
일반적인 language modeling(다음 단어 예측)에서 chatGPT처럼 질문에 답변을 하도록 하려면 어떻게 해야 할까?
1. Instruction fine-tuning
Language modeling 그 자체가 사용자를 돕는 것은 아니다.
6살 아이에게 달 착륙을 설명해보라고 입력했을 때 GPT-3의 답변을 보자.

이번엔 인간의 답변을 보자.

인간의 답변이 훨씬 뛰어나다.
1) Instruction finetuning
Instruction finetuning(IFT)은 다양한 태스크에 대해 (명령, 출력) 쌍의 예시 데이터를 수집하여 language model(LM)을 finetuning한다는 개념이다.
학습 후 평가 때는 처음 접하는 태스크를 활용한다.
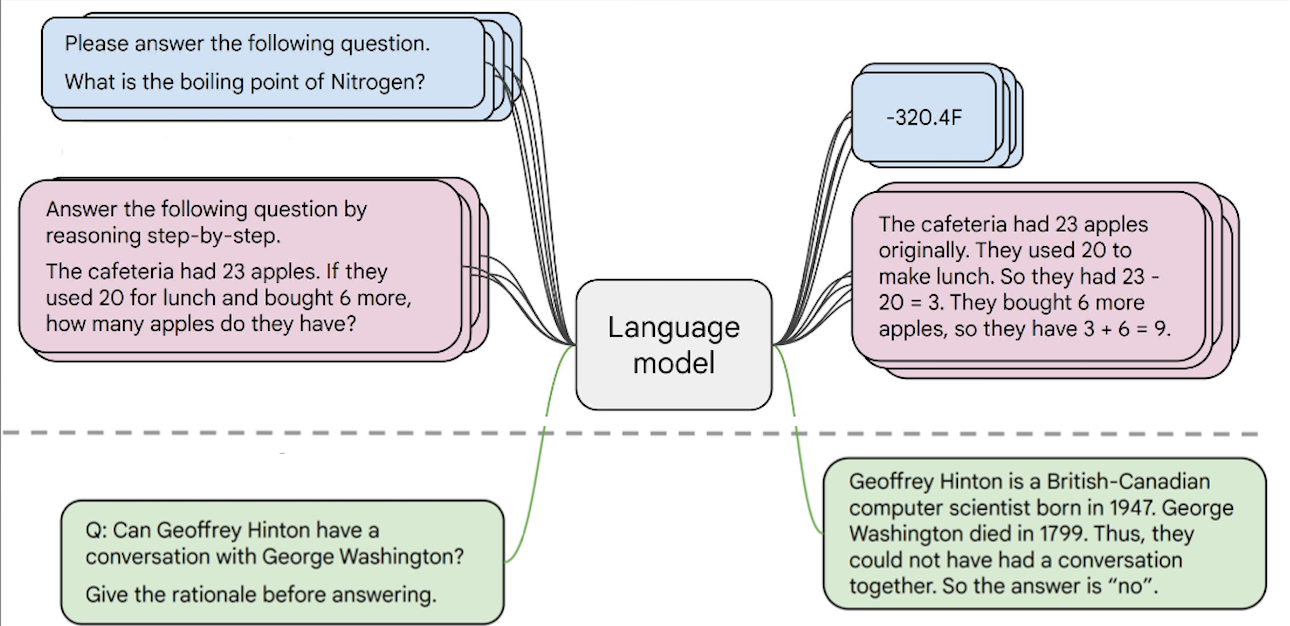
IFT에서는 데이터 크기와 모델의 규모가 핵심이다.
데이터 크기와 모델 규모가 클수록 IFT의 효과는 극대화된다.
예를 들어 GPT-3같은 초대형 모델이 IFT를 거치면 훨씬 더 다양한 태스크를 zero-shot 또는 few-shot으로 처리할 수 있게 된다.
Super-NaturalInstruction 데이터셋은 IFT에 자주 쓰이는 대표적인 데이터셋 중 하나로 1600개 이상의 태스크와 300만개 이상의 예시 데이터를 포함한다.
이 데이터셋의 목적은 모델이 단순히 언어 패턴을 학습하는 것을 넘어 다양한 태스크에 대한 지시를 이해하고 따르는 방식을 학습하도록 하는 것이다.
IFT를 거친 모델은 단순히 언어 패턴을 잘 맞추는가를 넘어 사람의 지시를 이해하고 지식 기반의 문제를 해결하는 능력을 가져야 할 것이다.
따라서 모델을 평가할 때도 실제 태스크 수행 능력을 평가해야 한다.
이때 MMLU라는 벤치마크를 사용한다.
MMLU는 57개의 지식 집약적인 태스크로 구성된 대규모 평가 세트로써 모델의 지시를 따르는 능력과 실제 문제 해결 능력을 제대로 검증할 수 있는 평가 도구이다.
이 그림을 한번 보자.
