
1. Positional Encoding
트랜스포머는 seq2seq처럼 입력을 순차적으로 받지 않습니다.
예를 들어 "I am a student"라는 문장이 seq2seq에 입력될 때는 "I" -> "am" -> "a" -> "student" 순으로 처리되지만, 트랜스포머에 입력될 때는 "I", "am", "a", "student"가 동시에 입력되어 처리됩니다.
트랜스포머처럼 문장을 한꺼번에 입력받는 경우, 어순 정보를 포함하지 못한다는 한계가 있습니다.
그래서 트랜스포머에서는 포지셔널 인코딩 과정을 거쳐 입력 임베딩에 어순 정보를 담아줍니다.

2. Understanding
포지셔널 인코딩은 사인과 코사인 함수를 이용하여 아래 식으로 위치 값을 만들어 냅니다.
는 입력 임베딩에서 벡터 위치를 의미하며 는 차원의 인덱스를 의미합니다.
또한, 은 트랜스포머의 모든 층의 출력 차원을 의미하는 트랜스포머의 하이퍼파라미터입니다.
아래 사진을 보면 는 행 인덱스, 는 열 인덱스, 그리고 열의 크기가 인 것으로 이해할 수 있습니다.
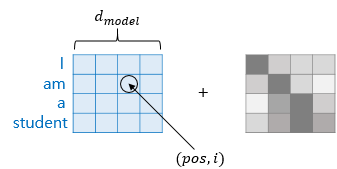
식을 보면 와 을 구분해놨는데, 차원의 인덱스가 짝수인 경우에는 사인 함수를, 홀수인 경우에는 코사인 함수를 사용하기 위함입니다.
이렇게 입력 임베딩에 포지셔널 인코딩 값을 더하면 순서 정보를 담을 수 있습니다.
문장 내에 중복된 단어가 존재하더라도 위치가 다르기 때문에 서로 다른 포지셔널 인코딩 값이 더해지고, 따라서 트랜스포머의 입력 매트릭스에서 중복된 단어는 다른 벡터 값을 갖게 됩니다.
3. Implementations
앞서 살펴본 포지셔널 인코딩을 구하는 공식을 구현해보며 이해해보겠습니다.
목표는 입력 임베딩에 더해줄 seq_length x 크기의 매트릭스를 만들고 그 안에 사인 함수와 코사인 함수를 이용해 위치 값을 넣어 주는 것입니다.
먼저 , , 값을 설정해야 합니다.
1. position
는 입력 임베딩의 벡터 위치, 즉 행을 의미합니다. 다시 말해 입력 문장이 "I am a student"일 때 "I"의 위치, "am"의 위치, "a"의 위치, "student"의 위치를 의미합니다.
따라서 는 입력 시퀀스의 길이 x 1 크기의 벡터로 표현할 수 있습니다. "I am a student"로 예를 들면 4 x 1 크기의 벡터를 만들면 됩니다. 구현을 위해선 시퀀스의 길이를 50으로 설정하겠습니다.
import numpy as np
seq_length = 50
pos = np.arange(seq_length)[:, np.newaxis]를 출력해보면 다음과 같습니다.
array([[ 0],
[ 1],
[ 2],
...,
[47],
[48],
[49]])2. angles
은 출력 차원, 즉 열의 크기를 의미합니다. 입력 문장의 각 벡터 위치를 몇 차원으로 표현할 것인지 뜻합니다. 구현에서는 트랜스포머 모델의 기본 차원인 512로 설정하겠습니다.
예를 들어 "I am a student"가 입력 문장이고 이 512라면 "I", "am", "a", "student" 각각의 위치를 512차원의 값으로 표현한다는 것입니다.
는 차원의 인덱스 벡터를 의미하므로 크기의 차원을 갖는 벡터를 만들어야 합니다. 그리고 와 의 곱을 통해 비로소 입력 임베딩과 같은 크기의 매트릭스를 만들 수 있습니다.
x = (seq_length, 1) x (1 x )
따라서 는 1 x 크기의 벡터로 표현할 수 있습니다.
d_model = 512
i = np.arange(d_model)[np.newaxis, :]를 출력해보면 다음과 같습니다.
array([[ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12,
13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25,
26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38,
...,
481, 482, 483, 484, 485, 486, 487, 488, 489, 490, 491, 492, 493,
494, 495, 496, 497, 498, 499, 500, 501, 502, 503, 504, 505, 506,
507, 508, 509, 510, 511]])와 , 이 다 준비되었습니다! 사인과 코사인 함수를 적용하기 위해 먼저 을 계산하겠습니다.
