
GPT를 다시 떠올려보자.
2018년에 공개된 GPT는 1억 1,700만개의 파라미터와 12개의 트랜스포머 디코더 레이어로 이루어져 있다.
학습 데이터는 약 7,000권 분량의 책들로 만들어진 BookCorpus이며 4.6GB 크기의 텍스트이다.
GPT는 대규모 언어 모델링이 자연어 추론같은 태스크에 효과적인 사전 학습 테크닉이 될 수 있음을 보여주었다.
그렇다면 2019년에 공개된 GPT-2는 GPT와 어떤 차이점이 있을까?
GPT-2는 GPT와 같은 아키텍처 기반에 파라미터 크기를 15억개로, 데이터는 40GB로 더 키운 모델이다.
또한 GPT-2부터 zero-shot learning이 본격적으로 발전하기 시작했다.
Zero-shot learning은 모델에게 예시를 보여주거나 그래디언트를 업데이트하는 과정 없이도 다양한 태스크를 수행하는 능력을 말한다.
그러니까 모델에 프롬프트를 제공하면 사전 학습 지식만을 바탕으로 프롬프트에 맞는 출력을 생성하는 것이다.
GPT-2는 태스크에 대해 파인튜닝을 하지 않았음에도 언어 모델링 벤치마크에서 SoTA를 달성했다.
모델이 수행할 태스크를 지정하는 프롬프트를 잘 작성하면 학습되지 않은 태스크도 수행할 수 있음을 보여줬다.
GPT-3는 어떨까?
GPT-3는 1,750억개의 파라미터로 이루어져 있으며 600GB의 데이터로 학습되었다.
GPT-3에서는 few-shot learning에 주목한다.
기존의 few-shot learning은 모델이 소량의 데이터로 학습하여 파라미터를 업데이트하는 방식이었다.
하지만 GPT-3의 few-shot learning은 프롬프트에 태스크 예시를 포함하여 제공하면 파라미터 업데이트 없이도 그 태스크를 수행한다.
이를 in-context learning이라고도 부르는데 태스크를 학습할 때 그래디언트를 업데이트하지 않고 프롬프트의 문맥 내에서 즉석으로 학습하기 때문이다.
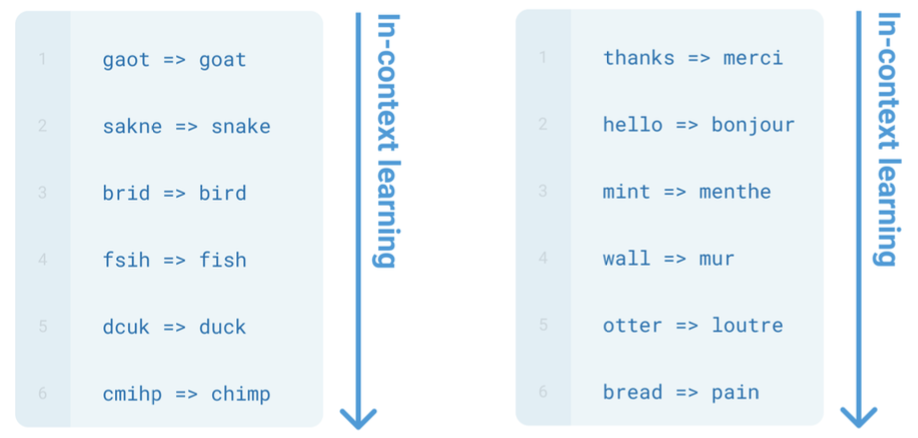
그럼 zero-shot과 one-shot, few-shot의 성능을 확인해보자.
Zero-shot은 프롬프트에서 태스크를 지정한다고 했다.

영어를 불어로 번역하라는 지시만 존재할 뿐 예시는 존재하지 않는다.
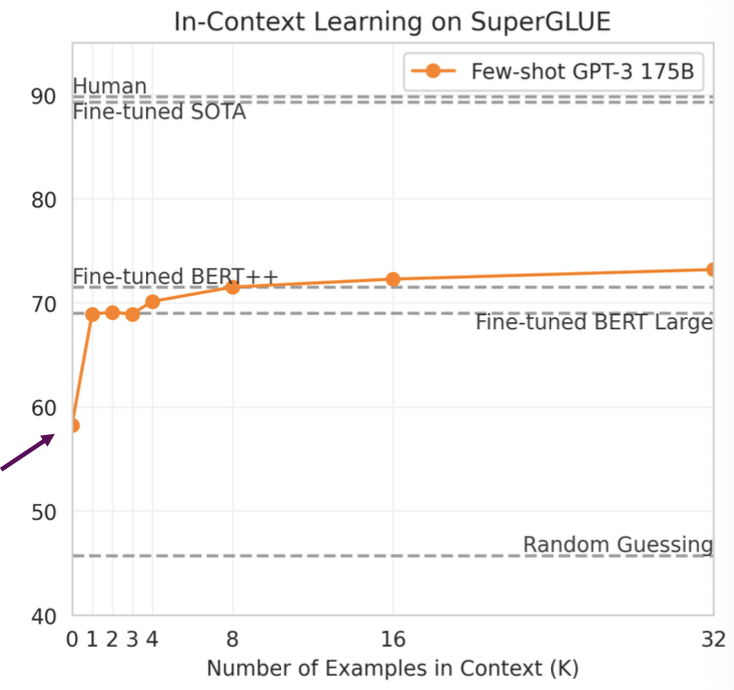
Zero-shot 성능은 예시를 하나라도 보여준 경우의 성능보다 훨씬 떨어지는 것을 확인할 수 있다.
One-shot은 프롬프트에서 태스크 지정과 함께 하나의 예시만 포함한다.

영어를 불어로 번역하라는 지시와 함께 sea otter는 loutre de mer로 번역된다는 예시를 함께 보여준다.
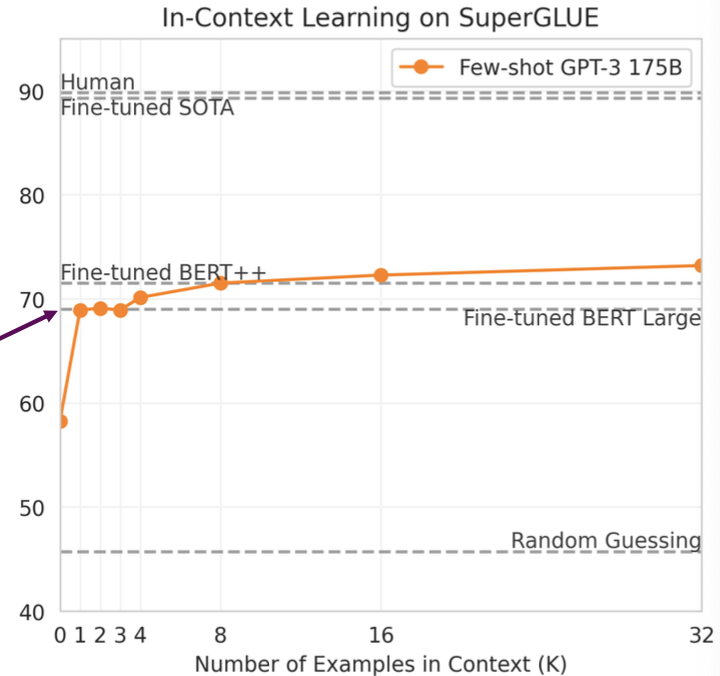
Zero-shot에서 단 하나의 예시만 포함되어도 성능이 많이 오르는 것을 확인할 수 있다.
Few-shot은 여러 예시를 포함한다.

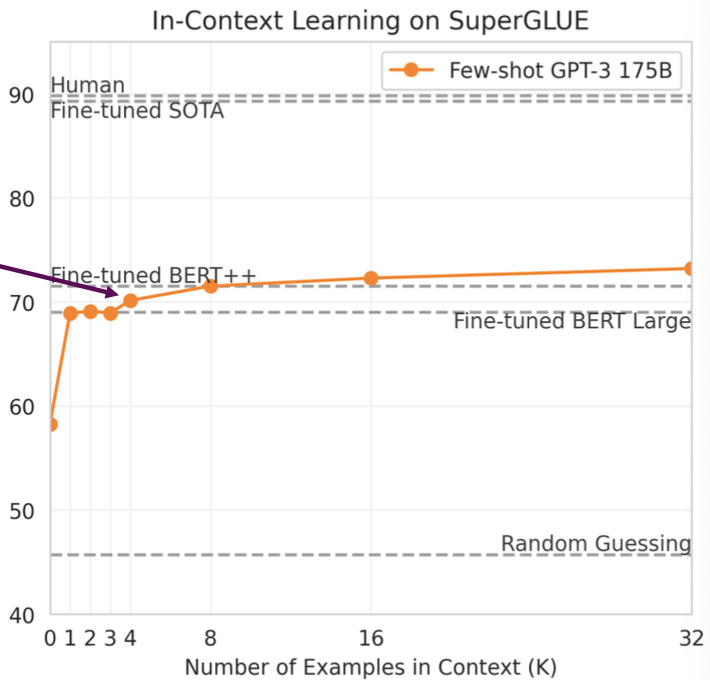
하나의 예시만 포함하는 one-shot은 2~3개의 예시를 포함했을 때와 성능 차이가 거의 없지만
예시가 4개 이상인 경우 성능이 예시 개수에 따라 우상향하는 것을 확인할 수 있다.
또한 단어 순서를 올바르게 정렬하는 태스크를 지정하고 모델에 100개의 예시를 제공했을 때
reversed words를 제외하면 모델의 파라미터가 많을수록 성능도 좋아지는 것을 확인할 수 있다.