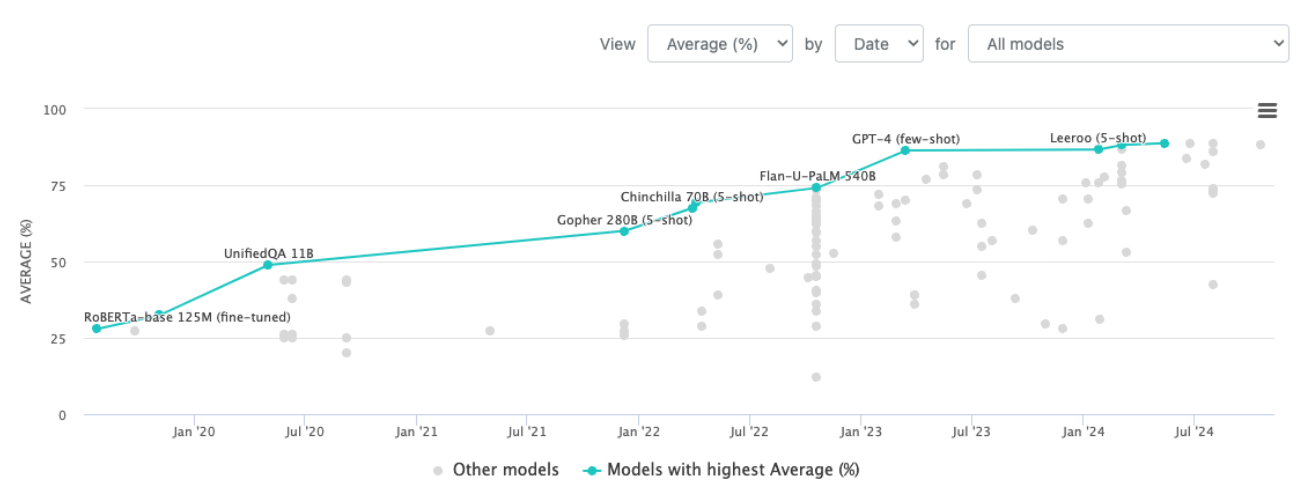
MMLU에 대한 모델의 성능을 표현한 그래프이다.
짧은 기간동안 모델의 성능이 빠르게 발전하고 있는 모습을 확인할 수 있다.
따라서 MMLU를 뛰어 넘는 새로운 벤치마크가 필요했다.
BIG-Bench (Beyond the Imitation Game Benchmark) 2022년 공개되었다.
언어의 완성도(perplexity) 평가를 넘어 추론, 지식, 창의력 등을 기준으로 언어 모델이 사람 수준에 얼마나 가까운지 평가하기 위해 만들어졌다.
204개의 다양하고 방대한 태스크와 함께 57개의 언어를 지원하여 다국어 성능을 측정할 수도 있다.
태스크 유형으로는 지식 기반 QA, 산수/수학 문제, 추론, 윤리적 딜레마 판단, 창의적 글쓰기, 추상적 패턴 인식 등이 있다.
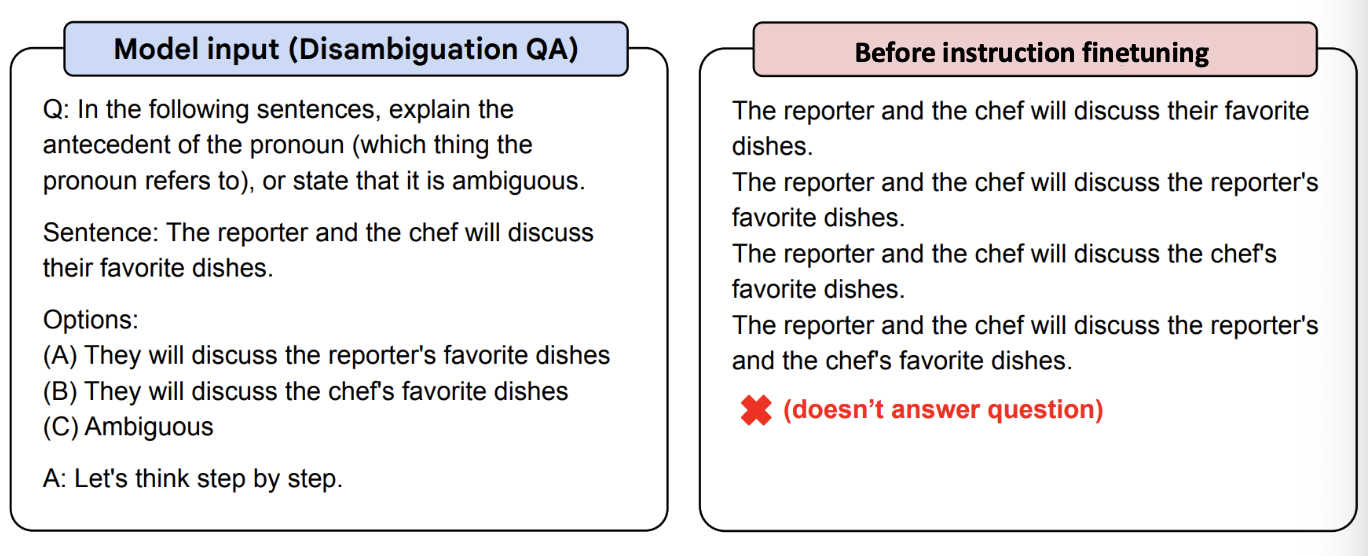
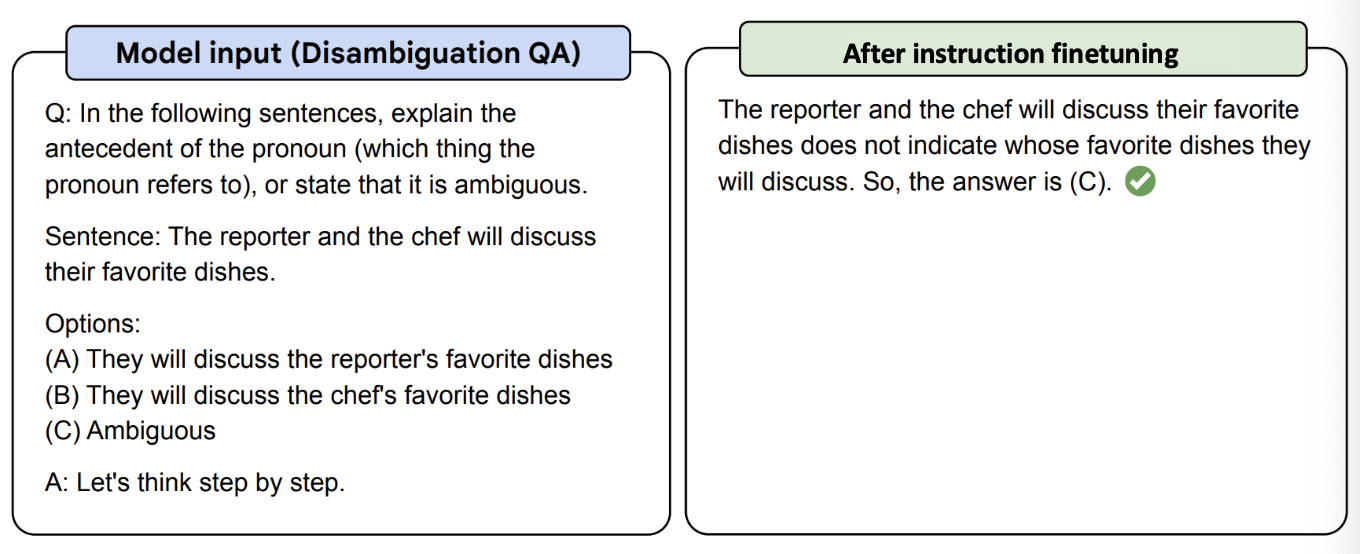
2. Reinforcement learning from human preferences(RLHF)
1) Limitation of instruction finetuning
IF의 명백한 한계점은 태스크에 대한 정답 데이터를 모으는 비용이 매우 크다는 것이다.
이 외의 한계점은 아래와 같다.
-
Open-ended creative generation은 명확한 답이 존재하지 않는다.
