
1. What's QA? Why do we care?
1) What is question answering?
QA의 목표는 "인간이 자연어로 던진 질문(Q)에 자동으로 답변(A)하는 시스템을 구축하는 것"이다.
QA를 세가지로 분류해보자.
-
정보 출처: 텍스트 구문, 전체 웹 문서, 지식 베이스, 표, 이미지 등
-
질문 유형: 사실 vs 비사실, 오픈 도메인 vs 클로즈드 도메인, 단일 vs 합성
-
답변 유형: 짧은 텍스트 부분, 문단, 리스트, 예/아니오
QA는 검색 엔진, 챗봇 등 연구를 넘어 산업 전반(구글 검색, gpt 등)에 널리 활용되고 있다.
2023년부터는 전문가 수준의 질문에 답변하는 연구가 진행되고 있다.
전문가 수준의 QA 벤치마크의 예로는 GPQA가 (Graduate-level Physics, Chemistry, Biology, and Machine Learning Question Answering)있다.
GPQA은 2023년 OpenAI, 스탠포드 등에서 제안한 전문 지식 평가용 QA 벤치마크이다.
2) Closed-book QA
모델이 외부 지식에 접근하지 않고 파라미터에 저장된 지식만으로 답변하는 방식이며 parametric QA라고도 한다.
closed-book QA는 단순히 다음 단어를 예측하는 방식으로 수행된다.
예를 들어 "Stanford University is located in ____?"의 경우 모델이 외부 검색 없이 파라미터 지식만으로도 빈칸에 "Stanford, Califonia"라고 답할 수 있다.
LLM은 오픈 도메인 QA도 잘 수행할 수 있다.
초기에 T5같은 모델을 통해 언어 모델이 직접 질문에 답변할 수 있다는 사실이 발견되었다.
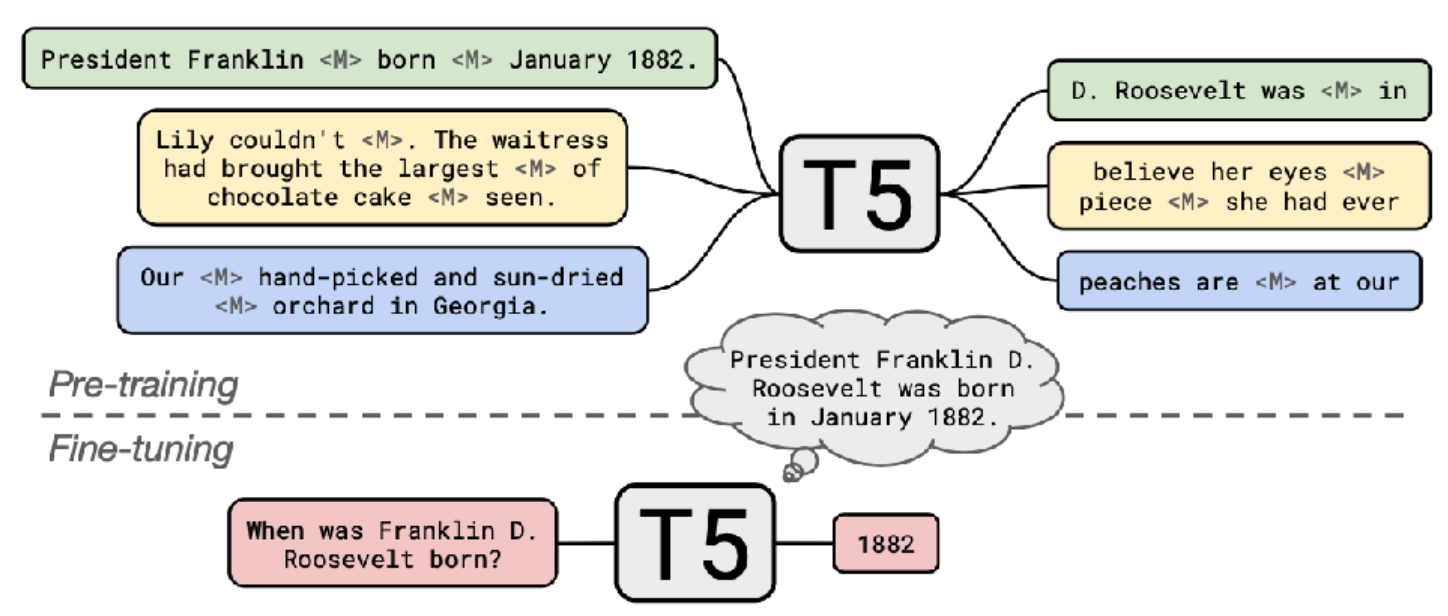
언어 모델은 세상에 대한 놀라운 수준의 지식을 가지고 있다는 것이 밝혀지며 closed-book QA는 모델의 성능을 평가하는 중요한 수단이 되었다.

MMLU(Massive Multitask Language Understanding)은 2021년에 발표된 언어 모델의 종합 지식 평가 벤치마크이다.
모델이 외부 지식을 참고하는 것이 아닌 parametric knowledge만으로 전문적인 질문들에 얼마나 정확히 답할 수 있는지를 평가한다.
ARC-C, MMLU, GPQA 등 많은 인기 있는 벤치마크들이 부분적으로 knowledge test 성격을 가지고 있다.
2. “Parametric” knowledge and why this is interesting
1) Parametric knowledge
parametric knowledge는 유용할까?
모델의 능력을 평가하는 일반적인 지표로 parametric knowledge를 왜 사용할까?
-
데이터 수집이 쉽고 자동 채점이 용이함 (예:
GPQA,Humanity's last exam) -
요약같은 다른 태스크를 수행할 때도
parametric knowledge는 유용함 -
parametric knowledge는scale같은 모델의 다른 능력들과도 상관관계가 있음
그렇다면 LM은 parametric knowledge를 어떻게 습득할까?
"Stanford University is located in ____?" 같은 문장의 빈칸을 채우는 학습을 통해 지식을 얻을 수 있다는 것을 알고 있다.
지식을 얻기 위해선 어떤 종류의 데이터가 필요하고 또 얼마만큼의 데이터가 필요할까?
연구 결과에 따르면 지식을 습득하기 위해선 그 지식에 관해 1,000번 이상 노출되거나 모델의 크기가 매우 거대해야 했다.
2) Limits
parametric knowledge에는 몇 가지 한계가 존재한다.
- 강건한 지식 습득의 어려움
-
논리적으로 추론해야 하는 지식을 학습하는 것이 어렵다.
"조 바이든은 짝수 연도에 태어났는가?"라는 질문으로 예를 들어보자.
모델은 조 바이든이 1946년에 태어났다는 사실을 알고 있고 짝수의 의미도 알고 있지만 위 질문에는 답을 못하는 경우이다.
특히
CoT없이 이러한 추론 지식을 학습하는 것은 어렵다.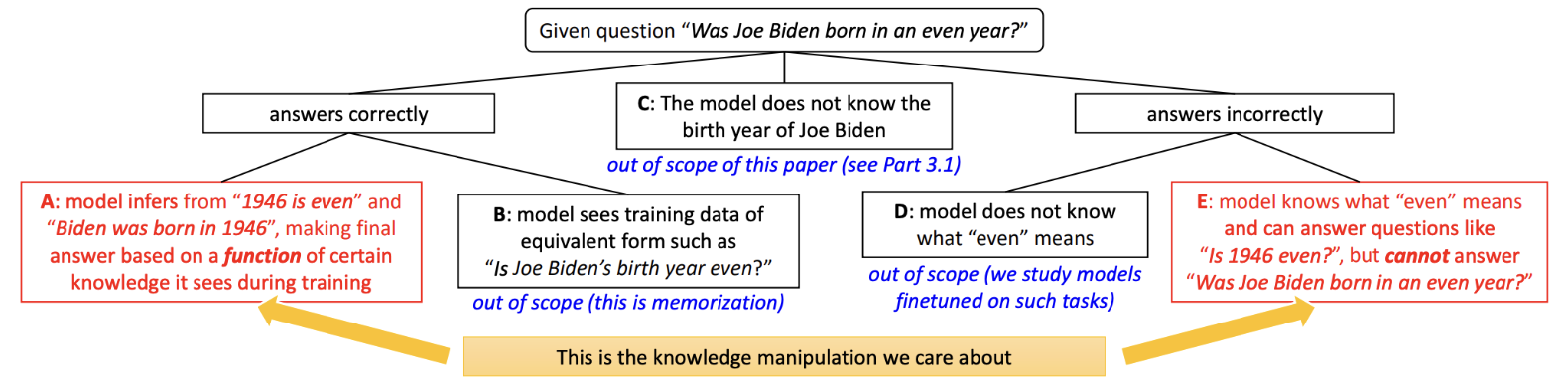
-
Reversal curse는 지식 활용을 제한한다.역전 저주란 "A는 B다."로 훈련된 LLM이 "B는 A다."를 배우는 데 실패하는 것을 의미한다.