Cycle letters: pleap -> apple
Random insertion: a.p!p/l!e -> apple
Reversed words: elppa -> apple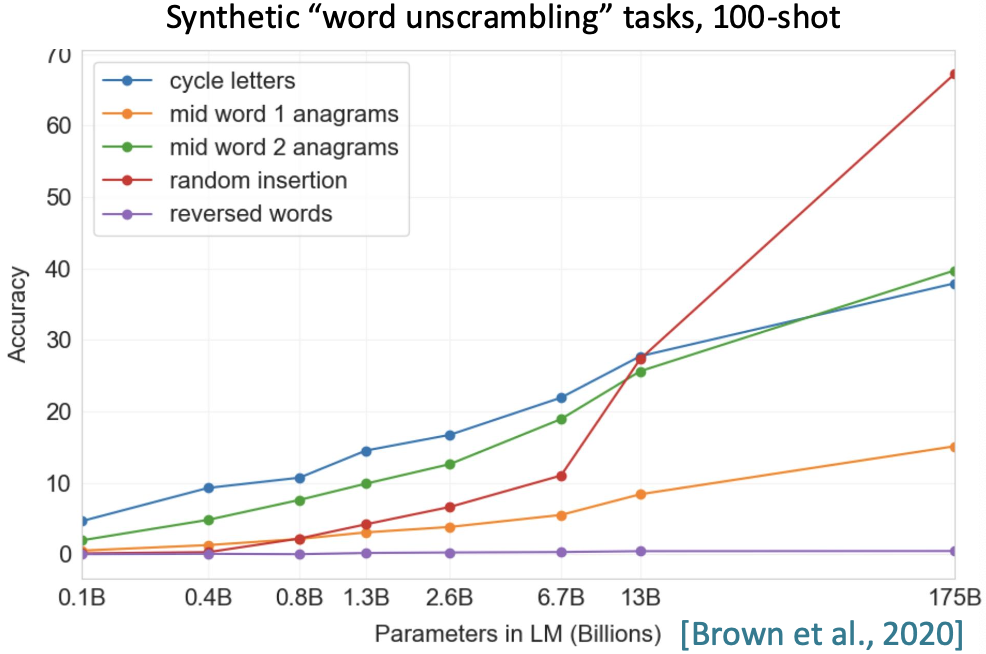
1. Prompting
전통적인 파인튜닝은 소량의 학습 데이터로 파라미터를 업데이트하는 방식이었다.

반면 few-shot learning은 파라미터 업데이트하여 학습하는 것이 아닌 모델이 프롬프트의 태스크 지시와 예시를 보고 배운다.

하지만 더 어려운 태스크에 대해선 프롬프트도 한계가 있지 않을까?
몇몇 태스크는 아무리 대규모 LM이라고 하더라도 프롬프트만으로 학습하기에 너무 어려울 것이다.
예를 들어 여러 단계를 거쳐야 하거나 다양한 지식과 맥락을 참고해야 하는 복합적인 추론의 경우 인간도 풀기 힘들 것이다.
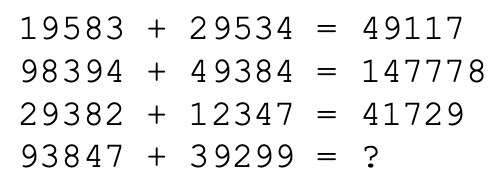
이럴 땐 프롬프트를 바꿔보자!
1) Chain-of-thought(CoT) prompting
Chain-of-thought prompting은 모델이 추론 과정을 단계별로 서술하도록 유도하는 프롬프트 기법이다.
기본적인 프롬프팅은 질문에 대한 답만을 제공했었다.

하지만 CoT prompting은 답을 추론하는 과정을 함께 제공함으로써 모델도 추론을 하도록 한다.

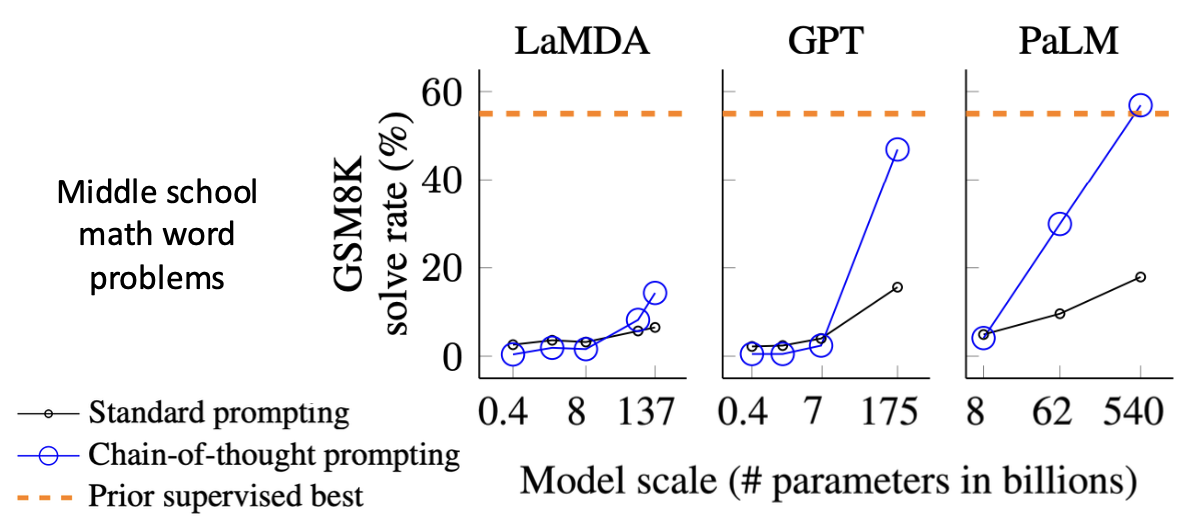
중학교 수학 단어 문제를 태스크로 LaMDA, GPT, PaLM 모델을 few-shot learning 했을 때
모델의 크기가 커질수록 CoT prompting의 성능도 좋아지는 것을 확인할 수 있다.
그렇다면 추론의 예시는 항상 필요할까?
모델이 추론을 하도록 요구할 수 있을까?
2) Zero-shot chain-of-thought prompting
Zero-shot CoT prompting은 추론을 유도하는 문구를 프롬프트에 함께 작성하여 모델이 중간 추론을 스스로 서술하도록 유도하는 방법이다.
태스크와 함께 "Let's think step by step." 같은 추론 유도 문구를 넣어주면 모델이 중간 추론과 함께 최종 답을 생성하는 방식이다.

Zero-shot CoT prompting은 일반 zero-shot보다 훨씬 뛰어난 성능을 보인다.
그럼에도 zero-shot CoT보다는 예시를 함께 제공하는 few-shot CoT가 더 좋은 성능을 보인다.

추론을 유도하는 문구는 다양하다.
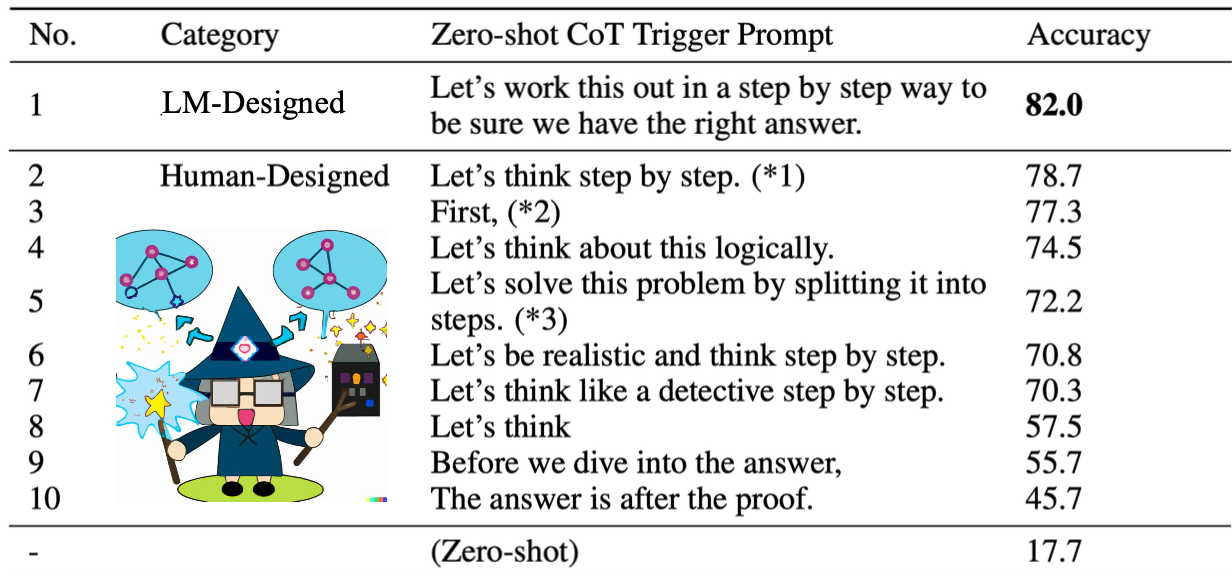
"Let's think step by step."은 인간이 만든 문구 중에서 가장 높은 성능을 보인다.
"Let's work this out in a step by step way to be sure we have the right answer."는 LM이 만든 문장이며 전체 문구 중 가장 높은 성능을 보인다.
하지만 이 문장들이 최고의 성능을 무조건 보장하는 것은 아니다.
위의 그림은 MultiArith라는 태스크로 한정했을 때의 성능이다.
다른 태스크에서는 다른 문장이 더 효과적일 수 있다는 것을 명심하자.
한편 프롬프트에 대해 모델이 얼마나 민감한지 그리고 일관성이 있는지에 대한 연구도 있다.
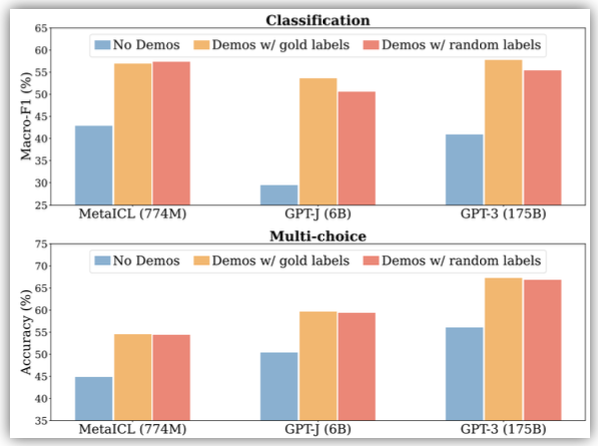
위 그림은 프롬프트에 따라 모델이 얼마나 민감한지를 평가한 실험이다.
No Demos는 프롬프트에 예시없이 단순히 질문만 있는 경우, Demos w/ gold labels는 프롬프트에 정답이 포함된 예시가 존재하는 경우, Demos w/ random labels는 프롬프트에 존재하는 예시에 틀린 레이블도 존재하는 경우이다.