Open-ended creative generation은 답이 정해져 있지 않은 생성을 뜻한다.
예를 들어 이야기나 노래 가사 생성에는 명확한 답이 존재하지 않는다.
-
Language modeling은 모든 오답 토큰에 같은 페널티를 부여한다.
Language modeling은 오답 토큰에 페널티를 부여하는데 이때 모든 오답 토큰이 같은 페널티를 받는다.
하지만 실제로는 오류에도 심각한 오류가 있고 덜 심각한 오류가 있다.
예를 들어 "The capital of France is London"은 심각한 사실 오류지만
"The capital of France is Pariss"는 단순히 철자 오류이므로 덜 심각하다.하지만 이 두 문장에 대해 똑같은 페널티를 부여한다.
그리고 IFT를 거쳐도 언어 모델의 목표와 인간이 선호하는 답변은 일치하지 않을 수 있다.
2) Optimizing for human preferences
LM을 요약 태스크로 학습시키고 있다고 생각해보자.
LM의 각 샘플 를 요약한 것에 대해 인간이 보상을 한다고 상상해보자.
은 샘플 의 요약에 대한 보상 점수이다.
요약을 잘 할수록 는 큰 값을 가질 것이다.

맨 왼쪽에 있는 글을 요약한 과 중 요약을 잘한 의 보상 점수 가 요약이 잘 되지 않은 보다 더 크다.
이제 LM의 샘플에 대한 기대 보상값을 최대화해보자
RLHF의 파이프라인은 아래와 같다.
