IMDB 데이터셋을 이용하여 텍스트를 긍정과 부정 레이블로 분류하는 모델을 만들어보자.
- IMDB 원본 데이터셋: http://mng.bz/0tIo
- GloVe 단어 임베딩: https://nlp.stanford.edu/projects/glove (glove.6B.zip)
1. 데이터 로드 및 전처리
먼저 구글 드라이브에 IMDB 데이터셋을 업로드하였기 때문에 Colab과 드라이브를 연동한다. (업로드할 때 시간이 많이 걸렸다는 건 안 비밀...)
from google.colab import drive
drive.mount('/content/drive/')파일을 하나씩 읽어 label과 text를 구하고 labels와 texts 리스트에 추가한다.
# IMDB 원본 데이터 전처리
import os
imdb_dir = '/content/drive/MyDrive/DL/개인공부/aclImdb'
train_dir = os.path.join(imdb_dir, 'train')
labels = [] # y
texts = [] # x
for label_type in ['neg', 'pos']:
dir_name = os.path.join(train_dir, label_type) # 분류 카테고리 별 폴더 경로
if label_type == 'neg':
label = 0
else:
label = 1
for fname in os.listdir(dir_name):
if fname[-4:] == '.txt':
f = open(os.path.join(dir_name, fname), encoding='utf8') # 파일을 하나씩 읽기
texts.append(f.read()) # texts 리스트에 추가
f.close()
labels.append(label) # labels 리스트에 추가데이터를 확인해본다.
print("text data")
for i in range(5):
print(f"{texts[i]}: {labels[i]}\n")text data
OK, so I just saw the movie, although it appeared last year... I thought that it was generally a decent movie, except for the storyline, which was stupid and horrible... First of all, we never get to know anything about the creatures, why they appeared, wtf are they doing in our world, and really, have they been on Earth before we were or did they just come from space? Secondly, the role of the butcher to maintain order is just so obviously created... Really, how large could the underground for a sub station could have been? There were only so many of those creatures, so I think instead of killing innocent people in vain, they could have just planted some tactical bombs, or maybe clear the are and a Nuke would have done the job. I know it sounds funny and it is, but I do not see the killing of people as being NECESSARY... Thirdly, Leon acts like Superman jumping on the train and fighting Vinnie Jones, who was way taller and bigger in stature. Then again, when he faces the conductor he does nothing and acts as a wimp, watching all the abominations. I mean OK, the conductor had creepy help(lol), but if Leon was so brave he would have gone all the way... I mean he risks his life first, then does nothing exactly when he should have. He could have died as a hero but lives as a coward... this might be the case, but not after showing so much braveness earlier on... Then, the cop thing... come on! This was a city having a subway, I bet there must have been other cops except that lady, other police stations,this was really kind of silly... All in all, great acting by Vinnie Jones, interesting idea up to the reason behind it which is not really built at all... By the way, what did the signs on the chest mean? Vinnie Jones cannot make up for the rest...: 0
This relic of a short film starts with a teen going through the process of attempting to get a driver's license. It quickly becomes sidetracked with just about every imaginable topic relating to cars.<br /><br />Such things as dune buggies, drag racing, custom paint jobs and car shows are discussed. It often attempts to be humorous but instead the film is dull, drawn out and even sexist at times. None of the people in the film are actually heard. Instead, everything is done in narration and voiceovers. Sorry, but I can't stand that.<br /><br />There is nothing educational or interesting about "Dad, Can I Borrow The Car?". It's just another piece of mindless filler to take up time on their "Wonderful World Of Disney" TV show. 1/10: 0
This woman who works as an intern for a photographer goes home and takes a bath where she discovers this hole in the ceiling. So she goes to find out that her neighbor above her is a photographer. This movie could have had a great plot but then the plot drains of any hope. The problem I had with this movie is that every ten seconds, someone is snorting heroin. If they took out the scenes where someone snorts heroin, then this would be a pretty good movie. Every time I thought that a scene was going somewhere, someone inhaled the white powder. It was really lame to have that much drug use in one movie. It pulled attention from the main plot and a great story about a photographer. The lesbian stuff didn't bother me. I was looking for a movie about art. I found a movie about drug use.: 0