그러니까 각 프롬프트 유형에 모델이 얼마나 의존하는지 측정한 것이다.
No Demos, 즉 프롬프트에 예시가 없는 경우는 다른 두 Demos 유형보다 성능이 낮은 것을 확인할 수 있다.
다시 말해 프롬프트에 예시가 없는 경우는 성능 향상에 큰 영향을 주지 못하는 것이다.
GPT-J와 GPT-3에서 정답 레이블 예시를 참고했을 때(Demos w/ gold labels)와 랜덤 레이블을 참고했을 때(Demos w/ random labels)의 성능이 비슷한 것을 볼 수 있다.
따라서 모델이 예시의 정답을 직접적으로 참고한기보다 질문-답변 형식이나 태스크 구조같은 예시 자체의 문맥적 패턴을 더 참고함을 알 수 있다.
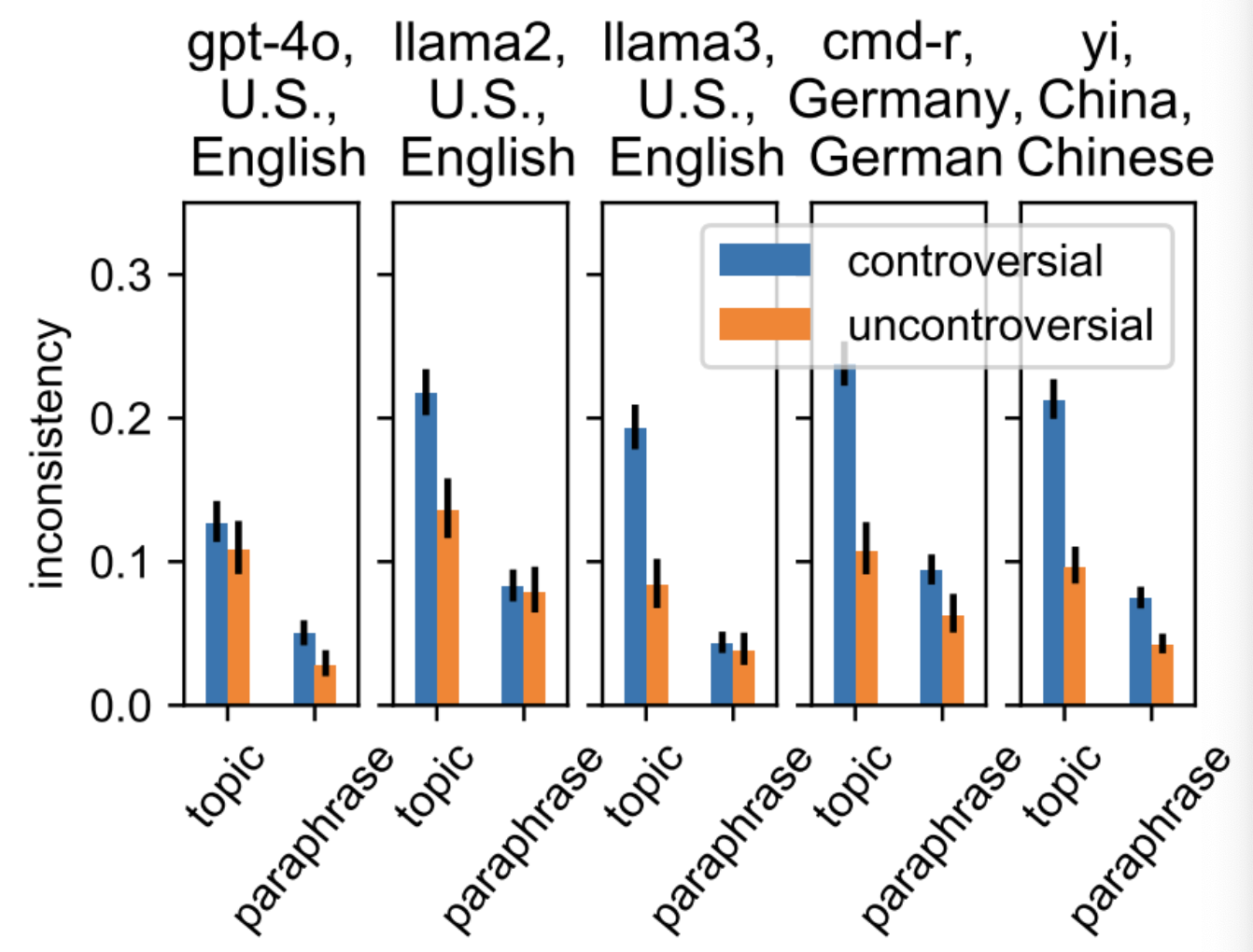
위 그림은 일관성에 대한 실험이다.
Topic은 같은 주제 내에서 질문이 달라지는 상황, paraphrase는 같은 질문을 다른 말로 표현하는 상황을 의미한다.
Controversial은 논란의 여지가 있는 질문, uncontroversial은 논란의 여지가 없는 질문이다.
예를 들어 topic의 controversial이 높다면 모델이 어떤 주제에 대해 논란있는 질문에 답변할 때 일관성이 없다는 뜻이다.
gpt-4o 모델은 다른 모델과 비교했을 때 topic에서 controversial과 uncontroversial의 차이도 적고 일관성 부족 수치도 가장 낮은 편이다.
따라서 gpt-4o 모델은 다른 모델들에 비해 어떤 주제에 대한 논란이 있는 질문과 논란이 없는 질문 모두에 대해 일관성이 있고 같은 질문을 다른 말로 표현한 질문에 대해서도 일관성이 있다는 것을 알 수 있다.
반면 cmd-r이나 yi같은 경우는 특히 어떤 주제의 논란이 있는 질문에 대해 일관성이 비교적 떨어지는 것을 확인할 수 있다.
3) Downside of prompt-based learning
프롬프트 기반으로 학습할 때 어떤 단점이 있는지 살펴보자.
-
Inefficiency: 프롬프트는 모델이 예측을 만들 때마다 처리되어야 한다.
-
Poor performance: 프롬프팅은 일반적으로 파인튜닝보다 성능이 더 안좋다.
-
Sensitivity: 프롬프트에 작성되는 워딩(예: 예시의 순서)에 따라 모델이 민감하게 반응할 수 있다.
-
Lack of clarity: 프롬프트로부터 모델이 무엇을 학습하는지 명료하지 않다. (랜덤 레이블 예시를 참고할 떄도 잘 작동한다.)
2. Introduction to PEFT
1) From fine-tuning to parameter efficient fine-tuning(PEFT)
Full Fine-tuning은 모델의 모든 파라미터를 업데이트하는 방식이다.
반면에 Parameter-efficient fine-tuning은 모델 파라미터의 작은 부분만 업데이트한다.
왜 파라미터의 일부만 파인튜닝하는 걸까?
-
모든 파라미터를 파인튜닝하는 것은 큰 모델에선 비현실적이다.
-
SoTA 모델의 파라미터는 과하게 많다.
하지만 파라미터 전체를 업데이트한 모델의 성능과 일부만 업데이트한 모델의 성능은 거의 비슷하다.
2) Why do we need efficient adaptation
현재의 AI 패러다임은 효율성을 넘어 정확성이 강조된다.
그래서 LLMs 학습과 파인튜닝에 소요되는 비용은 드러나지 않았다.
학습 비용이 커질수록 AI 개발은 산업계같이 투자를 많은 받은 조직에 집중될 것이다.
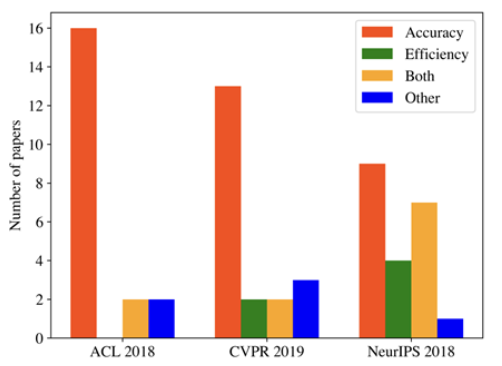
위 그림에서 확인할 수 있듯이 정확도 관련 논문이 탑 컨퍼런스의 큰 비중을 차지한다.
반면 효율성 관련 논문은 비중이 많이 낮은 편이다.
3) Different perspective to think about PEFT
PEFT를 바라보는 세 가지 관점이 있다.
파라미터 관점, 입력 관점, 함수 관점이다.
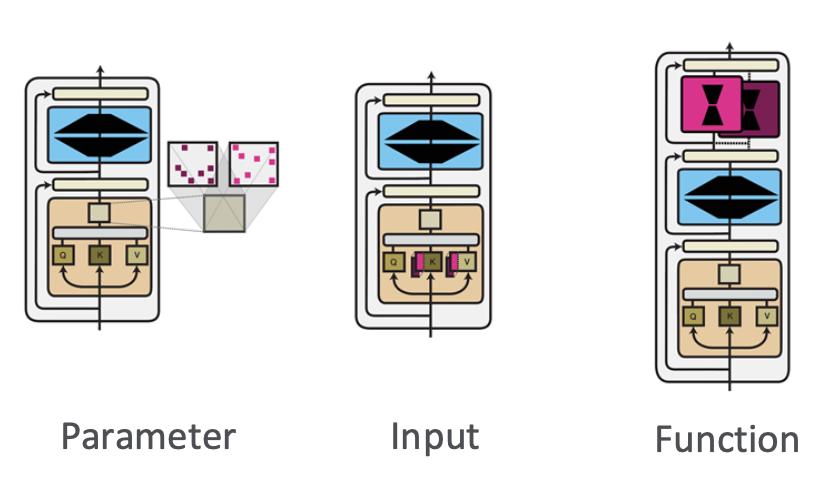
이 중 파라미터 관점에는 두 가지 접근 방식이 있다.
Sparse Subnetworks와 Low-rank Composition이다.
3. Pruning / subnetwork
1) Sparse subnetworks
레이어의 파라미터에 흔히 사용되는 귀납적 편향은 희소성이다.
이 말은 신경망의 모든 가중치가 중요한 것이 아니므로 일부 중요한 가중치만 남겨도 충분하다고 가정하는 것이다.
희소성을 만드는 가장 흔한 방법은 프루닝(Pruning)이다.
