소개
논문: FlowNet 2.0: Evolution of Optical Flow Estimation with Deep Networks (CVPR 2017)
저자: Ilg, E., Mayer, N., Saikia, T., Keuper, M., Dosovitskiy, A., & Brox, T.
한 줄 요약: FlowNet 발전판, image warping + stacking network + dataset scheduling + small displacement
사용 데이터셋: Chairs, Things3D, ChairsSDHom(제작), Sintel, KITTI, Middlburry
FlowNet2는 Optical Flow문제를 해결하기 위한 deep neural network 모델이다. Optical flow란 영상에서 움직임을 탐지하는 분야를 말하며, motion segmentation과 action recognition 분야에서 활용된다.
기존의 FlowNet이 optical flow를 딥러닝으로 해결하기 위한 첫 접근이었다면, FlowNet2는 해당 논문의 저자들이 FlowNet논문에서 제안한 FlowNetC, FlowNetS 네트워크들을 조합하여 큰 동작과 작은 동작을 모두 잘 탐지할 수 있는 모델과 학습법을 제안한 것이다.
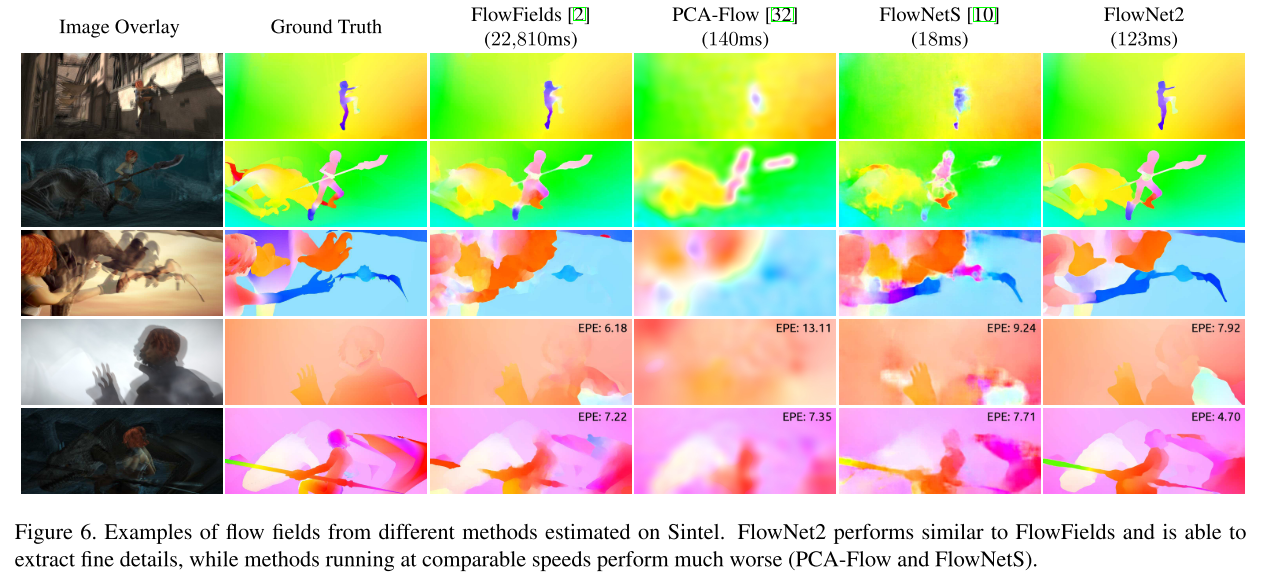
FlowNet2 를 이용하여 Sintel 데이터셋 위에서 optical flow를 추출한 결과 (맨 오른쪽), computation 시간이 들지만 정확하고 매끄러운 결과를 낸다
개선점
모델의 개선점은 크게 세 가지, 데이터 셋의 스케줄링, 네트워크를 쌓는 방식과 작은 displacement를 추가적으로 다루는 영역이 있으며, 각 영역에서 여러 실험을 하며 모델의 구조 및 학습법을 결정하였다.
첫 번째로, 데이터셋을 학습시키는 순서가 모델의 성능에 영향을 준다는 것을 보였다. Chairs와 같은 보다 보편적인 데이터셋을 먼저 훈련시킨 뒤, Things3D 데이터셋에 파인튜닝 하는 것이 훨씬 좋은 정확도를 보인다는 것을 FlowNetS, FlowNetC를 이용해 검증하고 이를 FlowNet2 모델의 학습에 이용했다.
