Vision-language reasoning
언어와 시각 정보 두 가지 modality 사이의 관계를 학습, 이해하고 이를 바탕으로 문제를 해결하는 것을 말한다
- 오늘 소개할 논문
- ViLBERT (NeurIPS 2019)
- BERT for vision-and-language
- 사전학습 BERT 모델, Faster R-CNN 모델을 사용하고 각 modality의 feature를 Self attention layer로 추출, 다른 modality와의 관계를 co-TRM layer로 반영하는 접근법을 사용했다
- LXMERT (EMNLP 2019)
- 이미지 feature와 자연어 feature가 하나의 모델에 반영됨
- Cross-modal reasoning language model
- Learning Cross-Modality Encoder Representations from Transformers
- 이를 위해, 시각적인 내용물에 대한 이해와 언어에 대한 이해, 그리고 그 두 가지 사이의 관계성과 일치성을 파악할 수 있어야 한다
- 최근에는 언어 모델에서의 접근법, 특히 트랜스포머/BERT의 모델을 가져와 사용하는 접근법이 많다. 태스크 당 다른 모델을 쓰는 것이 아니라 대규모 데이터로 사전학습 한 모델을 파인튜닝 하여 더욱 다양한 vision-language 태스크에서 사용할 수 있도록 만들었다
- 오늘 소개할 ViLBERT와 LXMERT는 모두 Transformer 인코더 구조를 모방한다는 점, 각 modality에 대한 인코더가 따로 존재한다는 점 등이 유사하지만, 모델 구조 및 사전 학습 방식과 파인튜닝한 태스크 및 방법에서 차이를 보이고 있다
- 이 두 가지를 살펴보며 최근 트랜스포머가 vision-language task에 적용되는 방향을 살펴볼 것이다
ViLBERT
VilBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks (NeurIPS 2019)
Summary
👉 Multimodal joint representation: BERT 기반으로 시각 정보와 언어 정보, 그리고 그 사이의 관계를 학습하고 VQA 등의 multi-modal downstream task에서 적용할 수 있도록 했다