프루닝 의미는 수학적으로 파라미터 벡터 의 각 원소에 0 또는 1을 할당하는 마스크 를 곱하는 과정으로 볼 수 있다.
로 표현할 수 있는데 이면 가중치를 유지하고 이면 가중치를 제거한다.
프루닝을 통해 모델 안에 subnetwork를 생성할 수 있다.
2) Pruning
프루닝 과정에선 규모가 가장 작은 편에 속하는 가중치들의 일정 비율을 제거한다.
프루닝 후 제거되지 않은 가중치들은 다시 학습하여 성능을 보정한다.
한번에 많은 가중치를 제거하는 방식보다 프루닝을 여러번 수행하여 가중치를 조금씩 제거하고 학습하는 방식이 더 자주 사용된다.
이를 iterative pruning이라고 한다.
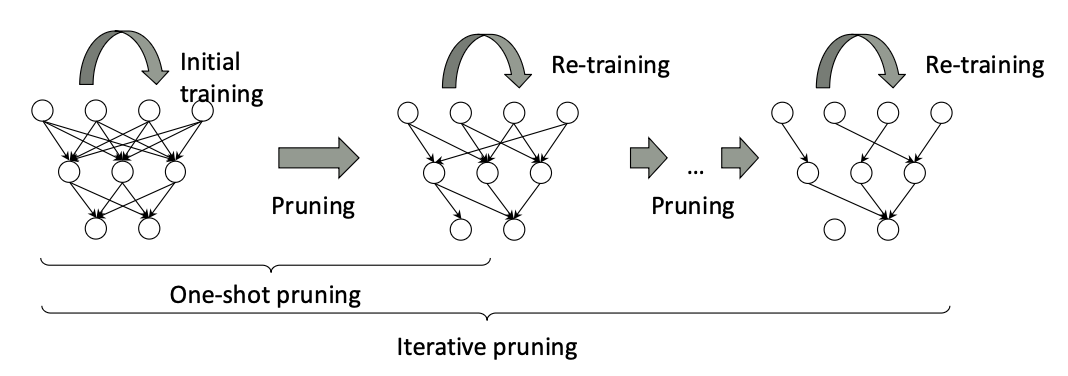
초기 학습 후 한번의 프루닝을 거치면서 가중치, 즉 노드 간 연결이 제거된 것을 확인할 수 있다.
이렇게 제거된 상태에서 다시 학습(Re-training)을 한다.
이 과정을 반복하면(iterative pruning) 맨 오른쪽 신경망처럼 중요한 가중치만 남게 된다.
프루닝은 기존 모델의 파라미터 에 태스크 특화 벡터 를 더하는 것으로 볼 수 있다.
이를 아래와 같이 표현할 수 있다.
최종 모델이 희소해야 한다면 기존 파라미터 에 binary mask 를 곱하여 프루닝된 가중치를 0으로 만들 수 있다.
로 표현할 수 있는데 이때 는 원소별 곱이다.
따라서 인 경우 가중치가 0이 되어 제거할 수 있다.
일반적인 프루닝은 최종 파라미터 에서 크기가 작은 것을 제거한다.
하지만 diff pruning은 태스크 특화 벡터 의 크기만 보고 프루닝한다.
여기서 잠깐!
우리는 지금 PEFT를 위한 접근 방식 중 파라미터 관점의 접근 방식인 sparse subnetworks에 사용되는 프루닝을 살펴보고 있다.
다시 말해 효율적인 파인튜닝을 위해 가중치의 일부만 업데이트하는 방법인 프루닝을 살펴보고 있는 것이다.
프루닝을 요약하자면
-
사전 학습 후의 가중치 에
-
태스크 데이터로 학습된 가중치 를 더하여
-
새로운 가중치 벡터를 만들고
-
이 벡터에서 작은 가중치는 제거
하여 일부 파라미터만 업데이트함으로써 효율적인 파인튜닝을 하겠다는 것이다.
이때 태스크 데이터로 학습된 가중치 만 보고 작은 가중치를 제거하는 방식이 diff pruning인 것이다.
3) The Lottery Ticket Hypothesis
무작위로 초기화된 밀집 모델엔 원래의 네트워크와 비슷한 정확도를 달성할 수 있는 작은 서브네트워크(당첨 티켓)가 들어있다는 가설이다.
이 현상은 RL이나 NLP뿐만 아니라 큰 CV 모델에서도 발견되었다.
또한 BERT같은 사전 학습 모델에서도 당첨 티켓이 발견되면서 무작위로 초기화된 모델뿐만 아니라 이미 학습된 모델에서도 서브네트워크를 추출할 수 있음이 밝혀졌다.
Masked language modeling같은 범용적인 태스크에서 학습된 서브네트워크가 전이(transfer)에 가장 효과적이었다.
정리하면 큰 모델 속에는 작은 네트워크가 숨어 있는데 이 서브네트워크만으로도 전체 모델과 같은 성능을 낼 수 있다는 가설이다.
4) Pruning Pre-trained Models
magnitude pruning은 0에서 가장 멀리 떨어진 가중치를 살린다는 기준을 갖고 있다.
파인튜닝 후의 최종 가중치 상태만 보는 것이다.
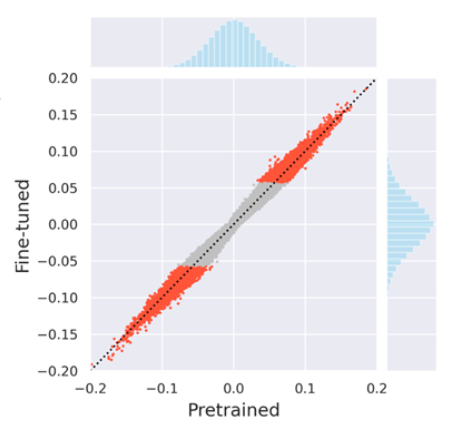
위의 그래프를 보면 대부분의 가중치가 사전 학습 값(검은색 대각선) 주변에 머물러 있다.
여기서 파인튜닝 가중치의 절대값이 가장 큰 것, 즉 0에서 음으로 양으로 멀리 떨어진 값인 빨간 점만 살린다.
하지만 파인튜닝 동안 가중치가 얼마나 많이 변했는지도 중요할 수 있다.
이를 고려하는 방식이 movement pruning이다.
Movement pruning은 0에서부터 가장 많이 움직인 가중치를 살린다는 기준을 갖는다.
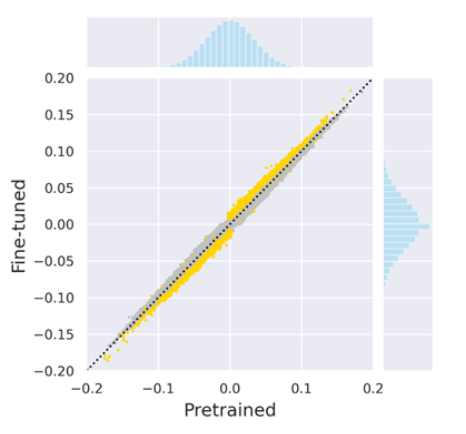
는 사전 학습 후의 파라미터, 는 파인튜닝 후의 파라미터이다.
라면 파인튜닝 후에 만큼 움직였음을 의미한다.
이는 만큼 0에서 멀어졌음을 의미하므로 가중치를 살린다는 의미로 노란점으로 표현하였다.
반면에 이라면 파인튜닝 후에 만큼 움직였음을 의미한다.
이는 만큼 0에 가까워졌음을 의미하므로 가중치를 제거한다는 의미로 회색점으로 표현하였다.
4. LoRA
PEFT를 위한 파라미터 관점의 접근 방식엔 sparse subnetworks와 low-rank composition가 있다고 했다.
이제 low-rank composition을 살펴보자.
그 전에 full fine-tuning을 다시 떠올려보자.
먼저 사전 학습된 자기회귀 언어 모델 가 있다고 생각해보자.
이 사전 학습 모델을 요약이나 NL2SQL, 독해 등 하위 태스크로 적응시킬 때 파인튜닝을 수행한다.
이때 사용되는 학습 데이터는 context()와 target() 쌍인 이다.
Full fine-tuning은 아래와 같은 최적화 식을 따른다.
입력 와 이전 스텝의 토큰 를 조건으로 현재 스텝 의 토큰 를 예측한다.
예측은 어휘 전체 집합에 대한 확률 분포이며 각 어휘가 다음 토큰일 확률을 가지고 있다.
학습 데이터는 형식, 즉 정답이 주어진 지도 학습 데이터이므로 정답 토큰 를 확률 분포에서 꺼내와서 이 정답 토큰이 나올 확률을 최대화한다.
이 확률을 최대화하기 위해 계산된 그래디언트에 따라 파라미터 를 로 업데이트한다.
이때 Full fine-tuning이므로 파라미터 전체가 업데이트된다.
1) LoRA: low rank adaptation
Full fine-tuning의 한계점은 무엇일까?
바로 파라미터 전체를 업데이트한다는 점일 것이다.
하위 태스크마다 새로운 파라미터 집합 를 학습해야 하는데 이때 원래의 모델()과 동일한 크기의 파라미터()를 학습해야 한다.
GPT-3의 경우 1,750억개의 파라미터가 존재하는데 1,750억개의 파라미터를 또 학습한다?
심지어 태스크 하나당 1,750억개의 파라미터인데 여러 태스크를 파인튜닝한다면?
학습 비용, 저장 공간 등 비용이 어마어마하다.
그래서 더 작은 사이즈의 파라미터 집합 를 최적화하도록 를 로 인코딩하자.
그러면 새로운 파라미터 크기 는 원래 모델의 파라미터 크기()보다 작을 것이다.
이제 최적화 식은 작은 차원의 파라미터 를 업데이트한다.
사전 학습된 LM의 파라미터 는 절대 건드리지 않는다.
랭크(rank)를 알아보자.
랭크란 선형독립인 열벡터의 개수 또는 행벡터의 개수, 즉 어떤 행렬이 가지는 독립적인 패턴의 개수이다.
예를 들어 어떤 행 가 이고 는 라면 이므로 똑같은 패턴을 가지므로 와 는 독립적인 패턴이 아니다.
큰 행렬 안에는 예시처럼 중복된 정보가 많다.
그래서 중복 패턴을 제거하여 독립적인 패턴만 남기면 차원이 축소된다.