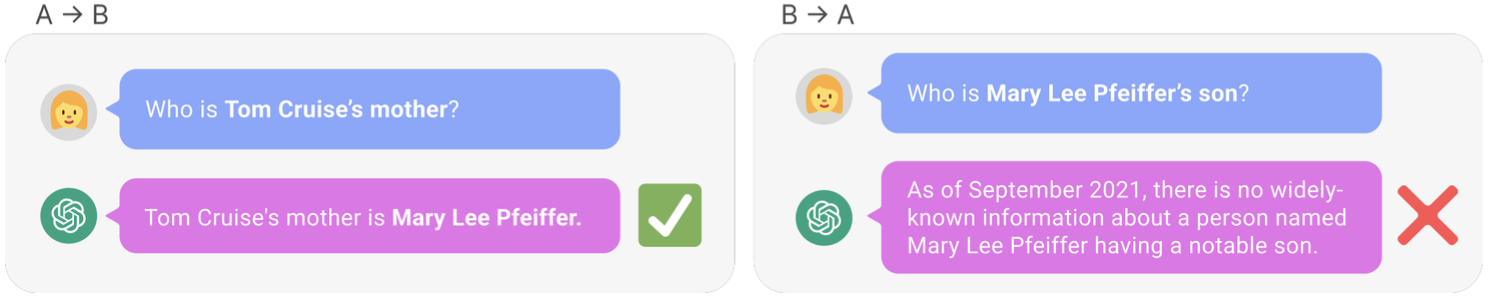
예를 들어 모델이 톰 크루즈의 어머니가 누구냐는 질문에는 답하지만
그의 어머니의 이름을 대고 아들이 누구냐는 역전된 질문에는 톰 크루즈라고 대답하지 못한다.
-
할루시네이션
LLMs는 많은 일을 잘 해내고 심지어closed-book QA에서도 훌륭한 성능을 보인다.하지만 모델이 모르는 것에 대해서도 답변을 적극적으로 지어낸다는 문제가 있다.
세상의 모든 것을 알지 못하므로 모를 때는 한 발 물러나서(
back off) 불확실성을 전달할 줄 알아야 한다.이를
abstention(기권)이라고 한다.backing off는abstention을 구현하는 방법 중 하나이다.
샘플링 또는 자기 평가를 통해서 답변 문장의 신뢰도를 추정하는데
이 신뢰도가 너무 낮으면 답변을 보류하거나 세부적인 답변 대신 간단히 답변한다.
3) Continued pretraining
abstention을 넘어서 사전 학습 후에도 새로운 parametric knowledge을 추가할 수 있을까?
이 경우 목표는 모델이 질문에 대해 잘 모를 때는 안정적으로 기권하고 새로운 정보를 얻었을 때는 그 지식을 추가하는 것이다.
지식을 업데이트하는 한 가지 방법은 도메인 특화 데이터로 사전학습을 계속 수행하는 것이다.
이를 continued pretraining, 줄여서 CPT라고 한다.
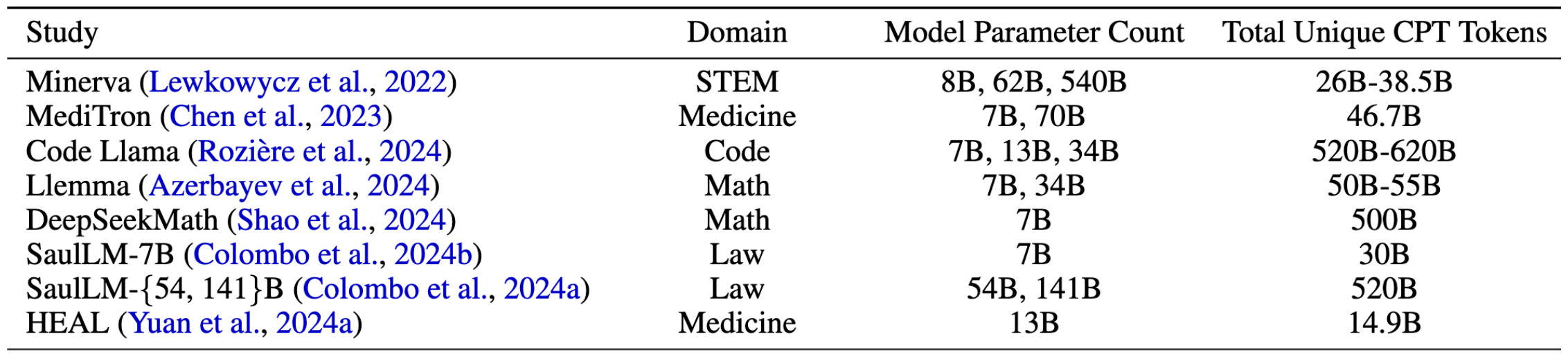
하지만 500억 개 이상의 데이터가 필요하다는 문제가 있다.
synthetic continued pretraining은 기존 데이터가 아닌 언어 모델이 변환한 데이터(LLM-transformed data)로 사전 학습을 수행하는 방법이다.
이 방법은 사전 학습의 다양성을 재현하는 것을 목표로 하며 도메인 주제, 표현 방식을 다양화하고 데이터 다양성을 확보하여 모델의 일반화 능력을 향상시킨다.
다시 말해 synthetic CPT는 적은 데이터로도 사전 학습의 효과를 재현하는 것을 목표로 한다.
language model augmentation은 이러한 접근법의 대표적인 프레임워크로 언어 모델이 스스로 데이터를 증강하는 방법이다.
예를 들어 도메인 관련된 짧은 문장을 제공하면 LLM이 그 문장을 변형하여 새로운 문장을 생성해낸다.
인간 개입 없이 데이터를 생성할 수 있고 데이터 양도 일반적인 CPT보다 훨씬 적게 필요하다는 장점이 있다.
하지만 모델이 생성한 문장을 모델이 학습하여 오류가 누적될 수 있다는 점과 데이터 품질 관리가 어렵다는 점이 문제점으로 꼽힌다.
따라서 synthetic CPT는 빠르고 저렴하지만 완벽하지는 않다.
하지만 많은 연구가 이 방식을 사전 학습 효율화 목적으로 채택하고 있다.
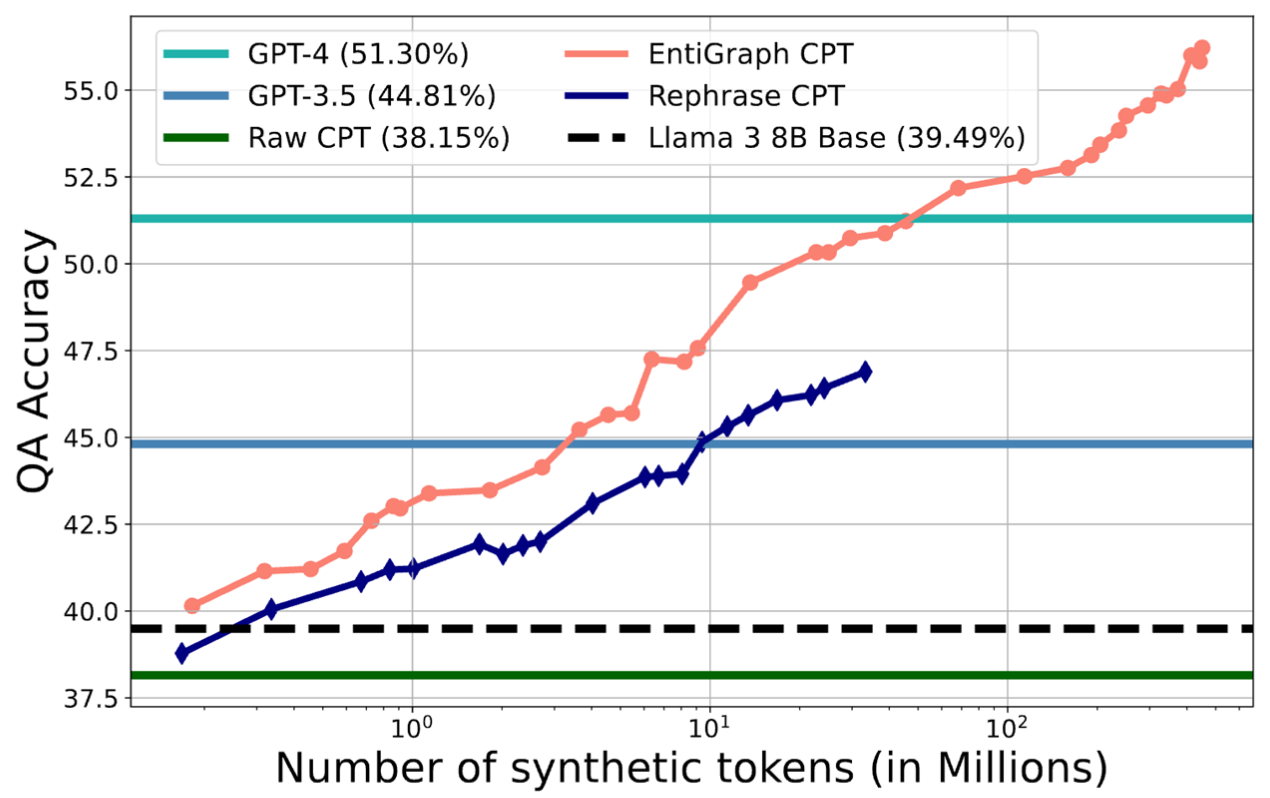
위 그래프에서 확인할 수 있듯이 합성 데이터를 사용한 EntiGraph CPT와 Rephrase CPT의 성능이 LLM의 평균 성능보다 높은 것을 확인할 수 있다.
다시 말해 CPT를 잘 활용하면 closed-book QA의 성능을 크게 향상시킬 수 있다.

블랙박스 언어 모델은 놀라운 성능을 보이지만 parametric memory에는 한계가 있다.
