1. 데이터 로드
이번 포스팅에서는 LSTM layer를 어떻게 사용하는지 간단히 코드로 구현해본다. 먼저 데이터셋은 어느정도 전처리가 되어 있는(시퀀스) Keras의 IMDB 데이터셋을 불러온다.
데이터를 불러온 후 padding을 적용하고 전처리를 마무리한다.
from keras.datasets import imdb
from keras.preprocessing import sequence
max_features = 10000 # 특성으로 사용할 단어 수
maxlen = 500 # 사용할 텍스트의 길이 (가장 빈번한 max_feature 개의 단어만 사용)
batch_size = 32
# 시퀀스 데이터 로드
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_features)
print(f"train sequence: {len(x_train)}")
print(f"test sequence: {len(x_test)}")
# 패딩
x_train = sequence.pad_sequences(x_train, maxlen=maxlen)
x_test = sequence.pad_sequences(x_test, maxlen=maxlen)
print(f"x_train size: {x_train.shape}")
print(f"x_test size: {x_test.shape}")Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb.npz
17464789/17464789 [==============================] - 0s 0us/step
train sequence: 25000
test sequence: 25000
x_train size: (25000, 500)
x_test size: (25000, 500)2. 모델 선언
LSTM layer를 호출하여 적용할 수 있다.
from keras.models import Sequential
from keras.layers import Embedding, LSTM, Dense
model = Sequential()
model.add(Embedding(max_features, 32))
model.add(LSTM(32))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])
model.summary()Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, None, 32) 320000
lstm (LSTM) (None, 32) 8320
dense (Dense) (None, 1) 33
=================================================================
Total params: 328353 (1.25 MB)
Trainable params: 328353 (1.25 MB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________3. 모델 학습 및 평가
# 학습
hist = model.fit(x_train, y_train, epochs=10, batch_size=128, validation_split=0.2)Epoch 1/10
157/157 [==============================] - 22s 123ms/step - loss: 0.5839 - acc: 0.6815 - val_loss: 0.4428 - val_acc: 0.8044
Epoch 2/10
157/157 [==============================] - 13s 85ms/step - loss: 0.3575 - acc: 0.8541 - val_loss: 0.3563 - val_acc: 0.8522
Epoch 3/10
157/157 [==============================] - 13s 84ms/step - loss: 0.2858 - acc: 0.8885 - val_loss: 0.2933 - val_acc: 0.8826
Epoch 4/10
157/157 [==============================] - 11s 68ms/step - loss: 0.2378 - acc: 0.9099 - val_loss: 0.3405 - val_acc: 0.8800
Epoch 5/10
157/157 [==============================] - 8s 52ms/step - loss: 0.2103 - acc: 0.9218 - val_loss: 0.3022 - val_acc: 0.8734
Epoch 6/10
157/157 [==============================] - 6s 38ms/step - loss: 0.1889 - acc: 0.9303 - val_loss: 0.3624 - val_acc: 0.8754
Epoch 7/10
157/157 [==============================] - 7s 42ms/step - loss: 0.1716 - acc: 0.9397 - val_loss: 0.3795 - val_acc: 0.8826
Epoch 8/10
157/157 [==============================] - 5s 35ms/step - loss: 0.1559 - acc: 0.9440 - val_loss: 0.3719 - val_acc: 0.8658
Epoch 9/10
157/157 [==============================] - 6s 37ms/step - loss: 0.1449 - acc: 0.9498 - val_loss: 0.3608 - val_acc: 0.8796
Epoch 10/10
157/157 [==============================] - 5s 29ms/step - loss: 0.1304 - acc: 0.9566 - val_loss: 0.3396 - val_acc: 0.8722학습이 어떻게 진행되었는지 그래프를 그려본다.
# 그래프
import matplotlib.pyplot as plt
history = hist.history
acc, val_acc = history['acc'], history['val_acc']
loss, val_loss = history['loss'], history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and Validation Accuracy')
plt.legend()
plt.show()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()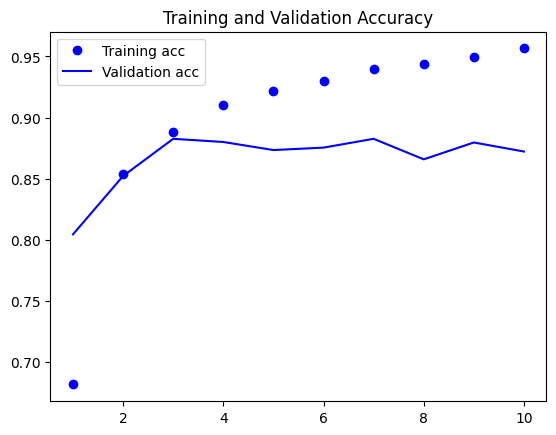
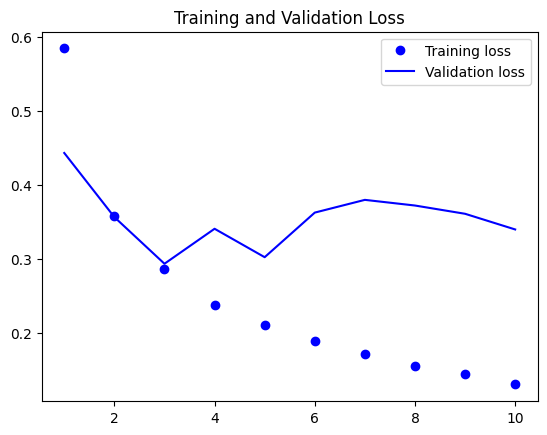
validation accuracy는 0.85를 넘어가면서 더 이상 오르지 않고 validation loss 역시 0.3에서 더 낮아지지 않는다.
정확도를 평가해보면
# 테스트 평가
performance = model.evaluate(x_test, y_test)
print(f"test accuracy: {performance[1]}")782/782 [==============================] - 6s 8ms/step - loss: 0.3718 - acc: 0.8630
test accuracy: 0.8629999756813049validation accuracy와 비슷한 수준의 test accuracy를 확인할 수 있다.
SimpleRNN 네트워크를 사용했을 때보다 성능이 더 좋았다. LSTM이 기울기 소실 문제로부터 덜 영향을 받기 때문이다. 하지만 많은 계산을 한 것치고 획기적인 결과는 아니다. LSTM의 성능이 더욱 더 높게 나오지 않는 이유 중 하나는 임베딩 차원이나 LSTM 출력 차원 같은 하이퍼파라미터를 전혀 튜닝하지 않았기 때문이다. 또 하나는 규제가 없다는 것이다. 그리고 가장 큰 이유는 LSTM이 리뷰를 전체적으로 길게 분석하는 것을 잘하나 이러한 분석이 해결하고자 하는 감성 분류 문제에 도움이 되지 않는다는 것이다. 이런 간단한 문제는 각 리뷰에 어떤 단어가 나타나고 얼마나 등장하는지 보는 것이 더 낫다. Fully Connected Network를 사용한 방법처럼 말이다. 하지만 훨씬 더 복잡한 자연어 처리, 예를 들어 질문응답, 기계 번역과 같은 문제에서는 LSTM의 능력이 드러난다.
