 인코딩 결과를 간단하게 로짓으로 변경하고, 출력을 뱉는다. 결과적으로 임베딩 레이어가 아닌 같은 차원의 임베딩 공간으로 임베딩들을 정의하고, 코사인 유사도를 통해 두 결과물의 연관성을 계산한다. 이러한 구조 덕분에 CLIP 모델은 이미지-텍스트 간 자유로운 매칭과 검색, 분류가 가능하다.
여담이지만, 해당 구조는 facebook에서 Passage를 검색 하는 모델인 DPR(Dense Passage Retrieval)과 똑같다고 볼 수 있다.
대조 학습(Contrastive learning)
목표: 배치 내의 올바른 이미지-텍스트 쌍을 맞추는 것
구현: 미니 배치 개의 샘플에 대해서 개의 텍스트와 개의 이미지가 존재할 때, 모델은 간능한 이미지- 텍스트 쌍 중 실제 짝을 맞추는 분류 문제로 훈련됨
손실 함수: 양방향 cross-entropy
이미지 와 텍스트 의 임베딩을 와 라고 할 때, 이들의 유사도 점수를 행렬 형태로 계산하고, 실제 짝 인 경우 유사도를 최대화하고 그렇지 않은 경우 유사도를 최소화 하도록 학습합니다. 즉 학습을 통해 모델은 이미지->텍스트, 텍스트->이미지 양쪽 방향에서 정답 쌍을 맞추도록 최적화한다고 볼 수 있다. 코드를 살펴보자.
#code by huggingface
def contrastive_loss(logits: torch.Tensor) -> torch.Tensor:
return nn.functional.cross_entropy(logits, torch.arange(len(logits), device=logits.device))
def clip_loss(similarity: torch.Tensor) -> torch.Tensor:
caption_loss = contrastive_loss(similarity)
image_loss = contrastive_loss(similarity.t())
return (caption_loss + image_loss) / 2.0
class CLIP(...):
def __init__():
...
self.visual_projection = nn.Linear(self.visual_hidden_size, self.projection_dim, bias=False)
self.text_projection = nn.Linear(self.text_hidden_size, self.projection_dim, bias=False)
self.logit_scale = nn.Parameter(torch.tensor(self.logit_scale_init_value))
...
def forward(..):
# image & text embeds == (Batch_size, Linear Hidden size)
image_embeds = vision_outputs[1]
image_embeds = self.visual_projection(image_embeds)
text_embeds = text_outputs[1]
text_embeds = self.text_projection(text_embeds)
# normalized features
image_embeds = image_embeds / image_embeds.norm(p=2, dim=-1, keepdim=True)
text_embeds = text_embeds / text_embeds.norm(p=2, dim=-1, keepdim=True)
# cosine similarity as logits -> (Batch_size, Batch_size)
logit_scale = self.logit_scale.exp()
logits_per_text = torch.matmul(text_embeds, image_embeds.t()) * logit_scale
logits_per_image = logits_per_text.t()
loss = None
if return_loss:
loss = clip_loss(logits_per_text)cosine similarity 를 구하기 L2-normalization을 거친 후, 내적한다.
