실험 정확도를 평가하는 방법과 성능을 향상시키는 머신러닝 기법
1. 데이터의 확인과 예측 실행
모델을 설정하고 결과를 보니 100%의 정확도가 나타났다. 정말일까?
2. 과적합 이해하기
과적합 모델이 학습 데이터셋 안에서는 일정 수준 이상의 예측 정학도
그러나 새로운 데이터에 적용하면 잘 맞지 않는 것을 의미
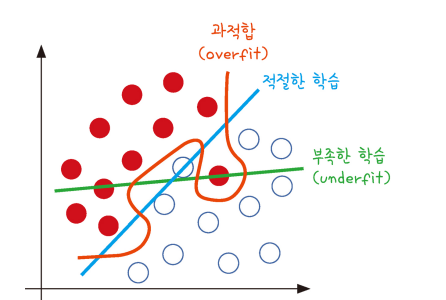
빨간색 선은 주어진 샘플에 정확히 맞게끔 그어짐.
새로운 샘플에는 정확한 분류가 나타나지 않음.
과적합은 층이 너무 많거나 변수가 복잡하면 발생하기도 하고
테스트 셋과 학습 셋이 중복되는 경우 생기기도 함.
3. 학습셋과 테스트셋
과적합을 방지하는 방법은 그러면 무엇일까?
먼저 학습을 하는 데이터셋과 이를 테스트할 데이터셋을 완전히 구분
학습과 둥시에 테스트를 병행하며 진행하는 것이 방법
지금까지 해온 방법은 모든 샘플을 그대로 테스트에 활용한 방법
머신러닝의 최종 목적은 과거의 데이터를 사용해서 새로운 데이터를 예측하는 것
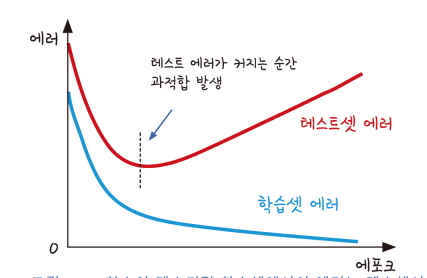
학습을 진행해도 테스트 결과가 좋아지지 않는 시점에서 학습 stop
저장된 X데이터와 y데이터에서 각각 정해진 비율(%)만큼 학습셋과 테스트셋으로 분리시키는 함수가 train_test_split함수
실습
from tensorflow.keras.models import Sequential, load_model
from tensorflow.keras.layers import Dense
from sklearn.model_selection import train_test_split
import pandas as pd
#데이터를 입력합니다.
df = pd.read_csv('./data/sonar3.csv', header=None)
#음파 관련 속성을 X로, 광물의 종류를 y로 저장합니다.
X = df.iloc[:,0:60]
y = df.iloc[:,60]
#학습 셋과 테스트 셋을 구분합니다.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, shuffle=True)
#모델을 설정합니다.
model = Sequential()
model.add(Dense(24, input_dim=60, activation='relu'))
model.add(Dense(10, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
#모델을 컴파일합니다.
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
#모델을 실행합니다.
history=model.fit(X_train, y_train, epochs=200, batch_size=10)
#모델을 테스트셋에 적용해 정확도 확인
score=model.evaluate(X_test, y_test)
print('Test accuracy:', score[1])
- 학습셋을 이용해 200번 반복했을 때 정확도 거의 1에 가까움
- 하지만 테스트 셋의 정확도는 0.809정도가 나타남.
모델 성능의 향상을 위해서는
1. 데이터를 보강하는 방법
--> 충분한 데이터를 가져와서 추가
2. 알고리즘을 최적화하는 방법
--> 데이터를 적절히 보완
--> 다른 구조로 모델을 바꾸어 가며 최적의 구조를 찾는 것
ex) 은닉층의 개수, 노드의 수, 최적화 함수의 종류
많은 경험을 통해 최적의 성능을 보이는 모델을 만드는 것이 중요!
4. 모델 저장과 재사용
model.save()함수 : 모델 이름을 적어 저장
#load_model을 추가하기 위해 Sequential 함수 추가
from tensorflow.keras.models import Sequential, load_model
#메모리에서 모델 삭제
del model
#load_model()함수를 이용해 조금 전 저장한 모델을 불러옴.
model = load_model('./data/model/my_model.hdf5')
#불러온 모델을 테스트셋에 적용해 정확도를 구함.
score = model.evaluate(X_test, y_test)
print('Test accuracy:', score[1])
5. K겹 교차 검증
k겹 교차 검증이란 데이터셋을 여러 개로 나누어 하나씩 테스트셋으로 사용하고 나머지를 합해서 학습셋으로 사용하는 방법
- 데이터 셋을 5개로 나누고 4개는 학습셋, 1개는 테스트셋으로 만듦
- 순차적으로 검증
예제 초음파 광물 예측
1. 몇 개의 파일로 만들건지 K변수에 넣는다.
2. KFold()함수를 불러오고, shuffle옵션을 true로 설정
3. acc_score라는 이름의 빈 리스트를 준비
4. split()에 의해 K개의 학습셋, 테스트셋으로 분리되고 for문에 의해 K번 반복
반복되는 학습마다 정확도를 구해 acc_score 리스트를 채운다.