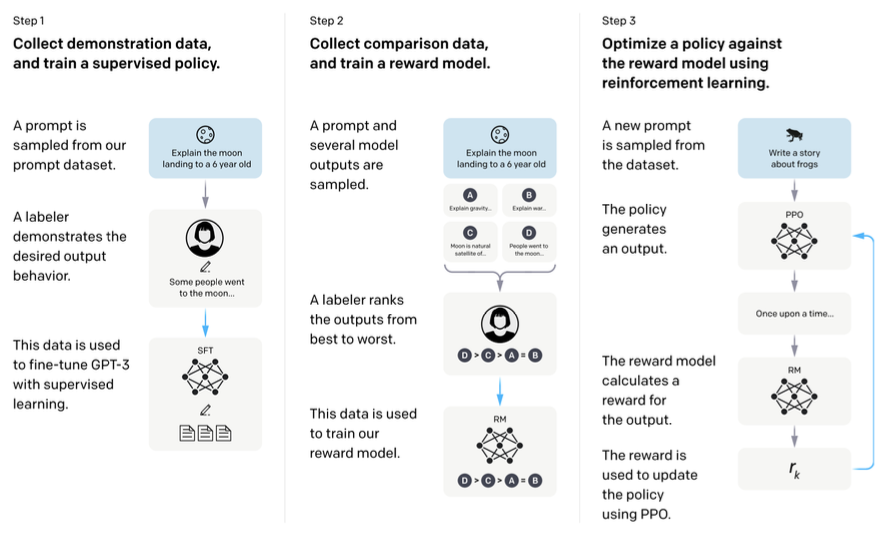
Step 1에서 IFT를, Step 2와 3에서는 보상을 최대화하면 된다.
그러면 어떻게 보상을 최대화할 수 있을까? Reinforcement learning를 사용한다.
는 보상을 최대화하기 위해 LM의 파라미터 를 바꾸는 수식이다.
여기서는 gradient ascent(경사상승법)을 사용한다.
그 전에! 파라미터 업데이트를 위한 경사하강법은 아래와 같았다.
경사하강법에서는 기울기가 0이 되는 지점을 찾기 위해 하강을 했다면 경사상승법에서는 기울기가 0이 되는 지점을 찾기 위해 상승을 하는 방식이다.
다시 말해 극대점을 찾는 과정이라고 생각하면 된다.
경사상승법은 아래와 같다.
변화량 은 이다.
확률 분포에서 한 토큰씩 뽑아 하나의 문장을 만든 후 이 문장에 대한 보상을 확인하고 보상값에 따라 파라미터를 업데이트하는 방식이다.
수식을 차례대로 살펴보자.
-
는 현재 LM의 파라미터를 기반으로 계산된 확률 분포이다.
예를 들어 "오늘은"이라는 단어 다음에 올 단어 확률 분포가 다음과 같다고 가정해보자.
이때 각 확률에 따라 샘플링한다.
60% 확률로 "날씨"가 선택될 수도, 30% 확률로 "기분"이 선택될 수도, 10% 확률로 "밥"이 선택될 수도 있다.
이렇게 샘플링된 단어들을 이어붙여 한 문장 를 만든다.
-
문장 를 보상 함수 에 넣어 보상을 계산한다.
-
파라미터 업데이트
파라미터 를 업데이트하기 위해선 의 변화량을 계산해야 한다.
보상 함수 은 사람이 평가하거나 reward model을 이용한다.
이때 보상은 보통 미분이 불가하다(non-differentiable).
다시 말해 를 직접 계산할 수 없다.
이때 policy gradient를 사용하여 업데이트를 가능하게 할 수 있다.
그럼 policy gradient가 무엇인지 아주 간략히 살펴보자.
3) Policy gradient
는 직접 계산할 수 없으므로 약간의 편법을 이용한다.
확률 분포 자체의 기울기를 계산하고 여기에 보상을 곱하여 보상이 높은 샘플은 확률을 높이고 낮은 샘플은 확률을 낮추는 방식으로 파라미터를 업데이트한다.
은 기대값이므로 위 식은 보상 함수 의 기대값을 의미한다.
내의 와 연관있는 것은 뿐이다.
이제 log-derivative trick을 사용한다.
Chain rule에 의해 이다.
따라서 이다.
이를 대입하면
이를 에 대한 기대값으로 표현하면 아래와 같다.
몬테카를로 샘플링을 이용하여 식을 아래와 같이 정리할 수 있다.
이것을 강화학습(reinforcement learning)이라고 한다.
어떤 행동이 좋다고 판단되면 이 행동이 다시 일어날 확률을 높임으로써 좋은 행동을 강화한다.
따라서 파라미터 업데이트식은 아래와 같다.
보상 이 크면 를 최대화하도록 파라미터를 업데이트하고 반대로 보상이 낮으면 를 최소화하도록 업데이트한다.
4) How do we model human preferences?
지금까지 미분 불가한 보상 함수 에 대해 기대 보상을 최대화하는 방식으로 언어 모델을 학습할 수 있음을 살펴봤다.
하지만 보상 함수에는 몇 가지 문제점이 있다.
-
인간이 보상을 반복 계산하는 것은 비용이 크다.

인간의 선호를 직접 물어보는 대신 인간의 선호를 모델링하여 이를 해결할 수 있다.
레이블이 있는 데이터를 사용하여 인간의 선호를 예측하는 모델 를 학습시키고 이 모델을 최적화하는 방식이다.
