AMD DL study - 모두의 딥러닝 정리
1.AMD DL study 1주차 -1

인공지능? 머신러닝? 딥러닝?인공지능 -> 머신러닝 -> 딥러닝 순서의 포함관계 딥러닝 실행을 위해 필요한 세 가지데이터, 컴퓨터, 프로그램2-1 데이터데이터 이름표 존재 여부로 두 종류 이름표가 존재하는 데이터 : 지도학습이름표를 맞히는 것ex) CNN, RNN 이름
2.AMD DL study 1주차 - 2
머신러닝은 데이터 안에서 규칙을 발견하고 그 규칙을 새로운 데이터에 적용해서 새로운 결과를 도출하는 일에 초점이 맞추어 있음.데이터를 머신 러닝 알고리즘에 넣으면 머신 러닝은 데이터가 가진 패턴과 규칙을 분석해서 저장.이후 저장된 분석결과와 비교해서 결과를 도출해냄.
3.AMD DL study 1주차 - 3
그렇게 어려운 수학을 사용하지는 않음, 간단하게 복습 함수: 두 집합 사이의 관계를 설명 일차함수y = ax^2 일때, a > 0 아래 볼록, 포물선의 맨 아래 최솟값 딥러닝에서는 이 최솟값을 찾는 것이 중요함미분 , 순간 변화율 , 기울기 한가지 변수를 미분하고 그
4.Linux에 Anaconda설치
우분투 설치처음에 계정 생성하는데 리눅스 환경에 익숙하지 않아서 찾아보느라 애먹었다....wget https://repo.anaconda.com/archive/그리고 sh Anaconda3-2023.09-0-Linux-x86_64.sh 코드로 설치파일 열기 약
5.AMD DL study 2주차 - 1
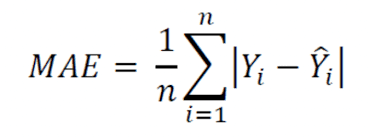
딥 러닝의 가장 말단에서 이루어지는 기본적인 두 가지 계산 원리선형회귀 , 로지스틱회귀가장 훌륭한 예측선 = 선형 회귀 분석을 이용한 모델 딥 러닝에는 정보가 필요하다! ex) 성적을 변하게 만드는 정보 성적을 변하게 만드는 '정보' 요소를 x라고 하고, 변하는 성적을
6.AMD DL study 2주차 - 2

5장 선형회귀 모델 : 먼저 긋고 수정하기 1 경사 하강법 y = x^2에서 다음과 같이 a1, a2 그리고 m을 대입해 그 자리에서 미분하면 순간 기울기를 알수 있음 중요한 점은 최솟값 m에서의 기울기임. 한 점에서 기울기를 구한다. 구한 기울기의 반대 방향 (기울
7.AMD DL study 2주차 - 3