It's hard to imagine that anyone could find this short their favorite if they have seen most of their shorts, but I know that humor is VERY subjective. I have seen all of their sound shorts (by far the best of their stuff IMO) and I found this one of their weaker efforts.<br /><br />In the year this was made (1930) Stan and Babe made 15 shorts and one feature. They were extremely popular and their boss Hal Roach took full advantage by keeping them working constantly. In addition, this was a time of experimentation for the writers and Stan. I would say this was an experiment that really did not work. As someone else said, it does not play to their strengths. Too much dialog and plot.<br /><br />The best part of this one for me is the largely improvised sequence with Stan as Agnes the maid and the great Thelma Todd talking about "girl" stuff.<br /><br />If you really want to see the boys at their most creative and funny check out Blotto, or Brats From the same year.<br /><br />They made so many shorts in such a short time that I think they can be forgiven for turning out a few less then par shorts. They made something like 108 films altogether. Very few (except for the ones made at FOX) were outright failures but there are some. County Hospital, Me And My Pal, The Live Ghost, The Fixer Uppers come to mind as essentially weak ones. But other then those I find something wonderful in just about all their shorts. Quite a record in my book.<br /><br />If you have seen and enjoyed all their other shorts then by all means check this one out, but I would be willing to bet that this one was less then memorable to Stan and Babe.: 0
I had high hopes for this film, because I thought CLEAN, SHAVEN (Kerrigan's first feature) was absolutely terrific, the most assuredly cinematic low budget film I'd ever seen.<br /><br />But much of CLAIRE DOLAN is utterly pointless and flat. Scene after scene seems randomly tossed into the mix, without much thought for narrative or character.<br /><br />Is Claire trying to escape being a prostitute or not? Hard to tell. Why does she pick up the trick at the airport if she wants to escape that life? Why does she then not pick up tricks when she needs money in Seattle? Why do we have to see her dye her hair to what is virtually the exact same color? Why does Claire accept some johns and not others? The filmmaker doesn't seem to know.<br /><br />It feels as if everything is improvised (though I understand this wasn't the case) and the filmmakers just held a camera on it as if they were making a verite documentary.<br /><br />After the screening I saw, Kerrigan defended his lack of narrative choices by condemning film narrative as politically conservative. It sounded like learned rhetoric. I think it was a cop-out.<br /><br />I am saddened that the maker of a film as exciting as CLEAN, SHAVEN would go on to make such a lame film as this one and then defend it with tired old "political" cliches.: 0texts와 labels에 데이터가 잘 저장되어있고, 5개의 text만 뽑아서 확인해본 결과 한 두 문장을 넘어 여러 문장으로 구성되어 있고 내용도 많은 편이다.
2. 데이터 토큰화
텍스트 데이터를 딥러닝 모델에 맞게 전처리하기 위해 토큰화 및 벡터화 과정을 거친다.
사전 학습된 단어 임베딩(GloVe)을 사용할 것이고 이는 학습 데이터가 부족한 문제에 특히 유용하기 때문에 200개의 데이터로만 학습을 진행해볼 것이다.
# 텍스트 데이터 토큰화
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
import numpy as np
maxlen = 100 # 토큰 개수 맞추기
training_samples = 200 # 훈련 샘플 개수
validation_samples = 10000 # 검증 샘플 개수
max_words = 10000 # 데이터셋에서 가장 빈도 높은 10000개의 단어만 사용
tokenizer = Tokenizer(num_words=max_words)
tokenizer.fit_on_texts(texts)
sequences = tokenizer.texts_to_sequences(texts)
word_index = tokenizer.word_index
print(f"고유 토큰 개수: {len(word_index)}")
data = pad_sequences(sequences, maxlen=maxlen) # padding
labels = np.asarray(labels)
print(f"데이터 크기: {data.shape}")
print(f"레이블 크기: {labels.shape}")
indices = np.arange(data.shape[0]) # 데이터 분할 전 섞기 위한 작업
np.random.shuffle(indices) # 섞기
data = data[indices]
labels = labels[indices]
x_train = data[:training_samples]
y_train = labels[:training_samples]
x_val = data[training_samples:training_samples + validation_samples]
y_val = labels[training_samples:training_samples + validation_samples]고유 토큰 개수: 88582
데이터 크기: (25000, 100)
레이블 크기: (25000,)3. GloVe 임베딩 전처리
glove.6B.zip를 다운로드 받으면 여러 차원의 임베딩 벡터 파일이 들어 있는데 그 중 glove.6B.100d.txt를 사용할 것이다. 40만 개의 단어에 대한 100차원 임베딩 벡터 파일이다.