5. k번의 학습이 끝나면 각 정확도를 취합해 모델 성능을 평가한다.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from sklearn.model_selection import KFold
from sklearn.metrics import accuracy_score
import pandas as pd
#데이터를 입력함.
df = pd.read_csv('./data/sonar3.csv', header=None)
#음파 관련 속성을 X로, 광물의 종류를 y로 저장함.
X = df.iloc[:,0:60]
y = df.iloc[:,60]
#몇 겹으로 나눌 것인지를 정함.
k=5
#KFold 함수를 불러옵니다. 분할하기 전에 샘플이 치우치지 않도록 섞어 준다.
kfold = KFold(n_splits=k, shuffle=True)
#정확도가 채워질 빈 리스트를 준비함.
acc_score = []
def model_fn():
model = Sequential() #딥러닝 모델의 구조를 시작함.
model.add(Dense(24, input_dim=60, activation='relu'))
model.add(Dense(10, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
return model
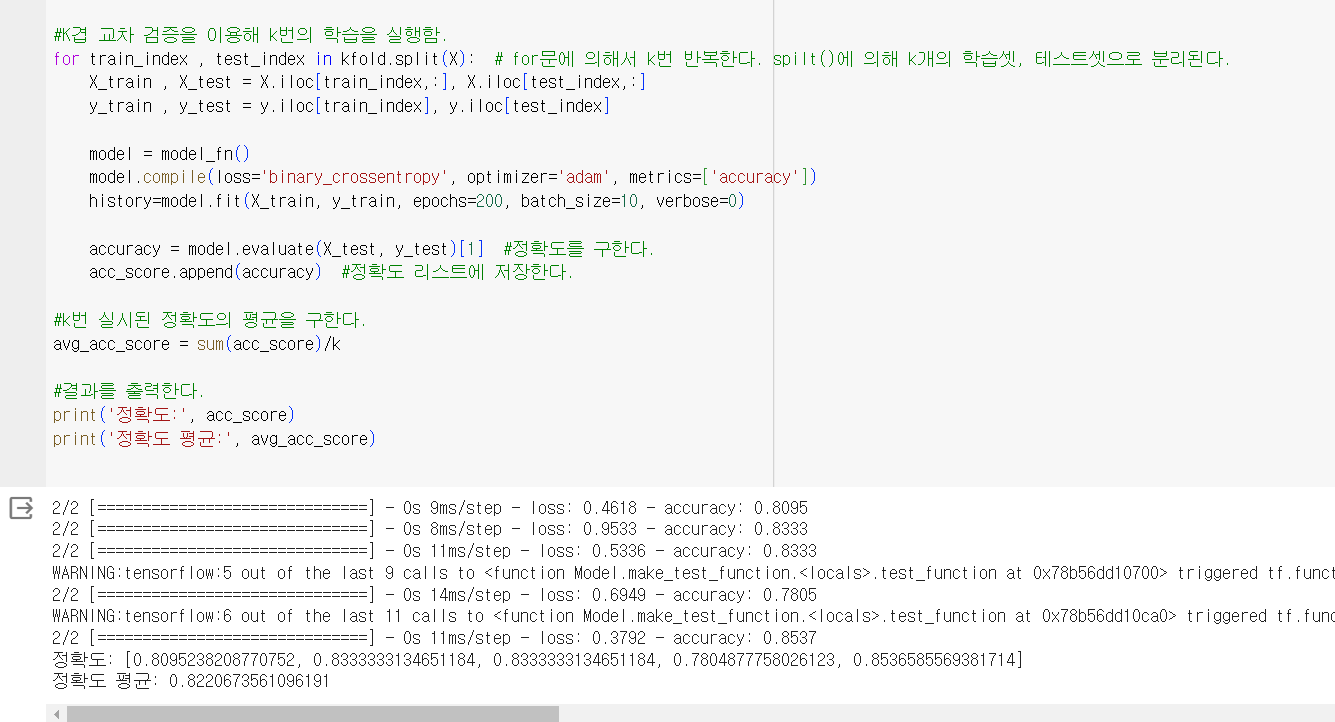
#K겹 교차 검증을 이용해 k번의 학습을 실행함.
for train_index , test_index in kfold.split(X): # for문에 의해서 k번 반복한다. spilt()에 의해 k개의 학습셋, 테스트셋으로 분리된다.
X_train , X_test = X.iloc[train_index,:], X.iloc[test_index,:]
y_train , y_test = y.iloc[train_index], y.iloc[test_index]
model = model_fn()
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
history=model.fit(X_train, y_train, epochs=200, batch_size=10, verbose=0)
accuracy = model.evaluate(X_test, y_test)[1] #정확도를 구한다.
acc_score.append(accuracy) #정확도 리스트에 저장한다.#k번 실시된 정확도의 평균을 구한다.
avg_acc_score = sum(acc_score)/k
#결과를 출력한다.
print('정확도:', acc_score)
print('정확도 평균:', avg_acc_score)
[^출처]: 모두의 딥러닝 개정 3판 (지은이: 조태호)
