
Parse tree란 문장의 문법 구조를 트리로 표현한 것으로 문장의 구문 구조 분석에 사용됩니다.
Parse tree는 구성 성분 구조(constituency structures)와 의존성 구조(dependency structures) 유형이 있습니다.
구성 성분 구조는 구문 구조 문법(phrase structure grammar)을 사용하여 단어들을 중첩된 구성 성분으로 구성하는 것입니다.
예를 들어 the dog를 살펴봅시다.
-
the는 정관사이므로 문법적으로 "한정사"입니다.
한정사는 Determiner이므로 Det으로 표기합니다.
따라서 로 표현할 수 있습니다. -
dog는 "명사"입니다.
명사는 N으로 표기합니다.
따라서 로 표현할 수 있습니다. -
the dog는 "명사구"입니다.
명사구는 NP로 표기합니다.
따라서 로 표현할 수 있습니다.
명사구 내의 한정사와 명사까지 문법으로 분석하면 입니다.
구성 성분 구조는 문장 구조를 이해하는데 도움을 줍니다.
하지만 아래의 문장을 살펴봅시다.
Scientists count whales from space
과학자가 우주에서 고래를 세고 있다는 뜻입니다.
우리는 이 뜻을 자연스럽게 우주에 있는 과학자가 바다에 있는 고래의 수를 센다로 이해합니다.
하지만 우주에 있는 과학자가 우주에서 유영하고 있는 고래의 수를 센다로 해석할 수도 있습니다.
전치사구와 동사구가 모호하여 이중으로 해석되기 때문입니다.
이때 의존성 방향(dependency paths)이 의미 해석에 도움을 줄 수 있습니다.
의존성 구조는 단어 간의 의존 관계, 즉 수식과 피수식 관계를 파악하는 것입니다.
단어 간 이진 비대칭 관계(binary asymmetric relations)를 아래 그림처럼 화살표로 표현합니다.
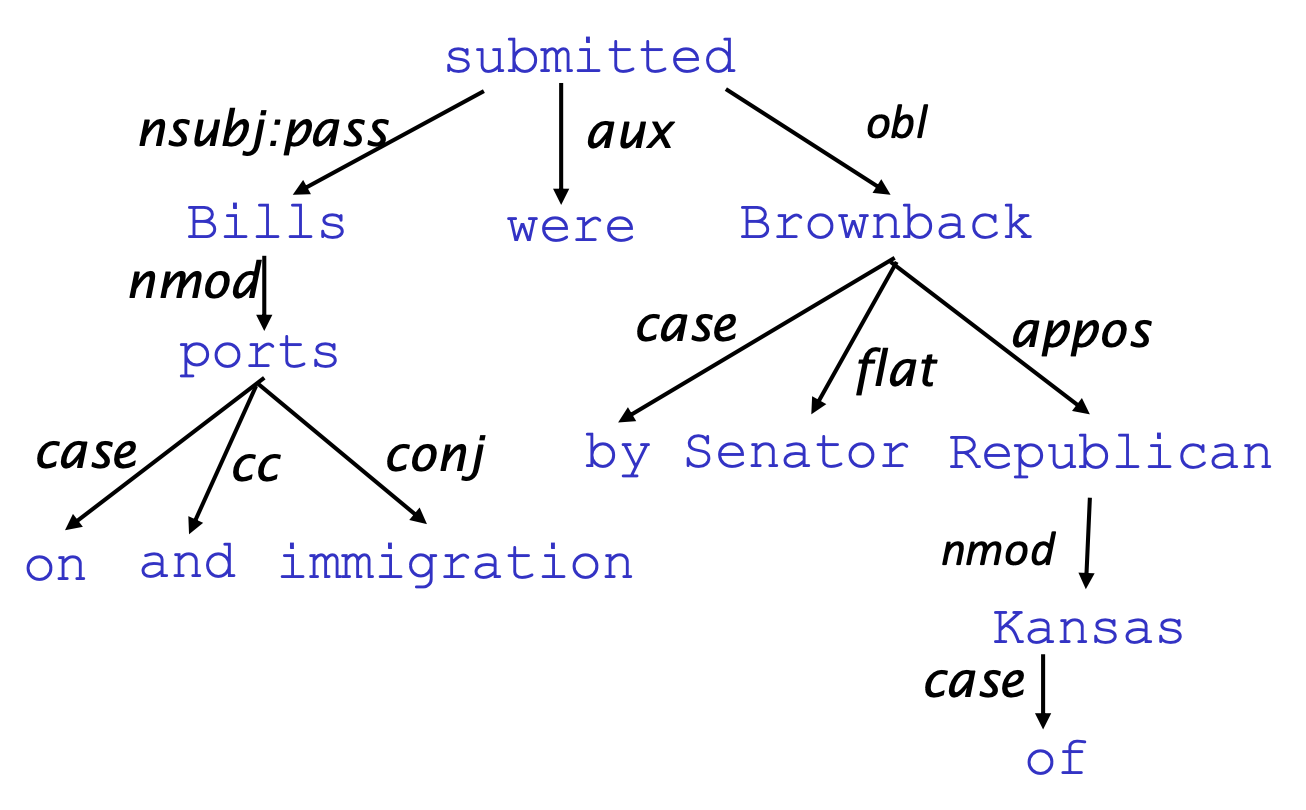
그리고 여러 화살표들이 모여 트리 구조를 형성합니다.
