
1. 워드 임베딩이란?
워드 임베딩이라는 밀집 단어 벡터를 사용하여 단어와 벡터를 연관 지을 수 있다.
원-핫 인코딩으로 만든 벡터는 대부분 0으로 채워져 희소(sparse)하고 고차원(word_index 크기와 차원이 같다)이다. 반면에 워드 임베딩은 밀집된(희소하지 않은) 저차원의 실수형 벡터이다. 원-핫 인코딩으로 얻은 단어 벡터와 달리 워드 임베딩은 데이터로부터 학습된다.
워드 임베딩의 특징이자 원-핫 인코딩 방식과 가장 큰 차이점은 더 많은 정보를 적은 차원에 저장하는 것이다. 보통 256차원이나 512차원 또는 그 이상의 어휘 사전을 다룰 때는 1024차원의 단어 임베딩을 사용하지만, 원-핫 인코딩의 경우 20000개의 토큰으로 이루어진 어휘 사전을 만들려면 20000차원 이상의 벡터를 구성해야 한다.
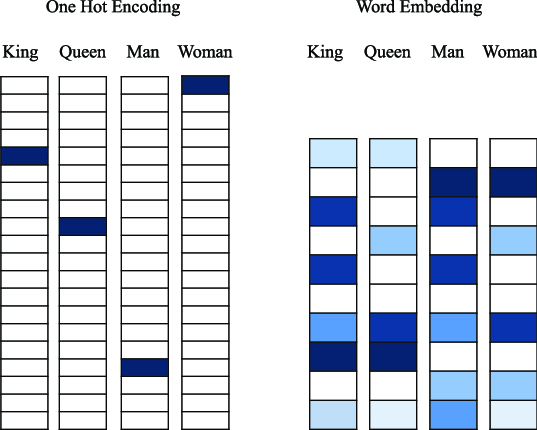
원-핫 인코딩으로 만든 벡터와 워드 임베딩를 비교한 예시이다. 원-핫 단어 벡터는 하나의 단어 정보를 저장하기 위해 대부분이 0으로 이루어진 배열, 즉 고차원 공간에 저장하지만 워드 임베딩은 비교적 저차원 공간을 사용한다.
워드 임베딩을 만드는 두 가지 방법이 있다. 첫 번째 방법은 감성 분류 같은 관심 대상 문제와 함께 워드 임베딩을 학습한다. 이 경우 랜덤한 단어 벡터로 시작하여 신경망의 가중치를 학습하는 것과 같은 방식으로 단어 벡터를 학습한다. 두 번째 방법은 다른 머신 러닝 작업에서 미리 계산된 단어 임베딩을 로드한다. 이를 사전 훈련된 워드 임베딩(pretrained word embedding)이라고 한다.
2. Embedding 층을 사용한 워드 임베딩 학습
단어와 밀집 벡터를 연관 짓는 가장 간단한 방법은 랜덤하게 벡터를 선택하는 것이지만 임베딩 공간이 구조적이지 않다는 문제점이 있다. 예를 들어 'accrate'와 'exact'는 대부분의 문장에서 비슷한 의미로 쓰이지만 완전히 다른 임베딩을 가진다. 심층 신경망이 이런 임의의 구조적이지 않은 임베딩 공간을 이해하기는 어렵다.
단어 벡터 사이에 좀 더 추상적이고 기하학적인 관계를 얻기 위해서는 단어 사이에 있는 의미 관계를 반영해야 한다. 워드 임베딩은 언어를 기하하적 공간에 매핑하는 것이다. 예를 들어 잘 구축된 임베딩 공간에서는 앞서 언급한 'accrate'와 'exact'같은 동의어가 비슷한 단어 벡터로 임베딩될 것이다.
일반적으로 두 단어 벡터 사이의 거리(L2 거리)는 두 단어 사이의 의미 거리와 관계되어 있다. 다시 말해 비슷한 단어들은 가까이 임베딩되고 의미가 다른 단어들은 멀리 떨어진 위치에 임베딩된다. 거리 외에 임베딩 공간의 특정 방향도 의미를 가질 수 있다.