-
LLMs는 파라미터 안에 방대한 양의 정보를 저장하는데 모델이 모든 것을 기억할 수 없다. -
세상은 계속 변화하고 새로운 지식이 생겨난다.
-
기업, 연구소 등은 비공개된 내부 문서를 활용하고 싶어하지만
parametric knowledge는 공개된 웹 데이터에 기반한다. -
블랙박스 언어 모델은 불투명하여 답변이 어떤 근거로부터 나왔는지 알 수 없어 검증이 불가능하다.
그렇다면 open-book은 closed-book의 한계를 극복할 수 있을까?
3. Reading comprehension and RAG systems
1) Reading comprehension
reading comprehension은 텍스트 구문 P를 이해하고 그 내용에 대한 질문 Q에 답하는 것이다.
예를 들면 다음과 같다.
-
Passage
Tesla was the fourth of five children. He had an older brother named Dane and three sisters, Milka, Angelina and Marica. Dane was killed in a horse-riding accident when Nikola was five. In 1861, Tesla attended the “Lower” or “Primary” School in Smiljan where he studied German, arithmetic, and religion. In 1862, the Tesla family moved to Gospić, Austrian Empire, where Tesla’s father worked as a pastor. Nikola completed “Lower” or “Primary” School, followed by the “Lower Real Gymnasium” or “Normal School.”
-
Question
What language did Tesla study while in school?
-
Answer
German
이렇게 단순히 정보를 추출하는 QA가 아닌 비교 추론 유형의 QA도 존재한다.
-
Passage
Kannada language is the official language of Karnataka and spoken as a native language by about 66.54% of the people as of 2011. Other linguistic minorities in the state were Urdu (10.83%), Telugu language (5.84%), Tamil language (3.45%), Marathi language (3.38%), Hindi (3.3%), Tulu language (2.61%), Konkani language (1.29%), Malayalam (1.27%) and Kodava Takk (0.18%). In 2007 the state had a birth rate of 2.2%, a death rate of 0.7%, an infant mortality rate of 5.5% and a maternal mortality rate of 0.2%. The total fertility rate was 2.2.
-
Question
Which linguistic minority is larger, Hindi or Malayalam?
-
Answer
Hindi
Hindi가 3.3%로 Malayalam의 1.27보다 크므로 Hindi라고 답변하였다.
이를 통해 reading comprehension이 단순한 정보 추출이 아니라 이해와 추론을 수행함을 확인할 수 있다.
reading comprehension은 왜 중요할까?
Wendy Lehnert(1977)에 따르면 "질문은 텍스트 이해의 모든 측면을 시험하도록 설계될 수 있으므로 질문에 답할 수 있는 능력은 이해 능력을 가장 강력하게 증명하는 방식이다."라고 하였다.
reading comprehension이 단순히 QA 태스크 중 하나가 아닌 전체적인 언어 이해를 평가하는 가장 포괄적인 지표라는 것이다.
많은 NLP 태스크가 reading comprehension 문제로 축소될 수 있다.
앞서 살펴본 정보 추출이나 의미역 결정에서도 그렇다.
의미역 결정(semantic role labeling, SRL)이란 문장 내에서 **누가, 무엇을, 언제, 어떻게, 왜, 어디서" 등 같은 의미역을 구조적으로 분석하는 태스크이다.
예를 들어 "UCD finished the 2006 championship as Dublin champions, by beating St Vincents in the final."라는 문장을 생각해보자.
"finished"에 대하여 다음과 같이 분석할 수 있다.
Who finished something? UCD
What did someone finish? the 2006 championship
What did someone finish something as? Dublin champions
How did someone finish something? by beating St Vincents in the final
2) Datasets
SQuAD는 대표적인 reading comprehension 데이터셋이자 현대 QA 연구의 핵심 데이터셋이기도 하다.

위 그림을 통해 SQuAD의 기본 구조를 확인할 수 있다.
가장 위에 텍스트 구문 P가 있고 그 아래에는 여러 질문 Q와 그에 대한 답인 ground truth answers가 A가 있다.
P는 위키피디아 문서의 한 단락이며 Q는 사람이 작성한 자연어 질문이다.
그리고 A는 P 내의 정답이 포함된 텍스트 구간 span이다.
SQuAD 외에도 QA 연구에 사용되는 다양한 데이터셋들이 존재한다.
TriviaQA는 일반 상식에 관한 질문과 정답으로 구성되어 있다.
정답이 포함된 웹 문단을 독립적으로 수집했지만 각 문단이 실제로 정답을 포함하는지 인간의 검증이 이루어지지 않았다.
Natural Question(NQ)은 질문은 구글에서 자주 검색된 질문으로, 정답은 위키피디아 문단으로 구성되어있다.
정답은 문자열의 일부분, 예/아니오, NOT_PRESENT(존재하지 않음) 형태일 수 있으며 인간이 검증이 이루어졌다.
실제 인간의 질의를 기반으로 확장한 대표적인 데이터셋으로 오픈 도메인 QA 모델의 주요 벤치마크로 사용된다.
HotpotQA는 전체 위키피디아를 대상으로 두 개 이상의 페이지에서 정보를 결합(multi-hop reasoning)해야 답할 수 있는 질문들로 구성되어 있다.
다음과 같은 질문과 답변을 살펴보자.
Q: "Armada"의 저자가 쓴 소설 중 어떤 소설이 스티븐 스필버그의 영화로 각색될 예정인가?
A: Ready Player One
위 질문에 답변을 하려면 먼저 "Armada"의 저자가 Ernest Cline임을 찾아야 한다.
그 다음엔 Cline의 소설 중 스필버그가 각색한 소설은 "Ready Player One"임을 찾아야 한다.
이렇게 hotpotQA는 단일 문단에서의 QA가 아닌 다중 문단(multi-hop)을 참고하여 답변하는 QA로 진화했다는 점에서 의의가 있으며 인간의 검증이 이루어졌다.
3) Retrieval augmentation
ODQA(Open-domain Question Answering)은 reading comprehension과 다르게 답이 포함된 문단이 주어졌다고 가정하지 않는다.
대신 위키피디아같은 방대한 문서 컬렉션에 접근할 수 있다.
하지만 정답이 어떤 문서에 있는지 알 수 없으며 모델의 목표는 어떤 오픈 도메인 질문에 대해서도 정답을 반환하는 것이다.
더 어렵고 도전적이지만 실용적인 문제이기도 하다.
이와 반대로 closed-domain 시스템은 의학, 기술 지원 등 특정 분야 내의 질문만을 다룬다.
Retrieval augmentation 프레임워크는 ODQA의 대표 구조로 DrQA에서 처음으로 제시되었다.

DrQA는 retriever와 reader 두 부분으로 구성되어 있다.
-
retriever: 질문에 대해 관련 문서를 검색
-
reader: 검색된 문서 중 정답이 포함된 부분을 neural reader가 추출
예를 들어 질문 “How many of Warsaw’s inhabitants spoke Polish in 1933?”에 대해 retrieval augmentation은 다음과 같이 작동한다.
-
retriever: 위키피디아 문서에서 "Warsaw demographics" 페이지 검색
-
reader: 검색 문서에서 숫자 표현이 포함된 문장을 찾아 정답 추출
retrieval augmentation은 이후 RAG 연구의 기반이 된다.
앞서 parametric knowledge를 활용하는 LLM의 한계점을 살펴봤었다.
모든 정보를 다 학습할 수 없다는 점, 새로운 지식이 계속해서 생겨난다는 점, 답변의 근거를 추척하거나 검증하기 어렵다는 점이 한계점이었다.
그렇다면 LLM에게 세상의 모든 지식을 기억하라고 요구하는 관련있고 유용한 정보를 필요할 때마다 즉시 제공할 수는 없을까?
retrieval 또는 search는 이러한 관련된 정보를 찾는 가장 보편적인 방법이다.
dynamic: 새로운 문서를 추가하거나 업데이트하기 쉽다.
interpretable(해석 가능): LLM이 참조한 문서를 함께 제시하여 사람이 생성 결과를 검증할 수 있다.

Retriever-Reader 프레임워크에 대해 더 자세히 알아보자.
리트리버의 입력은 방대한 문서 집합 과 질문 이다.
로 표현할 수 있으며 는 질문 와 관련도가 높은 문서, 는 그 문서의 개수를 의미한다.
는 사전에 정의되는데, 예를 들어 이라면 문서 집합 에서 질문 와 관련된 문서 개를 찾겠다는 것이다.
리더의 입력은 질문 와 찾아낸 관련 문서 이며 관련 문서에서 질문의 정답을 추출한다.
로 표현할 수 있으며 텍스트 구문을 기반으로 질문에 대한 정답을 출력하는 것이므로 reading comprehension 문제로 환원된다.
DrQA에서 리트리버는 기본적인 TF-IDF 기반의 희소 벡터 검색기를 사용했다.
리더는 사실상 reading comprehension 모델을 리트리버에 결합한 형태이며 SQuAD같은 QA 데이터셋으로 학습된 모델 또는 chatGPT같은 제로샷 LLM이 이에 해당한다.
4) Retrieval-Augmented Generation
이제 retriever-reader 구조에서 generation으로 확장한 형태인 RAG(Retrieval-Augmented Generation)를 알아보자.