먼저 은 다음과 같이 계산할 수 있습니다.
2 * (i//2) / np.float32(d_model)계산 방식을 보면 공식과 조금 다른 점을 발견할 수 있습니다.
계산을 공식에 쓰인 그대로 2 * i / d_model을 계산하는 것이 아닌 2 * (i//2) / d_model로 계산하는 것을 확인할 수 있습니다.
사실 공식을 그대로 구현하면 2 * (i//2) / d_model로 구현하는 것이 맞습니다.
에 을 넣으면 와 를 구할 수 있습니다.
번 인덱스와 번 인덱스는 사인, 코사인 함수만 다를 뿐 함수를 적용하는 은 동일한 것을 확인할 수 있습니다.
따라서 인덱스가 , 일 때는 , , 일 때는 , , 일 때는 입니다.
즉 짝수와 홀수의 첫 번째 인덱스는 , 두 번째 인덱스는 , 세 번째 인덱스는 , . . . 라는 패턴을 갖습니다.
이렇게 짝수 인덱스와 홀수 인덱스의 차원 위치 값을 일치시키는 이유는 사인과 코사인의 주파수를 일치시키기 위함입니다.
사인과 코사인이 동일한 주파수를 가지면 짝수 차원과 홀수 차원의 변화 패턴이 서로 연관되어 각 차원에서 위치 정보가 급격히 변하지 않고 부드러운 패턴을 유지할 수 있습니다.
이 값을 d_model인 512로 나누게 되면 동일한 실수 값이 2개 씩 있는 매트릭스가 만들어집니다.
연산의 결과는 다음과 같습니다.
array([[0. , 0. , 0.00390625, 0.00390625, 0.0078125 ,
0.0078125 , 0.01171875, 0.01171875, 0.015625 , 0.015625 ,
0.01953125, 0.01953125, 0.0234375 , 0.0234375 , 0.02734375,
...,
0.9765625 , 0.9765625 , 0.98046875, 0.98046875, 0.984375 ,
0.984375 , 0.98828125, 0.98828125, 0.9921875 , 0.9921875 ,
0.99609375, 0.99609375]])이제 이 벡터를 거듭제곱하여 각도를 계산합니다.
입니다.
angles = 1 / np.power(10000, (2 * (i//2) / np.float32(d_model))결과는 다음과 같습니다. 차원이 뒤로 갈수록 값이 작아지는 것을 확인할 수 있습니다.
array([[1.00000000e+00, 1.00000000e+00, 9.64661620e-01, 9.64661620e-01,
9.30572041e-01, 9.30572041e-01, 8.97687132e-01, 8.97687132e-01,
8.65964323e-01, 8.65964323e-01, 8.35362547e-01, 8.35362547e-01,
...,
1.24093776e-04, 1.24093776e-04, 1.19708503e-04, 1.19708503e-04,
1.15478198e-04, 1.15478198e-04, 1.11397386e-04, 1.11397386e-04,
1.07460783e-04, 1.07460783e-04, 1.03663293e-04, 1.03663293e-04]])3. pos x angles
pos 벡터와 angles 벡터를 곱하여 매트릭스를 만듭니다.
pos는 (seq_length, 1)인 열 벡터, angles는 (1, d_model)인 행 벡터였습니다.
angles_rads = pos * anglesangles_rads는 (seq_length, d_model)인 매트릭스입니다. 여전히 짝수 인덱스와 홀수 인덱스의 주파수가 일치하는 것을 확인할 수 있습니다.