예를 들어 다음과 같이 4개의 단어 cat, dog, wolf, tiger가 2차원 평면에 임베딩되어 있다.
이 벡터 표현을 사용하여 단어 간의 의미 관계를 기하학적 변환으로 인코딩할 수 있다. 예를 들어 cat에서 tiger로 이동하는 것과 dog에서 wolf로 이동하는 것을 같은 벡터로 나타낼 수 있다. 이 벡터는 '애완동물에서 야생 동물로 이동'하는 것으로 해석할 수 있다. 비슷하게 dog에서 cat으로 이동하는 것과 wolf에서 tiger로 이동하는 것을 나타내면 '개과 에서 고양이 과로 이동'하는 벡터로 해석할 수 있다.
실제 워드 임베딩 공간에서 의미있는 기하학적 변환의 일반적인 예는 성별 벡터와 복수 벡터이다. 예를 들어 'king' 벡터에 'female' 벡터를 더하면 왕과 여성의 의미를 합친 'queen' 벡터가 된다. 'king' 벡터에 'plural' 벡터를 더하면 왕과 복수형의 의미를 합친 'kings' 벡터가 된다. 워드 임베딩 공간은 전형적으로 위 예시처럼 해석 가능하고 잠재적으로 유용한 수천 개의 벡터를 특성으로 가진다.
사람의 언어를 완벽하게 매핑해서 어떤 자연어 처리 작업에도 사용할 수 있는 이상적인 단어 임베딩 공간은 아직 없다. 사람의 언어에도 그런 것은 없다. 세상에는 다양한 언어가 많이 있고 언어는 특정 문화와 환경을 반영하기 때문에 서로 동일하지 않다. 실제로 좋은 단어 임베딩 공간을 만드는 것은 어떤 문제를 다루느냐에 따라 크게 달라진다. 영어로 된 영화 리뷰 감성 분석 모델을 위한 완벽한 단어 임베딩 공간은 영어로 된 법률 문서 분류 모델을 위한 완벽한 임베딩 공간과 다를 것이다. 특정 의미 관계의 중요성이 작업에 따라 다르기 때문이다.
따라서 새로운 작업에서 새로운 임베딩을 학습하는 것이 타당하다. 다행히 역전파를 사용하면 쉽게 만들고 있다. Embedding 층의 가중치를 학습하면 된다.
# keras를 이용하여 Embedding 층의 객체 생성하기
from keras.layers import Embedding
embedding_layer = Embedding(1000, 64) # Embedding(가능한 토큰의 개수이며 여기서 1000은 단어 인덱스 최댓값 + 1, 임베딩 차원)Embedding 층을 특정 단어를 나타내는 정수 인덱스를 밀집 벡터로 매핑하는 딕셔너리라고 이해하는 것이 좋다. 정수를 입력으로 받아 내부 딕셔너리에서 이 정수에 연관된 벡터를 찾아서 반환한다. 다시 말해
(단어 인덱스 --> Embedding 층 --> 연관된 단어 벡터) 과정을 거친다.
Embedding 층은 크기가 (samples, sequence_length)인 2차원 정수 텐서를 입력으로 받는다. 각 샘플은 정수의 시퀀스이며 가변 길이의 시퀀스를 임베딩할 수 있다. 예를 들어 Embedding 층에 (64, 15) 크기의 배치를 주입한다는 것은 길이가 15인 시퀀스 64개로 이루어진 배치를 주입한다는 것과 같다.
배치에 있는 모든 시퀀스는 하나의 텐서에 담아야 하기 때문에 길이가 같아야 한다. 따라서 작은 길이의 시퀀스는 0으로 padding 되고 길이가 더 긴 시퀀스는 잘린다.