이렇게 차원이 축소되어 랭크가 작아진 행렬을 low rank 행렬이라고 한다.
이 low rank가 작은 차원의 파라미터를 만들어내기 위한 방법이다.
파라미터가 어떻게 업데이트되는지 살펴보자.
파인튜닝 중에 파라미터 업데이트는 낮은 내재적 랭크(low intrinsic rank)를 갖는다.
이는 파라미터가 업데이트될 때 고차원의 전체 공간을 다 쓰는 것이 아니라 저차원의 잠재 공간을 사용한다는 말이다.
가 full-rank 행렬, 즉 모든 패턴이 중복없이 독립적일 가능성이 있긴 하지만 실제로는 몇 개의 독립 패턴만으로 설명가능하다는 것이다.
가 사전 학습된 가중치 행렬이라고 할 때 full fine-tuning 후 가중치 는 이다.
하지만 LoRA에서는 low rank로 분해하도록 한다.
아래의 식을 살펴보자.
를 low rank로 분해한 것을 확인할 수 있다.
여기서 은 랭크이며 는 사전 학습 지식과 태스크 지식 사이의 균형 역할을 한다.
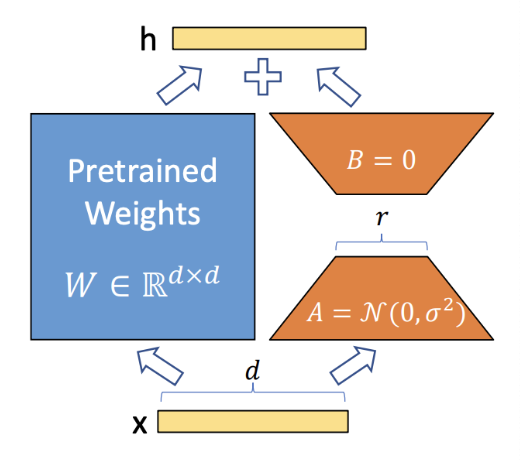
위 그림의 좌측인 사전 학습 파라미터는 건들지 않고 우측인 low rank 행렬을 학습하고 두 행렬을 합한다.
정리해보자.
Full fine-tuning은 비용이 너무 크므로 작은 차원의 행렬을 만들고 이 파라미터를 최적화하여 파인튜닝하는 접근 방법을 소개했다.
작은 차원의 파라미터를 만들 때 low rank로 분해하는 방법을 사용한다.
이를 low rank를 이용한 adaptation, 줄여서 LoRA로 부른다.
LoRA의 특징을 살펴보자.
-
랭크 을 늘리면 학습 가능한 파라미터 수가 늘어나는데 이 파라미터 수가 계속 늘어나면 원래의 파라미터 수에 수렴, 즉
full fine-tuning에 가까워진다. -
태스크를 바꾸고자 할 때 단순히 모듈만 교체하면 된다.
학습 후 모델의 파라미터 는 이고 가 모듈이다.
모듈 로 바꾸고자 한다면 단순히 모듈 를 로 바꾸면 된다.
베이스 모델 는 공유하고 모듈만 교체하면 되므로 여러 태스크를 한 모델에서 빠르게 바꿔서 사용할 수 있다.
-
LoRA는 주로self-attention모듈에 적용된다.트랜스포머 베이스 모델 는 그대로 두고
self-attention의query,key,value,output행렬 만 바꿔 끼우면 간단하다.
LoRA를 간단히 구현해보자.
input_dim = 768 # 사전 학습 모델의 은닉 상태 크기
output_dim = 768 # 레이어의 출력 크기
rank = 8 # 랭크 수
W = ... # input_dim x output_dim 크기의 사전 학습 파라미터 (파인튜닝 때 건들지 않음)
# 파인튜닝 떄 학습할 파라미터
W_A = nn.Parameter(torch.empty(input_dim, rank)) # LoRA 파라미터 A
W_B = nn.Parameter(torch.empty(rank, output_dim)) # LoRA 파라미터 B
# LoRA 파라미터 초기화
nn.init.kaiming_uniform_(W_A, a=math.sqrt(5)) # 작은 난수로 초기화
nn.init.zeros_(W_B) # 0으로 초기화 -> 파인튜닝 시작 때 LoRA가 영향을 미치지 않도록
def regular_forward_matmul(x, W):
h = x @ W
return h
# LoRA를 사용한 순방향 패스
def lora_forward_matmul(x, W_A, W_B):
h = x @ W # 입력 x와 사전 학습 파라미터 행렬곱
h += x @ (W_A @ W_B)*alpha # 사전 학습 파라미터에 파인튜닝 파라미터 덧셈
return h이 코드에 파인튜닝을 수행하는 코드는 없지만 LoRA를 어떻게 적용되는지는 알 수 있다.
-
파인튜닝에 사용될 파라미터 를 초기화
-
파인튜닝
-
사전 학습 파라미터 와 파인튜닝 파라미터 덧셈
실전에서 LoRA는 어떨까?
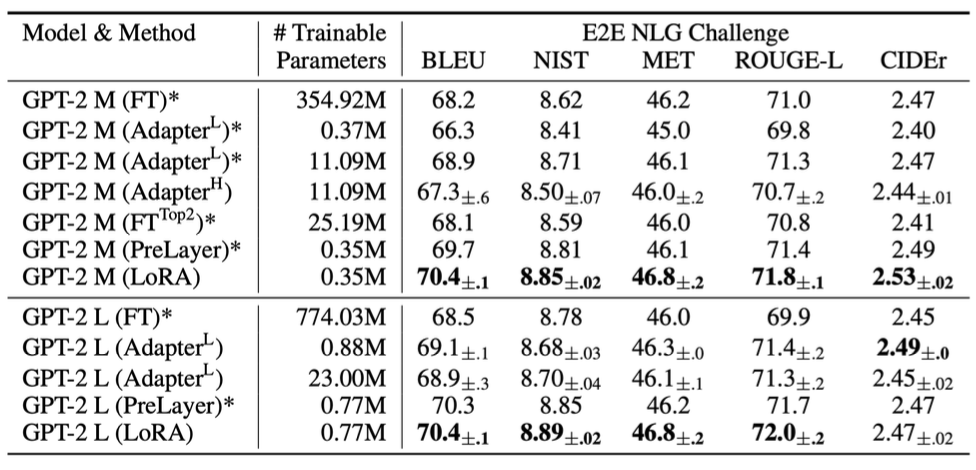
위 그림은 GPT-2 Medium, GPT-3 Large를 E2E NLG Challenge 태스크에 대해 여러 적응 방식을 적용한 테스트 결과이다.
모든 지표에서 숫자가 높을수록 성능이 좋다는 것을 의미한다.
결과를 살펴보면 LoRA는 학습 가능한 파라미터가 다른 모델보다 더 적거나 비슷함에도 성능은 가장 뛰어나다.
GPT-3같이 스케일이 큰 모델은 어떨까?
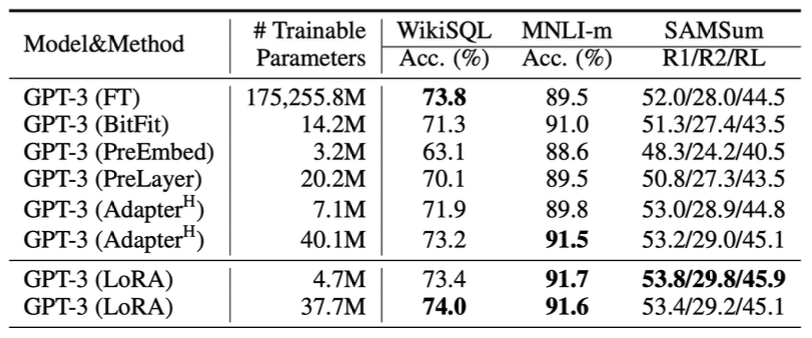
LoRA는 WikiSQL, MNLI-m, SAMSum 등 세 가지 데이터셋 모두에서 파인튜닝 성능이 가장 높다.
특히 WikiSQL에서 1,750억개의 파라미터를 학습한 GPT-3보다 훨씬 적은 3,700만개의 파라미터만 학습하였음에도 성능은 더 높다.
또한 LoRA는 다른 모델보다 더 나은 확장성과 태스크 성능을 보인다.
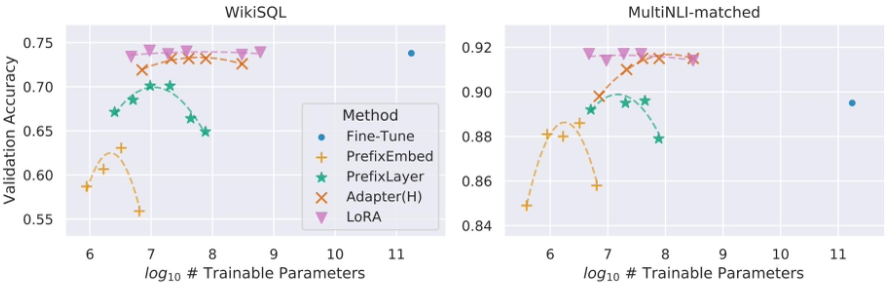
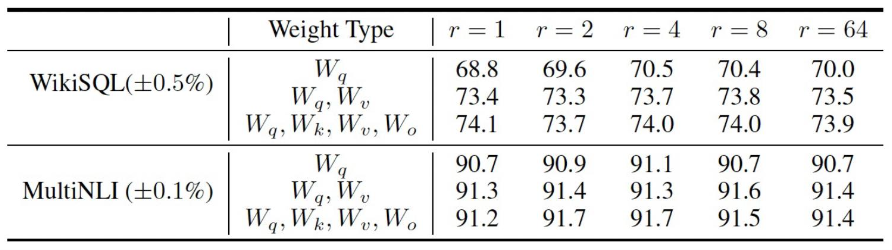
트랜스포머의 query, key, value, output 중 어떤 가중치 행렬에 LoRA에 적용하는 것이 좋을까?
