
이번 포스팅은 현대의 모델 학습에 가장 중요한 과정 중 하나인 Pretraining을 살펴보자.
1. Pretraining - Motivation
Pretraining의 주요 아이디어는 다음과 같다.
-
모델이 대규모의 다양한 데이터셋을 처리할 수 있도록 함
-
레이블 데이터는 사용하지 않음
레이블 데이터를 사용하면 크기를 늘릴 수 없기 때문
-
컴퓨팅 자원을 고려한 스케일링
2. Subword Modeling
수만개의 단어로 구성된 데이터를 학습하면 수만개의 단어로 구성된 고정된 어휘(vocabulary)를 가정할 수 있다.
예를 들어 hat처럼 흔한 단어는 학습 데이터에 분명히 존재하므로 vocabulary에도 이 단어를 찾을 수 있다.
그래서 테스트 타임에서 을 발견하면 vocabulary에서 매핑될 수 있다.
하지만 테스트 타임에서 처음 보는 단어, 즉 학습되지 않은 미지의 단어의 경우는 어떻게 해야할까?
미지의 단어는 사전에 구축한 vocabulary에 없으므로 모두 라는 토큰으로 매핑된다.
그림을 살펴보자.
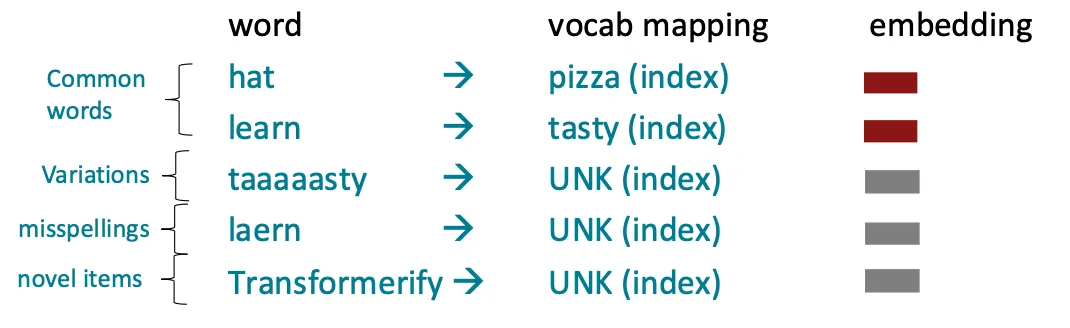
은 에 은 에 매핑되는 것을 확인할 수 있다.
'hat'은 왜 'hat'으로 매핑 안되고 'pizza'에 매핑되지? 'learn'은 왜 'tasty'에 매핑되지...
: 이 예시는 'hat', 'learn'이 흔한 단어이므로 vocabulary에 있는 단어로 매핑 가능함을 보여주는 예
그럼 'pizza', 'tasty'말고 'hat', 'learn'으로 표현하면 되는데 굳이 왜 이렇게 표현했는가?
: 수업 흥미 유발을 위한 장난이거나 잘못 적은 것 같다...
아래의 설명에선 'hat'은 'hat'으로, 'learn'은 'learn'으로 매핑되니 신경쓰지 말자!
중요한 건 'hat'과 'learn' 같은 흔한 단어는 사전에 구축된 단어로 매핑될 수 있다는 것가 변형된 나 을 잘못 쓴 , 새로운 단어 의 경우 매핑할 수 없는 단어이므로 에 매핑된다.
The Byte-pair Encoding Algorithm
NLP에서 subword modeling은 단어의 일부, 문자, 바이트같은 단어 이하 수준의 구조를 추론하는 것을 의미한다.
현대의 주요 패러다임은 단어의 일부로 구성된 어휘를 학습하는 것이다.
예를 들어 단어 는 하위 단어 로 구성되어 있다.
Byte-pair encoding은 이 같은 하위 단어 어휘를 정의하는 간단하고 효과적인 전략이다.
-
문자와 단어 끝 기호만 포함된 어휘로 시작한다.
예를 들어 는 로 구성되어 있고 여기서 가 단어 끝 기호다.
-
코퍼스에서 가장 일반적인 인접 문자 "a, b"를 찾고 "ab"를 하위 단어로 추가한다.
예를 들어 라는 단어 집합이 있을 때 아래와 같은 하위 단어로 쪼개진다.
여기서 가장 일반적인 인접 문자를 찾기 위해 문자 쌍 빈도를 계산한다.
가장 자주 등장하는 쌍이 "e, s"라고 가정하면 "es"를 하나의 토큰으로 병합하여 하위 단어로 추가한다.
-
문자 쌍의 인스턴스를 새로운 하위 단어로 대체하고 이 과정을 원하는 어휘 크기가 될 때까지 반복한다.
가장 자주 등장한 쌍 를 로 대체한다.
는 와 에 포함된 하위 단어이므로 개별 단어 를 로 병합하고 대체한다.
Byte-pair encoding algorithm은 원래 자연어 처리의 기계 번역 태스크에 사용되었다.
현재는 사전 학습된 모델에서 유사한 방법인 WordPiece가 사용된다.
자 다시 이 그림을 떠올려보자.
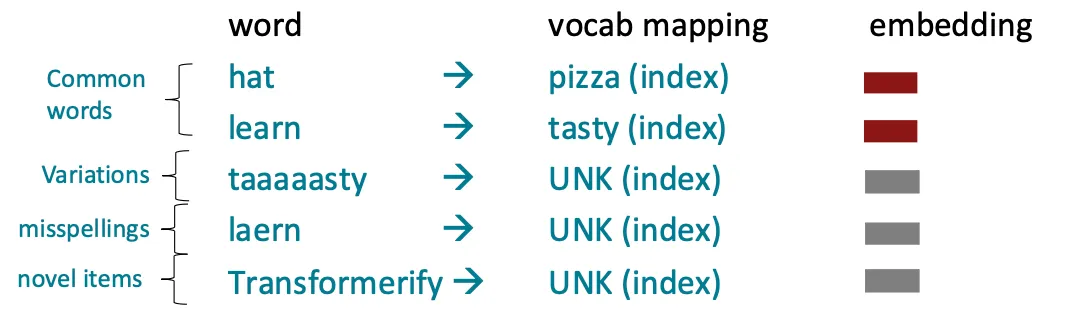
여기에 byte-pair encoding을 적용하면 아래와 같다.