Embedding 층의 객체를 생성할 때 토큰 벡터를 위한 내부 딕셔너리, 즉 가중치는 다른 층과 마찬가지로 랜덤하게 초기화된다. 훈련을 거치며 이 단어 벡터는 역전파를 통해 점차 조정되어 이어지는 모델이 사용할 수 있도록 임베딩 공간을 구성한다. 훈련이 끝나면 임베딩 공간은 특정 문제에 특화된 구조를 많이 가지게 된다. 지금까지 살펴본 내용을 IMDB 영화 리뷰 감성 예측 문제에 적용해 보겠다.
영화 리뷰에서 가장 빈도가 높은 10000개의 단어를 추출하고 리뷰에서 20개가 넘는 단어는 버릴 것이다. 이 네트워크는 10000개의 단어에 대해 8차원의 임베딩을 학습하여 정수 시퀀스 입력(2D 정수 텐서)을 임베딩 시퀀스(3D 실수형 텐서)로 바꿀 것이다. 그 다음 이 텐서를 2D로 펼쳐(Flatten) 분류를 위한 Dense 층을 훈련할 것이다.
from keras.datasets import imdb
from keras.preprocessing.sequence import pad_sequences
max_features = 10000 # 특성으로 사용할 단어 수
max_len = 20 # 사용할 텍스트의 길이 (가장 빈번한 max_features개의 단어만 사용)
(train_x, train_y), (test_x, test_y) = imdb.load_data(num_words=max_features) # 정수 리스트로 데이터 로드
print("train_x before preprocessing")
print(train_x[:3], '\n')
train_x = pad_sequences(train_x, maxlen=max_len)
print("train_x after preprocessing")
print(train_x[:3], '\n')
print("test_x before preprocessing")
print(test_x[:3], '\n')
test_x = pad_sequences(test_x, maxlen=max_len)
print("test_x after preprocessing")
print(test_x[:3])imdb 데이터셋에서 정수 리스트로 데이터를 불러왔다. 데이터는 10000개의 단어로 구성되어있고 리뷰마다 크기가 다양하므로 max_len인 20개로 단어 개수를 맞췄다.
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb.npz
17464789/17464789 [==============================] - 0s 0us/step
train_x before preprocessing
[list([1, 14, 22, 16, 43, 530, 973, 1622, 1385, 65, 458, 4468, 66, 3941, 4, 173, 36, 256, 5, 25, 100, 43, 838, 112, 50, 670, 2, 9, 35, 480, 284, 5, 150, 4, 172, 112, 167, 2, 336, 385, 39, 4, 172, 4536, 1111, 17, 546, 38, 13, 447, 4, 192, 50, 16, 6, 147, 2025, 19, 14, 22, 4, 1920, 4613, 469, 4, 22, 71, 87, 12, 16, 43, 530, 38, 76, 15, 13, 1247, 4, 22, 17, 515, 17, 12, 16, 626, 18, 2, 5, 62, 386, 12, 8, 316, 8, 106, 5, 4, 2223, 5244, 16, 480, 66, 3785, 33, 4, 130, 12, 16, 38, 619, 5, 25, 124, 51, 36, 135, 48, 25, 1415, 33, 6, 22, 12, 215, 28, 77, 52, 5, 14, 407, 16, 82, 2, 8, 4, 107, 117, 5952, 15, 256, 4, 2, 7, 3766, 5, 723, 36, 71, 43, 530, 476, 26, 400, 317, 46, 7, 4, 2, 1029, 13, 104, 88, 4, 381, 15, 297, 98, 32, 2071, 56, 26, 141, 6, 194, 7486, 18, 4, 226, 22, 21, 134, 476, 26, 480, 5, 144, 30, 5535, 18, 51, 36, 28, 224, 92, 25, 104, 4, 226, 65, 16, 38, 1334, 88, 12, 16, 283, 5, 16, 4472, 113, 103, 32, 15, 16, 5345, 19, 178, 32])