array([[0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ...,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00],
[1.00000000e+00, 1.00000000e+00, 9.64661620e-01, ...,
1.07460783e-04, 1.03663293e-04, 1.03663293e-04],
[2.00000000e+00, 2.00000000e+00, 1.92932324e+00, ...,
2.14921566e-04, 2.07326586e-04, 2.07326586e-04],
...,
[4.70000000e+01, 4.70000000e+01, 4.53390961e+01, ...,
5.05065679e-03, 4.87217476e-03, 4.87217476e-03],
[4.80000000e+01, 4.80000000e+01, 4.63037578e+01, ...,
5.15811758e-03, 4.97583806e-03, 4.97583806e-03],
[4.90000000e+01, 4.90000000e+01, 4.72684194e+01, ...,
5.26557836e-03, 5.07950135e-03, 5.07950135e-03]])4. Sine & Cosine
이제 짝수 인덱스에는 사인 함수를, 홀수 인덱스에는 코사인 함수를 적용해야 합니다.
angle_rads[:, 0::2] = np.sin(angle_rads[:, 0::2])
angle_rads[:, 1::2] = np.cos(angle_rads[:, 1::2])이로써 포지셔널 인코딩이 완성되었습니다!
array([[ 0.00000000e+00, 1.00000000e+00, 0.00000000e+00, ...,
1.00000000e+00, 0.00000000e+00, 1.00000000e+00],
[ 8.41470985e-01, 5.40302306e-01, 8.21856190e-01, ...,
9.99999994e-01, 1.03663293e-04, 9.99999995e-01],
[ 9.09297427e-01, -4.16146837e-01, 9.36414739e-01, ...,
9.99999977e-01, 2.07326584e-04, 9.99999979e-01],
...,
[ 1.23573123e-01, -9.92335469e-01, 9.77189818e-01, ...,
9.99987245e-01, 4.87215549e-03, 9.99988131e-01],
[-7.68254661e-01, -6.40144339e-01, 7.31235909e-01, ...,
9.99986697e-01, 4.97581752e-03, 9.99987621e-01],
[-9.53752653e-01, 3.00592544e-01, -1.44026922e-01, ...,
9.99986137e-01, 5.07947951e-03, 9.99987099e-01]])5. Additional Processing
완성된 포지셔널 인코딩은 2차원 매트릭스입니다.
하지만 트랜스포머 모델의 입력은 항상 3차원 형태를 가져야 하는데요.
그 이유는 배치(batch) 처리를 하기 위함입니다.
따라서 (seq_length, d_model)을 (batch_size, seq_length, d_model)로 변환해야 합니다.
pos_encoding = angle_rads[np.newaxis, ...]
이제 numpy array였던 angle_rads를 트랜스포머에서 사용할 수 있도록 tensor로 변환해주면 진짜 완성입니다!
import tensorflow as tf
pos_encoding = tf.cast(pos_encoding, dtype=tf.float32)6. Graph
포지셔널 인코딩을 시각화하여 특징을 살펴 보겠습니다.
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 6))
plt.pcolormesh(pos_encoding[0], cmap='RdBu')
plt.xlabel("Depth (Embedding Dimension)")
plt.ylabel("Position")
plt.colorbar()
plt.title("Positional Encoding Visualization")
plt.show()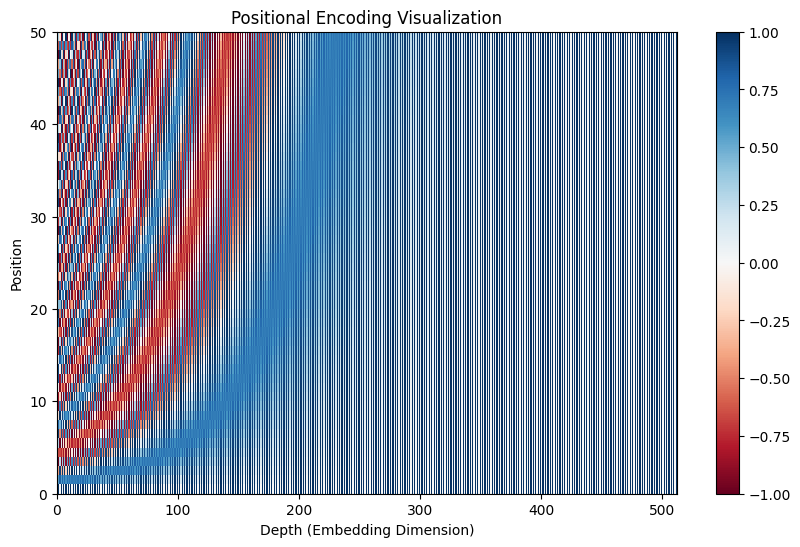
축은 d_model, 즉 512차원의 각 위치를 나타냅니다.