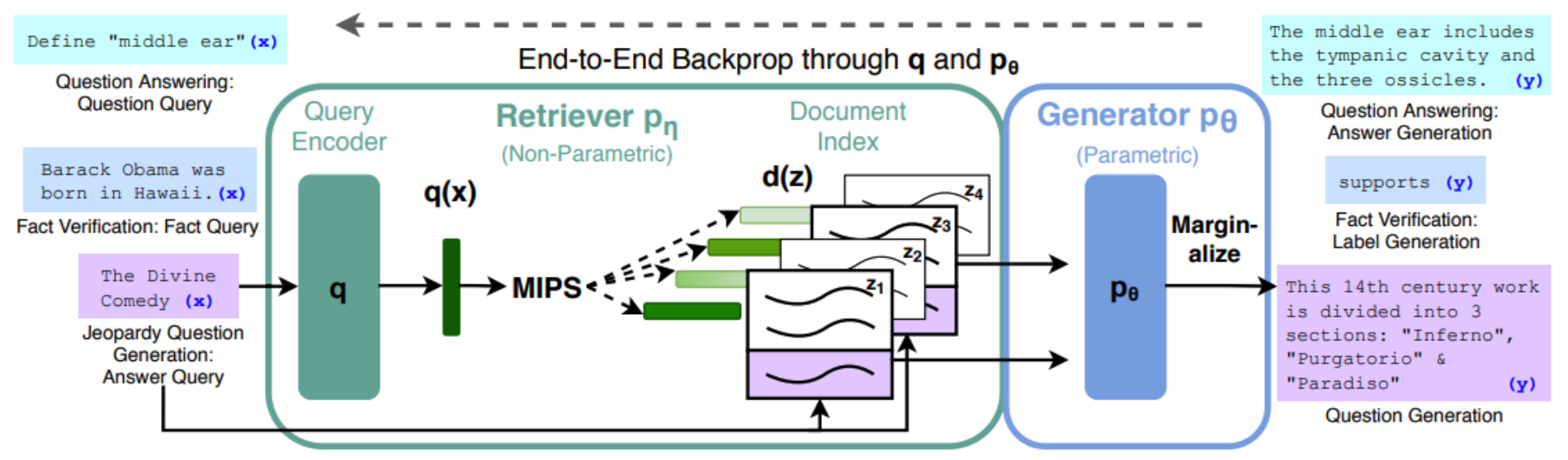
RAG가 매우 강력한 접근 방법이라고 하는데 RAG가 실제로 얼마나 잘 작동할까?
그리고 사실적인가?
먼저 검색 시스템에서 질문과 관련 문단을 찾기 위한 기법은 크게 아래 세 가지로 정리할 수 있다.
-
Word-overlap(BM25)
단어 기반 검색은 질문과 문서 간 공통 단어 수를 세어 유사도를 계산하는 방식이다.검색이 빨라 대규모 문서 검색에 적합하고 해석 가능하다는 장점이 있으나 단어 일치 기반이므로 의미를 이해하지 못한다는 단점이 있다.
-
Vector retrieval(DPR, Sentence vectors)
질문()과 문서()를 벡터 공간(embedding space)으로 변환하고 그 유사도(ex. 코사인 유사도)를 계산하는 방식이다.단어가 달라도 의미가 비슷하면 근접한 벡터로 매핑되어 semantic retrieval가 가능하다는 장점이 있으나 초기 학습 데이터 품질에 민감하고 계산 비용이 높으며 정기적 인덱스 업데이트가 필요하다.
-
Other, neural systems(ColBERT)
각 토큰 수준에서 문장 간 유사도를 계산하여 정확하면서도 효율적인 의미 검색을 수행하는 방식이다.BM25 수준의 빠른 검색 속도와 함께 DPR 보다는 높은 정확도를 가진다는 장점이 있으나 인덱스에 각 토큰 벡터를 저장해야 하므로 인덱스 크기가 크고 시스템 구현이 복잡하다.
가장 빠른 리트리버는 미리 계산된 벡터나 공통 단어 수를 기반으로 유사도를 계산하는 방법이다.
앞서 공통 단어 수를 계산하는 BM25의 경우 단어 빈도(TF-IDF)를 미리 계산해두고 QA 시에 단순히 점수 계산만 수헹하므로 검색을 빠르게 수행할 수 있다.
DPR 같은 밀집 벡터 검색도 모든 문서를 사전에 임베딩 벡터로 변환하고 FAISS 등을 이용하여 문서 벡터와 질의 벡터 간 코사인 유사도를 빠르게 계산할 수 있다.
모든 문서의 representation을 미리 만들어두면 검색 시에는 단순히 비교만 수행하면 된다.
가장 느린 리트리버는 언어 모델(LLM)을 직접 사용하여 유사도를 계산하는 방법이다.
질문 와 각 문서 를 입력으로 넣어 에 의 정답이 포함되어 있는지 모델이 직접 판단하므로 가장 정확하지만 검색이 느리다.
문서마다 LLM 호출이 필요하므로 수십만개의 문서를 처리하는 것은 현실적으로 불가하며 API 호출이나 GPU 연산 비용이 매우 크므로 실제 RAG 시스템에서는 거의 사용되지 않는다.
ColBERT는 빠름과 정확함의 절충형 모델이다.
문서의 각 토큰 단위 임베딩을 LLM을 이용해 사전에 계산하고 질문 또한 LLM으로 벡터화하되 유사도를 계산할 땐 LLM이 아닌 벡터 간 비교를 수행한다.
토큰 단위 임베딩에 있어 BM25와의 차이점은 의미의 유무이다.
BM25는 의미가 아닌 공통된 단어 수를 계산하는데 반해 ColBERT는 토큰에 의미가 포함되어 있다.
다시 말해 LLM으로 임베딩하여 정확도를 높이되 유사도는 LLM을 사용하지 않고 벡터들과 질의 벡터를 비교하므로 빠르게 유사도를 계산할 수 있다.
a. Joint Training
리트리버를 학습할 수도 있다.
리트리버와 리더를 함께 업데이트하는 joint training을 알아보자.
각 텍스트 문단은 BERT를 사용하여 벡터로 인코딩될 수 있고 질문과 구문의 표현 간 내적을 통해 리트리버 점수가 계산될 수 있다는 사실을 인지하고 아래 그림을 살펴보자.
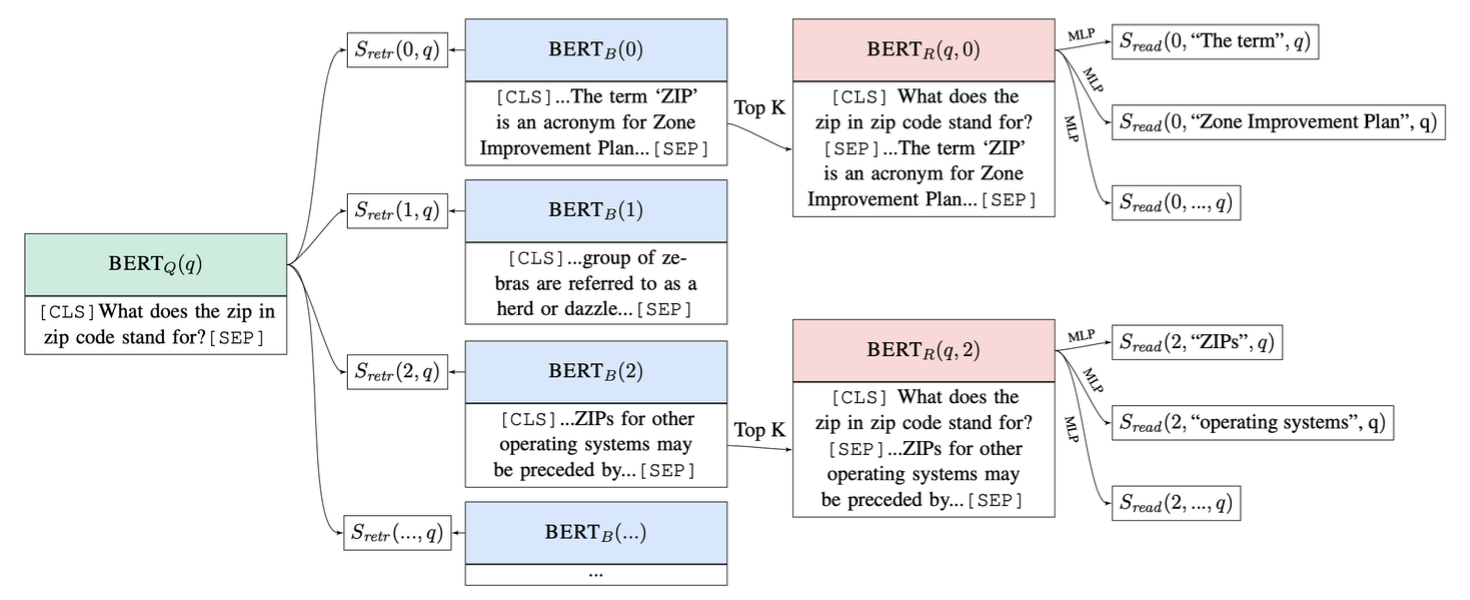
가장 왼쪽의 는 "What does the zip in zip code stand for?"같은 질문을 벡터로 인코딩한다.
중간의 는 위키피디아의 문단들을 벡터로 인코딩한다.
질문 벡터와 문단 벡터를 연결하는 는 리트리버 점수를 구하는 것을 의미한다.
다시 말해 질문 의 벡터와 번째 문단 벡터 간 내적으로 유사도를 계산한다.
이 유사도를 기준으로 리트리버가 상위 k개(top-k)의 문단을 선택한다.