-
인간의 판단은 노이즈가 있고 형편 없다.

인간이 점수를 매기는 방법 대신 더 신뢰있는 방법인 쌍비교를 수행한다.
응답을 비교해서 무엇이 더 나은지 평가하는 것이다.

5) RLHF
RLHF는 Reinforcement Learning from Human Preferences, 즉 인간의 선호에 따른 강화학습이다.
RLHF 이해에 필요한 몇 가지 요소를 살펴보자.
-
: Pretrained LM (IFT가 수행되거나 되지 않거나)
-
: LM의 출력에 대해 스칼라 보상을 출력하는 보상 모델이며 인간의 쌍비교 데이터셋으로 학습됨
-
LM의 파라미터 최적화 방법은 보상 함수에 의함
이제 RLHF를 해보자.
-
원본 모델 를 복사하여 을 만들고 파라미터 도 그대로 가져온다.
원본 모델의 파라미터를 바꾸면 pretraining 모델을 잃게 되므로 모델의 복사본을 만든다.
-
복사 모델 을 강화학습으로 파라미터 업데이트
복사 모델이 생성한 문장 를 보상 모델 에 넣어 평가한다.
는 반복을 통해 문장을 여러번 생성하고 생성된 문장이 평균적으로 얼마나 좋은지 판단한다는 의미다.
-
보상 최적화
최적화 식:
여기서 는 KL 페널티(Kullback-Leibler)
그러니까 최적화 식은 보상 점수에서 페널티를 뺀 것
RLHF에서는 모델이 보상 를 최대화하도록 학습한다.
이때 보상만 좇으면 모델이 원래의 언어적 유창성을 잃거나 사실에서 벗어난 이상한 출력을 할 가능성이 존재한다.
원래의 언어적 유창성과 사실성에서 크게 벗어나지 않도록 하는 안전 장치 필요한데 그 장치가 페널티다.
-
KL 페널티
학습 모델 이 원본 모델 의 분포에서 너무 벗어나면 안된다.
따라서 두 확률 분포의 차이를 벌칙으로 두자.
이때 확률 분포 간 차이를 재는 방법이 바로 KL이다.
식을 다시 정리하면
첫 항 는 보상 모델이 주는 점수
둘째항 은 원래의 LM과 너무 달라지는 것을 억제하는 페널티
는 둘 사이의 균형을 조절하는 하이퍼파라미터
정리하면 보상 모델의 점수를 높이지만 원래 LM의 분포와의 차이(KL)가 커지면 벌점을 부여하여 최적화 목표 함수 의 출력을 조절한다.
Fraction preferred to ref를 지표로 각 모델이 모델 크기에 따라 어떤 값을 갖는지 살펴보자.
Fraction preferred to ref는 기준 모델과 참조 모델의 응답 중 기준 모델의 응답이 더 선호된 비율을 의미한다.
기준 모델은 (1) pretraining 모델, (2) pretraining + IFT 모델, (3) RLHF 모델로 총 3개이다.
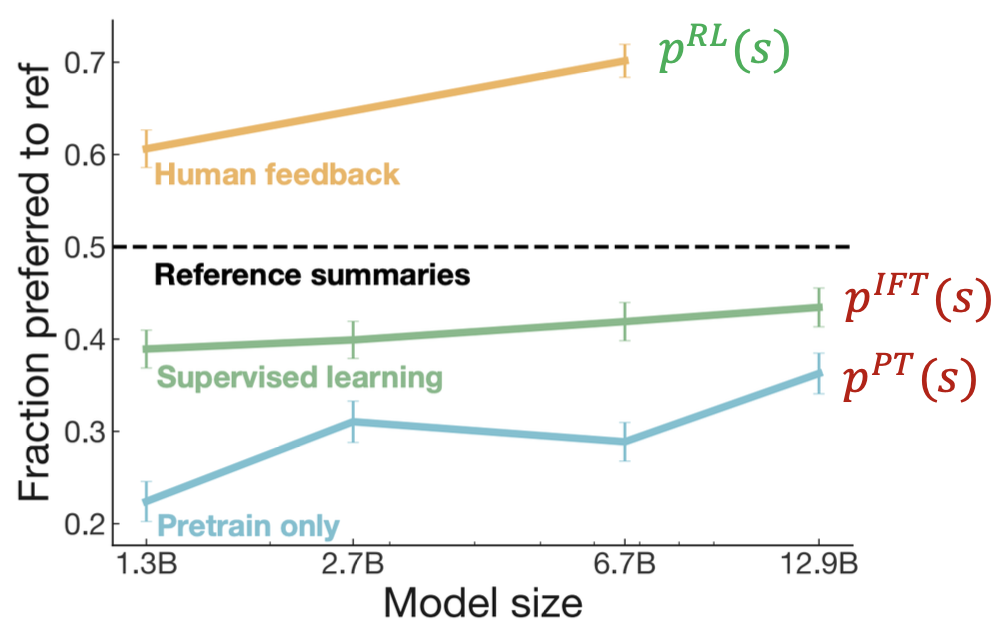
Pretraining 모델과 IFT 모델은 reference summaries(0.5)보다 낮은 비율을 보인다.