앞서 각도를 계산하며 차원이 커질수록 그 값은 작아지는 것을 확인할 수 있었습니다.
따라서 차원이 높을수록 주파수가 낮아서 위치별 변화가 느린 것을, 차원이 낮을수록 주파수가 높아서 위치별 변화가 빠른 것을 확인할 수 있습니다.
이러한 패턴을 통해 높은 차원에서는 문장 전체의 관계를 잘 학습하도록, 낮은 차원에서는 문장 내에서 가까운 관계를 잘 학습할 수 있습니다.
축은 position, 즉 토큰의 위치를 나타냅니다.
토큰의 위치가 앞쪽(0번)에서 뒤쪽(50번)을 향할수록 주파수의 패턴(-1 ~ 1을 이루는 색상)이 점점 확장되어 색상이 넓게 퍼지는 것을 확인할 수 있습니다.
이는 낮은 토큰 위치에서는 pos * angle 값이 작아서 변화가 거의 없었으나 높은 토큰 위치에서는 pos * angle 값이 커져서 변동이 커지기 때문입니다.
예를 들어 0번 위치에서는 , 로 표현되어 패턴의 변화가 단적이지만 위치 값이 클수록 -1 ~ 1사이를 아우르는 실수 값이 표현되므로 패턴의 변화가 넓습니다.
3. Code
포지셔널 인코딩을 구현하기 위해 사용한 코드는 다음과 같습니다.
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
# 각도 계산
def get_angles(position, i, d_model):
angles = 1 / np.power(10000, (2 * (i//2)) / np.float32(d_model))
return position * angles
# 포지셔널 인코딩 생성
def positional_encoding(position, d_model):
angle_rads = get_angles(
np.arange(position)[:, np.newaxis], # (seq_length, 1)
np.arange(d_model)[np.newaxis, :], # (1, d_model)
d_model)
angle_rads[:, 0::2] = np.sin(angle_rads[:, 0::2])
angle_rads[:, 1::2] = np.cos(angle_rads[:, 1::2])
pos_encoding = angle_rads[np.newaxis, ...] # (1, seq_length, d_model)
return tf.cast(pos_encoding, dtype=tf.float32)
seq_length = 50
d_model = 512
pos_encoding = positional_encoding(seq_length, d_model)
# 시각화
plt.figure(figsize=(10, 6))
plt.pcolormesh(pos_encoding[0], cmap='RdBu')
plt.xlabel("Depth (Embedding Dimension)")
plt.ylabel("Position")
plt.colorbar()
plt.title("Positional Encoding Visualization")
plt.show()텐서플로우를 이용하여 포지셔널 인코딩 클래스를 구현한 코드도 책에서 참고하였습니다.
import numpy as np
import tensorflow as tf
class PositionalEncoding(tf.keras.layers.Layer):
def __init__(self, position, d_model):
super(PositionalEncoding, self).__init__()
self.pos_encoding = self.positional_encoding(position, d_model)
def get_angles(self, position, i, d_model):
angles = 1 / tf.pow(10000, (2 * (i // 2)) / tf.cast(d_model, tf.float32))
return position * angles
def positional_encoding(self, position, d_model):
angle_rads = self.get_angles(
position=tf.range(position, dtype=tf.float32)[:, tf.newaxis],
i=tf.range(d_model, dtype=tf.float32)[tf.newaxis, :],
d_model=d_model)
# 배열의 짝수 인덱스(2i)에는 사인 함수 적용
sines = tf.math.sin(angle_rads[:, 0::2])
# 배열의 홀수 인덱스(2i+1)에는 코사인 함수 적용
cosines = tf.math.cos(angle_rads[:, 1::2])
angle_rads = np.zeros(angle_rads.shape)
angle_rads[:, 0::2] = sines
angle_rads[:, 1::2] = cosines
pos_encoding = tf.constant(angle_rads)
pos_encoding = pos_encoding[tf.newaxis, ...]
print(pos_encoding.shape)
return tf.cast(pos_encoding, tf.float32)
def call(self, inputs):
return inputs + self.pos_encoding[:, :tf.shape(inputs)[1], :]