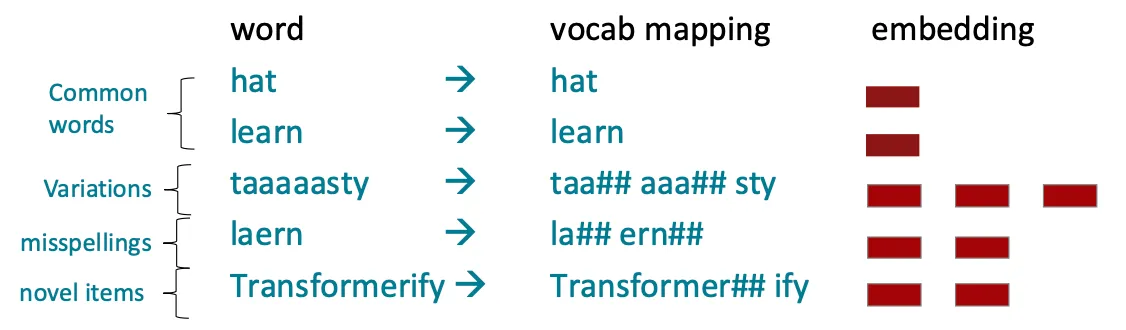
흔히 사용되지 않는 단어인 와 , 가 하위 단어로 나뉜 것이 확인된다.
는 직관적이고 은 비교적 직관적이지 않다.
이처럼 하위 단어는 때로는 직관적으로, 때로는 직관적이지 않은 구성 요소로 나눠 진다.
최악의 경우엔 문자 수만큼 하위 단어로 나뉘기도 한다.
3. Motivating Model Pretraining from Word Embeddings
단어는 그 단어와 함께하는 존재로 알 수 있다.이 인용문은 분포 의미론을 요약한 표현이며 word2vec에 영감을 주었지만 한계가 존재했다.
단어의 완전한 의미는 항상 맥락에 따라 달라지며 완전한 맥락 없이는 완전한 의미도 포착할 수 없다."" 문장에서 같은 단어 가 다른 의미로 사용되는 것을 보면 알 수 있다.
초기 word embeddings는 학습된 임베딩 벡터를 단어마다 고정해두었다.
라는 단어는 어떤 문장에 등장하든 항상 같은 벡터를 가진다.
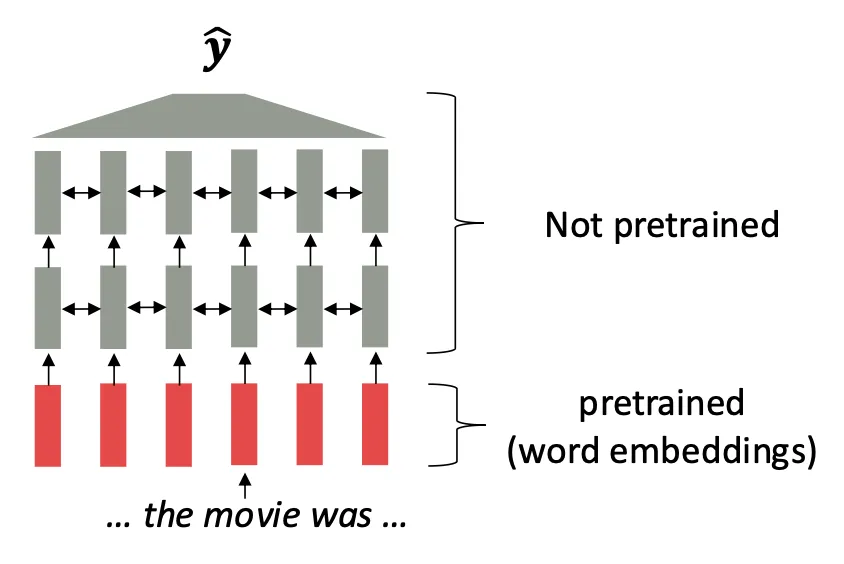
따라서 이후의 연구는 LSTM이나 Transformer가 하위 태스크를 학습하면서 전체 문맥을 통합하는 것에 초점을 두었다.
하지만 질의 응답같은 복잡한 태스크를 위한 학습 데이터는 언어의 모든 문맥을 가르치기 충분하지 않았다.
게다가 대부분의 신경망 파라미터는 임의적으로 초기화된 상태에서 학습을 시작한다는 것도 문제였다.
현대의 NLP는 어떤 방식으로 위 문제를 해결할까?
NLP 신경망의 파라미터는 pretraining을 통해 초기화된다.
이때 pretraining은 입력 문장의 일부를 가리고 모델이 가려진 부분을 복원하도록 학습시키는 방식으로 진행된다.
Pretraining은 강력한 언어 표현, 파라미터 초기화, 확률 분포를 구축하는 데 효과적이었다.
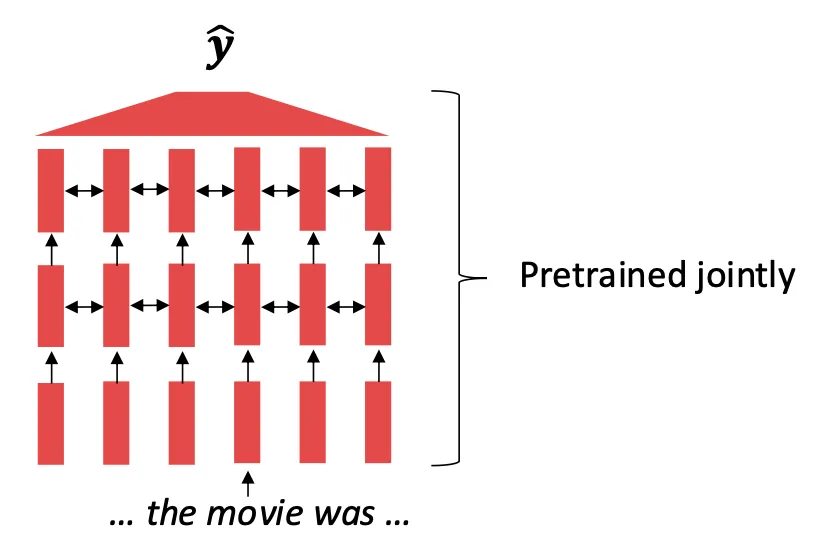
입력의 일부를 숨기고 숨겨진 것을 맞히는 과정이란 어떤 걸까?
