NLP
1.One-Hot Encoding

1. 텍스트 데이터에 대하여 텍스트는 단어의 시퀀스나 문자의 시퀀스로 이해할 수 있고 따라서 가장 흔한 시퀀스 형태의 데이터다. 시퀀스를 처리하는 딥러닝 모델로 문서 분류, 감성 분석, 저자 식별, 질문 응답 등 기본적인 자연어 이해 문제를 해결할 수 있다. 물론 이
2.Word Embedding

1. 워드 임베딩이란? 워드 임베딩이라는 밀집 단어 벡터를 사용하여 단어와 벡터를 연관 지을 수 있다. 원-핫 인코딩으로 만든 벡터는 대부분 0으로 채워져 희소(sparse)하고 고차원(word_index 크기와 차원이 같다)이다. 반면에 워드 임베딩은 밀집된(희소하지 않은) 저차원의 실수형 벡터이다. 원-핫 인코딩으로 얻은 단어 벡터와 달리 워드 임베딩은...
3.텍스트 감성 분류 모델
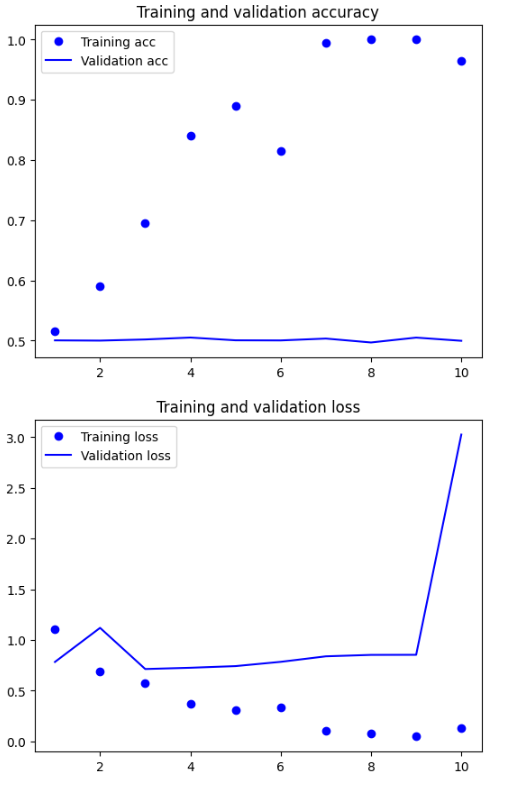
IMDB 데이터셋을 이용하여 텍스트를 긍정과 부정 레이블로 분류하는 모델을 만들어보자. IMDB 원본 데이터셋: http://mng.bz/0tIo GloVe 단어 임베딩: https://nlp.stanford.edu/projects/glove (glove.6B.zip) 1. 데이터 로드 및 전처리 먼저 구글 드라이브에 IMDB 데이터셋을 업로드하였기 때문에...
4.LSTM을 활용한 분류 모델 예시
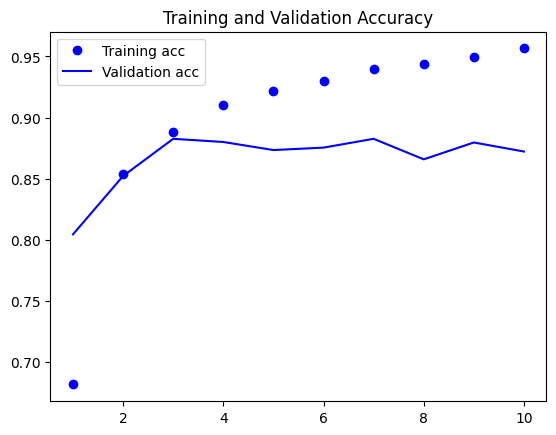
1. 데이터 로드 이번 포스팅에서는 LSTM layer를 어떻게 사용하는지 간단히 코드로 구현해본다. 먼저 데이터셋은 어느정도 전처리가 되어 있는(시퀀스) Keras의 IMDB 데이터셋을 불러온다. 데이터를 불러온 후 padding을 적용하고 전처리를 마무리한다. 2. 모델 선언 LSTM layer를 호출하여 적용할 수 있다. 3. 모델 학습 및 평가...
5.Positional Encoding

1. Positional Encoding 트랜스포머는 seq2seq처럼 입력을 순차적으로 받지 않습니다. 예를 들어 "I am a student"라는 문장이 seq2seq에 입력될 때는 "I" -> "am" -> "a" -> "student" 순으로 처리되지만, 트랜스포머에 입력될 때는 "I", "am", "a", "student"가 동시에 입력되어 처리...
6.Transition-based Dependency Parsing

Parse tree란 문장의 문법 구조를 트리로 표현한 것으로 문장의 구문 구조 분석에 사용됩니다. Parse tree는 구성 성분 구조(constituency structures)와 의존성 구조(dependency structures) 유형이 있습니다. 구성 성분 구조는 구문 구조 문법(phrase structure grammar)을 사용하여 단어들을...
7.Pretraining

이번 포스팅은 현대의 모델 학습에 가장 중요한 과정 중 하나인 Pretraining을 살펴보자. 1. Pretraining - Motivation Pretraining의 주요 아이디어는 다음과 같다. 모델이 대규모의 다양한 데이터셋을 처리할 수 있도록 함 레이블 데이터는 사용하지 않음 레이블 데이터를 사용하면 크기를 늘릴 수 없기 때문 컴...
8.Post Training

일반적인 language modeling(다음 단어 예측)에서 chatGPT처럼 질문에 답변을 하도록 하려면 어떻게 해야 할까? 1. Instruction fine-tuning Language modeling 그 자체가 사용자를 돕는 것은 아니다. 6살 아이에게 달 착륙을 설명해보라고 입력했을 때 GPT-3의 답변을 보자. 이번엔 인간의 답변을 보자...
9.Efficient Adaptation (Prompting + PEFT)

GPT를 다시 떠올려보자. 2018년에 공개된 GPT는 1억 1,700만개의 파라미터와 12개의 트랜스포머 디코더 레이어로 이루어져 있다. 학습 데이터는 약 7,000권 분량의 책들로 만들어진 BookCorpus이며 4.6GB 크기의 텍스트이다. GPT는 대규모 언어 모델링이 자연어 추론같은 태스크에 효과적인 사전 학습 테크닉이 될 수 있음을 보여주었...
10.Question Answering

1. What's QA? Why do we care? 1) What is question answering? $$ \text{Question(Q)} \rightarrow \text{System} \rightarrow \text{Answer(A)} $$ QA의 목표는 "인간이 자연어로 던진 질문(Q)에 자동으로 답변(A)하는 시스템을 구축하는 것"이다....