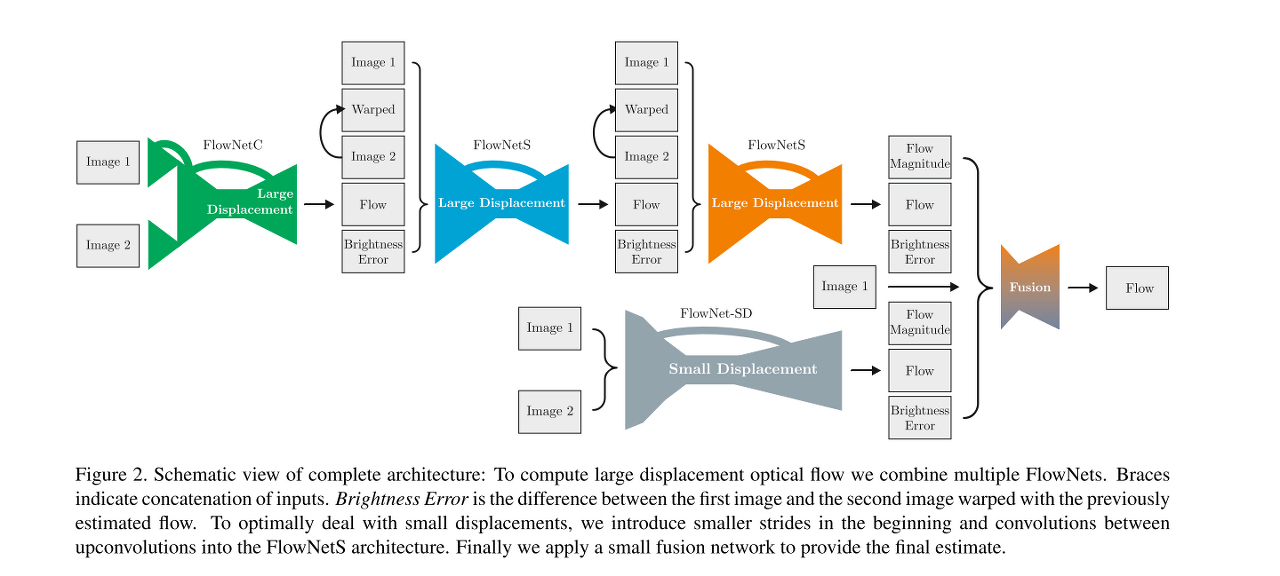
두 번째로, FlowNetC, FlowNetS와 그 변형들을 조합하여 가장 성능이 좋은 모델을 찾아냈다. 이는 iterative refinement방식을 딥러닝에 적용한 것이라고 할 수 있다. 데이터셋의 순서는 앞선 단계에서 찾은 Chairs → Things3D로 학습시켰으며, 하나의 FlowNetC와 두 개의 FlowNetS가 합쳐진 모델인 FlowNet2-CSS 모델이 가장 좋은 성능을 보였다.
셋째로, 기존 FlowNet의 문제점이었던 실제 예시에 적응이 잘 되지 않는 이슈는 작은 동작들에 대한 예측의 신뢰성이 낮다는 점이었다. 본 논문에서는 Chair 데이터셋의 느낌이지만 움직임은 매우 작은 UCF101의 displacement histogram을 따르는 데이터셋, ChairsSDHom을 제작하였다. 앞서 설계한 FlowNet2-CSS 모델을 ChairsSDHom과 Things3D 데이터셋에 파인튜닝 하였고(FlowNet2-CSS-ft-sd), 작은 displacement를 다루기 위해 추가로 FlowNetS를 변형한 FlowNet2-SD 모델을 제안했다.
FlowNet2 모델의 구조
FlowNet2는 FlowNet2-CSS-ft-sd와 FlowNet2-SD, 두 모델로부터의 flow들과 flow magnitude, brighteness error를 받고 한 번 더 확장을 해주는 네트워크로 이루어져 있다. 세 가지 벤치마크, Sintel, KITTI와 Middlebury에서 실험한 결과, SOTA 모델들과 유사하거나 보다 뛰어난 정확도를 확인했다. Optical flow가 활용될 수 있는 motion 분류와 action recognition분야에서도 SOTA 모델들과 유사한 성능을 보였다.
관련 개념
Optical flow
Optical flow란 영상에서 인접한 두 장의 이미지에 나타나는 명암의 변화를 고려하여 움직임의 벡터 필드를 표현하는 분야이다. 움직이는 물체가 있을 때, t 순간에서 (x,y)에 있던 픽셀은 t+1 순간에 어디에 위치할지를 풀어낸다. 대표적인 알고리즘으로 Lucas-Kanade 알고리즘이 있다
Iterative refinement
대략적인 예측 -> 보완해가며 오차를 줄이는 방식을 말한다