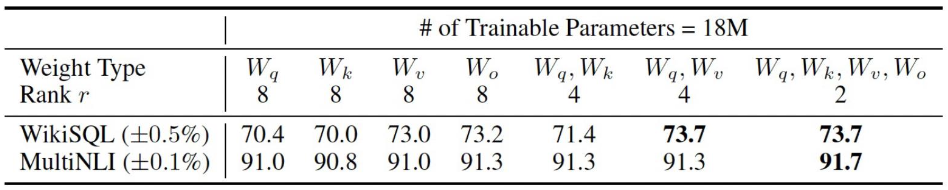
위 표를 살펴보면 에 대해 rank가 일 때, 즉 query, key, value, output 모두에 인 LoRA를 적용했을 때 각 벤치마크에 대해 성능이 73.7, 91.7로 가장 높은 것을 확인할 수 있다.
하지만 WikiSQL 벤치마크에 대해서 에만 를 적용했을 때의 성능도 73.7이다.
전반적으로 두 가중치 행렬 에 LoRA를 적용했을 때 좋은 성능을 보인다.
그렇다면 LoRA에서 최적의 rank 은 어떤 값일까?
특정 가중치 행렬에 대해 의 값을 늘려가며 성능을 측정한 결과이다.
이 클수록 가중치 행렬에서 표현할 수 있는 차원이 늘어나므로 더 많은 패턴을 담을 수 있으니까 성능이 엄청 올라갈 거라는 생각이 들었지만 결과는 아니었다.
아주 작은 값으로도 경쟁력있는 성능을 보여준다.
2) From LoRA to QLoRA
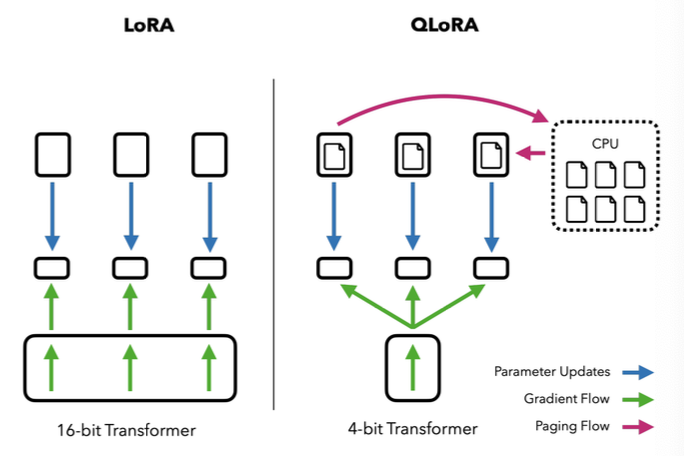
LoRA도 학습 파라미터 수를 많이 줄여 GPU 메모리 효율이 높아 다양한 태스크에 효율적인 파인 튜닝이 가능했다.
하지만 사전 학습 모델의 파라미터는 학습이 없어도 full precision(16/32-bit) 상태로 GPU 메모리에 존재하므로 대규모 모델일수록 메모리 부담이 크다.
QLoRA는 LoRA의 장점을 그대로 가지면서 사전 학습 모델을 4-bit precision으로 양자화하여 메모리 부담을 줄인다.
또한 GPU 메모리만 사용하는 대신 CPU 메모리와 GPU 메모리 간 교환을 최적화하여 GPU VRAM이 부족해도 안정적인 학습이 가능하다.
4-bit NormalFloat(NF4)란 QLoRA에서 도입한 새로운 데이터 타입으로 가중치가 정규분포를 따른다는 특성을 활용한다.
정규분포를 따르는 실수값을 4-bit로 표현할 때 최적인 방식으로 성능의 손실을 최소화할 수 있다.
5. Prompt tuning
1) Prefix-Tuning
Prefix 파라미터는 말그대로 접두사처럼 사전 학습 파라미터 앞에 붙어 태스크 데이터를 학습하는 파라미터이다.
각 트랜스포머 레이어의 self-attention 모듈에 prefix 파라미터를 추가한다.
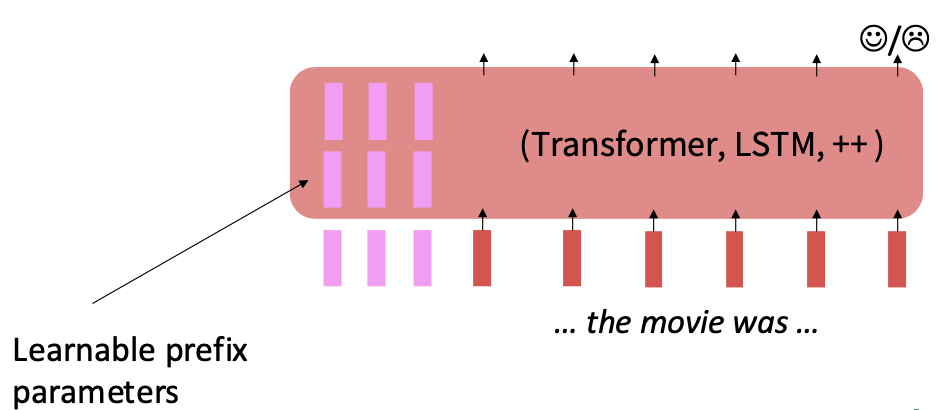
Prefix-Tuning은 사전 학습 파라미터는 고정하고 파인튜닝 때 prefix 파라미터만 학습하는 효율적인 파인튜닝 방법이다.
파인튜닝 데이터로 학습을 할 때 입력 앞에 prefix를 붙이는데, prefix란 실제 단어 임베딩은 아닌 가상의 임베딩이지만 모델은 이것을 실제 단어처럼 처리한다.
예를 들어 입력이 [Carolina, likes, listening, to, music}]일 때
prefix-tuning에서는 [p1, p2, ..., pk, Carolina, likes, listening, to, music}]이 된다.
여기서 virtual tokens라 불리는 [{p1, p2, ..., pk}]도 attention에 사용된다.
Self-attention은 문장의 토큰이 다른 토큰과의 어떤 연관성을 가지는지를 계산하는 과정이다.
Prefix-tuning에서는 virtual tokens인 prefix와의 연관성도 계산하고 파라미터를 업데이트 할 땐 prefix 파라미터를 업데이트한다.
이를 통해 사전 학습 파라미터를 업데이트하지 않고도 모델을 특정 태스크에 적응시킬 수 있다.
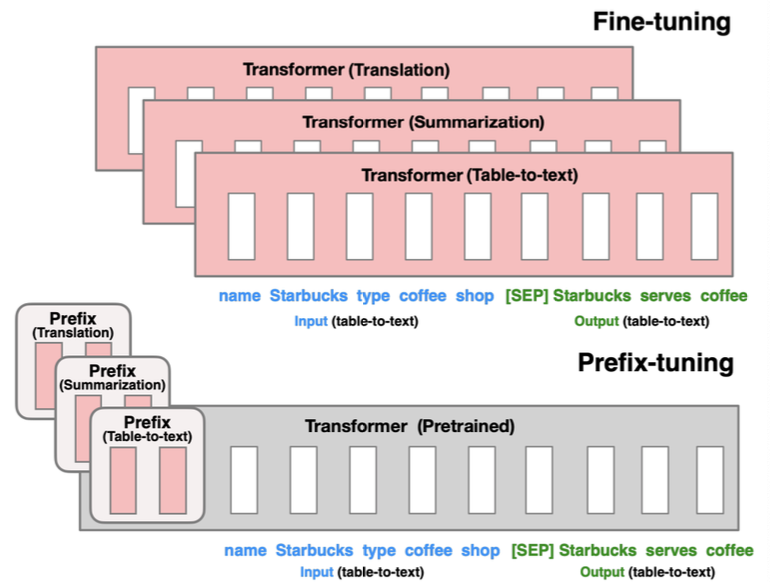
위 그림처럼 모델의 본체, 즉 사전 학습 파라미터는 고정하고 prefix 파라미터만 바꿔 끼우면 이 파라미터에 맞게 태스크 적응이 되는 것이 prefix-tuning의 장점이다.
2) Prompt-Tuning
Prompt tuning은 prefix tuning과 유사하다.
Prefix tuning은 각 트랜스포머 레이어의 self attention 모듈의 K, V에 학습 가능한 파라미터를 붙였었다.
반면에 prompt tuning은 트랜스포머 내부가 아닌 외부에 학습 가능한 파라미터를 만들고 이 파라미터가 학습된다.
지금까지 살펴본 튜닝 접근 방식을 아래의 그림으로 표현할 수 있다.
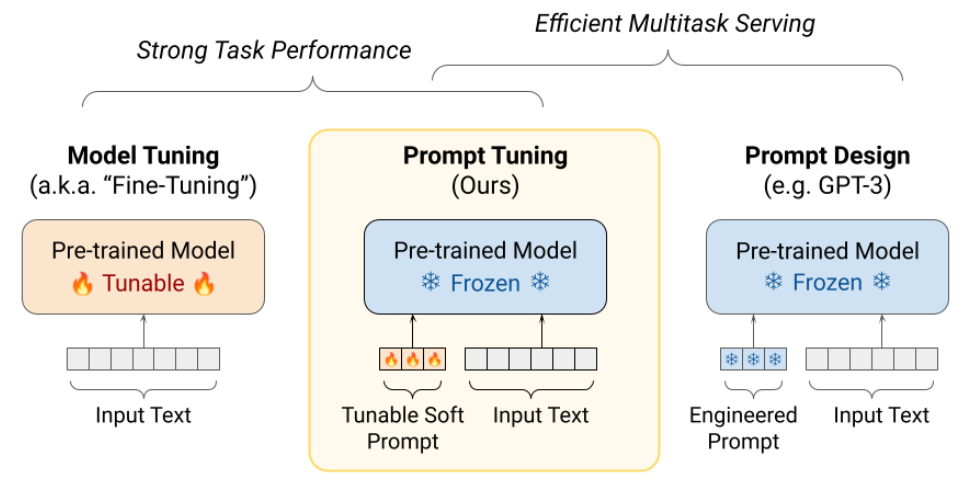
Model tuning은 전통적인 파인튜닝 방식이며 사전 학습 파라미터를 직접 튜닝한다.
이 방식은 성능은 좋지만 태스크마다 모델을 새로 학습해야 하므로 파라미터 크기가 클 경우 더욱 비효율적이다.
가장 우측의 prompt design(in-context learning)은 사전 학습 파라미터는 고정하고 사람이 작성한 프롬프트를 바탕으로 태스크를 수행하게 하는 방식이다.
프롬프트의 질에 성능이 좌우되며 파라미터 업데이트는 없다.