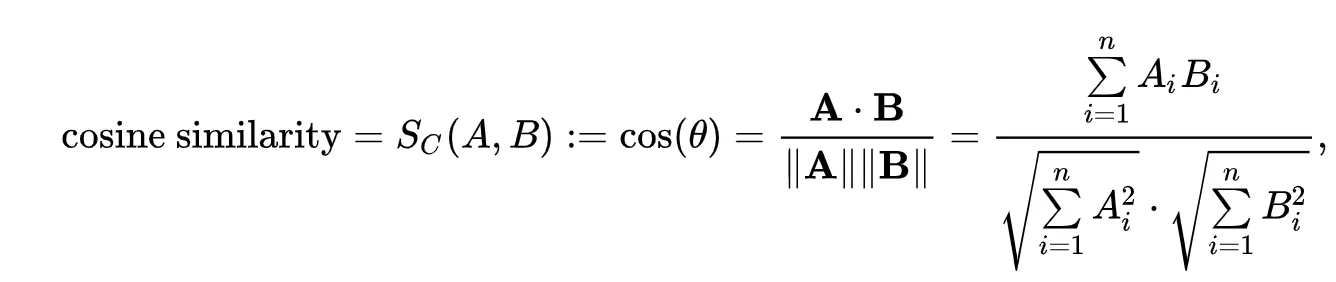
이후 loss function에서 하나의 유사도를 트랜스포즈를 통해 손실을 계산한다. 이는 텍스트 기준과 이미지 기준의 로짓을 계산하기 위해 사용된다. 본 코드에서도 똑같은 걸 확인할 수 있다.
similarity는 텍스트 기준 logits (logits_per_text)
similarity.t()는 이미지 기준 logits (logits_per_image)
음 그럼 왜 similarity를 L2-Norm 이나 다른 걸 사용하지 않는 걸까 라는 의문이 들 수도 있다.
L2-Norm은 벡터의 방향 뿐만 아니라 크기에도 영향을 받는다. 정규화를 통해 [0,1] 범위로 만들었어도 벡터의 길이 자체가 사라지는 것은 아니다. 이는 학습이 벡터 방향보다는 norm을 조작하는 방식으로 치우칠 위험이 있다.
하지만, cosin similarity는 벡터 방향만을 고려하기 때문에 해당 문제를 일으키기 않는다.
그럼 loss에 대해서 살펴보자. CLIP Loss는 InfoNCE를 배치 단위의 소프트 맥스로 일반화시켯다. InfoNCE가 무엇일까?
InfoNCE는 "positive 쌍이 softmax에서 선택될 확률이 높아지도록" 유도하는 손실이다.
sim(q, k)는 보통 cosine similarity 또는 dot product입니다.- τ는 temperature로, 값이 작을수록 분포가 sharper 해져 positive 쌍만 강조됩니다.
- : Anchor (예: query, 텍스트)
- : Positive key (정답 쌍)
- : 모든 candidate key (positive 포함)
- : 유사도 함수 (cosine 또는 dot product)
- : temperature (softmax sharpness 조절용)
이를 배치 단위로 바꾼 것이

해당 코드로, 하나의 배치 단위에서 정답 쌍은 로짓을 1로, 아닌 것은 로짓을 0으로 정답 쌍을 만들어서 학습을 돌린다.
훈련 효율성
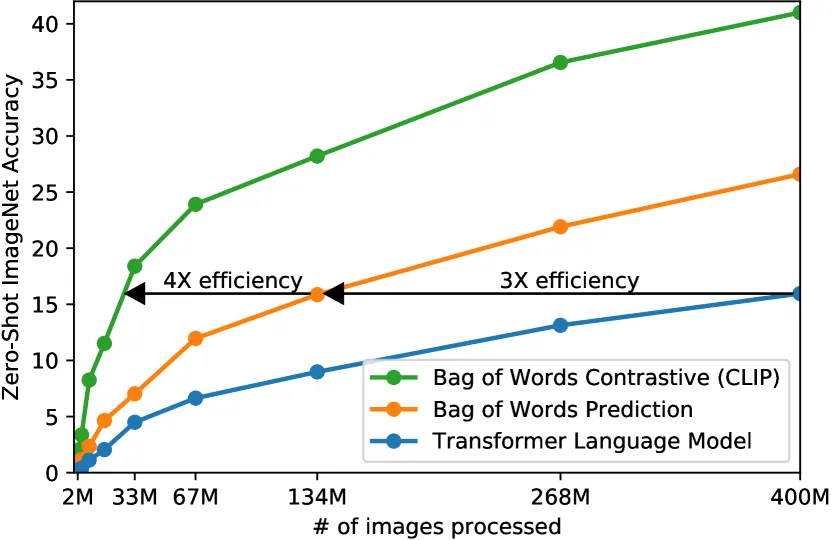
원래 저자들이 최초에 고려한 방법은 VirTex(Desai & Johnson, 2020)와 유사하게 이미지에서 캡션 문장 자체를 생성(predict)하는 것이었으나, 웹 규모로 이 접근을 확장하는 데 어려움을 겪었다고 보고했다.(이미지에 대한 상세한 문장 서술을 정확히 맞춰야 하므로 난이도가 높고 비효율적임)
반면에 Bag-of-Words 방식으로 단어 분포만 예측하거나, 나아가 대조적 목표로 전환하자 학습 효율이 크게 향상되었다.