이 파일을 파싱하여 단어(한 line의 0번째 인덱스 값)와 이에 상응하는 벡터 표현(line의 1번째 인덱스 값의 넘파이 배열)을 매핑하는 인덱스({단어1: 벡터1, 단어2: 벡터2, ...})를 만든다.
glove_dir = '/content/drive/MyDrive/DL/개인공부'
embeddings_index = {}
f = open(os.path.join(glove_dir, 'glove.6B.100d.txt'), encoding='utf8')
for line in f:
values = line.split()
word = values[0]
coefs = np.asarray(values[1:], dtype='float32')
embeddings_index[word] = coefs
f.close()
print(f"단어 벡터 개수: {len(embeddings_index)}")단어 벡터 개수: 400000모델의 Embedding layer로 사용하기 위해 Embedding 행렬을 만든다. 행렬의 크기는 (최대 단어 개수, 임베딩 차원)이어야 한다. 이 행렬의 i번째 원소는 앞서 만든 embeddings_index의 i번째 단어에 상응하는 embedding_dim차원 벡터이다. 인덱스 0은 어떤 단어나 토큰도 아닐 경우를 나타낸다.
100차원의 임베딩 벡터를 사용했으므로 embedding_dim을 100으로 설정한다.
# GloVe 단어 임베딩 행렬 준비
embedding_dim = 100
embedding_matrix = np.zeros((max_words, embedding_dim))
for word, i in word_index.items():
if i < max_words:
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector # 임베딩 인덱스에 없는 단어는 모두 0으로 처리4. 모델 정의
from keras.models import Sequential
from keras.layers import Embedding, Flatten, Dense
model = Sequential()
model.add(Embedding(max_words, embedding_dim, input_length=maxlen))
model.add(Flatten())
model.add(Dense(32, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.summary()Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, 100, 100) 1000000
flatten (Flatten) (None, 10000) 0
dense (Dense) (None, 32) 320032
dense_1 (Dense) (None, 1) 33
=================================================================
Total params: 1320065 (5.04 MB)
Trainable params: 1320065 (5.04 MB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________5. 모델에 GloVe 임베딩 로드
Embedding 층은 하나의 가중치 행렬을 가진다. 이 행렬은 2차원 부동 소수 행렬이고 각 i번째 원소는 i번째 인덱스에 상응하는 단어 벡터이다.
모델의 첫 번째 층인 Embedding 층에 준비한 GloVe 행렬을 로드한다.
추가적으로 Embedding 층의 trainable 속성을 False로 설정하여 업데이트되지 않도록 한다.
# 사전 훈련된 단어 임베딩을 Embedding layer에 로드
model.layers[0].set_weights([embedding_matrix])
model.layers[0].trainable = False6. 모델 학습
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])
hist = model.fit(x_train, y_train, epochs=10, batch_size=32, validation_data=(x_val, y_val))
model.save_weights('pre_trained_glove_model.h5')Epoch 1/10
7/7 [==============================] - 3s 120ms/step - loss: 1.1054 - acc: 0.5150 - val_loss: 0.7837 - val_acc: 0.5004
Epoch 2/10
7/7 [==============================] - 1s 110ms/step - loss: 0.6873 - acc: 0.5900 - val_loss: 1.1201 - val_acc: 0.5000
Epoch 3/10
7/7 [==============================] - 1s 97ms/step - loss: 0.5735 - acc: 0.6950 - val_loss: 0.7140 - val_acc: 0.5019
Epoch 4/10
7/7 [==============================] - 1s 94ms/step - loss: 0.3708 - acc: 0.8400 - val_loss: 0.7265 - val_acc: 0.5051
Epoch 5/10
7/7 [==============================] - 1s 95ms/step - loss: 0.3057 - acc: 0.8900 - val_loss: 0.7427 - val_acc: 0.5005
Epoch 6/10
7/7 [==============================] - 1s 111ms/step - loss: 0.3314 - acc: 0.8150 - val_loss: 0.7849 - val_acc: 0.5003
Epoch 7/10
7/7 [==============================] - 1s 97ms/step - loss: 0.1079 - acc: 0.9950 - val_loss: 0.8392 - val_acc: 0.5034
Epoch 8/10
7/7 [==============================] - 1s 110ms/step - loss: 0.0745 - acc: 1.0000 - val_loss: 0.8534 - val_acc: 0.4969
Epoch 9/10
7/7 [==============================] - 1s 110ms/step - loss: 0.0475 - acc: 1.0000 - val_loss: 0.8542 - val_acc: 0.5050
Epoch 10/10
7/7 [==============================] - 1s 98ms/step - loss: 0.1279 - acc: 0.9650 - val_loss: 3.0266 - val_acc: 0.4997단 몇 에포크만에 Training loss는 0에 가까워지고 Training accuracy는 1이 되었으나 validation loss 값은 학습을 진행할수록 오히려 커지고 validation accuracy는 0.5 전후에서 더 커지지 않고 있다. 그래프를 그려 시각적으로 다시 확인해본다.