이렇게 입력 문장에 빈칸을 만들고 저 빈칸에 들어갈 단어가 무엇인지 맞추면서 모델이 학습한다.
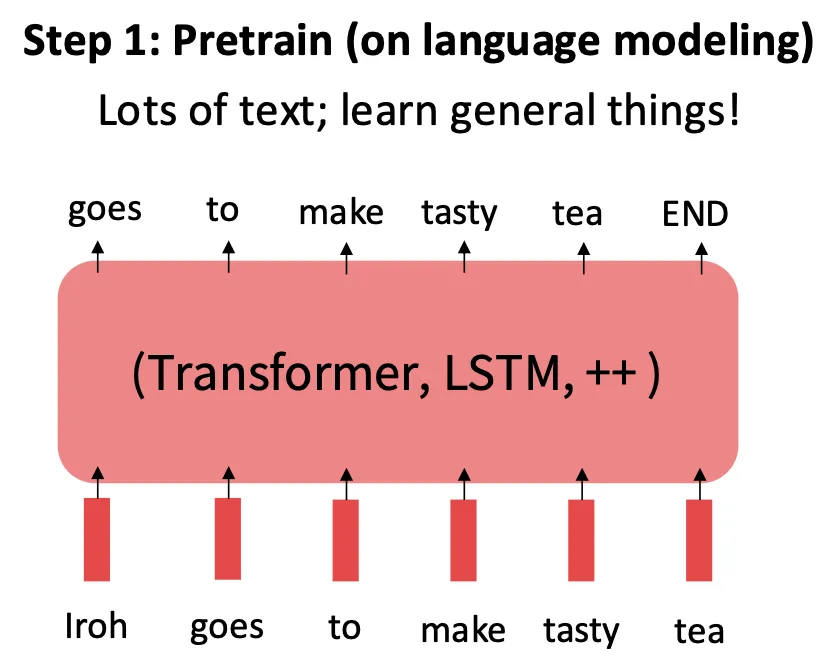
Language modeling을 통한 pretraining은 어떨까?
먼저 language modeling을 떠올려보자.
단어의 확률 분포 모델 은 시점의 단어의 확률 분포 계산을 위해 과거의 맥락을 모두 고려한다.
Language modeling을 통한 pretraining은 대량의 텍스트에 대해 language modeling을 하도록 신경망을 학습시킨 후 신경망의 최종 파라미터를 저장하면 된다.
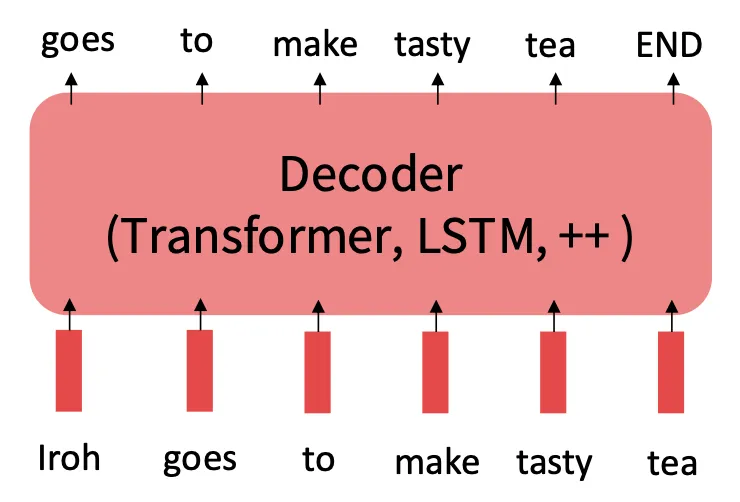
Pretraining 후에는 Finetuning을 수행한다.
Finetuning을 시작할 때의 파라미터는 임의로 초기화된 상태가 아닌 pretraining의 파라미터이므로 여러 이점이 있다.
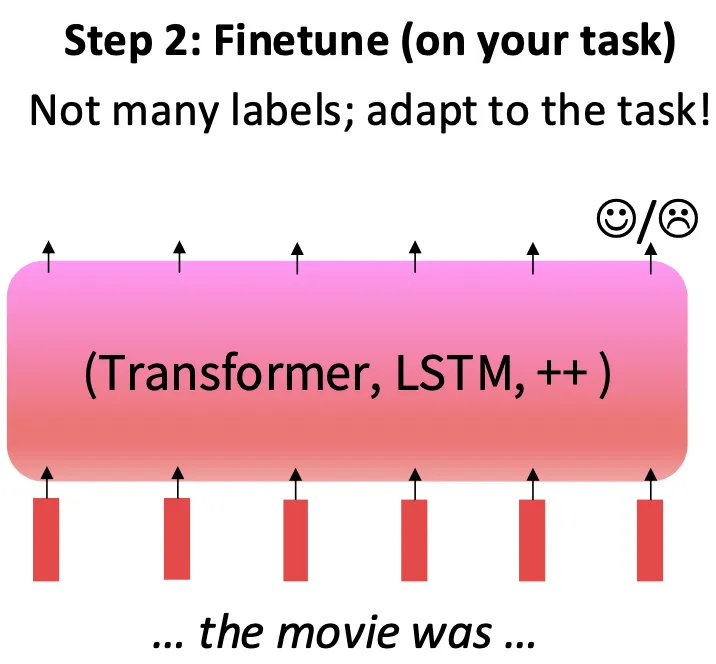
어떤 이점이 있는지 신경망의 학습 관점에서 살펴보자.
신경망은 pretraining 단계에서 을 최소화하는 파라미터, 즉 를 찾는다.
pretraining의 결과는 에 근사한 파라미터 이다.
Finetuning 단계에서는 이 에서 시작하여 에 근사하는 파라미터를 찾는다.
이 말은 확률적 경사 하강법이 근처에서 탐색을 이어 간다는 말이다.
이때 주변의 지역 최솟값이 일반화가 잘 되는 경향이 있고 주변의 finetuning의 손실 기울기도 잘 전파될 수 있다.
질의 응답처럼 고품질의 레이블 데이터가 많은데도 왜 pretraining에서는 비지도 학습을 택할까?
그 이유는 데이터의 양 때문이 아니라 다양성 때문이다.
인터넷의 텍스트 데이터는 문맥이 풍부하고 다양하다.
질의 응답 태스트 데이터가 아무리 품질이 좋다하더라도 인터넷의 텍스트 데이터 만큼 다양성을 가지긴 쉽지 않다.