위의 그래프 처럼 대조적 접근은 이미지와 텍스트를 전체 문장 단위로 비교하므로, 개별 단어까지 정확히 맞출 필요 없이 이미지와 어울리는 문장인지 만을 판별하게 되어 학습 난이도를 낮추는 효과가 있었다고 한다. 그 결과 CLIP에서는 이미지-텍스트 일치 여부 예측이라는 간단한 프레임워크만으로도 고성능의 시각 표현 학습이 가능함을 보였다. 또한 거대한 데이터셋을 사용함으로써 모델이 과적합될 걱정이 적어, ImageNet 예측으로 초기화한다든지 복잡한 데이터 증강을 사용하는 등의 기법도 배제하여 구현을 단순화했다.
전처리
이미지 증강: 랜덤 크롭
텍스트: 별도 처리 없음(한문장이라서)
실험 결과
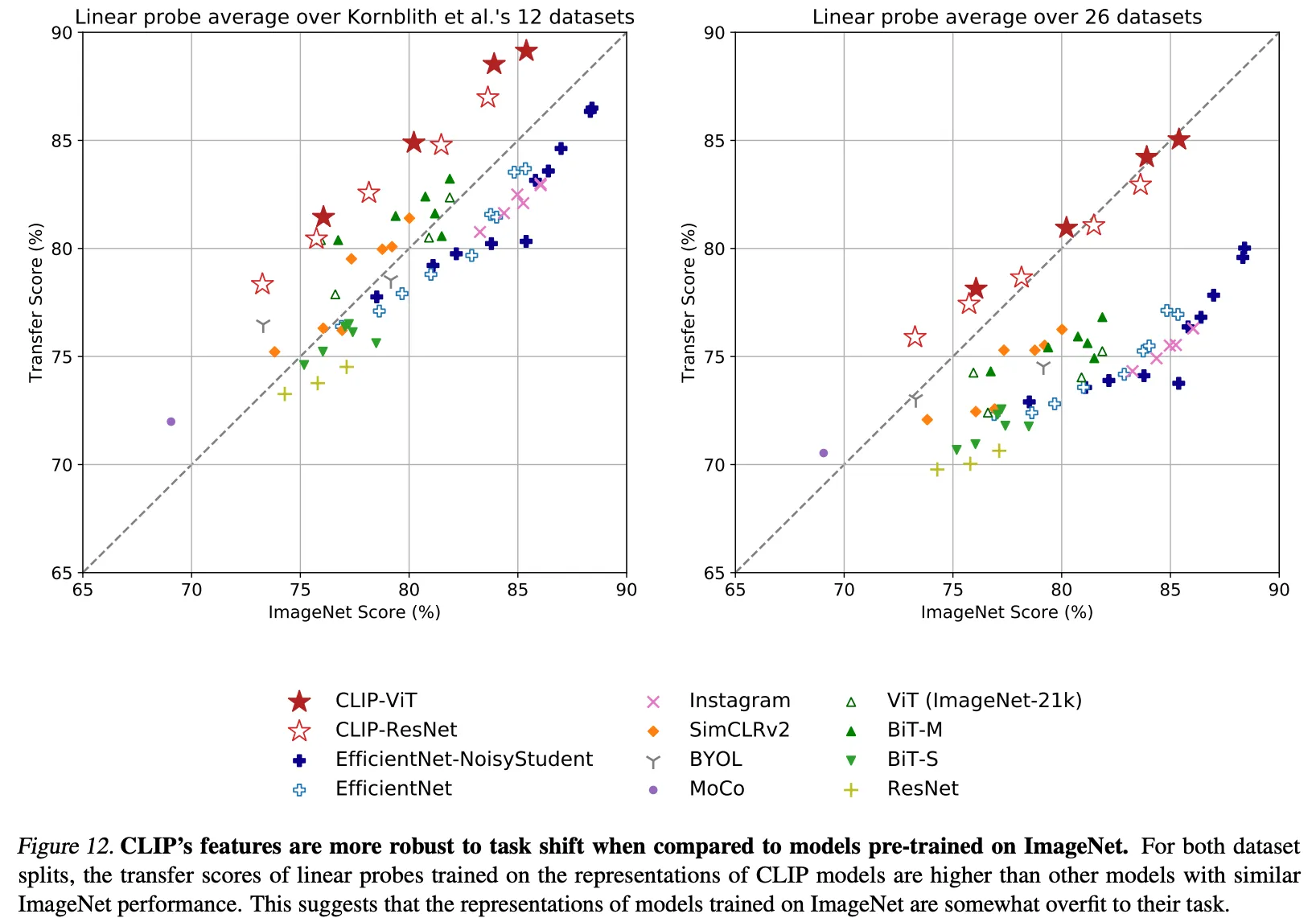
1. Zero-Shot Classification
(fully supervised linear probe: BERT와 같이 출력단에 Linear 레이어를 하나 달아서 학습 시키는 방식)
- 자연어로 표현된 클래스 이름을 이용해 분류기를 생성하는 zero-shot 방식
- STL10, CIFAR10, Food101 등 5개 데이터셋에서 fully supervised 성능과 거의 동일한 수준 도달
- 대부분의 경우 zero-shot 성능은 fully supervised linear probe보다 10–25% 낮지만, 4-shot 수준의 성능은 유사하다.
2. Few-Shot Learning
- 16-shot logistic regression 성능과 CLIP zero-shot 성능이 유사한 수준.