이때 각 단어는 지배(head) 또는 피지배(dependent) 역할을 가지며
지배와 피지배 관계는 로 표현할 수 있습니다.
이번 포스팅은 의존성 구문 분석(dependency parsing)과 Transition-based dependency parsing을 알아보겠습니다.
1. Dependency Parsing
의존성 구문 분석(dependency parsing)은 입력 문장 의 구문 의존 구조(syntactic dependency structure)를 분석하는 작업입니다.
쉽게 말해 단어들로 이루어진 입력 문장 (여기서 는 ROOT)을
의존성 트리 그래프 로 매핑하는 과제입니다.
따라서 출력은 문장의 단어들이 의존 관계로 연결된 의존성 트리입니다.
이 트리는 하나의 ROOT만 존재하며 이 때 ROOT는 문장의 주요 동사이거나 가짜 ROOT입니다.
가짜 ROOT 노드는 트리 전체의 헤드로 추가되며 모든 단어가 정확히 하나의 노드에 의존하도록 만들기 위함입니다.
의존성 구문 분석은 학습과 구문 분석, 두 가지 문제를 다룹니다.
학습은 주석(annotated)된 문장 집합 가 의존성 그래프에 주어졌을 때 새로운 문장을 구문 분석할 수 있는 모델 을 학습합니다.
구문 분석은 학습된 구문 분석 모델 과 새로운 문장 가 주어졌을 때 모델 에 따라 문장 의 최적 의존성 그래프 를 생성합니다.
2. Transition-based Dependency Parsing
Transition-based dependency parsing의 가장 일반적이고 효율적인 구현 방식 중 하나인 Greedy Deterministic Transition-based Parsing을 기반으로 설명하겠습니다.
전이 기반(transition-based)은 문장을 읽고 상태(state)를 변경해가며 의존 트리를 점진적으로 만들어가는 방식을 뜻합니다.
그럼 state와 transition이 무엇인지 살펴보겠습니다.
State
어떤 문장 이 주어졌을 때 하나의 상태 는 아래의 삼중항으로 정의됩니다.
- : 의 단어들 중 일부를 담고 있는 stack
- : 의 단어들 중 아직 처리되지 않은 단어들을 담고 있는 buffer
- : 형태가 인 의존성 관계(arc) 집합
여기서 와 는 문장의 단어이며 은 의존 관계의 종류
문장 에 대해 다음이 성립합니다.
-
초기 상태 은 아래와 같이 ROOT()만 stack에 있고 나머지 단어들은 buffer에 있으며 아직 어떤 전이도 되지 않은 상태
-
종결 상태는 buffer가 완전히 비고 모든 의존 관계가 설정
Transitions
의존성 구문 분석을 위한 전이는 SHIFT, LEFT-ARC, RIGHT-ARC 세 가지로 구성됩니다.
먼저 SHIFT는 buffer에서 첫 번째 단어를 제거하고 그 단어를 stack의 맨 위에 넣는 작업을 의미합니다.
단 buffer가 비어있지 않아야 합니다.
LEFT-ARC는 의존 관계 를 에 추가하는 작업을 의미합니다.
여기서 는 stack에서 두 번째 단어(top - 1)이고 는 stack의 맨 위(top) 단어입니다.
그 다음 를 제거합니다.
단 stack에 최소 2개 이상의 단어가 있어야 하고 는 ROOT가 아니어야 합니다.
RIGHT-ARC는 의존 관계 를 에 추가하는 작업을 의미합니다.
여기서도 는 stack에서 두 번째 단어(top - 1)이고 는 stack의 맨 위(top) 단어입니다.
그 다음 를 제거합니다.
단 stack에 최소 2개 이상의 단어가 있어야 합니다.
3. Example
간단한 예를 들어보겠습니다.
She eats apples라는 문장을 예로 들어봅시다.
우선 초기에는 모든 단어가 처리되지 않았으니 모두 buffer에 존재할 것입니다.
먼저 첫 단어 를 stack에 저장합니다.
stack의 최상단에는 가 있습니다.
그 다음 단어 를 처리합니다.
stack의 최상단에는 가 있습니다.
Stack의 두 번째 단어 는 첫 번째 단어 에 의존합니다.
따라서 라는 의존 관계가 만들어집니다.
이 의존 관계를 에 저장하고 stack의 두 번째 단어 를 제거합니다.
다음 단어 를 처리합니다.
stack의 최상단에는 가 있습니다.
Stack의 첫 번째 단어 는 두 번째 단어 에 의존합니다.
따라서 라는 의존 관계가 만들어집니다.
이 의존 관계 역시 에 저장하고 stack의 첫 번째 단어 을 제거합니다.
Stack의 와 사이에 루트 관계를 만듭니다.
가 문장의 루트가 되고 Stack에서 제거됩니다.
buffer가 비고 stack에 만 남았으므로 구문 분석을 종료합니다.
이로써 의존성 트리(dependency tree)가 만들어졌습니다.
4. 정리
이번 포스팅은 전이 기반 의존성 구문 분석에 대해 알아봤습니다.
이 방식은 전통적인 구문 분석으로 널리 알려져있습니다.
하지만 최근에는 딥러닝을 활용한 neural dependency parsing이 각광받고 있습니다.
다음 포스팅은 신경망 의존성 구문 분석에 대해 알아보고 전통적인 방식과의 차이점을 알아보도록 하겠습니다.