list([1, 194, 1153, 194, 8255, 78, 228, 5, 6, 1463, 4369, 5012, 134, 26, 4, 715, 8, 118, 1634, 14, 394, 20, 13, 119, 954, 189, 102, 5, 207, 110, 3103, 21, 14, 69, 188, 8, 30, 23, 7, 4, 249, 126, 93, 4, 114, 9, 2300, 1523, 5, 647, 4, 116, 9, 35, 8163, 4, 229, 9, 340, 1322, 4, 118, 9, 4, 130, 4901, 19, 4, 1002, 5, 89, 29, 952, 46, 37, 4, 455, 9, 45, 43, 38, 1543, 1905, 398, 4, 1649, 26, 6853, 5, 163, 11, 3215, 2, 4, 1153, 9, 194, 775, 7, 8255, 2, 349, 2637, 148, 605, 2, 8003, 15, 123, 125, 68, 2, 6853, 15, 349, 165, 4362, 98, 5, 4, 228, 9, 43, 2, 1157, 15, 299, 120, 5, 120, 174, 11, 220, 175, 136, 50, 9, 4373, 228, 8255, 5, 2, 656, 245, 2350, 5, 4, 9837, 131, 152, 491, 18, 2, 32, 7464, 1212, 14, 9, 6, 371, 78, 22, 625, 64, 1382, 9, 8, 168, 145, 23, 4, 1690, 15, 16, 4, 1355, 5, 28, 6, 52, 154, 462, 33, 89, 78, 285, 16, 145, 95])
list([1, 14, 47, 8, 30, 31, 7, 4, 249, 108, 7, 4, 5974, 54, 61, 369, 13, 71, 149, 14, 22, 112, 4, 2401, 311, 12, 16, 3711, 33, 75, 43, 1829, 296, 4, 86, 320, 35, 534, 19, 263, 4821, 1301, 4, 1873, 33, 89, 78, 12, 66, 16, 4, 360, 7, 4, 58, 316, 334, 11, 4, 1716, 43, 645, 662, 8, 257, 85, 1200, 42, 1228, 2578, 83, 68, 3912, 15, 36, 165, 1539, 278, 36, 69, 2, 780, 8, 106, 14, 6905, 1338, 18, 6, 22, 12, 215, 28, 610, 40, 6, 87, 326, 23, 2300, 21, 23, 22, 12, 272, 40, 57, 31, 11, 4, 22, 47, 6, 2307, 51, 9, 170, 23, 595, 116, 595, 1352, 13, 191, 79, 638, 89, 2, 14, 9, 8, 106, 607, 624, 35, 534, 6, 227, 7, 129, 113])]
train_x after preprocessing
[[ 65 16 38 1334 88 12 16 283 5 16 4472 113 103 32
15 16 5345 19 178 32]
[ 23 4 1690 15 16 4 1355 5 28 6 52 154 462 33
89 78 285 16 145 95]
[1352 13 191 79 638 89 2 14 9 8 106 607 624 35
534 6 227 7 129 113]]
test_x before preprocessing
[list([1, 591, 202, 14, 31, 6, 717, 10, 10, 2, 2, 5, 4, 360, 7, 4, 177, 5760, 394, 354, 4, 123, 9, 1035, 1035, 1035, 10, 10, 13, 92, 124, 89, 488, 7944, 100, 28, 1668, 14, 31, 23, 27, 7479, 29, 220, 468, 8, 124, 14, 286, 170, 8, 157, 46, 5, 27, 239, 16, 179, 2, 38, 32, 25, 7944, 451, 202, 14, 6, 717])
