소개
Stereo Matching에 대한 딥러닝 접근법 중의 하나로, KITTI 데이터셋에서 SOTA를 기록한 모델이다.
특징:
1) end-to-end -> 후처리 필요 없이 disparity map을 얻을 수 있음
2) context information 사용 -> 복잡하게 놓인 사물에 대해서도 보다 정확히 대응점을 찾을 수 있음
구조 요약:
인풋 L, R 이미지 각각
-> CNN, Spatial Pyramid Pooling
=> 4D Cost volume
-> 3D CNN
=> disparity map!
정리
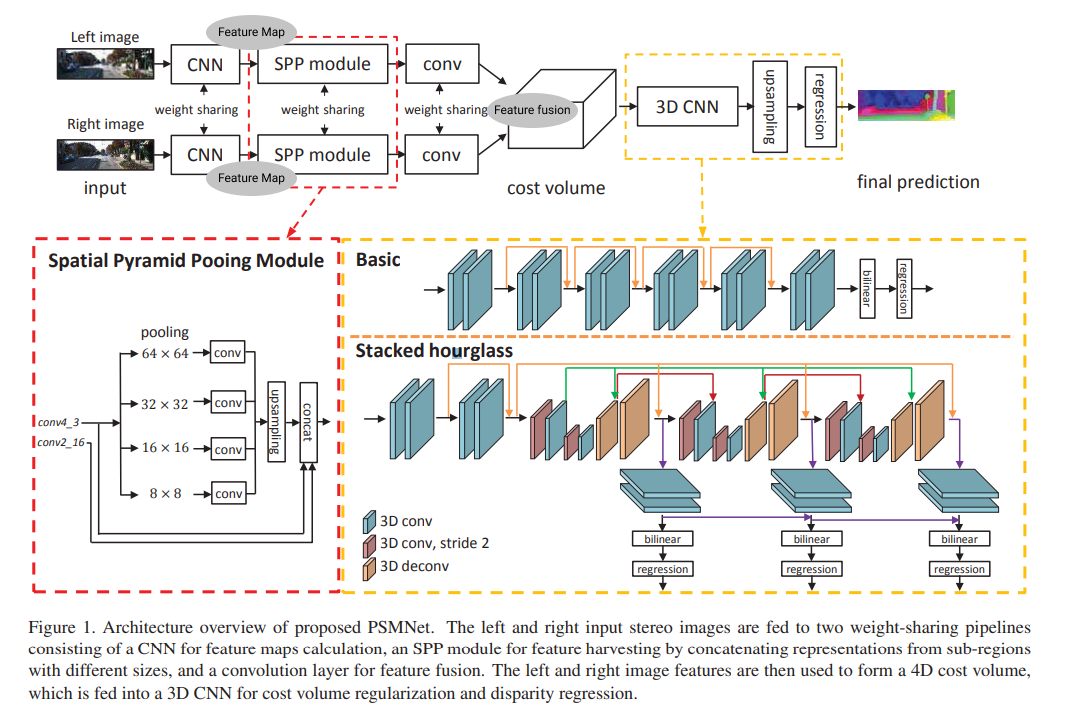
본 논문에서는 신경망을 기반으로 스테레오 정합을 통한 depth map을 얻으며, end-to-end로 후처리 과정을 필요로 하지 않으면서도 KITTY 데이터 셋에서 SoTA를 기록한 모델을 제시한다. 모델에서 핵심적인 구성 요소는 spatial pyramid pooling모듈(이하 SPP 모듈)과, stacked hourglass 구조이며, 각각을 포함하는 두 부분으로 모델을 나눌 수 있다.