따라서 인터넷의 텍스트 데이터를 레이블링 없이 활용하면 모델이 보편적이고 다양한 지식을 학습할 수 있다.
4. Model Pretraining Three Ways
1. Encoders
인코더에서는 양방향 문맥을 사용하여 미래의 단어도 확인할 수 있다.
그렇다면 강력한 표현을 만들기 위해선 어떻게 학습해야 할까?
Pretraining Encoders
지금까지는 language model pretraining을 살펴봤다.
인코더에서 양방향 문맥을 사용하므로 language modeling을 사용할 수 없다.
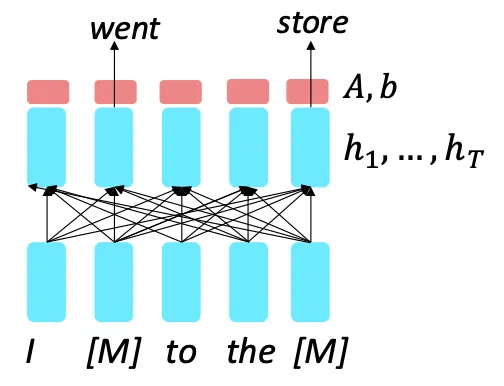
따라서 입력 문장의 일부 단어들을 특별한 [MASK] 토큰으로 대체하고 이 대체된 단어들을 예측하는 방식으로 학습한다.
이때 masked out인 단어에만 손실 항을 추가한다.
Masked out인 단어에만 손실 항을 추가한다는 말은 전체 시퀀스에서 손실을 계산할 때 [MASK]로 가려진 단어 위치에는 손실을 포함시키고 가려지지 않은 단어 위치는 손실을 계산하지 않는다는 말이다.
따라서 가 의 마스킹된 버전이라면 모델은 를 학습하는 것이다.
이것을 Masked LM이라고 한다.
BERT: Bidirectional Encoder Representations from Transformers
Devlin et al.은 2018년에 Masked LM을 제안하고 BERT라는 pretrained transformer의 가중치를 공개했다.
BERT의 방식을 좀 더 살펴보면 아래와 같다.
-
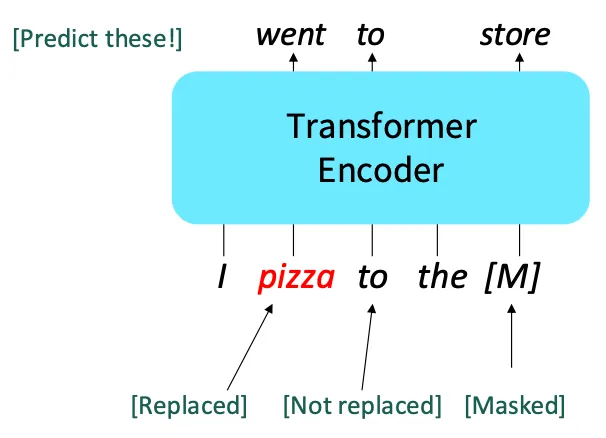
단어 토큰 중 임의의 15%를 예측, 이 15%의 토큰을 아래처럼 처리함
- 입력 단어의 80%의 [MASK] 토큰으로 대체- 입력 단어의 10%의 무작위 토큰으로 대체
- 입력 단어의 10%는 바꾸지 않고 남기지만 예측은 그대로 함
BERT의 pretraining 입력은 두 개의 문장 덩어리이다.
예를 들어 이다.
BERT는 한 문장이 다른 문장을 따르는지 아니면 관련 없는 무작위 문장인지 예측하도록 학습되었다.
이를 next sentence prediction이라고 부르는데 후에는 이러한 과정이 불필요하다고 주장되었다.
BERT의 세부적인 사항을 살펴보자.
-
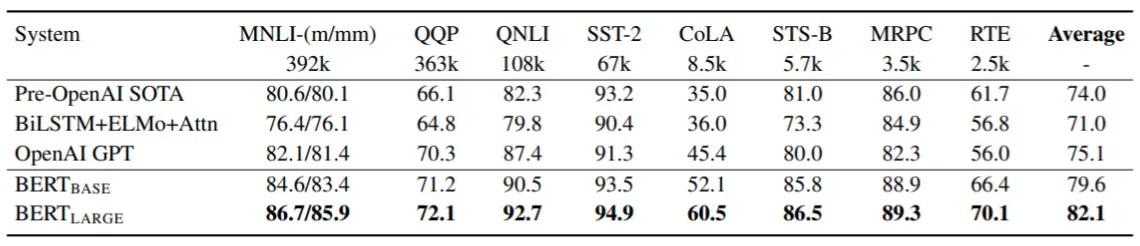
BERT-base와 BERT-large, 2개의 모델이 함께 공개되었다.
BERT-base는 12개의 레이어, 768차원의 은닉 상태, 12개의 어텐션 헤드, 1억 1,000개의 파라미터로 구성되어 있다.
BERT-large는 24개의 레이어, 1024차원의 은닉 상태, 16개의 어텐션 헤드, 3억 4,000개의 파라미터로 구성되어 있다. -
학습 데이터
8억개의 단어로 구성된 BookCopus와 25억개의 단어로 구성된 English Wikipedia로 학습되었다. -
Pretraining은 단일 GPU에서는 비용이 비싸고 실용적이지도 않다.
BERT는 64개의 TPU 칩으로 4일에 걸쳐 학습되었다.
TPU는 특수한 텐서 연산 가속 장치이다. -
Finetuning은 단일 GPU에서도 실용적이고 흔하다.
따라서 pretraining은 한번, finetuning은 여러 번 수행한다.
BERT를 finetuning하여 광범위한 태스크에서 SOTA를 얻을 수 있었다.
Limitations of Pretrained Encoders
BERT의 성능이 훌륭한데도 왜 pretrained encoder를 모든 태스크에 사용하지 않을까?
만약 태스크가 시퀀스를 생성하는 것과 관련있다면 pretrained decoder를 사용하는 것을 고려해야 한다.
BERT와 다른 pretrained encoder는 근본적으로 자기회귀 생성 방식을 사용하지 않는다.