👉 각 modality 별 stream을 구분하여 처리 과정을 다르게 할 수 있도록 하고, co-attention transformer layer를 사용해 각 모달에서 추출한 표현들 사이의 관계를 학습할 수 있도록 했다. 서로의 modality에서 영향을 받은 vision representation, language representation이 최종 아웃풋이 된다
Pre-requisite
Object detection (객체 검출): 이미지가 주어졌을 때, 그 안에서 물체들의 위치를 찾아내고 각 물체가 어떤 물체인지 판별하는, 이미지 분야의 과제이다

- ⇒ 문장에서 "토큰"을 추출하듯이, "이미지의 토큰"을 만들기 위해 사전학습 된 객체 검출 모델을 사용하여 이미지의 feature를 추출하여 트랜스포머 기반 멀티모달 모델의 입력값으로 이용했다
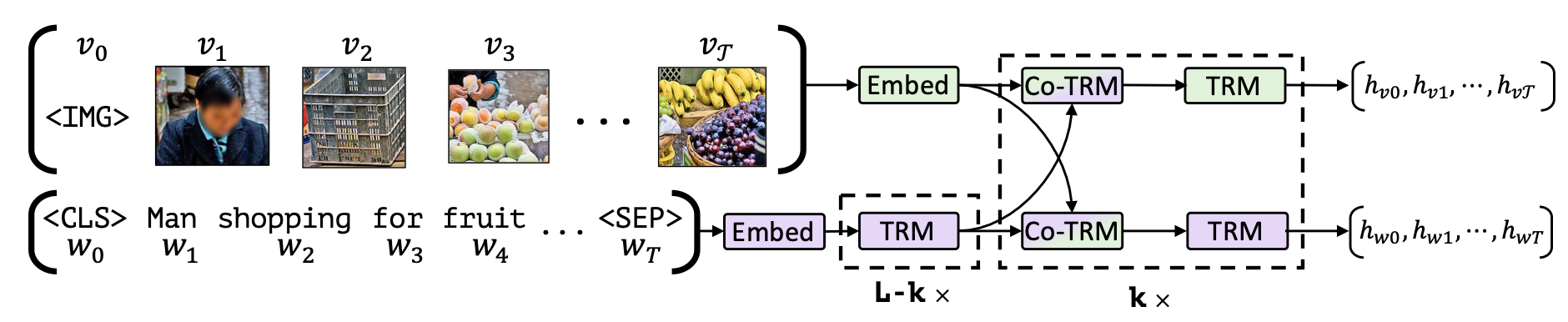
Model
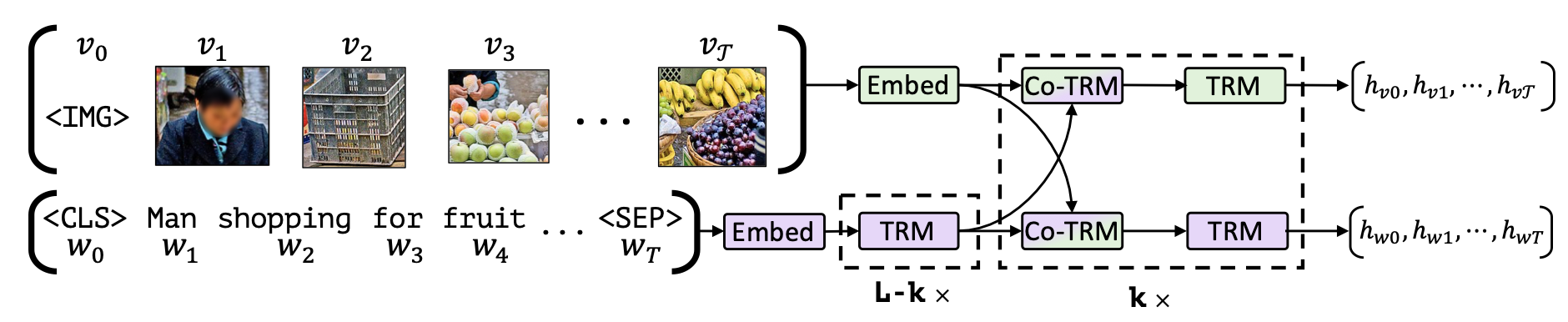
-
모델은 vision을 위한 것과 language를 위한 것, 두 개의 stream으로 각각 modality를 독립적으로 이해한다.
→ 이를 통해 통일된 BERT에 이미지 토큰과 언어 토큰을 모두 입력하는 것에 비해 각각의 modality에서 필요한 처리 단계를 조정하고, 언어로 사전학습된 BERT의 파라미터가 이미지에 적응하는 과정에서 망가지는 것을 방지할 수 있다
-
그 뒤 co-TRM 블록에서 서로가 서로의 representation에 attention 하는 방식으로 language와 vision 사이의 관계를 반영했다
-
모델의 아웃풋으로는 vision에 대한 representation과 language에 대한 representation 두 가지를 얻게 된다
Co-Attentional Transformer Layers (Co-TRM)
중간 단계의 visual, linguistic representation들이 주어졌을 때, 트랜스포머 block의 multi-head attention에서 query, key, value 중 key와 value로 다른 modality의 representation을 사용한다
How to get visual token?