참조 모델이 기준 모델인 이 두 개의 모델보다 더 낫다는 것을 의미한다.
하지만 RLHF 모델은 0.5보다 높은데 이는 RLHF 모델의 응답이 참조 모델의 응답보다 더 자주 선택되었다는 것을 의미한다.
이를 통해 pretraining + IFT에 RLHF까지 이용하면 모델이 인간이 선호하는 응답을 더 잘 생성할 수 있음을 알 수 있다.
3. InstructionGPT and ChatGPT
1) InstructGPT
InstructGPT는 다양한 태스크가 포함된 IFT 데이터를 레이블러가 만들고 이 데이터로 IFT를 수행한다.
레이블러가 IFT 데이터를 만들 때는 아래의 세 가지 방식을 차용했다.
-
Plain
레이블러에게 무작위의 태스크를 만들도록 요청하되 태스크가 다양성을 갖도록 하여 편향을 방지한다.
-
Few-shot
레이블러에게 하나의 instruction을 만들고 그 instruction에 맞는 query/response 쌍을 여러 개 만들도록 요청한다.
-
User-based
OpenAI API 대기자 명단의 사람들이 적은 실제 사용 사례(use-cases)에 상응하는 프롬프트를 만들도록 레이블러에게 요청한다.
예를 들면
-
Use-case가 브레인스토밍일 때 프롬프트: "내 직업에 대한 열망을 되찾는 방법 5가지를 나열하라."
-
Use-case가 생성일 때 프롬프트: "곰 한마리가 해변으로 가서 물개와 친구가 되고 집으로 되돌아 오는 내용의 짧은 글을 작성하시오."
-
InstructGPT의 답변은 GPT-3보다 더 좋은, 즉 인간이 선호하는 답변을 보여준다.


참고로 instructGPT도 RLHF 모델이다.
2) ChatGPT
ChatGPT는 instructGPT와 동일한 RLHF를 사용하되 데이터 수집 방식에 약간의 차이를 뒀다.
Human AI Trainer가 User와 AI assistant의 역할을 모두 맡아 대화를 작성했다.
다시 말해 사용자의 쿼리와 그 쿼리에 상응하는 답변 모두 인간이 작성했다.
AI Trainer가 답변을 작성할 때는 모델이 답변을 제안하여 참고할 수 있도록 했다.
기존 instructGPT 데이터셋도 대화 형식으로 변환한 뒤 AI Trainer가 만든 데이터와 섞었다.
ChatGPT를 간단히 한 문장으로 표현하면 언어 모델을 대화에 최적화한 것이라고 할 수 있다.
강화학습을 위한 보상 모델을 구축하기 위해선 모델이 생성한 두 개 이상의 응답에 대해 품질을 기준으로 순위를 매긴 비교 데이터가 필요했다.
이 데이터를 수집하기 위해선 먼저 AI Trainer와 챗봇이 나눈 대화 중에서 챗봇, 즉 모델이 만든 메시지를 무작위로 선택한다.
그리고 이 메시지와 비슷한 맥락을 가진 다른 응답을 몇 개 샘플링한다.
비슷한 맥락의 여러 답변에 대해 AI Trainer가 품질을 기준으로 순위를 매긴다.
이 데이터로 보상 모델을 학습하면 답변이 인간의 선호에 적합한지에 대한 스칼라 점수를 출력할 수 있다.
보상 모델을 만들었으니 ChatGPT가 보상을 최대화하도록 finetuning을 수행한다.
보상을 최대화할 때는 Proximal Policy Optimization(PPO)를 사용하는데 PPO는 앞서 살펴본 policy gradient의 변형이다.
PPO를 간단히 살펴보자.
앞서 살펴본 RLHF를 간략히 설명하자면 LM의 확률 분포에 따라 토큰을 뽑아서 한 문장을 만들고
문장을 보상 모델에 넣어 좋은 문장인지 점수를 출력한 후 이 점수에 따라 파라미터를 업데이트하는 방식이었다.
단편적으로 보면 모델은 좋은 보상이 최대가 되는 지점, 즉 기울기가 0인 극대점을 찾아 파라미터를 업데이트한다.
보상이 최대가 되는 지점을 찾기 위해 policy gradient를 사용했었다.
하지만 policy gradient는 이전 정책과 새로운 정책 간 차이가 커서 스텝이 커지는 문제가 발생할 수 있다.
이전 정책은 현재 파라미터 기반의 확률 분포를, 새로운 정책은 극대점을 찾기 위한 임의의 확률 분포를 뜻한다.
스텝을 계산할 때 새로운 정책과 이전 정책 간 비율인 확률비를 사용하는데 새로운 정책과 이전 정책 간 차이가 클수록 확률비가 커지므로 스텝 또한 커진다.
스텝이 커지면 극대점을 찾지 못하고 건너 뛰는 상황이 발생하여 성능이 엉망이거나 학습이 불안정할 수 있다.
