
장단기 메모리(LSTM:Long Short-Term Memory)란?
장단기 메모리(LSTM:Long Short-Term Memory)는 기존 순환 신경망( RNN :Recurrent Neural Network)의 문제인 기울기 소멸 문제(vanishing gradient problem)를 방지하도록 개발되었습니다.
장단기 메모리(LSTM:Long Short-Term Memory)는 은닉층(hidden layer)의 메모리 셀에 입력 게이트, 망각 게이트, 출력 게이트를 추가하여 불필요한 기억을 지우고, 기억해야할 것들을 정합니다.
장단기 메모리(LSTM:Long Short-Term Memory)는 은닉 상태(hidden state)를 계산하는 식이 기존의 순환 신경망( RNN :Recurrent Neural Network)보다 조금 더 복잡해졌으며 셀 상태(cell state)라는 값을 추가하였습니다. 장단기 메모리(LSTM:Long Short-Term Memory)는 순환 신경망( RNN :Recurrent Neural Network)과 비교하여 긴 시퀀스의 입력을 처리하는데 탁월한 성능을 보입니다.
그래서 종합적으로 판단 해본 결과, 시계열 데이터 처리와 예측에 장단기 메모리(LSTM:Long Short-Term Memory)사용하기로 정하고 모델을 설계하였습니다.
사용모듈
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.optimizers import Adam
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from zipfile import ZipFile #압축파일 다루기위해
import os다음과같이 사용 모듈을 import 해주고,
사용할 데이터를 다운받아줍니다.
#기후 정보가 들어있는 데이터 다운로드
zip_path = tf.keras.utils.get_file(origin='https://storage.googleapis.com/tensorflow/tf-keras-datasets/jena_climate_2009_2016.csv.zip',
fname='jena_climate_2009_2016.csv.zip', extract=True)
csv_path, _ = os.path.splitext(zip_path)사용할 데이터셋은 Max Planck Institute for Biogeochemistry에 의해 측정된 Jena Climate dataset 입니다. 이 데이터셋은 온도, 기압, 습도 등의 14가지 컬럼(colum)으로 구성되어 있으며, 매 10분마다 측정되어 있습니다.
독일의 Jena에 위치한 생물지구화학을 연구하는 Max Planck 연구소의 날씨 시계열 데이터 입니다.
데이터 전처리
#데이터에서 5개의 기후관련 컬럼을 추출한 후, 데이터 30만개로 학습데이터 지정
df = pd.read_csv(csv_path)
weather_data=np.array(df[['p (mbar)', 'T (degC)', 'VPmax (mbar)', 'sh (g/kg)', 'wv (m/s)']])
train_data=weather_data[:300000]
train_mean,train_std =np.mean(train_data),np.std(train_data)
train_data=(train_data-train_mean)/train_std사용할 5개의 기후적 특징 컬럼만 남도록 전처리를 해줍니다.
훈련용으로 사용할 30만개의 데이터를 나눠줍니다.
각각 5개의 컬럼들은 아래의 값들을 나타냅니다.
- p (mbar) = 내부 압력을 정량화하는 데 사용되는 파스칼 SI 유도 압력 단위
- T (degC) = 섭씨 온도를 나타냅니다.
- VPmax (mbar) = 포화증기압을 나타냅니다.
- sh (g/kg) = 특정 습도, 특정습도는 습한 공기의 샘플에서 수증기의 질량을 샘플의 질량으로 나눈 것값을 나타냅니다.
- wv (m/s) = 풍속을 나타냅니다.
훈련데이터 지정
시퀀스의 길이를 직접 나누지않고 kears의 keras.preprocessing.timeseries_dataset_from_array를 사용해
훈련 데이터셋을 만들어 주겠습니다.
#데이터를 sequence length 길이로 직접 자르는 작업없이 keras.preprocessing.timeseries_dataset_from_array를 이용하여 train dataset 구성
datax=train_data[:-(sequencelength+predict_step)]
datay=train_data[sequencelength+predict_step:,[1]] #기온을 예측하기 때문에 기온 정보만을 라벨 데이터로 설정
train_dataset = keras.preprocessing.timeseries_dataset_from_array(datax, datay, sequence_length=sequencelength, batch_size=batch_size)훈련 설정(추가)
sequencelength=200 #학습 데이터를 200개 단위로 잘라서 학습
predict_step=60 #10시간 후가 60개 데이터 포인트이므로, 라벨 데이터로 x1 데이터의 60 step 이후의 데이터를 y1데이터로 설정
batch_size=1024 #batch size 설정모델 빌드
다음과 같이 모델을 빌드합니다.
feature_number=5 #feature:T (degC), p (mbar), VPmax (mbar), sh (g/kg), wv (m/s)
inputs = keras.Input(shape=(sequencelength,feature_number))
x = layers.LSTM(units=100)(inputs) #LSTM layer로 학습 모델을 구성
outputs = keras.layers.Dense(1)(x)
model = keras.Model(inputs=inputs, outputs=outputs)
model.compile(optimizer=Adam(learning_rate=0.001), loss='mse', metrics=["mean_squared_error"])
# loss 및 metric으로 mse(평균제곱오차) 설정
model.fit(train_dataset,epochs=30)Epoch 1/30
293/293 [==============================] - 45s 131ms/step - loss: 0.0021 - mean_squared_error: 0.0021
Epoch 2/30
293/293 [==============================] - 40s 137ms/step - loss: 3.1705e-04 - mean_squared_error: 3.1705e-04
Epoch 3/30
293/293 [==============================] - 39s 132ms/step - loss: 3.2673e-04 - mean_squared_error: 3.2673e-04
Epoch 4/30
293/293 [==============================] - 39s 134ms/step - loss: 3.2276e-04 - mean_squared_error: 3.2276e-04
.