는 선택된 문단을 리더가 입력받아 문단에서 정답을 추출한다.
는 정답 후보에 대한 로짓 값을 의미한다.
이렇게 리트리버와 리더를 연결하여 학습한다.
리트리버의 경우 정답이 포함된 문서는 높은 점수를, 무관한 문서는 낮은 점수를 받도록 학습되고 리더의 경우 선택된 문단에서 올바른 정답을 정확히 추출하도록 학습된다.
리트리버와 리더의 손실을 결합하여 함께 업데이트하는 방식이다.
하지만 위키피디아 전체 문서를 BERT로 인코딩해야 하므로 연산량이 어마어마하다는 한계점이 존재한다.
이를 해결하기 위해 DPR, ANCE, Contriver 같은 연구들이 등장했다.
b. Dense Passage Retrieval
이번엔 DPR(Dense Passage Retrieval)을 살펴보자.
DPR은 질문-정답 쌍을 사용하여 리트리버를 학습시킬 수 있다.
앞서 리트리버와 리더를 함께 학습하는 방식을 살펴보았는데 DPR은 질문-정답 쌍을 이용하여 리트리버 자체를 독립적으로 학습할 수 있게 되어 보다 효율적이다.
임베딩 공간에서 정답이 포함된 문서는 질문과 가깝게, 정답이 포함되지 않은 문서는 질문과 멀게 배치되도록 학습된다.
이 때 두 개의 독립적인 BERT 인코더가 사용되는데 아래 그림의 와 이다.
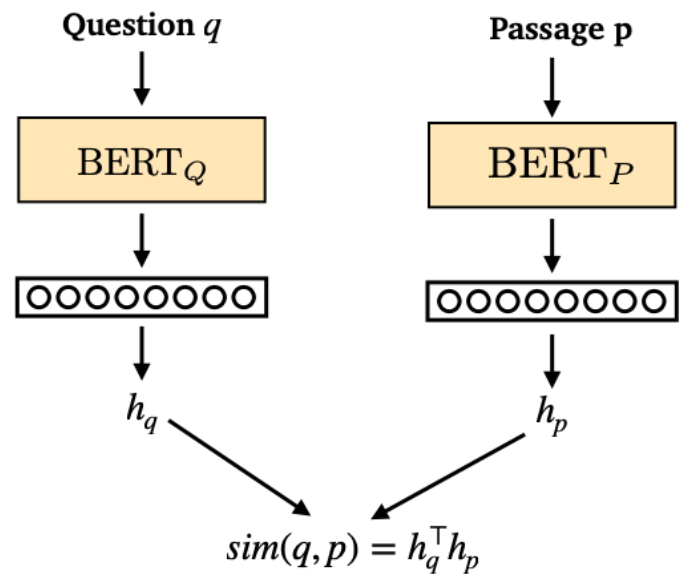
는 질문을 벡터로 인코딩하고 는 문서를 벡터로 인코딩한다.
DPR은 top-k accuracy에서 BM25를 뛰어 넘고 특히 k가 작을수록 성능은 더 크게 차이가 난다.
그리고 학습 데이터가 많을수록 성능이 더 향상되는 것을 확인할 수 있다.
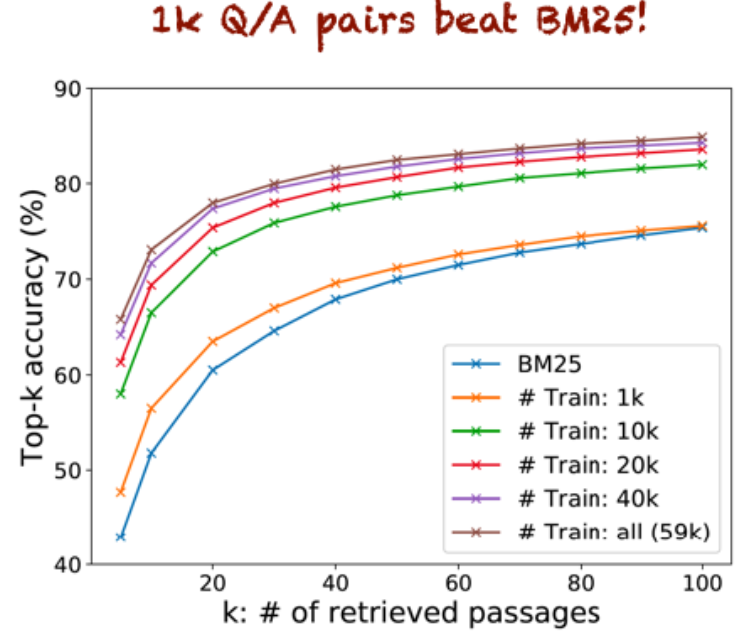
BERT를 사용한 학습 가능한 리트리버는 BM25같은 기존의 정보 검색 모델보다 훨씬 뛰어난 성능을 보인다.
DPR 학습에는 샘플링을 사용하는데 앞서 정답이 포함된 문선는 질문과 가깝게 정답이 포함되지 않은 문서는 질문과 멀게 배치되도록 학습한다고 했다.
이때 정답이 포함된 문서를 긍정 샘플로 설정하고 이외의 문서들은 부정 샘플로 사용하여 학습을 수행한다.
이 샘플링 분야도 연구가 많이 되는 분야라고 한다.
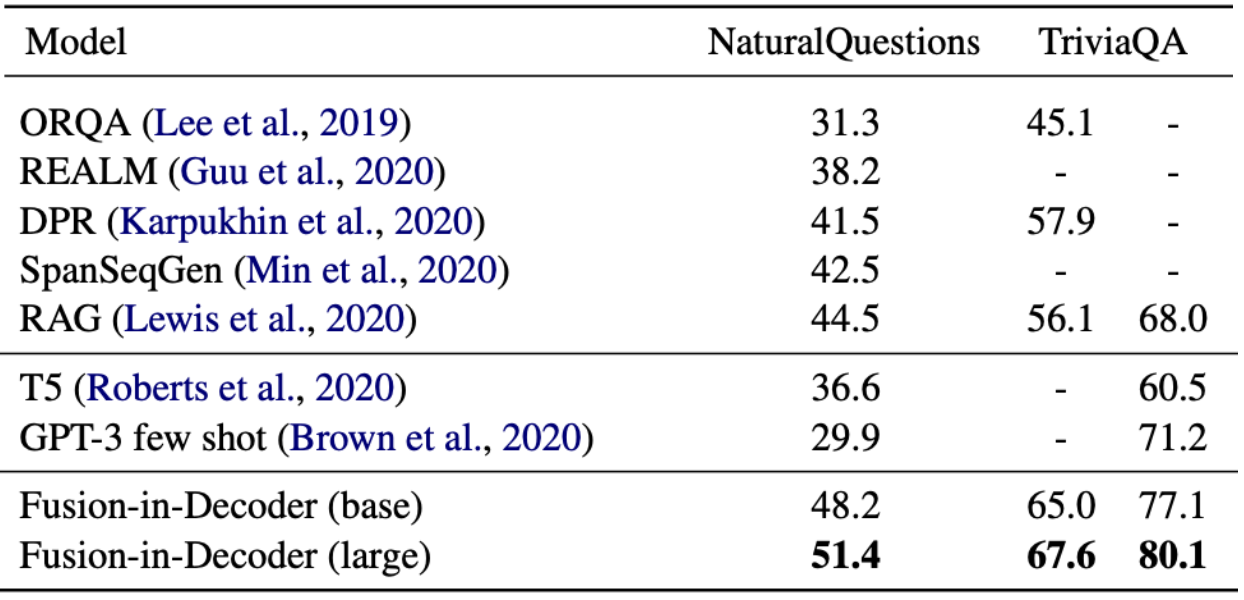
c. Fusion-in-Decoder
최근 연구는 정답을 추출하기보다 생성하는 방식이 더 효과적임이 밝혀졌다.
Fusion-in-Decoder(FiD) 모델은 DPR을 이용해 질문과 관련된 top-k의 패시지를 검색하고 T5를 이용해 검색된 패시지들을 종합하여(fusion) 자연어 답변을 생성하는 방식이다.
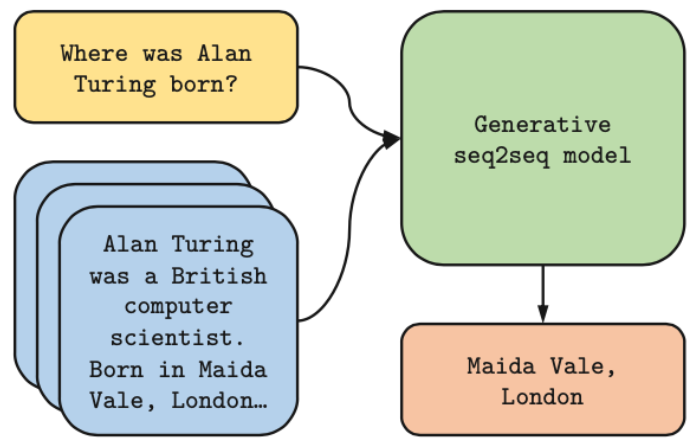
리더를 사용하는 기존의 모델(DPR reader, DrQA)은 검색된 문서에서 정답에 해당하는 span을 추출하는 것을 살펴봤었다.
예를 들어 "The capital of France is Paris."라는 문장이 있을 때 "Paris"만 잘라내는 방식이었다.