객체 검출 태스크로 사전 학습 된 Faster R-CNN 모델을 사용해 10 ~ 36개 사이의 높은 클래스 탐지 확률을 가진 region box들을 선택했다. 각 선택된 영역에 대한 convolutional feature들의 mean-pool 된 값을 visual token으로 사용했다
- 영준님 설명 Faster R-CNN에서 RPN 모듈이 있는데, 거기에서 제안된 Region들 중에서 선택하는 것일 것이다
Pre-trained parameters
- 사전 학습된 BERT 모델로 linguistic stream을 초기화하고,
- 사전 학습된 Faster R-CNN으로 region feature를 추출, 객체 별 클래스를 판별했다 (라벨로 이용)
Training Tasks (Pre-train)
- Masked multi-modal training
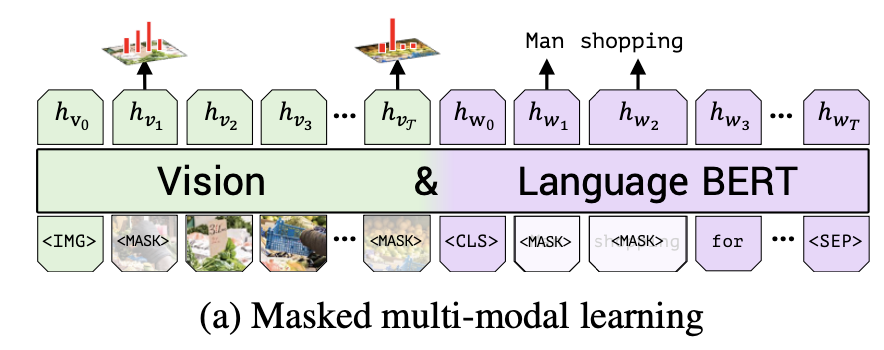
BERT의 MLM처럼 입력값을 마스킹하며, 언어에 대해서는 동일하고 image의 경우 15%의 영역을 선택, 그 중 90%의 영역을 지웠다.
이미지에서는 masking된 feature의 값을 예측하기 보다는, 해당 영역의 semantic class에 대한 분포를 예측했다
→ 왜냐하면, 이미지에 대한 설명은 각 이미지 영역 자체의 feature를 설명하는 게 아니고, 높은 레벨의 맥락을 다루기 때문이다- Multi-modal alignment prediction
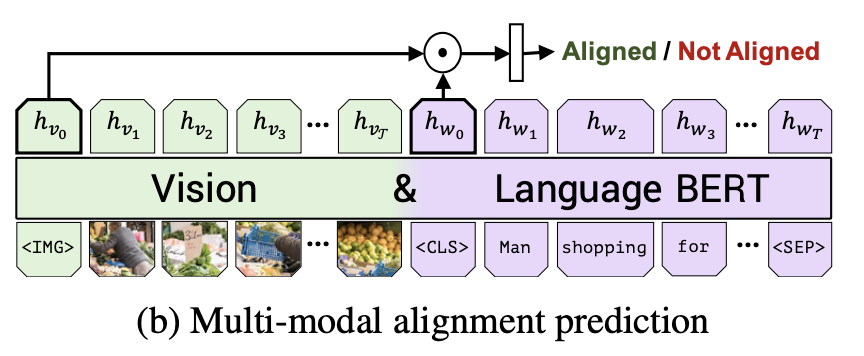
이미지-텍스트 쌍이 입력으로 주어졌을 때, 텍스트가 이미지를 설명하는 것이 맞는지(aligned) 아닌지(not aligned)를 판별한다
$h_\text{IMG}, h_\text{CLS}$ 토큰을 BERT의 CLS 토큰 처럼 사용하며, 이 두 개의 토큰들의 element wise product를 두 모달리티를 거친 입력값의 전체적인 표현으로 사용해 판별 과제를 수행했다Dataset
Conceptual captions 데이터셋을 사용해 이미지와 이미지에 대한 caption이 함께 있는 데이터를 학습했다