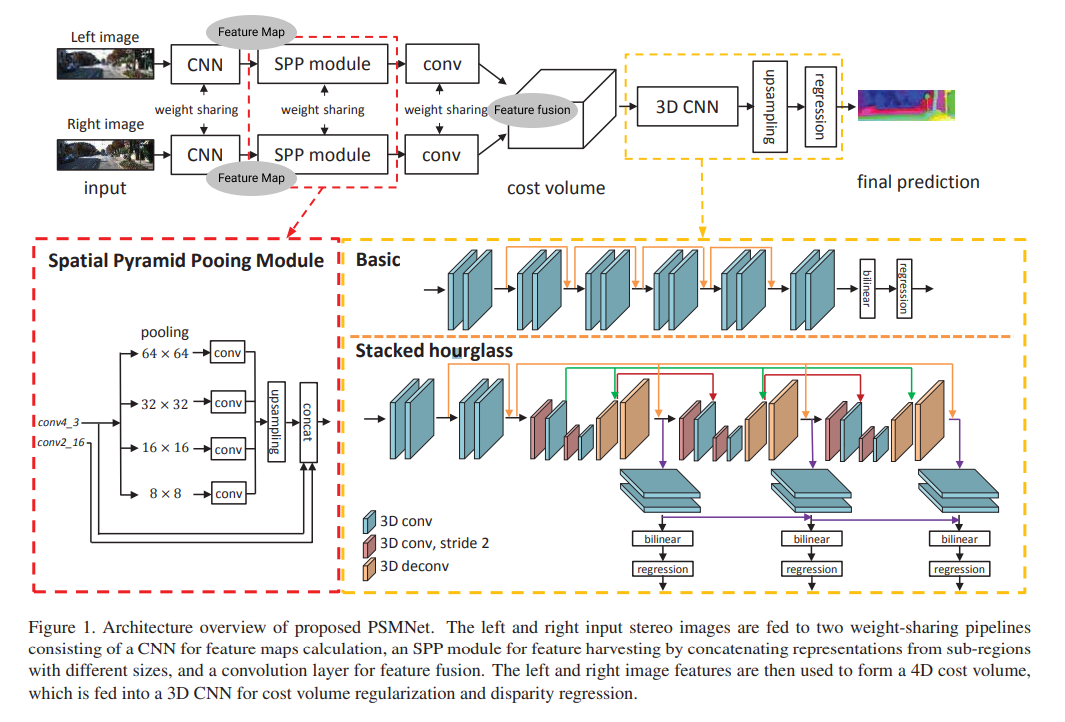
첫 번째 부분에서는 왼쪽 카메라와 오른쪽 카메라 로부터의 사진을 받아 feature를 추출, cost volume을 계산한다. 가장 먼저, 두 인풋 사진에 각각 동일한 weight의 CNN을 적용하여 feature를 추출한다. 추출된 feature map이 각각 spatial pyramid pooling 모듈(이하 SPP)를 거쳐 이미지의 맥락 정보를 포함하는 feature가 된다. SPP 모듈은 SPP에서는 각기 다른 크기의 feature map을 생성하고 이를 병합한다. 영상 분할에서 해당 이미지의 맥락 정보(context)를 이용한 논문을 차용한 것으로, 전체적 맥락을 포함하는 특징을 추출할 수 있으며, 이를 통해 복잡하게 놓인 물체들에 대해서도 대응점을 잘 찾을 수 있다. 병합된 feature는 컨볼루션 레이어를 거쳐 fusion되고, 왼쪽과 오른쪽으로부터의 feature map이 결합돼 4D cost volume을 생성한다.
두 번째 부분에서는 4D cost volume을 인풋으로 맥락 정보를 함께 학습하여 depth map을 내보낸다. 우선, 4D cost volume을 인풋으로 3D CNN을 통과시켜 cost volume을 정규화하는데, 이 때 일반적인 구조보다는 중간중간에 supervision과정을 거치는 stacked hourglass 구조를 사용했을 때 맥락 정보를 잘 학습하였다. Stacked hourglass모델은 3개의 hourglass모델이 겹쳐져 있는데, 각 부분에서 생성된 disparity map와 loss를 합쳐 학습에 이용하고, 추론 시에는 마지막 hourglass의 아웃풋을 사용한다.
모델은 Scene Flow, KITTI 2015, KITTI 2012 데이터셋에서 평가 되었다. 모델은 처음에 Scene Flow로 학습되었다. Scene Flow 데이터셋에서 평가했을 때 PSMNet은 다른 모델들보다 높은 정확도를 보였다. 이후 KITTI 데이터셋에 맞게 파인튜닝되어 KITTI 데이터셋에서 평가되어 KITTI 2012와 KITTI 2015에서 SoTA를 기록했다.
관련 개념
Stereo Matching (스테레오 정합)
스테레오 카메라에서 왼쪽과 오른쪽의 사진을 받고, 카메라 내부의 구조와 사진 상에서 대응되는 점들의 위치 차이를 이용하여 사진에서 물체의 깊이를 측정하는 분야이다. Disparity map (depth map)을 얻는 것을 목적으로 한다.
CNN 관련
- Pooling: CNN에서 pooling은 feature map의 크기를 줄이고, 인풋에서의 위치에 덜 민감하게 만들어 주어 다른 위치에 feature가 위치하더라도 탐지할 수 있게 해준다. 종류로는 max pooling, average pooling, stochastic pooling 등이 있다.