하지만 이 방식은 문서 내에 정답이 정확히 동일한 문장으로 있지 않으면 추출이 불가능하다는 점, 다중 문서 결합이 불가능하고 복잡한 서술적 답변 생성이 불가능하다는 단점이 존재했다.
따라서 Izacard0&Grave(2020)는 Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering에서 검색된 문서를 읽고 새로운 문장을 만들어내는 생성형 접근을 제안하였다.
이 생성형 접근은 기존의 방식보다 더 나은 성능을 보였다.
d. Limits
그렇다면 얼마나 많은 문서를 사용할 수 있을까?
리트리버가 가장 중요하다.
만약 문서 하나만 사용할 수 있다면 질문에 대한 문서를 정확히 찾아야 한다.
왜 수많은 문서를 한꺼번에 언어 모델에 입력하지 않을까?
언어 모델은 전체 문맥에 주의를 기울이지 못한다.
언어 모델은 긴 문맥이 입력될 때 이 문맥 전체를 고르게 인식하지 못한다.
그러니까 긴 문맥에 대해 초반과 중반, 후반 문맥을 인식할 때 고르게 인식하지 않고 주의 정도가 다르다는 것이다.
실험에 대한 아래의 그림을 통해 살펴보자.
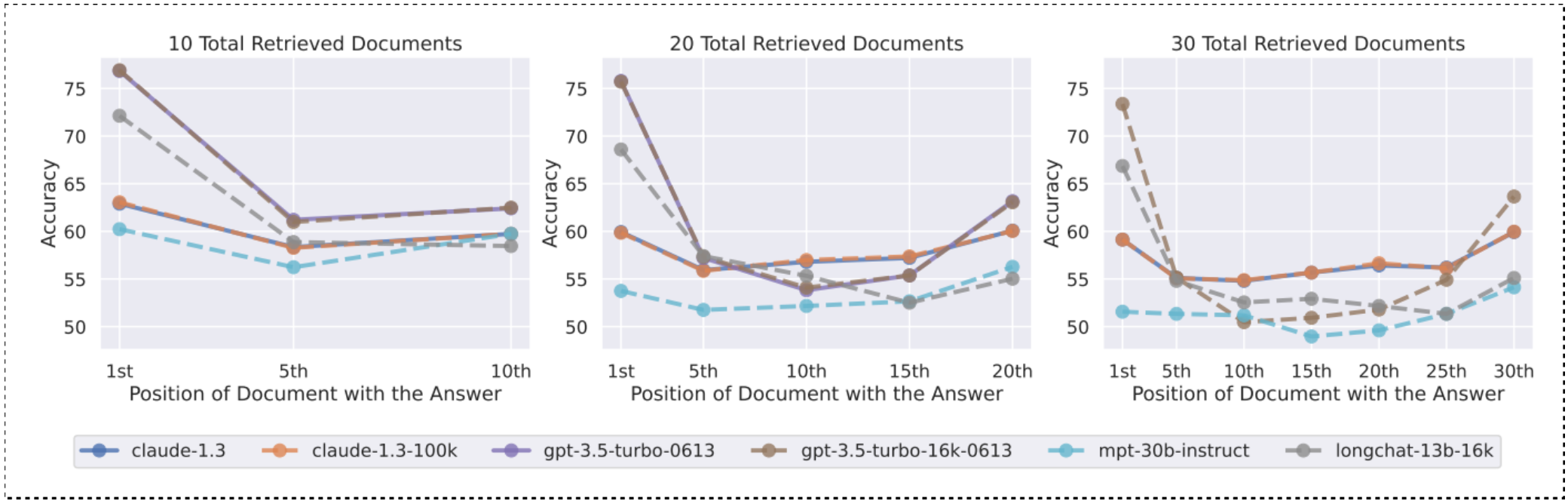
이 실험의 조건은 문서에 대해 질문과 관련있는 문서는 단 하나만 존재하고 나머지 문서는 모두 질문과 관련없는 문서로 구성했다.
그래프의 x축은 관련 있는 단 하나의 문서가 전체 문서에서 어느 부분에 위치하는지를 나타낸다.
y축은 정확도를 의미한다.
그리고 문서가 10개일 때, 20개일 때, 30개일 때의 실험을 보여준다.
예를 들어 가장 왼쪽의 그래프는 문서가 총 10개일 때 관련있는 문서의 위치(x)에 따른 정확도를 보여준다.
관련 문서가 맨 앞에 있을 때 정확도가 가장 높고 중간에 있을 때는 가장 낮고 맨 뒤에 있을 때는 중간에 있을 때보다는 정확도가 더 높은 것을 확인할 수 있다.
이러한 현상은 총 문서가 20개, 30개일 때 더 명확히 나타난다.
맨 앞에 정답 문서가 위치할 때 정확도가 가장 높고 중간 위치에서 가장 낮고 맨 뒤에 위치할 때 중간보다 정확도가 좀 더 높아진다.
이를 통해 모델이 입력 초반이나 후반에는 주의를 두지만 중간 문맥은 거의 무시한다는 것을 알 수 있다.
실제 환경에서 언어 모델은 많은 문서를 활용하지 못한다.
아래의 그림을 보자.
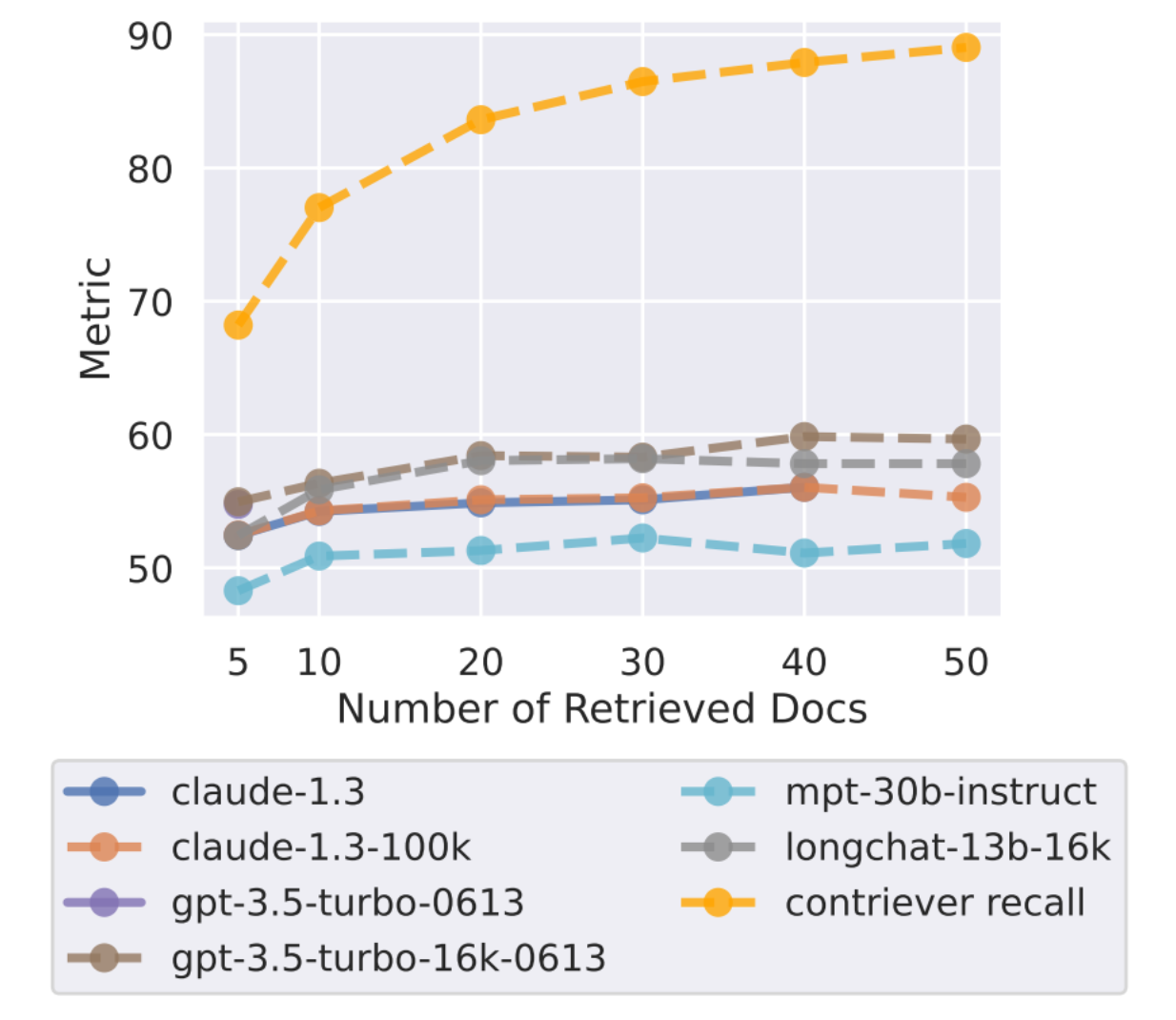
노란선은 리트리버의 성능을 의미하는데 검색된 문서의 개수가 많을수록 성능 또한 상승하는 것을 확인할 수 있다.
노란선 이외의 선들은 RAG의 성능을 의미하는데 5-20개의 문서보다 많은 문서가 검색되면 성능 변화가 거의 없고 빠르게 포화되는 것을 확인할 수 있다.
리트리버의 품질은 좋음에도 LLM의 답변 품질은 그만큼 오르지 않는 현상을 확인할 수 있다.
RAG의 현실적인 한계점을 보여준다.
e. Web search
요즘에는 웹 검색과 함께 LLM을 사용하여 더 방대한 오픈 도메인을 활용할 수 있다.