Transfer learning
- Visual Question Answering(VQA)
- Visual Commonsense Reasoning (VCR)
- Grounding Referring Expressions
- Caption-Based Image Retrieval

LXMERT
LXMERT: Learning Cross-Modality Encoder Representations from Transformers (EMNLP 2019)
LXMERT: Learning Cross-Modality Encoder Representation from Transformers
Summary
👉 3개의 트랜스포머 기반 인코더: vision 인코더, language 인코더, cross-modality 인코더를 사용하였고 각 modality 별, 그리고 modality 사이의 관계를 사전학습 하여 vision-language 사이의 연결이 필요한 태스크에 적용 가능한 사전학습 모델과 그 방법을 제시하였다
👉 자연어, 이미지의 임베딩 정보를 합쳐 cross modality output을 내고, 이를 BERT의 CLS 토큰 처럼 이용했을 때 가장 좋은 성과가 나왔다고 한다. 이미지에 대한 질문에서 질문 내 자연어 사이의 관계, 이미지의 정보, 그리고 그 관계가 이미지에 어떻게 매핑되는지가 하나의 모델에 담겨 있다
👉 5가지의 사전학습 태스크를 아래와 같이 수행했다
1️⃣ Language encoder: masked cross-modality language modeling
2️⃣~3️⃣ Vision encoder: masked object prediction (feature regression + label classification)
4️⃣~5️⃣ Cross-modailty: cross-modality matching, image question answering
👉 모델을 VQA, GQA 등의 visual question answering 태스크에 적용해, SOTA 결과를 얻었다