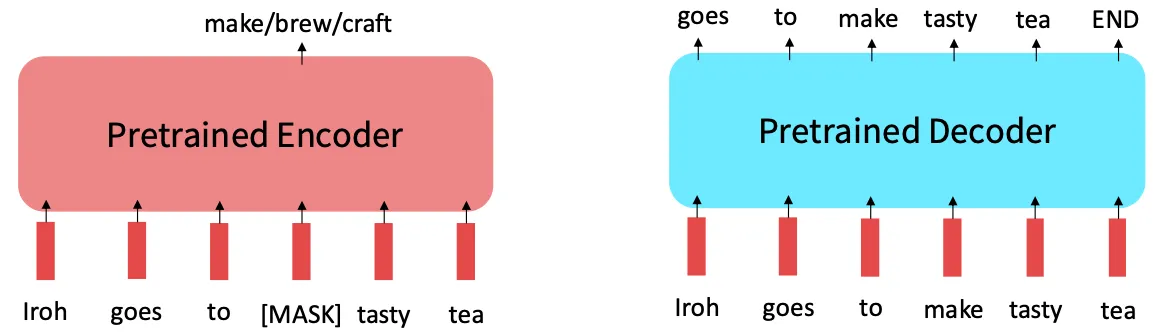
Extensions of BERT
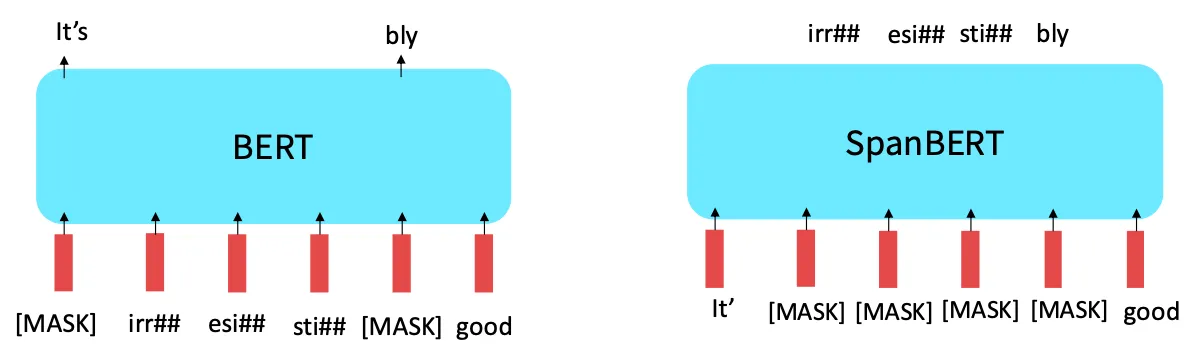
RoBERTa, SpanBERT 등의 다양한 BERT의 변종을 볼 수 있다.
BERT의 pretraining 공식에 일반적으로 받아들여지는 몇 가지 개선 사항을 RoBERTa와 SpanBERT로 살펴보자.
-
RoBERTa: BERT를 더 길게 학습하고 next sentence prediction 제거
-
SpanBERT: 연속된 단어 범위를 마스킹하여 더 어렵지만 더 유용한 pretraining 태스크가 됨
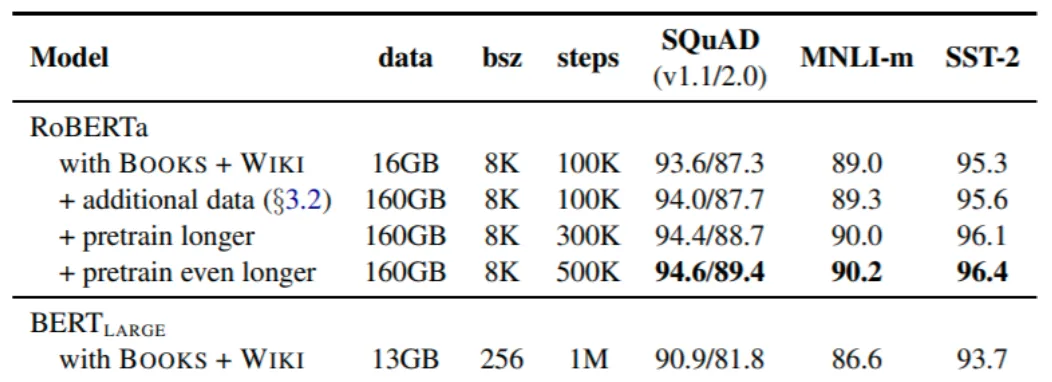
RoBERTa 논문에서 얻은 결론은 더 많은 컴퓨팅과 더 많은 데이터는 기본적인 트랜스포머 인코더를 변경하지 않더라도 pretraining을 개선할 수 있다는 것이다.
2. Encoders-Decoders
디코더와 인코더의 장점은 무엇일까?
인코더-디코더를 pretraining하는 가장 좋은 방법은 무엇일까?
Pretraining encoder-decoders: what pretraining objective to use
인코더-디코더 모델은 language modeling을 할 수 있다.
입력 문장을 prefix, suffix로 나누고 인코더에 prefix를 넣고 디코더는 suffix를 예측한다.
예를 들어 문장 "Carolina woke up in the morning and got ready for work."에 대해 아래처럼 나눌 수 있다.
prefix: Carolina woke up in the morning
suffix: and got ready for work.인코더에 입력된 prefix를 조건으로 하여 디코더가 language modeling 방식으로 suffix를 예측한다.
당연한 말이지만 prefix는 예측 대상이 아니다.
이것을 간단한 식으로 정리하면 아래와 같다.
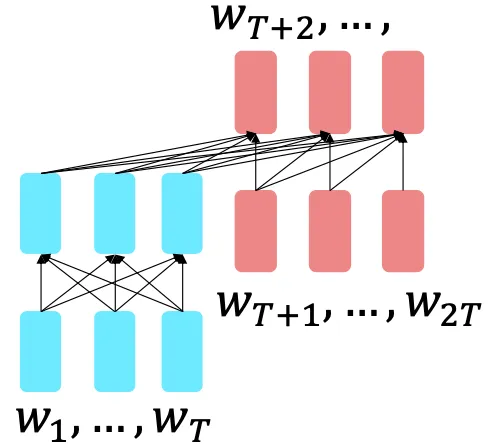
정리하면 인코더-디코더 모델에서 인코더는 양방향 문맥의 이점을 활용하고 디코더는 language modeling을 통해 전체 모델을 학습하는데 사용된다.
Raffel et al.(2018)이 발견한 가장 효과적인 방법은 span corruption이었으며 모델은 T5이다.