제미나이가 구글 검색을 이용하는 것뿐만 아니라 perplexity, bing, GPT 등 많은 LLM이 웹 검색을 활용한다.
이러한 시스템의 아키텍처를 구글의 RARR(Retrieval-Augmented Response Refinement)을 대표로 살펴보자.
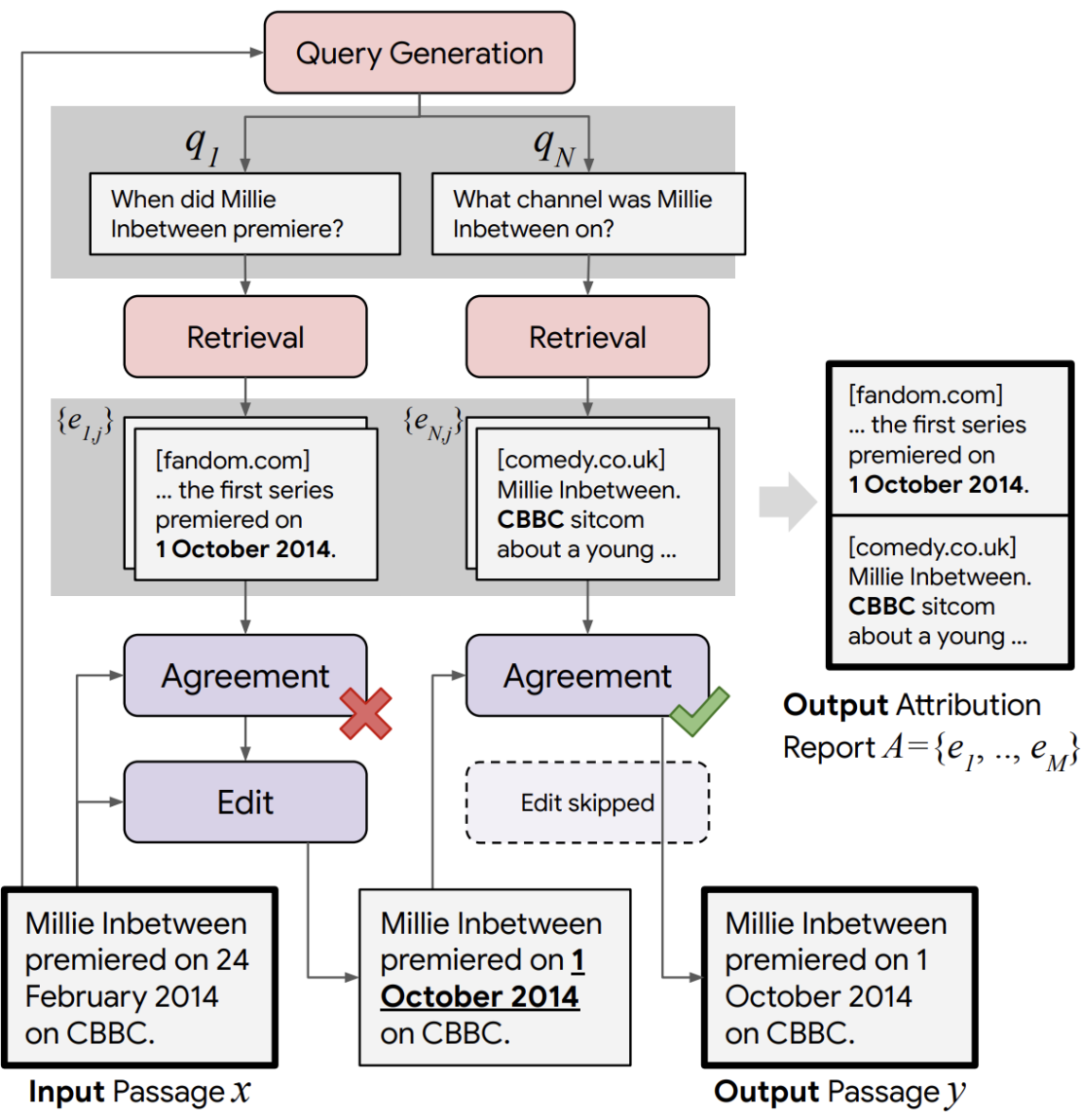
RARR은 다음과 같은 4단계 파이프라인을 수행한다.
- Query generation
사용자의 입력에 대해 모델이 응답을 생성한다.
이 응답이 Input Passage 이다.
"Millie Inbetween premiered on 24 February 2014 on CBBC."
이 응답에 대한 쿼리를 생성한다.
: "When did Millie Inbetween premiere?"
: "What channel was Millie Inbetween on?"
- Retrieval
생성된 각 쿼리별로 관련 문서를 검색한다.
에 대한 문서 는 "... the first series premiered on 1 October 2014."
에 대한 문서 은 "Millie Inbetween. CBBC sitcom about a young ..."
- Agreement check
모델이 생성한 응답 와 검색 문서 가 내용 상 일치하는지 QA를 통해 확인한다.
일치하면 일관성이 유지되므로 그대로 통과하고 일치하지 않으면 Edit 단계로 보낸다.
Edit 단계에서는 LLM이 검색 문서를 사실로 간주하고 이에 맞게 응답을 수정한다.
예시에서 원래의 응답은 방영일을 "24 February 2014"라고 하였으나 검색 문서를 참고하여 "1 October 2014"로 수정한 것을 확인할 수 있다.
반면 채널은 원래의 응답과 검색 문서 모두 "CBBC"로 동일하므로 그대로 통과시킨다.
- Output attribution
마지막으로 모델은 최종 응답과 함께 출처를 명시한다.
RARR는 QA 자체를 fact-checking 메커니즘으로 사용한다는 것을 통해 사실 검증에도 QA가 사용될 수 있음을 알 수 있다.
f. Citation
LLM 기반의 QA 시스템이 정답일까?
RAG의 특별한 장점은 출처를 명시할 수 있다는 점이다.
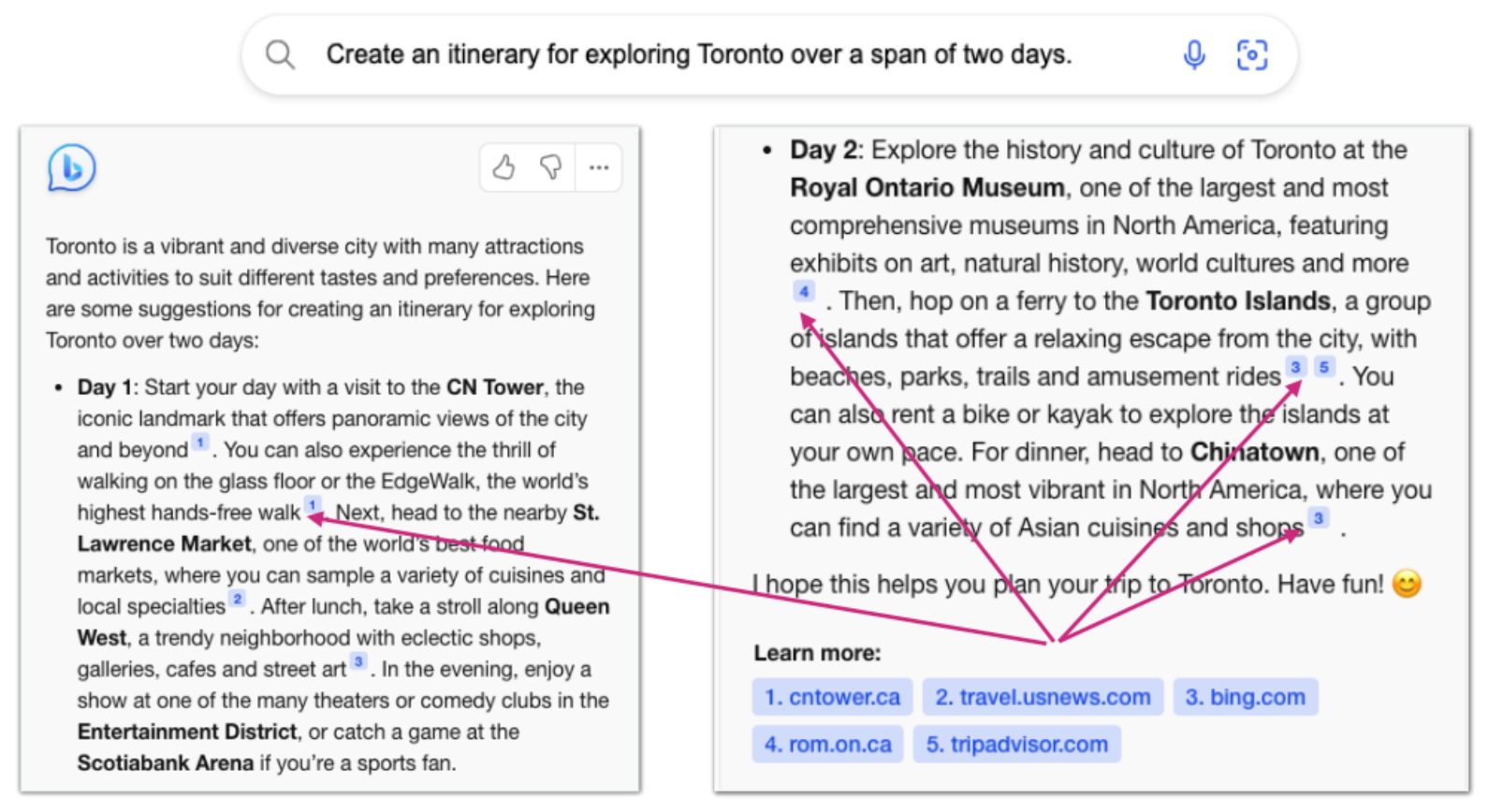
그럼 이 출처들은 얼마나 정확할까?