# 그래프
import matplotlib.pyplot as plt
history = hist.history
acc = history['acc']
val_acc = history['val_acc']
loss = history['loss']
val_loss = history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()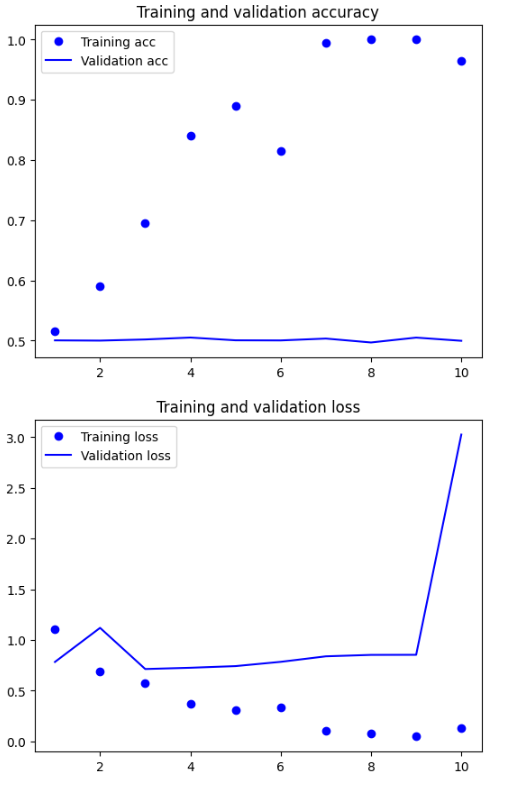
학습 데이터를 200개만 사용했으므로 Training Accuracy 그래프를 통해 과적합이 빠르게 시작된 것을 확인할 수 있고 Training Accuracy와 Validation Accuracy의 차이 또한 크다.
loss 그래프도 Training loss는 과적합으로 인해 0에 수렴하고 있는 모습을 보이지만 Validation loss는 오히려 10번째 학습에서 값이 크게 튄 모습을 확인할 수 있다.
이진 분류 모델의 Validation Accuracy가 0.5라는 것은 사실상 답을 맞춘다기 보다 그냥 찍는 수준이고 따라서 현재의 모델은 형편없다고 할 수 있다. 하지만 학습 데이터 개수를 늘리고 Early Stopping을 사용하여 과적합을 방지한다면 성능이 좋아질 것으로 예상된다.
7. 사전 학습된 단어 임베딩을 사용하지 않고 모델 학습
# 사전 훈련된 단어 임베딩을 사용하지 않고 같은 모델 학습하기
# 사전 훈련된 단어 임베딩을 사용하여 학습하는 것과 사용하지 않고 학습하는 것을 비교
from keras.backend import clear_session
from keras.models import Sequential
from keras.layers import Embedding, Flatten, Dense
clear_session()
model = Sequential()
model.add(Embedding(max_words, embedding_dim, input_length=maxlen))
model.add(Flatten())
model.add(Dense(32, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.summary()Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, 100, 100) 1000000
flatten (Flatten) (None, 10000) 0
dense (Dense) (None, 32) 320032
dense_1 (Dense) (None, 1) 33
=================================================================
Total params: 1320065 (5.04 MB)
Trainable params: 1320065 (5.04 MB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________Embedding layer에 사전 학습된 단어 임베딩을 사용하지 않고 컴파일 및 학습을 진행한다.