그럼 스텝이 커지는 것을 어떻게 방지할 수 있을까?
확률비가 너무 클 때 이를 일정 범위 내로 잘라낸다면 스텝이 커지는 것을 방지할 수 있을 것이다.
이를 확률비를 clipping한다고 표현한다.
이것이 PPO이다.
PPO를 이용하면 확률비를 clip으로 제한하여 스텝이 커지는 것을 방지할 수 있으므로 안정적인 학습이 가능하다.
모두가 알다시피 ChatGPT의 대화 성능은 놀라울 정도였다.

3) Comparisons
아래 그림을 보자.
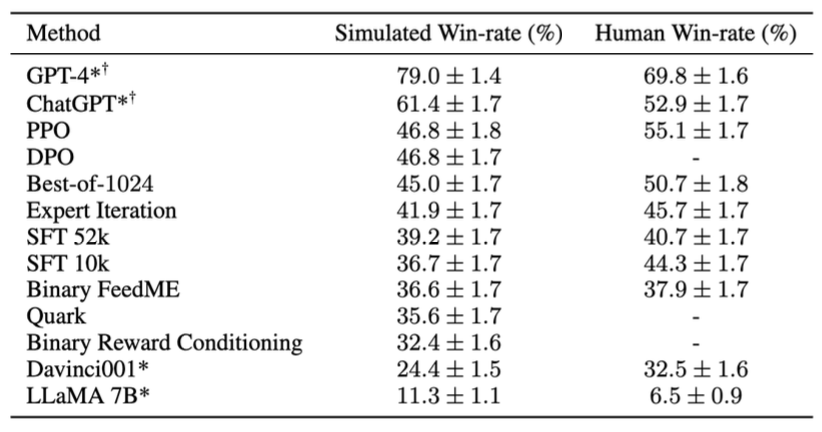
Simulated Win-rate는 시뮬레이션 기반 평가로 method 모델의 응답과 참조 모델의 응답을 평가 모델이 비교했을 때 method 모델이 더 좋은 경우에 대한 비율의 의미한다.
Human Win-rate는 인간 기반 평가로 method 모델의 응답과 참조 모델의 응답을 인간이 비교했을 때 method 모델의 응답이 더 좋은 경우에 대한 비율을 의미한다.
앞서 살펴본 PPO도 인간의 피드백 기준 약 55.1%이므로 RLHF 알고리즘으로써 효과가 있음을 확인할 수 있다.
RLHF 없이 IFT만 수행한 SFT 류의 모델은 RLHF 모델보다 응답이 좋지 못한 것을 확인할 수 있다.
IFT도 수행하지 않은 Davinci001이나 LLaMA 7B 모델은 응답 성능이 좋지 못한 것을 확인할 수 있다.
최근에는 GPT-4의 피드백을 인간 대용으로 사용하여 RLHF 알고리즘을 평가한다.
인간의 피드백은 비용이 큰데 속도는 느리면서 노이즈도 있기 때문이다.
RLHF는 응답의 스타일까지 변화시킨다.
아래 그림을 보자.

단순히 IFT만 수행한 Alpaca 모델의 응답은 짧고 간결한 문장이지만 Alpaca에 PPO를 수행한 모델은 보다 구체적인 응답을 보인다.
따라서 RLHF는 모델이 더 구체적이고 깔끔한 형식의 응답을 하도록 만들 수 있다.
4. Limitation of RL and reward modeling
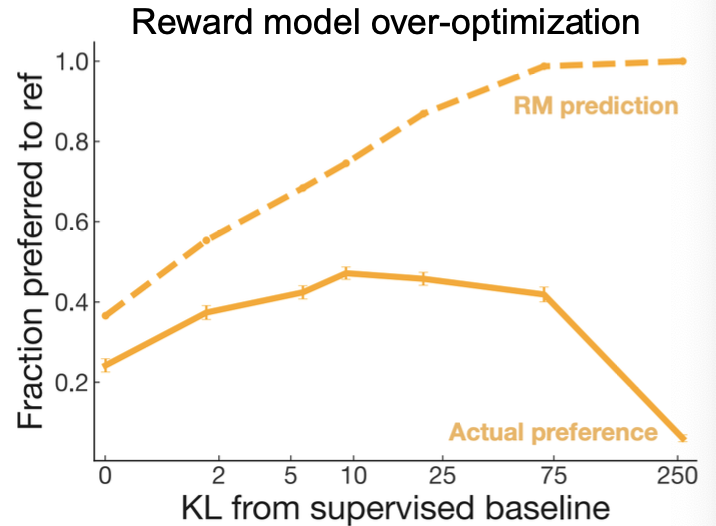
인간의 선호는 믿을 수 없다.
강화학습에는 reward hacking 문제가 흔한데 이는 보상 함수의 허점으로 인해 발생한다.
모델이 보상을 최대화하도록 학습하는 이유는 의도된 목표를 달성하기 위함인데
모델이 이 목표를 달성하는 대신 단순히 보상 점수만 높이는 행동을 학습하는 것이다.