앞서 언급한 prefix, suffix를 활용하는 방법과는 사뭇 다르다.
span은 연속적인 구간을 뜻하고 corruption은 변형을 뜻한다.
그러니까 span corruption은 문장의 연속적인 구간을 변형을 한다는 것이다.
인코더에는 연속된 구간이 변형된 문장이 입력되고 디코더에서 이 변형을 예측한다.
좀 더 구체적으로 말하자면 길이가 다른 span을 고유한 placeholder로 바꾸고 이 placeholder의 디코딩한다.
아래의 예시 문장을 보자.
Thank you for inviting me to your party last week."이 문장에서 길이가 다른 span을 선택해야 하는데 두 개의 단어로 구성된 "for inviting"과 하나의 단어인 "last"를 선택하고 placeholder로 바꾸자.

이때 placeholder는 고유해야 하므로 "for inviting"은 <X>로, "last"는 <Y>로 바꾸자.
Thank you <X> me to your party <Y> week.그리고 디코더에서 이 placeholder가 원래 어떤 span인지 예측하면 된다.
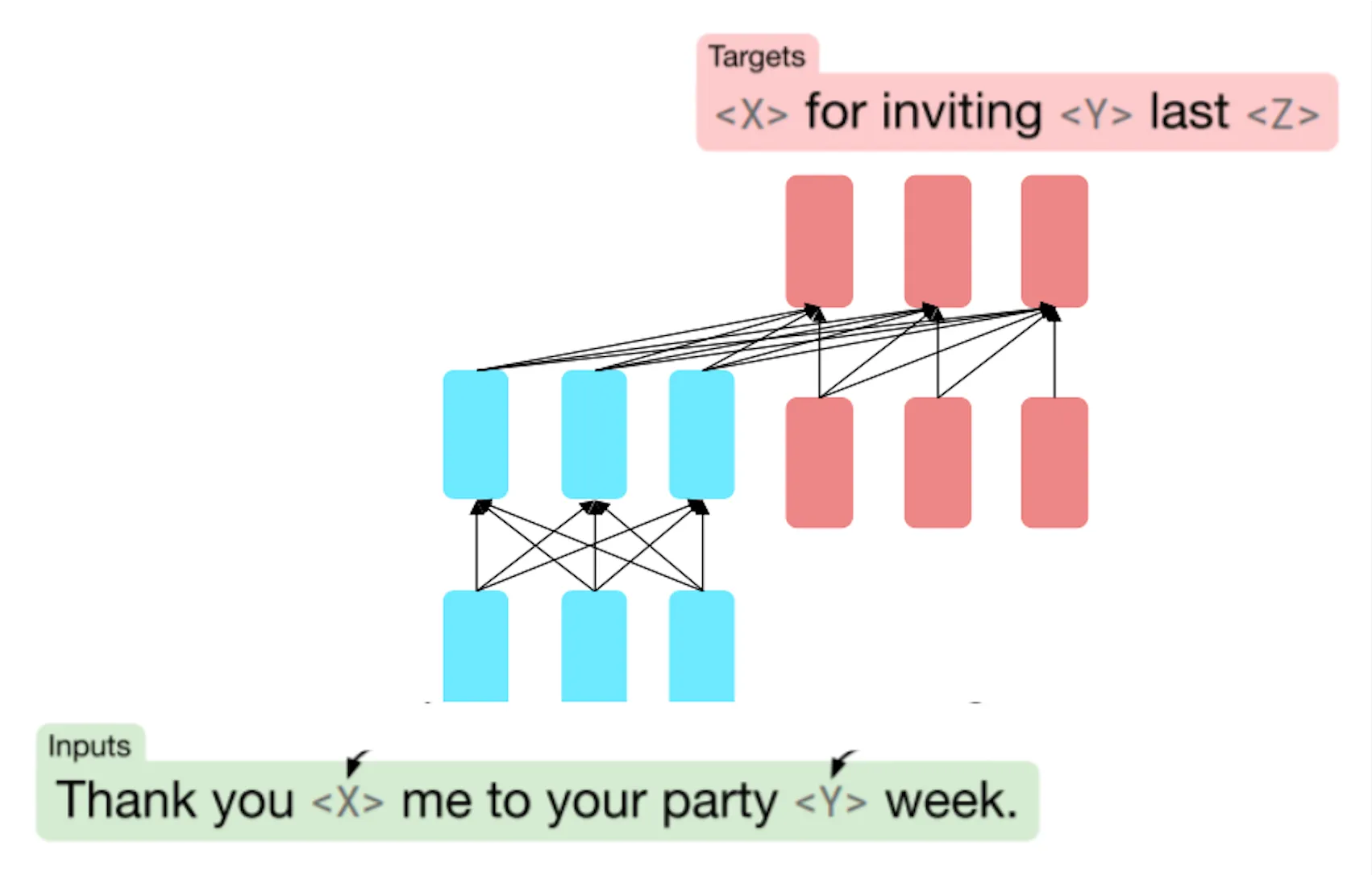
이 때 span을 placeholder로 변환하는 과정은 텍스트 전처리 단계에서 구현된다.
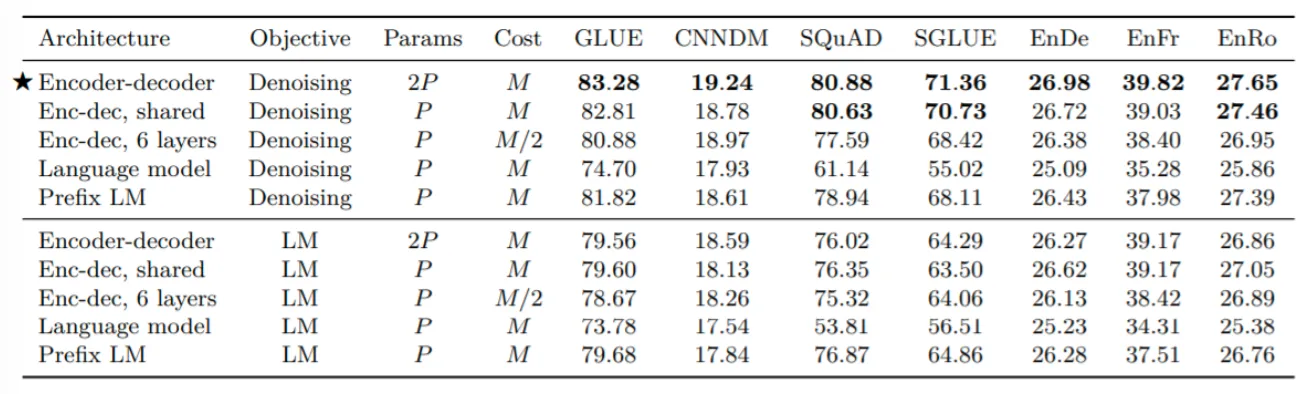
Raffel et al.(2018)은 인코더-디코더가 디코더보다 특정 작업에 더 효과적이며 span corruption이 language modeling보다 더 효과적임을 발견했다.