- zero-shot classifier를 few-shot 초기화(weight prior)로 사용하는 기법도 제안되었으나, 최적화 과정에서 결국 zero-shot으로 수렴하는 경우 많음.
- human experiment에서도 one-shot에서 큰 성능 향상을 보였으며, CLIP도 유사한 추세를 보임.
3. Linear Probe 성능 (Representation Quality)
- ViT-L/14 모델이 27개 벤치마크 중 21개에서 최고 성능 기록.
- linear classifier 기준으로도 CLIP의 표현력은 매우 강력, zero-shot 분류기와 비교 시 상관관계 0.82 기록.
- linear probe는 zero-shot classifier와 구조 유사 (정규화된 feature → softmax).
4. Robustness & Distribution Shift
- CLIP은 기존 ResNet-50 기반 모델보다 distribution shift에 더 robust.
- zero-shot 모델이 few-shot이나 fully supervised 모델보다도 더 높은 effective robustness를 보이는 경우 존재
5. Prompt Engineering
- label만 사용하는 것보다
"A photo of a {label}."형태로 프롬프트를 생성했을 때 zero-shot 성능이 평균 5% 향상. - 데이터셋별 문맥 최적화를 통해 추가 개선 가능 (예: “a type of pet”)
6. Scaling Law 실험
- ResNet 기반 CLIP 모델 (RN50 → RN50x64)에서 연산량이 증가할수록 성능도 log-linear하게 증가함.