👉 vs. ViLBERT:
1️⃣ 추가적인 사전학습 태스크: RoI feature regression, image question answering
2️⃣ 더 정교하고 여러 개의 컴포넌트를 가진 모델 구조 (object-relationship encoder, cross-modality layer 등)
3️⃣ 모든 파라미터를 scratch 부터 학습시켰다 (사전학습 파라미터를 사용할 때보다 더 성능이 잘 나왔다고 함)
VQA, NLVR 등의 태스크에서 성능 개선!
Model
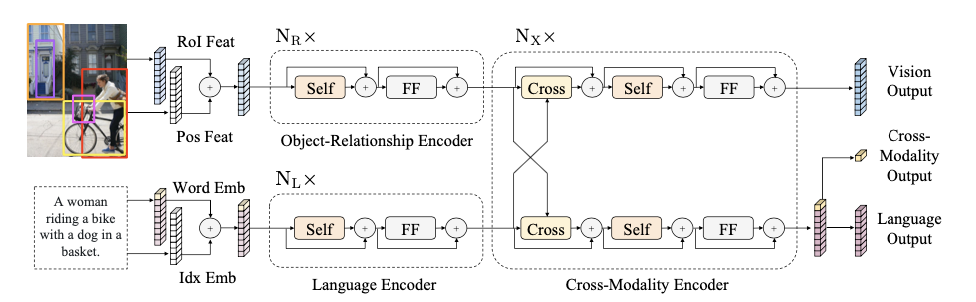
ViLBERT처럼, self-attention과 cross-attention 레이어로 모델을 구성했다
- 입력: 각 이미지는 특정한 object들의 sequence로 이루어져 있으며, 각 문장은 단어들의 sequence로 이루어져 있다
- 출력: image, language, cross-modality representation
Input embeddings
- 단어 단위 문장 임베딩: WordPiece 토크나이저를 사용하고, 각 토큰에 해당하는 벡터로 변환된다. 각 토큰의 위치 정보 또한 임베딩한다

-
객체 단위 이미지 임베딩: 사전학습된 Faster R-CNN 모델로 객체를 검출하고, 각 검출된 객체 별 위치 정보(bounding box 좌표)와 RoI feature를 합쳐 사용한다
- 최대 36개의 객체를 사용했다
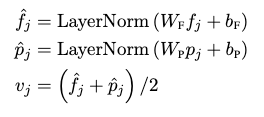
Encoders
Language encoder + Object-relationship encoder + Cross-modality encoder 학습
- 각 single modality 인코더는 self-attention과 feed forward 모듈로 이뤄져 있다
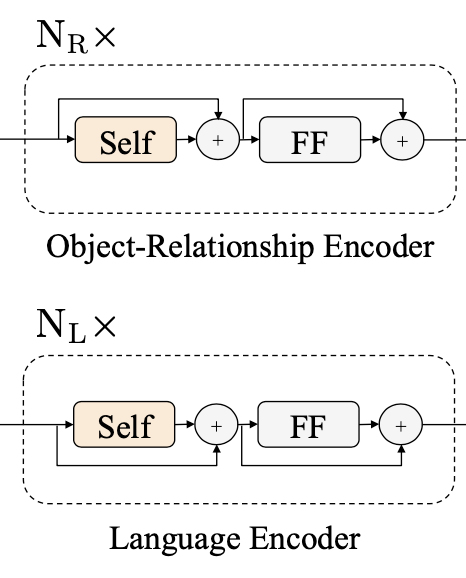
- Cross-modality 인코더: 각 single-modality 인코더를 거친 vision, language 각각의 representation들을 입력으로 두 모달리티 사이 관계와 alignment를 학습한다