제임스 웹 우주망원경의 최신 발견은 무엇이라는 질문에 대해 3개의 출처를 인용하여 답변을 생성했지만 출처 [1]은 답변을 뒷받침하지 않고 출처 [2]는 부분적으로만 뒷받침하며 출처 [3]만 답변을 정확히 뒷받침한다.
위 예시처럼 출처 자체도 LLM이 생성한 것이므로 할루시네이션이 발생할 수 있다.
그렇다면 출처에 대한 할루시네이션은 얼마나 자주 일어날까?
이를 정량적으로 평가한 결과를 살펴보자.
먼저 현재 RAG 시스템에 생성한 응답이 얼마나 유용한지(Perceived Utility) 그리고 얼마나 읽기 쉬운지(Fluency)에 대한 평가 결과는 아래와 같다.
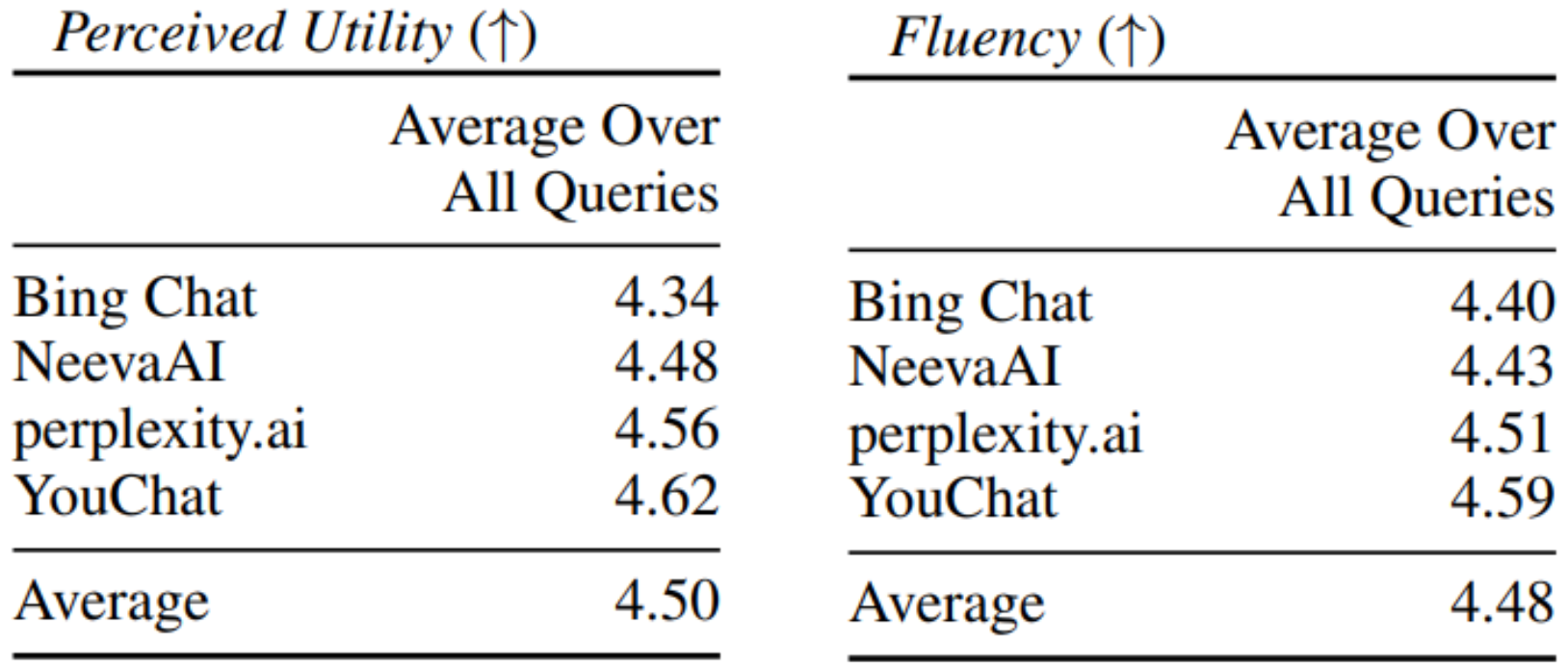
5점 만점 기준으로 모든 시스템이 유용한 응답을 생성하고 생성된 답변의 가독성도 좋다고 평가받았다.
하지만 출처에 대한 정확성와 재현율에 대한 평가 결과는 상당히 낮은 것을 확인할 수 있다.
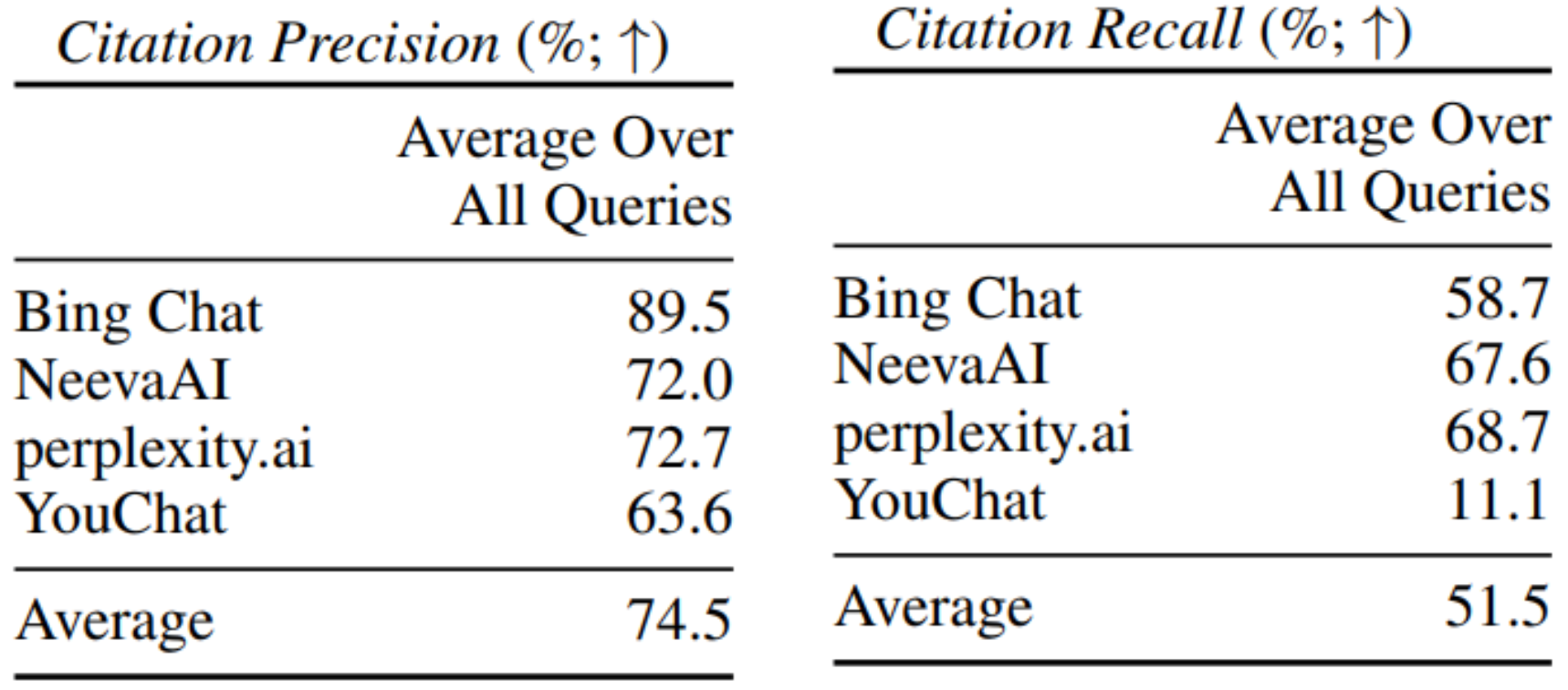
출처의 정확성은 제시된 출처가 실제로 문장을 뒷받침하는가에 대한 비율을 의미하며 Bing Chat이 상대적으로 높은 정확도를 보였지만 나머지 시스템은 약 70% 수준에 머무르고 있다.
출처의 재현율은 답변에 포함된 모든 사실 중 출처로 뒷받침된 비율을 의미하며 평균이 50%대를 기록하였는데 이는 LLM의 답변 중 절반 정도는 출처가 없는 진술임을 의미한다.
특히 YouChat의 경우 약 11%로 recall이 매우 낮아 대부분의 문장이 근거 없이 생성되었다는 것을 알 수 있다.
4. Conclusion
정리하자면 다음과 같다.
QA는 LLM의 가장 대표적인 활용 분야 중 하나이다.
특히 QA는 LLM의 능력과 지식 이해력을 평가하는 주요 수단이다.
RAG, 인터넷 검색 기반 QA 등 시스템 관점에서도 QA는 중요하다.
한계점은 검색기는 완벽하지 않으며 LLM은 많은 문서를 한 번에 처리하지 못한다는 점이다. (long-context limitation)