- GPT에서의 scaling law와 유사한 패턴 관측
7. Ablation 및 비교 실험
- Visual N-Gram, SimCLRv2, ResNet 등과 비교:
- 일부 fine-grained task에서는 오히려 CLIP이 underperform
- 반면 Stanford Cars, Food101, Kinetics700 등에서는 20~28%p 이상 우세.
- BERT식 텍스트 인코딩 구조와 비교되는 특징도 언급됨
텍스트 인코더 코드
class ResidualAttentionBlock(nn.Module):
def __init__(self, d_model: int, n_head: int, attn_mask: torch.Tensor = None):
super().__init__()
self.attn = nn.MultiheadAttention(d_model, n_head)
self.ln_1 = LayerNorm(d_model)
self.mlp = nn.Sequential(OrderedDict([
("c_fc", nn.Linear(d_model, d_model * 4)),
("gelu", QuickGELU()),
("c_proj", nn.Linear(d_model * 4, d_model))
]))
self.ln_2 = LayerNorm(d_model)
self.attn_mask = attn_mask
def attention(self, x: torch.Tensor):
self.attn_mask = self.attn_mask.to(dtype=x.dtype, device=x.device) if self.attn_mask is not None else None
return self.attn(x, x, x, need_weights=False, attn_mask=self.attn_mask)[0]
def forward(self, x: torch.Tensor):
x = x + self.attention(self.ln_1(x))
x = x + self.mlp(self.ln_2(x))
return x
class Transformer(nn.Module):
def __init__(self, width: int, layers: int, heads: int, attn_mask: torch.Tensor = None):
super().__init__()
self.width = width
self.layers = layers
self.resblocks = nn.Sequential(*[ResidualAttentionBlock(width, heads, attn_mask) for _ in range(layers)])
def forward(self, x: torch.Tensor):
return self.resblocks(x)이미지-인코더
class VisionTransformer(nn.Module):
def __init__(self, input_resolution: int, patch_size: int, width: int, layers: int, heads: int, output_dim: int):
super().__init__()
self.input_resolution = input_resolution
self.output_dim = output_dim
self.conv1 = nn.Conv2d(in_channels=3, out_channels=width, kernel_size=patch_size, stride=patch_size, bias=False)
scale = width ** -0.5
self.class_embedding = nn.Parameter(scale * torch.randn(width))
self.positional_embedding = nn.Parameter(scale * torch.randn((input_resolution // patch_size) ** 2 + 1, width))
self.ln_pre = LayerNorm(width)
self.transformer = Transformer(width, layers, heads)
self.ln_post = LayerNorm(width)
self.proj = nn.Parameter(scale * torch.randn(width, output_dim))
def forward(self, x: torch.Tensor):
x = self.conv1(x) # shape = [*, width, grid, grid]
x = x.reshape(x.shape[0], x.shape[1], -1) # shape = [*, width, grid ** 2]
x = x.permute(0, 2, 1) # shape = [*, grid ** 2, width]
x = torch.cat([self.class_embedding.to(x.dtype) + torch.zeros(x.shape[0], 1, x.shape[-1], dtype=x.dtype, device=x.device), x], dim=1) # shape = [*, grid ** 2 + 1, width]
x = x + self.positional_embedding.to(x.dtype)
x = self.ln_pre(x)
x = x.permute(1, 0, 2) # NLD -> LND
x = self.transformer(x)
x = x.permute(1, 0, 2) # LND -> NLD
x = self.ln_post(x[:, 0, :])
if self.proj is not None:
x = x @ self.proj
return xRef 1) https://www.v7labs.com/blog/contrastive-learning-guide
Ref 2) https://arxiv.org/pdf/2103.00020
Ref 3) https://github.com/openai/CLIP/tree/main
Ref 4) https://huggingface.co/docs/transformers/en/model_doc/clip
Ref 5) https://en.wikipedia.org/wiki/Cosine_similarity
Ref 6) https://openai.com/index/clip/