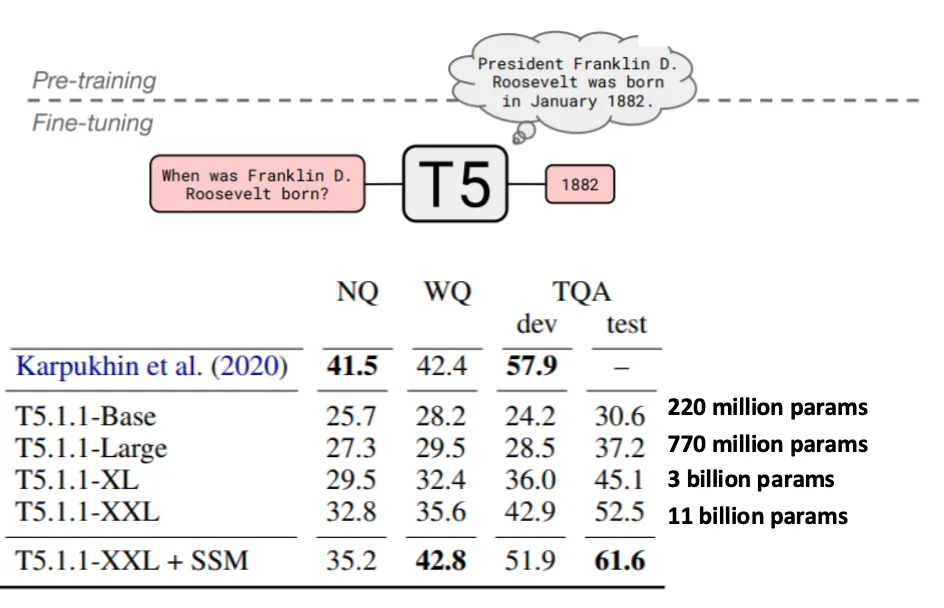
T5는 다양한 질문에 답하도록 finetuning이 가능하며 파라미터에서 지식을 추출할 수 있다는 특성을 가진다.
3. Decoders
디코더는 미래의 단어를 학습할 수 없으며 생성 작업에 뛰어나다.
가장 큰 pretrained model은 모두 디코더 기반 모델이다.
Pretraining decoders
pretraining decoder 기반의 언어 모델을 사용할 경우 디코더가 을 모델링하도록 학습되었다는 사실을 무시해도 된다.
다시 말해 하위 태스크를 위해 finetuning을 할 때 디코더가 pretraining하는 방식이 아닌 다른 방식을 사용해도 된다는 뜻이다.
예를 들어 pretraining의 마지막 은닉 상태에 대해 분류기를 학습시켜 finetuning할 수 있다.
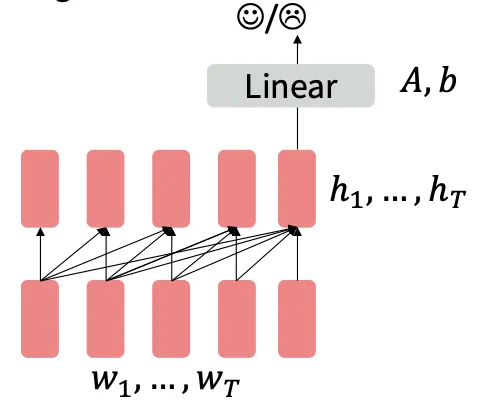
단 위 그림처럼 분류로 finetuning을 하고자 할 때 Linear layer 자체는 pretrainig되지 않았으니 이 레이어는 처음부터 학습해야 한다.
Pretraining decoder를 식으로 간단히 표현하면 아래와 같다.
Finetuning시 와 는 무작위로 초기화되고 하위 태스크에 의해 다시 업데이트된다.
간단히 말하자면 분류기 같은 결이 다른 태스크로 finetuning하므로 pretraining 모델의 은닉 상태 는 사용하되 태스크에 맞게 학습되도록 가중치 , 초기화 후 다시 학습된다는 말이다.
기울기는 전체 네트워크를 통해 역전파된다.
디코더를 언어 모델로서 pretraining하는 것, 그리고 이 디코더를 제너레이터로 사용하여 을 finetuning하는 것은 자연스러운 일이다.
태스크의 출력이 시퀀스이고 이 시퀀스 내의 단어가 pretraining에 사용된 단어들이라면 language modeling head를 그대로 쓸 수 있어서 유용하다.
예를 들어 Dialogue나 summarization같은 태스크가 있다.
이 경우 식은 아래와 같다.
, 는 사전학습된 가중치이다.
간단히 말하자면 대화, 요약같은 결이 비슷한 태스크로 finetuning을 하므로 pretraining 모델의 은닉 상태 뿐만 아니라 가중치 , 도 그대로 사용할 수 있다는 밀이다.
4. Very large models and in-context learning
1. Generative Pretrained Transformer (GPT)
아주 큰 언어 모델은 파라미터 업데이트가 없어도 단순히 예시 몇 개로부터 일종의 학습을 수행하는 것으로 보인다.
이처럼 입력 프롬프트에 예시를 주면 모델이 그 예시 패턴을 따라 새로운 입력에 답을 잘 하는 현상을 in-context learning이라고 한다.
GPT-3가 in-context learning의 전형적인 예다.