list([1, 14, 22, 3443, 6, 176, 7, 5063, 88, 12, 2679, 23, 1310, 5, 109, 943, 4, 114, 9, 55, 606, 5, 111, 7, 4, 139, 193, 273, 23, 4, 172, 270, 11, 7216, 2, 4, 8463, 2801, 109, 1603, 21, 4, 22, 3861, 8, 6, 1193, 1330, 10, 10, 4, 105, 987, 35, 841, 2, 19, 861, 1074, 5, 1987, 2, 45, 55, 221, 15, 670, 5304, 526, 14, 1069, 4, 405, 5, 2438, 7, 27, 85, 108, 131, 4, 5045, 5304, 3884, 405, 9, 3523, 133, 5, 50, 13, 104, 51, 66, 166, 14, 22, 157, 9, 4, 530, 239, 34, 8463, 2801, 45, 407, 31, 7, 41, 3778, 105, 21, 59, 299, 12, 38, 950, 5, 4521, 15, 45, 629, 488, 2733, 127, 6, 52, 292, 17, 4, 6936, 185, 132, 1988, 5304, 1799, 488, 2693, 47, 6, 392, 173, 4, 2, 4378, 270, 2352, 4, 1500, 7, 4, 65, 55, 73, 11, 346, 14, 20, 9, 6, 976, 2078, 7, 5293, 861, 2, 5, 4182, 30, 3127, 2, 56, 4, 841, 5, 990, 692, 8, 4, 1669, 398, 229, 10, 10, 13, 2822, 670, 5304, 14, 9, 31, 7, 27, 111, 108, 15, 2033, 19, 7836, 1429, 875, 551, 14, 22, 9, 1193, 21, 45, 4829, 5, 45, 252, 8, 2, 6, 565, 921, 3639, 39, 4, 529, 48, 25, 181, 8, 67, 35, 1732, 22, 49, 238, 60, 135, 1162, 14, 9, 290, 4, 58, 10, 10, 472, 45, 55, 878, 8, 169, 11, 374, 5687, 25, 203, 28, 8, 818, 12, 125, 4, 3077])
list([1, 111, 748, 4368, 1133, 2, 2, 4, 87, 1551, 1262, 7, 31, 318, 9459, 7, 4, 498, 5076, 748, 63, 29, 5161, 220, 686, 2, 5, 17, 12, 575, 220, 2507, 17, 6, 185, 132, 2, 16, 53, 928, 11, 2, 74, 4, 438, 21, 27, 2, 589, 8, 22, 107, 2, 2, 997, 1638, 8, 35, 2076, 9019, 11, 22, 231, 54, 29, 1706, 29, 100, 2, 2425, 34, 2, 8738, 2, 5, 2, 98, 31, 2122, 33, 6, 58, 14, 3808, 1638, 8, 4, 365, 7, 2789, 3761, 356, 346, 4, 2, 1060, 63, 29, 93, 11, 5421, 11, 2, 33, 6, 58, 54, 1270, 431, 748, 7, 32, 2580, 16, 11, 94, 2, 10, 10, 4, 993, 2, 7, 4, 1766, 2634, 2164, 2, 8, 847, 8, 1450, 121, 31, 7, 27, 86, 2663, 2, 16, 6, 465, 993, 2006, 2, 573, 17, 2, 42, 4, 2, 37, 473, 6, 711, 6, 8869, 7, 328, 212, 70, 30, 258, 11, 220, 32, 7, 108, 21, 133, 12, 9, 55, 465, 849, 3711, 53, 33, 2071, 1969, 37, 70, 1144, 4, 5940, 1409, 74, 476, 37, 62, 91, 1329, 169, 4, 1330, 2, 146, 655, 2212, 5, 258, 12, 184, 2, 546, 5, 849, 2, 7, 4, 22, 1436, 18, 631, 1386, 797, 7, 4, 8712, 71, 348, 425, 4320, 1061, 19, 2, 5, 2, 11, 661, 8, 339, 2, 4, 2455, 2, 7, 4, 1962, 10, 10, 263, 787, 9, 270, 11, 6, 9466, 4, 2, 2, 121, 4, 5437, 26, 4434, 19, 68, 1372, 5, 28, 446, 6, 318, 7149, 8, 67, 51, 36, 70, 81, 8, 4392, 2294, 36, 1197, 8, 2, 2, 18, 6, 711, 4, 9909, 26, 2, 1125, 11, 14, 636, 720, 12, 426, 28, 77, 776, 8, 97, 38, 111, 7489, 6175, 168, 1239, 5189, 137, 2, 18, 27, 173, 9, 2399, 