[컴퓨터 비전 논문] - Learning a deep convolutional network for colorization in monochrome-color dual-lens system
Computer vision papers
개요
논문 출처: Dong, X., Li, W., Wang, X., & Wang, Y. (2019, July). Learning a deep convolutional network for colorization in monochrome-color dual-lens system. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 33, pp. 8255-8262).
흑백렌즈 + 컬러 렌즈를 가진 듀얼렌즈 카메라에서 해상도 높은 컬러 이미지를 만드는 데 활용할 수 있는 딥러닝 모델을 제안한다. 이 논문에서는 attention 방식을 적용하여 픽셀의 색상을 입힐 때 색상의 정확도를 높였으며, 3-D regulation과 residue joint learning을 활용하여 SOTA 결과를 도출하였다.
Summary
본 논문에서는 흑백 렌즈와 컬러 렌즈를 가진 시스템에서 흑백 사진의 색상을 입히는 기술을 Deep CNN을 활용하여 학습시킨다. 흑백 사진과 컬러 사진의 조합으로 선명한 컬러 사진을 만드는 기술은 기존에 많이 연구되어 왔지만, end-to-end이면서 컬러와 흑백 듀얼 렌즈를 지닌 시스템에서 사용 가능한 모델에 적용할 수 있는 접근법은 이 논문이 처음이라는 점에서 의의가 있다. 본 연구에서는 여러 개의 ResNet의 조합과 attention, 3-D regulation, residue joint learning 기술을 기반의 모델을 구현한다. 전체적인 모델의 모습은 아래와 같다.
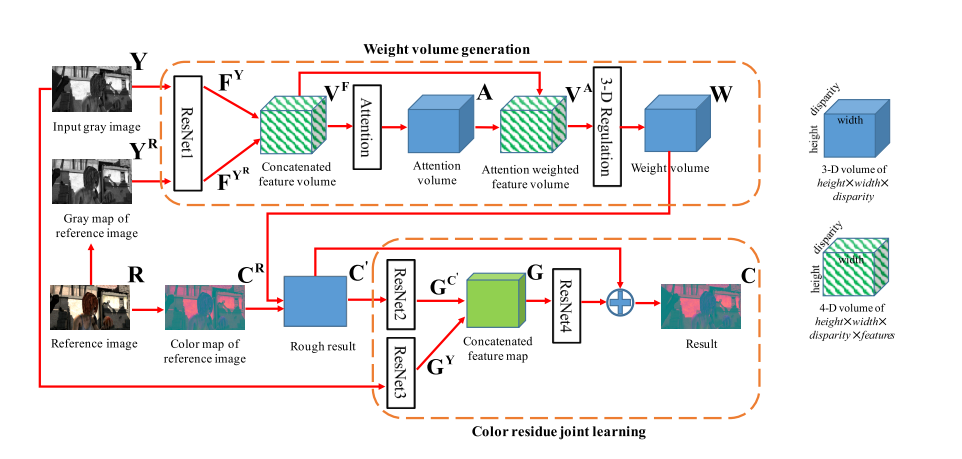
사용된 모델의 핵심은 두 가지 부분, attention-weighted feature volume, 3-D regulation을 통한 weight volume 생성과 color residue joint learning으로 나눌 수 있다. 이 때, 컬러 사진은 gray map과 color map으로 나눈다 (YCbCr 색공간의 Y 채널과 Cb/Cr 채널)
첫 번째, weight volume generation에서는 ResNet과 Attention을 활용한다. ResNet으로 얻은 흑백 사진(Y)과 컬러사진 gray map(Y^R)의 feature volume에서 어텐션 볼륨(V^F)을 구하고, 이를 적용해 어텐션 값에 따라 가중치가 매겨진 feature volume(V^A)을 얻어 각 픽셀에 색을 입힐 때 보다 도움이 되는 픽셀들을 활용한다. 3-D regulation으로 로부터 weight volume(W)을 생성한다.
컬러사진 gray map과 이미지 픽셀들에 얻어진 weight volume의 가중 합으로 대략적으로 색상을 입힌 결과(C')를 얻을 수 있다.
두 번째, 대략적으로 얻은 결과의 정확성을 보정하기 위해 이 결과와 인풋 흑백 이미지의 특징을 추출하고 결합해 feature map을 얻는다. Feature map은 ResNet을 한 번 더 거쳐 residue color map Φ가가 되고, 이를 C'과 더하여 색상이 입혀진 최종 결과물 C를 얻는다.
활용한 데이터셋은 stereo dataset(left camera와 right camera로부터의 image)이다. 데이터셋의 한 쌍의 사진 중 하나를 흑백 이미지로 바꾸고 이를 input image로 사용한다. 또한, 두 카메라들 사이 light-efficiency difference를 반영하기 위해 (흑백 사진의 선명도가 더욱 뛰어난 이유) 각각의 사진에 다른 수준의 노이즈를 추가하여 조정, monochrome과 color input을 재현하였다. 본 논문에서는 해당 데이터셋으로 다른 SOTA 결과와 비교하여 성능을 검증하였다. 아래 그림에서 색상을 입힌 결과를 보면 이 논문의 모델을 사용한 결과인 (c)가 실제 컬러 이미지인 (d)와 가장 유사하게 선명한 것을 알 수 있다.

Related Concept
ResNet
신호 표현을 직접 학습하는 대신, residual(잔류) 표현 함수를 학습함으로써 매우 깊은 네티워크를 가질 수 있다. 네트워크의 깊이가 깊어지는 경우에 성능이 좋아진다고 가정했는데, gradient vanishing, exploding (= degradation)이 발생할 수 있기 때문에 성능이 오히려 떨어질 수 있다.
- Skip connection: 레이어의 입력을 출력에 바로 연결시킨다. Weight layer를 통해 나온 결과와 그 전 결과를 더하고 relu를 사용한 것인데, 성능을 크게 개선한다
→ 각 레이어의 입력이 전 레이어의 출력에만 의지하는 것이 아니라, 각 레이어의 입력이 다른 구조의 네트워크의 출력이 된다.
→ 각 레이어가 독립적임 즉, 어떠한 레이어를 삭제한다고 해서 검사에 영향을 주지 않음. 삭제한 레이어가 많을수록 에러가 비례적으로 커짐. 앙상블 시스템이라고도 할 수 있다.