.
.
293/293 [==============================] - 39s 133ms/step - loss: 2.8352e-04 - mean_squared_error: 2.8352e-04
Epoch 29/30
293/293 [==============================] - 39s 134ms/step - loss: 2.9059e-04 - mean_squared_error: 2.9059e-04
Epoch 30/30
293/293 [==============================] - 39s 132ms/step - loss: 2.9402e-04 - mean_squared_error: 2.9402e-04
다음과 같은 학습 과정을 확인 하실 수 있습니다.
훈련평가
#최종 train data 평균제곱오차 측정
metrics=model.evaluate(train_dataset, verbose=2)
print("Train Data MSE:", metrics[1])293/293 - 34s - loss: 9.7451e-04 - mean_squared_error: 9.7451e-04 - 34s/epoch - 115ms/step
Train Data MSE: 0.0009745141724124551
오차는 0.0009745141724124551로 매우 적습니다.
예측해보기
예측데이터 지정
남은6만개의 데이터로 테스트 데이터를 설정합니다.
#테스트 데이터 split test_data=weather_data[300000:360000] test_mean,test_std =np.mean(test_data),np.std(test_data) test_data=(test_data-test_mean)/test_std
데이터셋 구성을 해줍니다.
test_datax=test_data[:-(sequenceelength+predict_step)]
test_datay=test_data[sequencelength+predict_step:,[1]]
test_dataset = keras.preprocessing.timeseries_dataset_from_array(test_datax, test_datay, sequence_length=sequencelength, batch_size=batch_size) #array로 시계열데이터 전처리최종적으로 테스트 데이터의 오차를 측정합니다.
#최종 test data mse 측정
metrics=model.evaluate(test_dataset, verbose=2)
print("Test Data MSE:", metrics[1])59/59 - 7s - loss: 5.4285e-04 - mean_squared_error: 5.4285e-04 - 7s/epoch - 126ms/step
Test Data MSE: 0.0005428535514511168
평균 제곱근오차 0.0005428535514511168 인것을 확인할 수 있습니다.
예측결과를 시각화 해보겠습니다.
예측 시각화
#테스트데이터의 샘플 추출
for x, y in test_dataset.take(1):
sample_testx=x
sample_testy=y
#모델로 샘플데이터 예측
predict_results=model.predict(sample_testx)
3번 예측 돌려보도록 하겠습니다.
step=np.array(range(0,261))
plt.title("Test Data Result 1")
plt.xlabel("Step")
plt.ylabel("Y value")
plt.plot(np.array(range(0,200)), sample_temperature_testx[0], 'b', label='test data input(only temperature)')
plt.plot([260], sample_testy[0], 'ro', label='label data')
plt.plot([260], predict_results[0],'go', label='predicted value')
plt.legend(loc='upper right')
plt.show()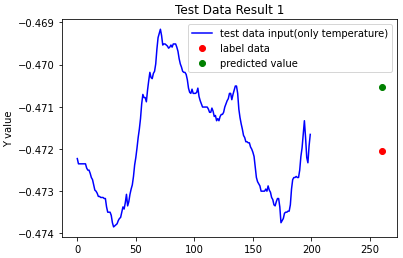
plt.title("Test Data Result 2")
plt.xlabel("Step")
plt.ylabel("Y value")
plt.plot(np.array(range(0,200)), sample_temperature_testx[500], 'b', label='test data input(only temperature)')
plt.plot([260], sample_testy[500], 'ro', label='label data')
plt.plot([260], predict_results[500],'go', label='predicted value')
plt.legend(loc='upper right')
plt.show()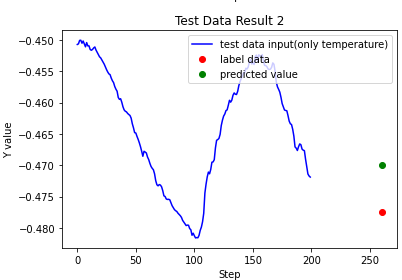
plt.title("Test Data Result 3")
plt.xlabel("Step")
plt.ylabel("Y value")
plt.plot(np.array(range(0,200)), sample_temperature_testx[1000], 'b', label='test data input(only temperature)')
plt.plot([260], sample_testy[1000], 'ro', label='label data')
plt.plot([260], predict_results[1000],'go', label='predicted value')
plt.legend(loc='upper right')
plt.show()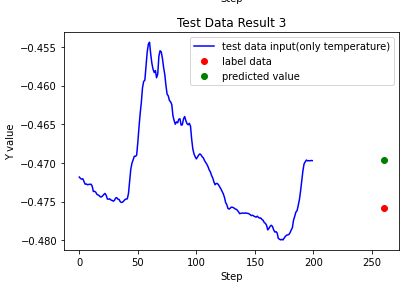
다음과 같이 예측 결과값들을 보실 수 있습니다.
마무리
오늘은 순환 신경망( RNN :Recurrent Neural Network)의 기울기 소멸 문제(vanishing gradient problem)를 획기적으로 방지한 장단기 메모리(LSTM:Long Short-Term Memory)로 30만개의 날씨데이터를 훈련해 예측해보는 모델을 간단히 빌드해보았습니다.
앞으론 개인 프로젝트, 팀으로 진행한 프로젝트들이나, 도커 aws등을 활용한 머신러닝 웹서빙등과 논문리뷰도 업로드 해보려고 합니다.
긴글 읽어주셔서 항상 감사드리고 오늘도 깊은 하루 되세요! 감사합니다.


sequencelength, predict_step, batch_size가 위 본문에서는 정의되어 있지 않습니다. 어떤 값으로 초기화하셨는지 알 수 있나요?