17, 6, 2, 428, 2, 232, 11, 4, 8014, 37, 272, 40, 2708, 247, 30, 656, 6, 2, 54, 2, 3292, 98, 6, 2840, 40, 558, 37, 6093, 98, 4, 2, 1197, 15, 14, 9, 57, 4893, 5, 4659, 6, 275, 711, 7937, 2, 3292, 98, 6, 2, 10, 10, 6639, 19, 14, 2, 267, 162, 711, 37, 5900, 752, 98, 4, 2, 2378, 90, 19, 6, 2, 7, 2, 1810, 2, 4, 4770, 3183, 930, 8, 508, 90, 4, 1317, 8, 4, 2, 17, 2, 3965, 1853, 4, 1494, 8, 4468, 189, 4, 2, 6287, 5774, 4, 4770, 5, 95, 271, 23, 6, 7742, 6063, 2, 5437, 33, 1526, 6, 425, 3155, 2, 4535, 1636, 7, 4, 4669, 2, 469, 4, 4552, 54, 4, 150, 5664, 2, 280, 53, 2, 2, 18, 339, 29, 1978, 27, 7885, 5, 2, 68, 1830, 19, 6571, 2, 4, 1515, 7, 263, 65, 2132, 34, 6, 5680, 7489, 43, 159, 29, 9, 4706, 9, 387, 73, 195, 584, 10, 10, 1069, 4, 58, 810, 54, 14, 6078, 117, 22, 16, 93, 5, 1069, 4, 192, 15, 12, 16, 93, 34, 6, 1766, 2, 33, 4, 5673, 7, 15, 2, 9252, 3286, 325, 12, 62, 30, 776, 8, 67, 14, 17, 6, 2, 44, 148, 687, 2, 203, 42, 203, 24, 28, 69, 2, 6676, 11, 330, 54, 29, 93, 2, 21, 845, 2, 27, 1099, 7, 819, 4, 22, 1407, 17, 6, 2, 787, 7, 2460, 2, 2, 100, 30, 4, 3737, 3617, 3169, 2321, 42, 1898, 11, 4, 3814, 42, 101, 704, 7, 101, 999, 15, 1625, 94, 2926, 180, 5, 9, 9101, 34, 2, 45, 6, 1429, 22, 60, 6, 1220, 31, 11, 94, 6408, 96, 21, 94, 749, 9, 57, 975])]
test_x after preprocessing
[[ 286 170 8 157 46 5 27 239 16 179 2 38 32 25
7944 451 202 14 6 717]
[ 10 10 472 45 55 878 8 169 11 374 5687 25 203 28
8 818 12 125 4 3077]
[ 34 2 45 6 1429 22 60 6 1220 31 11 94 6408 96
21 94 749 9 57 975]]전처리한 데이터셋을 출력한 결과이다.
from keras.models import Sequential
from keras.layers import Embedding, Flatten, Dense
model = Sequential()
model.add(Embedding(10000, 8, input_length=max_len)) # 3D 텐서를 2D 텐서로 펼치기 위해 input_length 지정. Embedding 층의 출력 크기는 (samples, maxlen, 8)
model.add(Flatten())
model.add(Dense(1, activation='sigmoid')) # 이진 분류
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics='accuracy')
model.summary()
hist = model.fit(train_x, train_y, epochs=10, batch_size=32, validation_split=0.2)Embedding layer를 10000개의 토큰에 대한 8차원 임베딩으로 구성하였다. Embedding layer는 3D 텐서(이번 경우는 (10000, 20, 8))를 출력하고 이를 다시 2D 텐서로 펼칠 때 크기를 지정하기 위해 max_len을 input_length에 지정하였다.
Flatten을 통해 (10000, 20, 8)의 3D 텐서를 (10000, 20*8)의 2D 텐서로 펼치고 감성 분류를 위해 Dense layer를 모델의 출력층으로 구성하였다.