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])
hist = model.fit(x_train, y_train, epochs=10, batch_size=32, validation_data=(x_val, y_val))Epoch 1/10
7/7 [==============================] - 3s 337ms/step - loss: 0.6925 - acc: 0.5250 - val_loss: 0.6998 - val_acc: 0.5020
Epoch 2/10
7/7 [==============================] - 2s 269ms/step - loss: 0.5800 - acc: 0.9400 - val_loss: 0.7029 - val_acc: 0.5018
Epoch 3/10
7/7 [==============================] - 1s 211ms/step - loss: 0.4420 - acc: 0.9750 - val_loss: 0.7129 - val_acc: 0.5001
Epoch 4/10
7/7 [==============================] - 1s 188ms/step - loss: 0.2849 - acc: 0.9900 - val_loss: 0.7077 - val_acc: 0.5013
Epoch 5/10
7/7 [==============================] - 2s 319ms/step - loss: 0.1634 - acc: 0.9950 - val_loss: 0.7073 - val_acc: 0.5048
Epoch 6/10
7/7 [==============================] - 2s 246ms/step - loss: 0.0961 - acc: 1.0000 - val_loss: 0.7419 - val_acc: 0.5028
Epoch 7/10
7/7 [==============================] - 1s 164ms/step - loss: 0.0575 - acc: 1.0000 - val_loss: 0.7351 - val_acc: 0.5019
Epoch 8/10
7/7 [==============================] - 1s 160ms/step - loss: 0.0366 - acc: 1.0000 - val_loss: 0.7389 - val_acc: 0.5074
Epoch 9/10
7/7 [==============================] - 1s 150ms/step - loss: 0.0244 - acc: 1.0000 - val_loss: 0.7715 - val_acc: 0.4983
Epoch 10/10
7/7 [==============================] - 2s 369ms/step - loss: 0.0171 - acc: 1.0000 - val_loss: 0.7731 - val_acc: 0.5024그래프를 그려 확인해본다.
# 그래프
import matplotlib.pyplot as plt
history = hist.history
acc = history['acc']
val_acc = history['val_acc']
loss = history['loss']
val_loss = history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()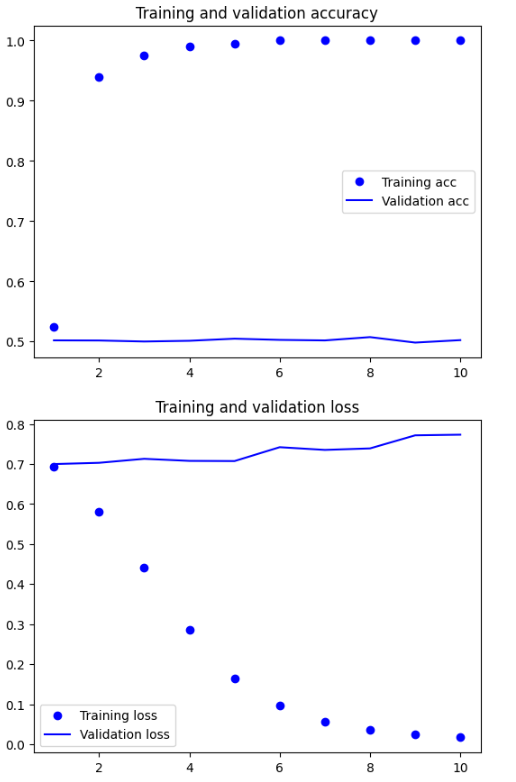
2번째 학습부터 Training Accuracy가 1에 가까워지는 과적합 성향을 보인다. 그리고 Validation Accuracy는 0.5에 계속 머물러있다.
Training loss는 우하향하고 있으나 Validation loss는 오히려 높아지고 있어 이 모델 또한 매우 좋지 않은 모델이라고 할 수 있다.
8. 모델 평가
사전 학습된 임베딩을 사용한 모델을 평가해보자. 테스트 데이터셋을 모델 입력에 맞게 전처리하고 이전에 저장한 가중치를 다시 로드하여 평가한다.
# 테스트 데이터 전처리
train_dir = os.path.join(imdb_dir, 'test')
labels = [] # y
texts = [] # x
for label_type in ['neg', 'pos']:
dir_name = os.path.join(train_dir, label_type) # 분류 카테고리 별 폴더 경로
if label_type == 'neg':
label = 0
else:
label = 1
for fname in os.listdir(dir_name):
if fname[-4:] == '.txt':
f = open(os.path.join(dir_name, fname), encoding='utf8') # 파일을 하나씩 읽기
texts.append(f.read()) # texts 리스트에 추가
f.close()
labels.append(label) # labels 리스트에 추가
sequences = tokenizer.texts_to_sequences(texts)
x_test = pad_sequences(sequences, maxlen=maxlen)
y_test = np.asarray(labels)# 사전 학습된 임베딩을 사용한 모델의 성능 평가
model.load_weights('pre_trained_glove_model.h5')
model.evaluate(x_test, y_test)782/782 [==============================] - 2s 2ms/step - loss: 0.7987 - acc: 0.5746
[0.798652708530426, 0.5745599865913391]앞서 사전 학습된 임베딩을 사용한 모델의 Validation Accuracy에서도 확인할 수 있듯이 테스트 정확도는 0.57로 성능이 매우 좋지 않은 모델이다.
적은 수의 훈련 샘플로 작업하는 것은 어려운 일이다. 하지만 학습 데이터를 늘려본다면...