Prompt tuning은 사전 학습 파라미터는 고정하고 virtual tokens를 입력에 붙이는 방식으로 튜닝 시 이 virtual token embeddings만 학습된다.
파라미터 효율적이고 여러 태스크에 쉽게 적용이 가능하다는 장점이 있다.
Prompt tuning은 모델 크기가 클수록 성능이 좋다.
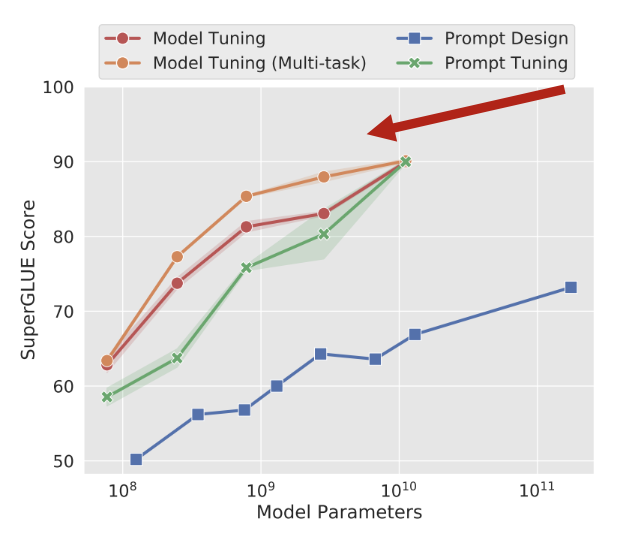
작은 크기의 모델의 경우 full fine-tuning 방식(Model Tuning, Model Tuning(Multi-task))이 성능이 더 좋다.
하지만 모델의 크기가 커질수록 prompt tuning의 성능이 full fine-tuning의 성능과 근접하는 것을 확인할 수 있다.
어마어마한 양의 파라미터 전체를 학습한 모델의 성능과 이보다 훨씬 적은 파라미터만 학습한 모델의 성능이 비슷하므로 prompt tuning 역시 하위 태스크로의 효율적인 적응 방법이다.
6. Adapters
함수 관점에서 태스크 적응을 살펴보자.
태스크 특화 모델 는 로 표현할 수 있다.
이때 는 원본 모델 함수(사전 학습 모델), 는 태스크 에 특화된 함수로 볼 수 있다.
은 함수의 결합 연산 중 하나로 어떤 방식을 쓰느냐에 따라 다르다.
다시 말해 태스크 특화 모델은 원본 모델의 기능에 태스크 특화 기능을 더한다는 것이다.
이 방식은 특히 multi-task learning에서 자주 사용되는데 태스크별로 모듈 를 만들어 두면 이 모듈만 바꿔가며 태스크 특화 모델을 사용할 수 있기 때문이다.
1) Adapters
사전 학습 모델의 파라미터()는 고정하고 모델의 레이어 사이에 학습 가능한 모듈()을 삽입하여 하위 태스크에 적응하는 방식에서 학습 가능한 모듈을 adapter라고 한다.
Adapter를 트랜스포머 레이어 안에 넣을 땐 아래와 같이 구성된다.
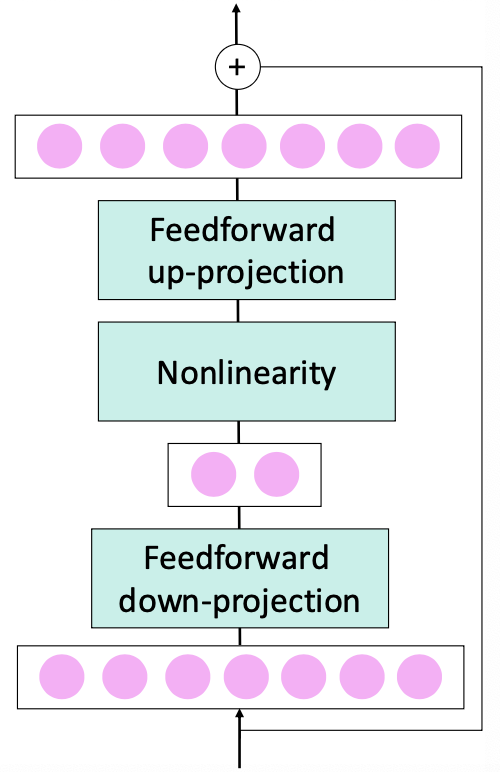
-
Feedforward down-projection: 먼저 입력 차원 를 작은 차원 로 줄인다.
를 입력 와 곱한다.
-
Nonlinearity: 비선형성 적용을 위해 비선형 함수 에 입력한다.
-
Feedforward up-projection: 줄인 차원 를 다시 원래 차원 로 복원한다.
를 곱한다.
정리하면 adapter는 아래와 같이 표현된다.
그리고 adapter는 residul connection으로 입력 와 더해진다.
참고로 여기서 입력 는 모델 입력이 사전 학습 모델을 거친 상태, 즉 은닉 상태를 의미한다.
이렇게 adapter를 사용하면 학습해야 하는 파라미터 수가 수준으로 줄어든다.
반면에 full fine-tuning은 이다.
Adapter는 보통 multi-head attention 뒤나 feed-forward layer 뒤에 추가된다.
각 레이어마다 task-specific bias를 주기 위함이다.
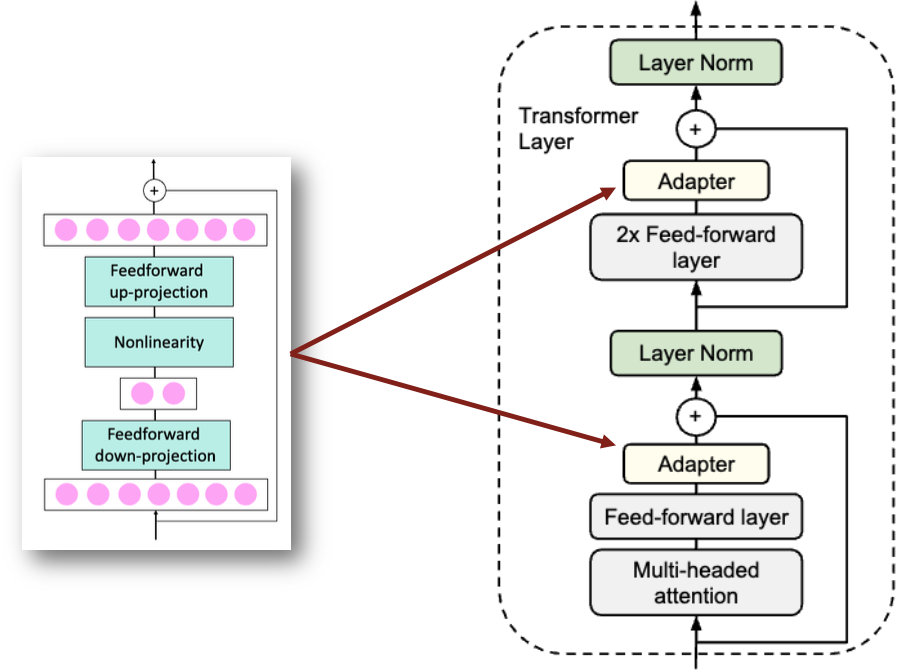
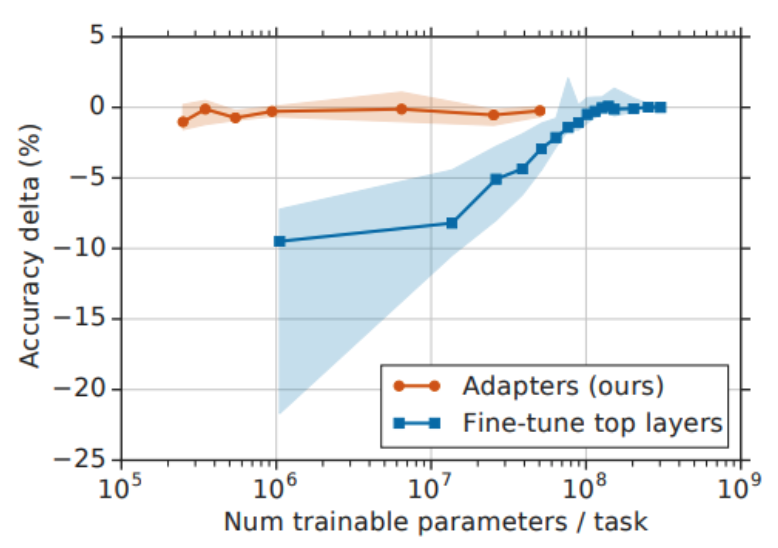
위 그래프는 GLUE 벤치마크의 9개 태스크에 대해 adapter만 학습했을 때(주황)와 상위 몇개의 레이어만 학습했을 때(파랑)의 성능 분포를 비교를 보여준다.
y축의 accuracy delta는 full fine-tuning 대비 성능 차이이다.
그러니까 이라는 건 full fine-tuning과 성능 차이가 없다는 것이다.
adapter를 사용했을 때는 학습 파라미터 수가 수준만 되어도 full fine-tuning과 차이가 없음을 확인할 수 있다.
반면에 fine-tune top layers의 경우 학습 파라미터 수가 수준은 되어야 full fine-tuning과 성능이 비슷하다.
태스크를 언어인 경우는 어떨까?
Adapter는 원본 모델이 태스크나 언어에 더 적합해지도록 하는 변화를 학습한다.
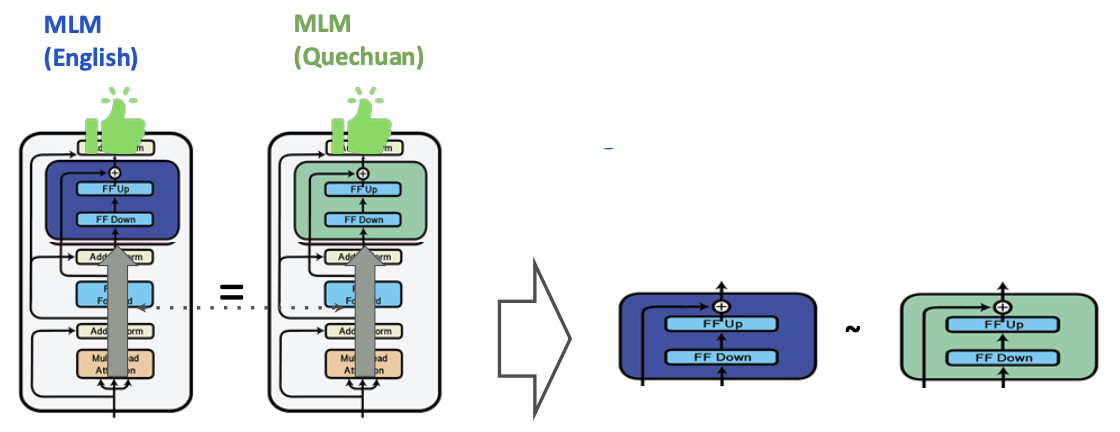
Masked language modeling(MLM)을 이용하여 언어에 특화된 변화(예를 들어 영어에서 케추아어로)를 학습할 수 있다.