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, 20, 8) 80000
flatten (Flatten) (None, 160) 0
dense (Dense) (None, 1) 161
=================================================================
Total params: 80161 (313.13 KB)
Trainable params: 80161 (313.13 KB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
Epoch 1/10
625/625 [==============================] - 11s 14ms/step - loss: 0.6689 - accuracy: 0.6288 - val_loss: 0.6197 - val_accuracy: 0.6928
Epoch 2/10
625/625 [==============================] - 3s 5ms/step - loss: 0.5445 - accuracy: 0.7492 - val_loss: 0.5285 - val_accuracy: 0.7284
Epoch 3/10
625/625 [==============================] - 3s 5ms/step - loss: 0.4645 - accuracy: 0.7860 - val_loss: 0.5020 - val_accuracy: 0.7484
Epoch 4/10
625/625 [==============================] - 2s 3ms/step - loss: 0.4232 - accuracy: 0.8093 - val_loss: 0.4941 - val_accuracy: 0.7580
Epoch 5/10
625/625 [==============================] - 2s 3ms/step - loss: 0.3937 - accuracy: 0.8255 - val_loss: 0.4947 - val_accuracy: 0.7586
Epoch 6/10
625/625 [==============================] - 2s 4ms/step - loss: 0.3693 - accuracy: 0.8393 - val_loss: 0.4973 - val_accuracy: 0.7596
Epoch 7/10
625/625 [==============================] - 2s 3ms/step - loss: 0.3470 - accuracy: 0.8521 - val_loss: 0.5035 - val_accuracy: 0.7578
Epoch 8/10
625/625 [==============================] - 3s 4ms/step - loss: 0.3272 - accuracy: 0.8640 - val_loss: 0.5096 - val_accuracy: 0.7556
Epoch 9/10
625/625 [==============================] - 2s 3ms/step - loss: 0.3085 - accuracy: 0.8740 - val_loss: 0.5177 - val_accuracy: 0.7522
Epoch 10/10
625/625 [==============================] - 2s 3ms/step - loss: 0.2909 - accuracy: 0.8816 - val_loss: 0.5271 - val_accuracy: 0.7494performance = model.evaluate(test_x, test_y, batch_size=100)
print(f"test loss = {performance[0]:.4f}, test accuracy = {performance[1]:.2f}")250/250 [==============================] - 1s 2ms/step - loss: 0.5238 - accuracy: 0.7530
test loss = 0.5238, test accuracy = 0.7510번 학습 후 테스트 데이터셋으로 간단히 성능을 평가했을 때 accuracy가 약 0.75였다.
3. 정리
워드 임베딩에 대해 살펴보고 이를 통한 간단한 텍스트 분류 모델을 만들어 보았다. 워드 임베딩을 이용하면 저차원 공간에 더 많은 정보를 저장할 수 있으므로 원-핫 인코딩을 이용한 벡터보다 더 효율적이다.
워드 임베딩을 사용하기 위해선 max_feature와 패딩을 위한 max_len을 지정해야하고 이에 따라 입력할 데이터도 max_feature개 전후의 단어로 구성되어 있어야 하며, 데이터 마다 max_len 크기로 padding해야 한다.
Embedding layer는 2D 텐서를 입력받아 3D 텐서를 출력하고 이를 다시 2D 텐서로 펼치기 위해서 Flatten 함수를 사용하는 것과 Embedding layer를 선언할 때 input_length를 max_len으로 미리 지정해주는 것을 주의하자.
만약 학습 데이터가 충분하지 않다면 문제에 맞는 단어 임베딩을 학습하기 어렵다. 이러한 경우 미리 계산된 임베딩 공간에서 임베딩 벡터를 로드하는 방안이 있다. 이와 관련하여 다음 포스트는 pretrained word embedding에 대해 작성하겠다.
이미지 출처: https://www.researchgate.net/figure/Comparison-of-representations-between-one-hot-encoding-and-word-embeddings_fig3_358234888 (Felix Beierle's Comparison of representations between one hot encoding and word embeddings.)