Output representations
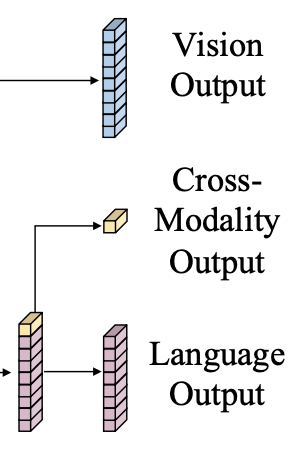
아웃풋으로 총 세 가지, vision, cross-modality, language output을 얻게 된다
BERT처럼, language output의 첫 번째 CLS 토큰에 해당하는 정보가 전체적인 정보를 담고 있는 것으로 사용해 이를 cross-modality output으로 사용한다
Pre-training
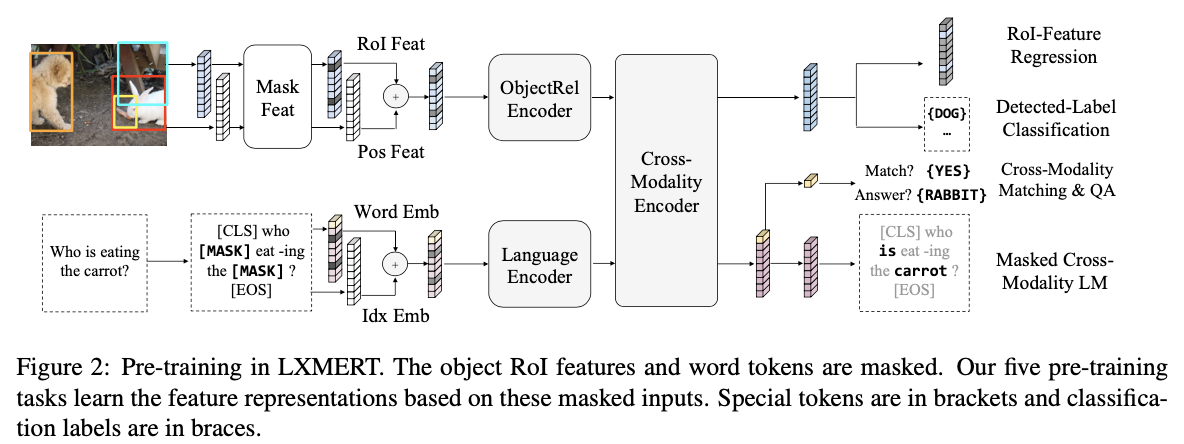
-
Language: Masked Cross-modality LM
BERT와 거의 동일한데, [MASK]로 치환된 토큰의 원본을 맞추는 문제를 풀 때 vision feature로부터도 단서를 얻어 예측한다
-
Vision: Masked Object Prediction
Vision feature에서 일부를 0으로 마스킹하고, 그 부분에 대해
- RoI-Feature Regression: 마스킹 된 객체의 RoI feature를 회귀로 맞춘다
- Detected Label Classification: 마스킹된 object의 Faster R-CNN 출력 클래스를 맞춘다
-
Cross-Modality:
- Cross-Modality Matching: 이미지와 텍스트가 매칭되는지(aligned 인지) 여부를 판단한다
- Image Question Answering: 사전 학습 데이터 중 일부는 QA 데이터셋으로 구성되는데, 랜덤하게 (매칭되지 않도록) 치환되지 않은 데이터라면 이미지, 질문에서 그 정답을 찾는 문제를 해결한다
Pre-training Dataset
COCO=Cap, VG-Cap, VQA, GQA, VG-QA 다섯 가지의 데이터셋을 이용해 사전 학습을 진행했다. 또한, train set과 dev set만을 사전 학습에 이용했다
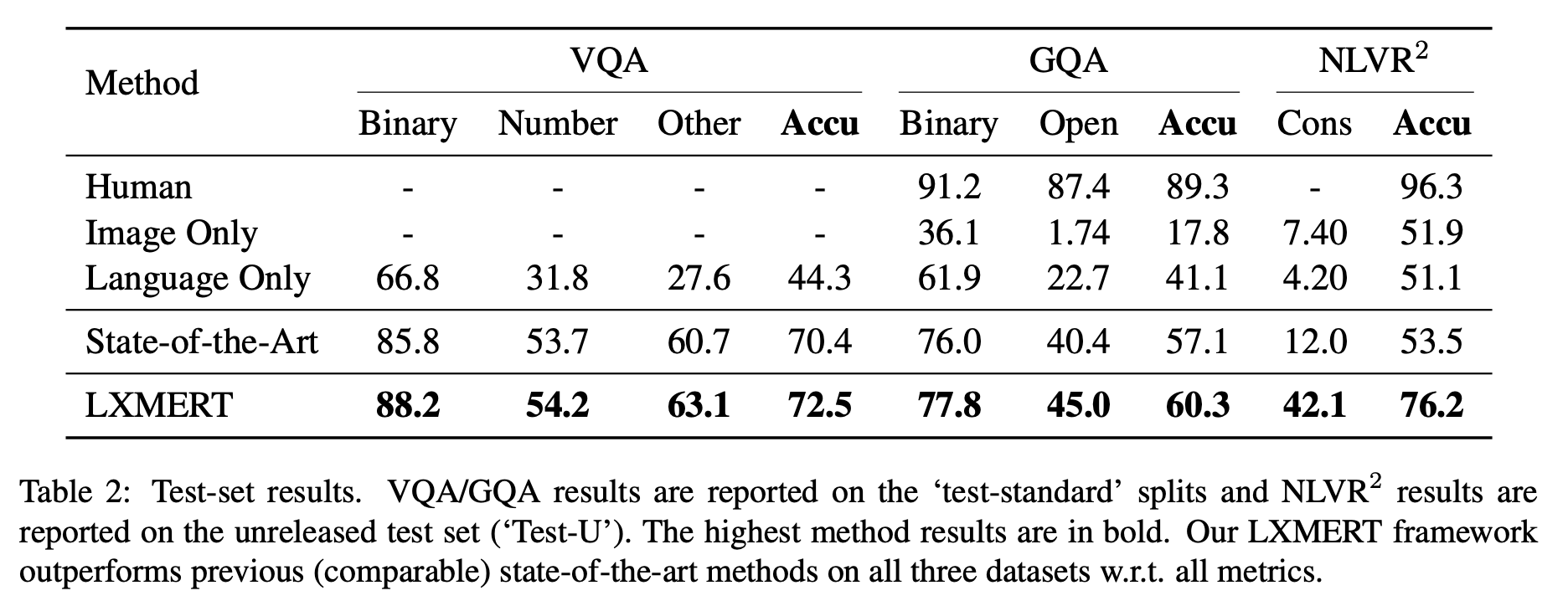
Results