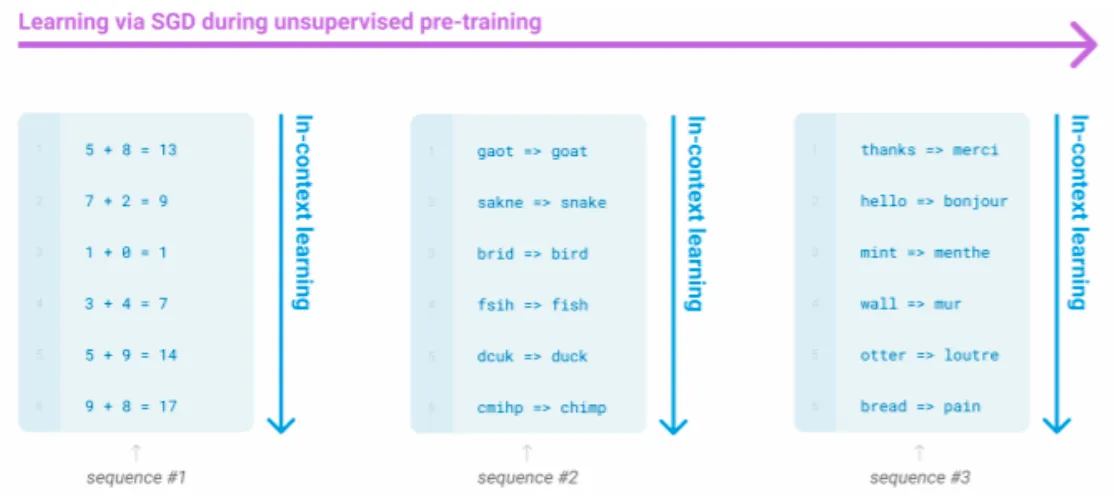
2. How do LLMs generalize?
In-context learning은 주목할 만하다.
하지만 이게 학습을 하는 것일까?
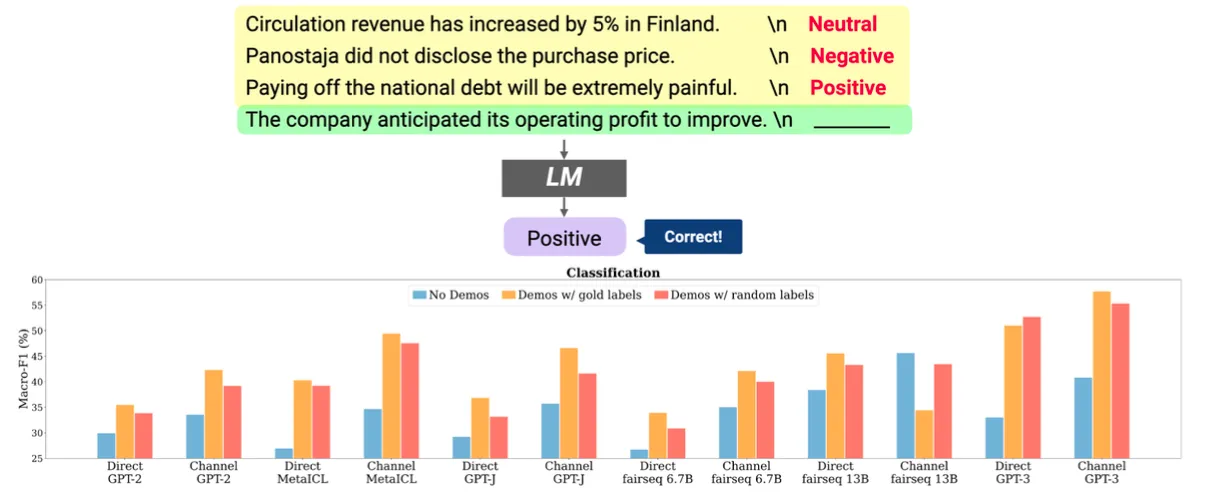
무작위 레이블을 사용해도 모델은 학습 문제에서 좋은 성능을 낼 수 있다.
전통적인 의미의 학습 관점에서는 파라미터를 업데이트하는 건 아니니까 학습이라 할 순 없겠지만 예시를 보고 규칙을 추론하여 일반화한 뒤 새로운 입력에 이를 적용한다는 점에서는 학습이라고 볼 여지도 있다.
그러니 이게 학습인지 아닌지 명확한 답은 없다.
3. Scaling Efficiency: how do we best use our compute
GPT-3는 1759억개의 파라미터를 사용했고 3000억개의 텍스트 토큰을 사용하여 학습되었다.
대규모 트랜스포머의 학습 비용은 대략 파라미터 * 토큰 수에 비례한다.
그렇다면 OpenAI가 최적의 모델을 구축하는데 필요한 적절한 파라미터-토큰 데이터를 확보했을까? 아니다.
오히려 이 GPT-3보다 가벼운 모델이 더 좋은 성능을 달성한 경우가 있다.
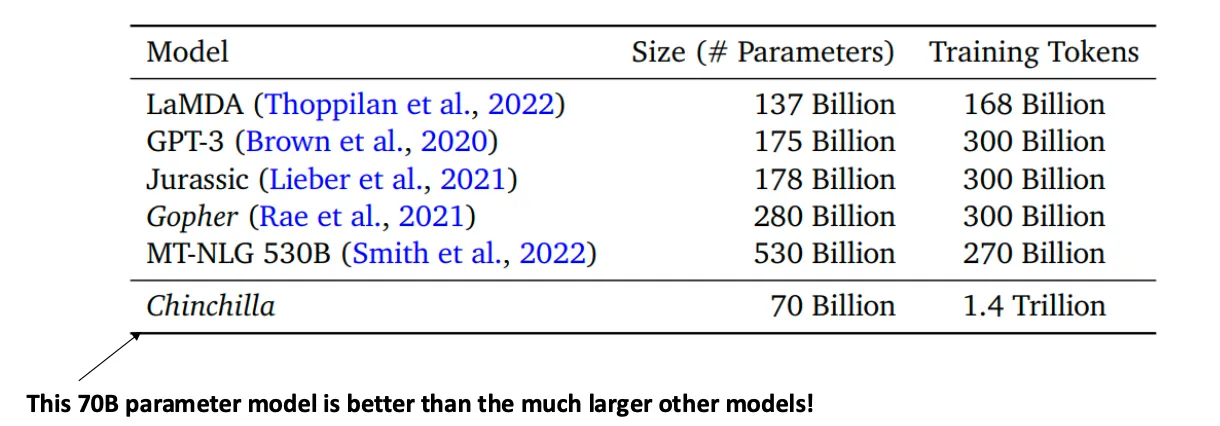
Chinchilla는 700억개의 파라미터를 사용했음에도 더 큰 모델보다도 성능이 뛰어나다.