챗봇이 사실 여부 상관 없이 마치 도움이 되는 듯 보이면서 사실인 것 같은
그런 그럴싸한 응답을 생성하여 보상을 받는 것이다.
이 때문에 모델이 진실과 할루시네이션이 섞인 응답을 생성하게 된다.
그리고 인간이 아닌 인간 선호도 모델은 더더욱 믿을 수 없다.
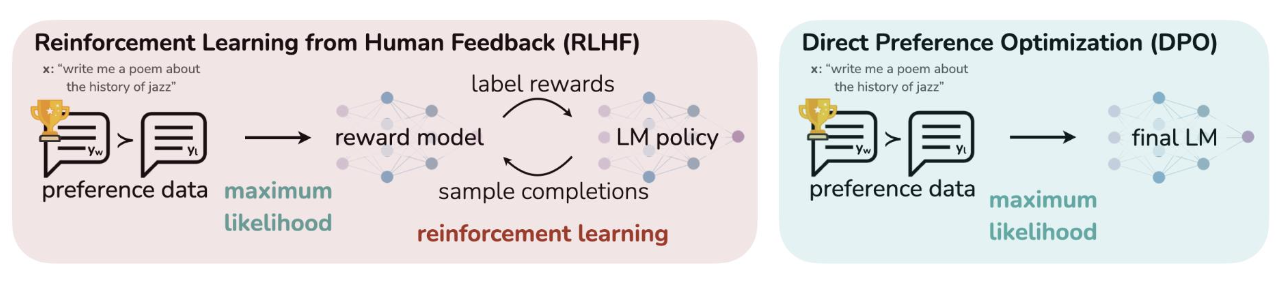
5. Introducing Direct Preference Optimization(DPO)
RLHF는 보통 3단계 파이프라인으로 구성된다.
Instruction finetuning reward model 학습 RL로 최적화(예: PPO)
여기서 RL 최적화는 복잡하면서 reward shaping과 하이퍼라라미터 조정도 어렵다는 문제가 있다.
DPO는 RL을 거치지 않고 인간의 선호 데이터로 직접 LM을 최적화하는 방식이다.
DPO에 대한 식을 살펴보자.
식을 하나하나 다 풀어서 살펴보고 싶지만 그러기엔 내 지식이 너무 부족하다.
그래서 간단히만 살펴보자.
DPO는 RL을 거치지 않는다고 했으니 RLHF에서 RL을 지워보자.
앞서 아래와 같은 수식을 통해 보상을 최대화했었다.
Reward model의 출력한 보상에서 KL 페널티를 빼서 원본 모델(pretrained model)의 분포에서 크게 벗어나지 않도록 하는 식이었다.
Closed form soultion에 따라 최적 분포는 아래와 같다.
여기서 는 정규화 상수이다.
이 식을 로그 변환하여 보상 함수에 대한 식으로 정리하자.
이제 이 식을 LM의 분포에 적용하면 아래와 같이 표현할 수 있다.
DPO는 인간의 선호 데이터로 직접 LM을 최적화하는 방식이라고 했다.
인간의 선호 데이터는 보통 쌍(pairwise)비교 데이터로 주어지는 것을 살펴봤었다.
입력 에 대해 사람이 더 선호한 응답을 (winning), 덜 선호한 응답을 (losing)으로 데이터를 구성하자.
그리고 인간의 선택을 모델링하기 위해 Bradley-Terry 모델을 쓰는데 아래와 같다.
선호한 응답에서 덜 선호한 응답을 빼는 방식이다.
최종 DPO 손실을 정의하면 아래와 같다.
여기서 가 선호한 응답의 보상, 가 덜 선호한 응답의 보상이다.
인간이 선호한 응답 의 보상이 보다 크도록 만드는 방향으로 학습된다.
DPO는 기존의 RLHF 방법론보다 더 좋은 성능을 보인다는 연구 결과가 많다.
복잡한 강화학습 대신 쌍비교 데이터를 이용하여 단순한 weighted MLE(Maximum Likelihood Estimation)을 사용할 수 있다.
요약 태스크인 TL;DR에서 인간이 작성한 요약과 모델이 작성한 요약을 비교했을 때 어떤 요약이 더 선호되는 지를 GPT-4로 판별한 결과 DPO로 작성된 요약이 PPO(RLHF)로 작성된 요약보다 더 높은 win-rate를 달성했다.
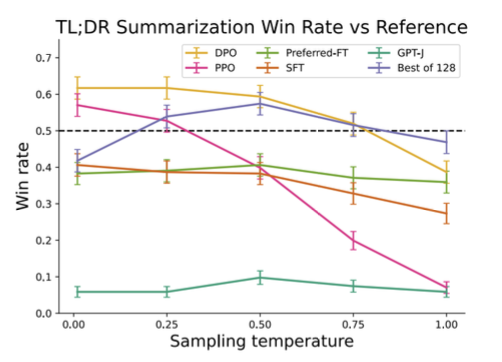
따라서 현재 대부분의 오픈소스 LLM은 DPO를 주로 사용한다.