영어 방언 적응을 위한 adapter를 사용하는 것도 비슷한 방식이다.
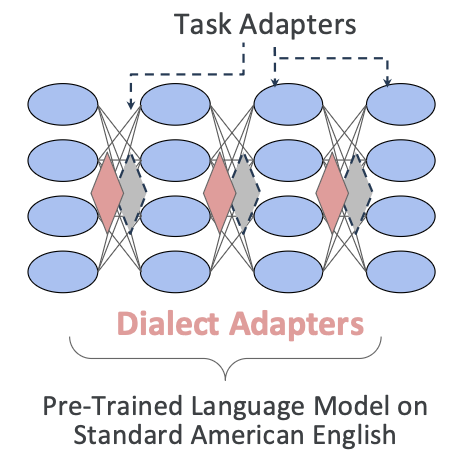
표준 미국 영어로 학습된 사전 학습 언어 모델에 방언을 학습한 adapter를 연결하면 된다.
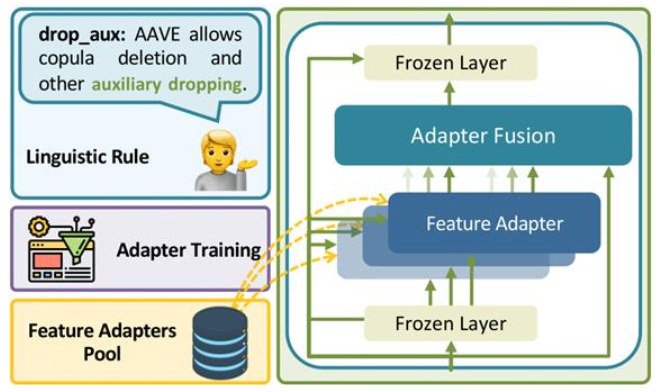
그럼 여러 태스크에 적응하려면 어떻게 해야 할까?
예를 들어 모델을 보조 동사를 탈락시키는 언어 규칙을 반영한 요약으로 적응시키려면 특정 언어 규칙을 따르는 태스크 adapter와 요약 태스크 adapter가 필요할 것이다.
이때 adapter fusion을 이용하면 된다.
Feature Adapters Pool에 특정 태스크나 특징을 학습한 별도의 adapter를 모아놓고 Feture Adapter에서 필요한 adapter를 불러와서 결합(fusion)하여 여러 adapter를 동시에 사용할 수 있다.
2) Unifying View
He et al. [2022]은 LoRA, prefix tuning, adapters가 유사한 함수 형태로 표현될 수 있음을 보였다.
세가지 방법 모두 모델의 hidden representation 에 작은 변화를 주어 표현할 수 있다.
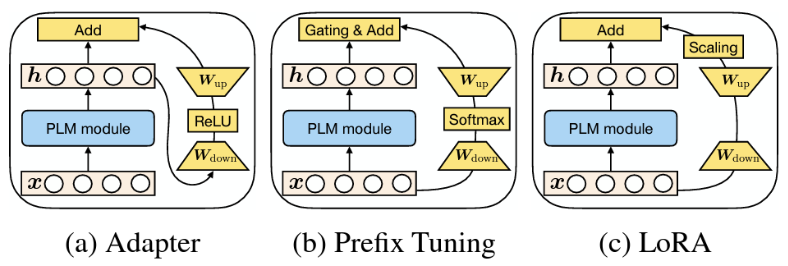
먼저 adapter의 경우 원본 모델 출력이 down-projection , nonlinearity , up-projection 를 거쳐 residual connection되는 것을 확인할 수 있다.
Prefix tuning의 경우 입력 문장 가 모듈에 입력되는 것처럼 보이지만 실제로 입력되는 건 virtual tokens이다.
각 트랜스포머 레이어의 self-attention의 K, V에 prefix 파라미터를 붙여야 한다.
따라서 모듈은 prefix 파라미터인 를 만들어 원래 문장의 에 붙인 뒤 이를 softmax에 넣어 attention score를 계산한다.
그리고 이 결과를 원본 모델 출력과 더하는데 이 과정이 gating & add이다.
LoRA는 모델 입력 를 새로운 가중치 행렬에 통과시켜 low rank로 분해한 뒤 scaling factor 를 곱하여 원본 모델 출력과 더한다.
이외에도 희소성, 구조, low rank 근사, 리스케일링 등의 속성 또한 적용되고 조합될 수 있다고 주장하였다.
3) Performance comparison
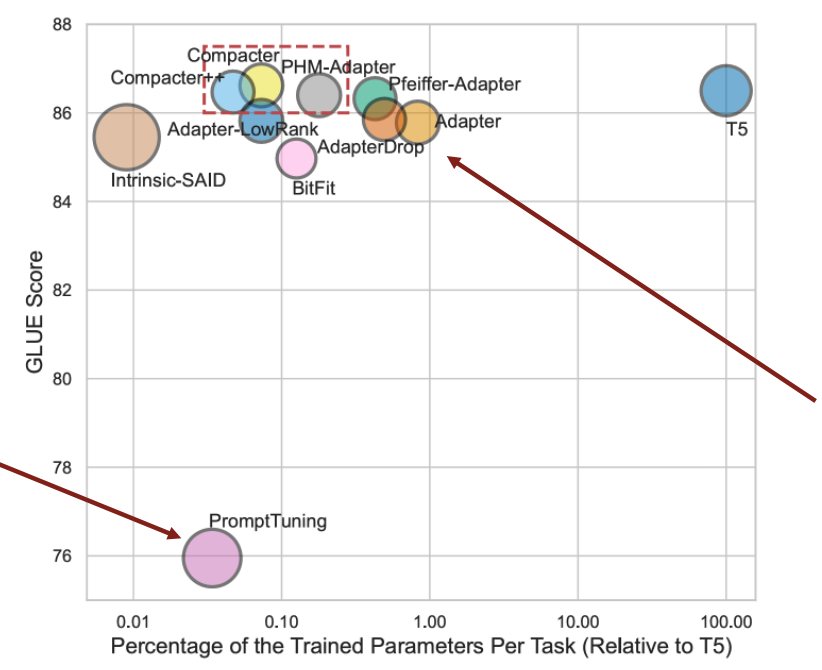
x축은 학습 파라미터의 크기, y축은 GLUE Score를 의미한다.
Prompt tuning은 학습 파라미터 수는 가장 작은 편에 속하지만 성능이 다른 방식에 비해 낮다.
이는 capacity에 한계가 존재하기 때문이다.
Adapter는 prompt tuning보다 성능이 더 좋지만 많은 파라미터를 학습해야 한다.
하지만 T5같은 full fine-tuning 모델보다 파라미터를 훨씬 적게 쓰고도 비슷한 성능을 달성했다.
7. Other adaptation methods
앞서 설명한 적응 방법 외에도 다양한 효율적인 적응 방법들이 존재한다.
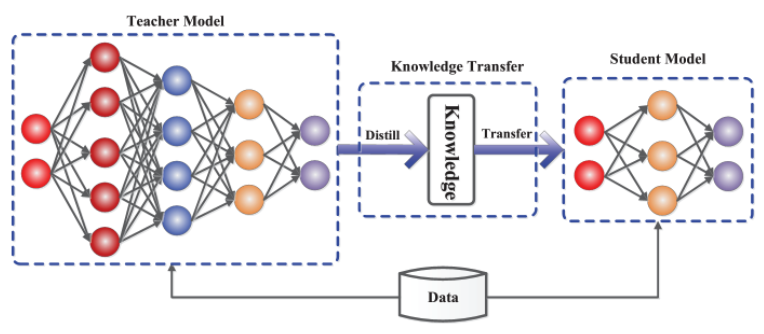
Knowledge Distillation(지식 증류)는 큰 모델(teacher model)의 지식을 작은 모델(student model)로 전이하는 방법이다.
Teacher model이 데이터에 대해 예측한 레이블, 은닉 상태 등을 생성하면 knowledge transfer 단계에서 student model이 이를 학습한다.
Student model은 teacher model과 비슷한 성능을 유지하면서도 파라미터가 훨씩 적어서 추론 속도나 메모리 효율성을 높일 수 있다.
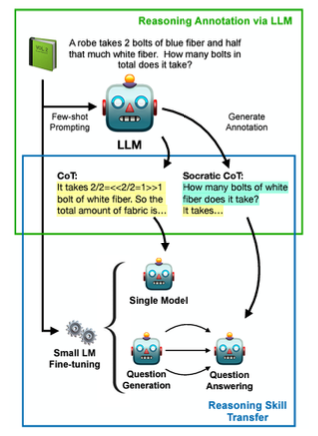
Reasoning Skill Transfer는 LLM이 생성한 annotation을 더 작은 모델이 학습하는 방식이다.
LLM이 few-shot prompting으로 문제를 풀고 CoT나 Socratic CoT같은 reasoning annotation을 생성하게 한다.
그 다음 문제와 annotation을 더 작은 모델에 전달하고 작은 모델은 질문 생성과 답변을 반복하여 추론 능력을 습득한다.
이 과정을 통해 작은 모델도 추론 능력을 일부 획득하게 되어 성능을 개선함과 동시에 효율성을 가질 수 있다.
이외에도 긴 문맥을 다루기 위해 입력을 요약하는 gist 토큰을 생성하여 메모리와 계산량을 절약하는 Gist Tokens, 외부에서 지식을 검색하는 방법과 요약 토큰 활용을 결합한 Retrieval-enhanced Fine-Tuning(ReFT) 등의 방법이 있다.