로지스틱 회귀 : 참과 거짓 중 하나를 내놓는 과정 ex) 공부 시간에 대한 합격 여부를 판가름하는 경우로지스틱 회귀는 선형 회귀와 마찬가지로 적절한 선을 그려주는 과정, 다만 직선이 아니라 S자 사진의 x를 ax+b로 생각한다....여기서의 a는 그래프의 경사도, a
8.AMD DL study 3주차 -1
뉴런의 신호 전달 일정한 수준을 넘으면 참, 그렇지 않으면 거짓을 내보내는 일인공 신경망, 신경망 켜고 끄는 기능이 있는 신경이 있으면 사람의 뇌처럼 동작이 가능할까에서 시작 퍼셉트론 입력 값을 여러개 받아 출력을 만듬. 입력 값에 가중치를 조절할 수 있게 만들어 최초
9.AMD DL study 3주차 8장 다층 퍼셉트론
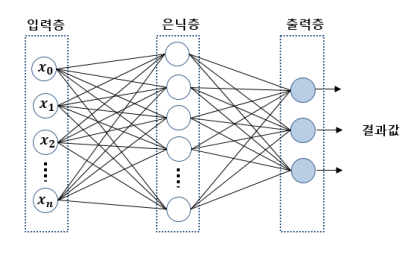
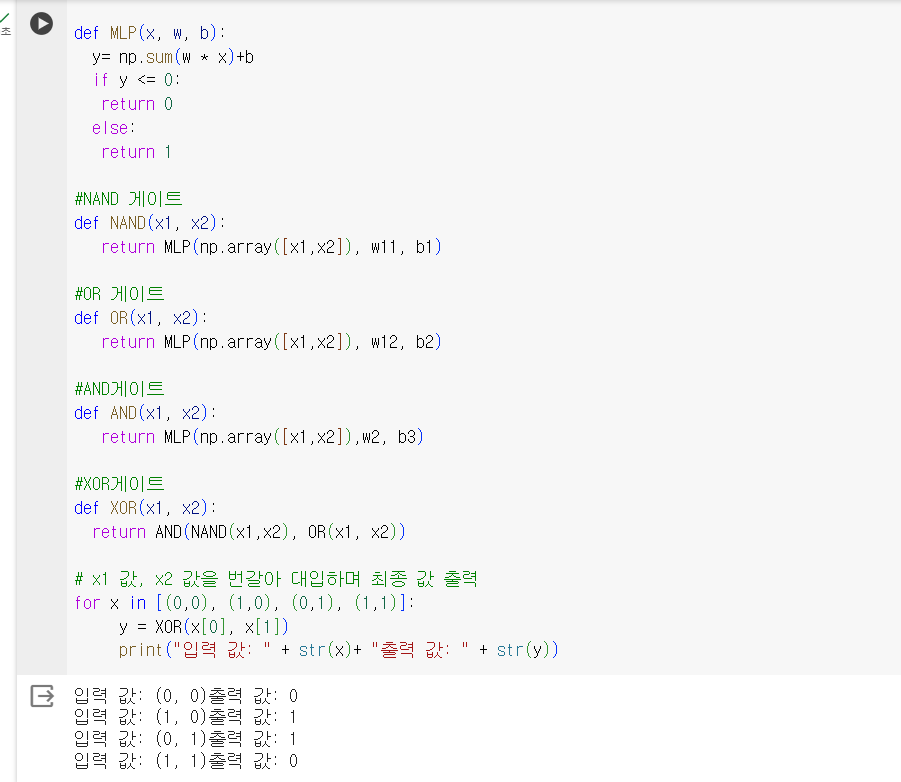
XOR 문제를 해결하기 위해서 퍼셉트론 2개를 한번에 계산하는 은닉층을 만듭니다. x1과 x2를 두 연산으로 각각 보내고 x1과 x2를 각각 NAND와 OR연산을 동시에 진행합니다. 그 후 결과를 AND 처리하면 우리가 구하고자 하는 출력 값을 만들 수 있습니다. 은
10.AMD DL study 3주차 9장 오차 역전파에서 딥러닝으로
9장 오차 역전파에서 딥러닝으로 오차 역전파의 등장으로 은닉층에 포함된 가중치를 업데이트 할 수 있게 되었습니다. --> 우리가 아는 딥러닝의 탄생으로 이어짐. 1. 딥러닝의 태동, 오차 역전파 앞서 XOR문제를 해결했지만, 입력 값과 출력 값을 알고 있는 상태에서
11.4주차 - 10장 딥러닝 모델 설계하기
10장 딥러닝 모델 설계하기 텐서플로, 케라스를 이용해서 딥러닝을 배울수 있따. 1. 모델의 정의 #텐서플로 라이브러리 안에 있는 케라스 API에서 필요한 함수들을 불러옵니다. from tensorflow.keras.models import Sequential f
12.4주차 11장 데이터 다루기
1. 딥러닝과 데이터 데이터의 양도 중요하지만 '필요한' 데이터도 중요하다. 데이터가 머신 러닝과 딥러닝에 효율적으로 사용되게끔 가공되었는지도 중요 데이터 분석에 가장 많이 사용하는 파이썬 라이브러리 판다스 , 맥플롯립 2. 피마 인디언 데이터 분석하기 피마 인
13.4장 12장 다중 분류 문제 해결하기
클래스가 2개가 아닌 3개, 참 거짓이 아닌 여러 개 중에 어떤 것이 답인지다중 분류 여러 개의 답 중 하나를 고르는 문제 import pandas as pd!git clone https://github.com/taehojo/data.gitdf = pd.rea
14.6주차 13장 모델 성능 검증하기
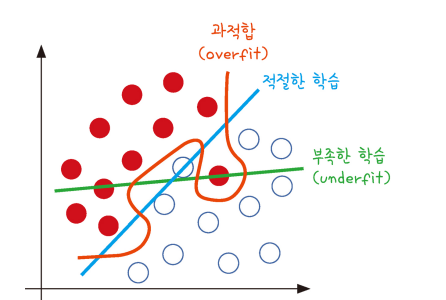
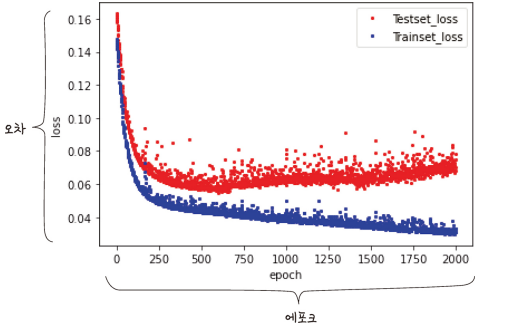
실험 정확도를 평가하는 방법과 성능을 향상시키는 머신러닝 기법 모델을 설정하고 결과를 보니 100%의 정확도가 나타났다. 정말일까?과적합 모델이 학습 데이터셋 안에서는 일정 수준 이상의 예측 정학도그러나 새로운 데이터에 적용하면 잘 맞지 않는 것을 의미 빨간색 선은 주
15.6주차 14장 모델 성능 향상시키기
1. 데이터의 확인과 검증셋 import pandas as pd !git clone https://github.com/taehojo/data.git #와인 데이터를 불러옴 df = pd.read_csv('./data/wine.csv', header=None) #데이터
16.6주차 15장 실제 데이터로 만들어 보는 모델
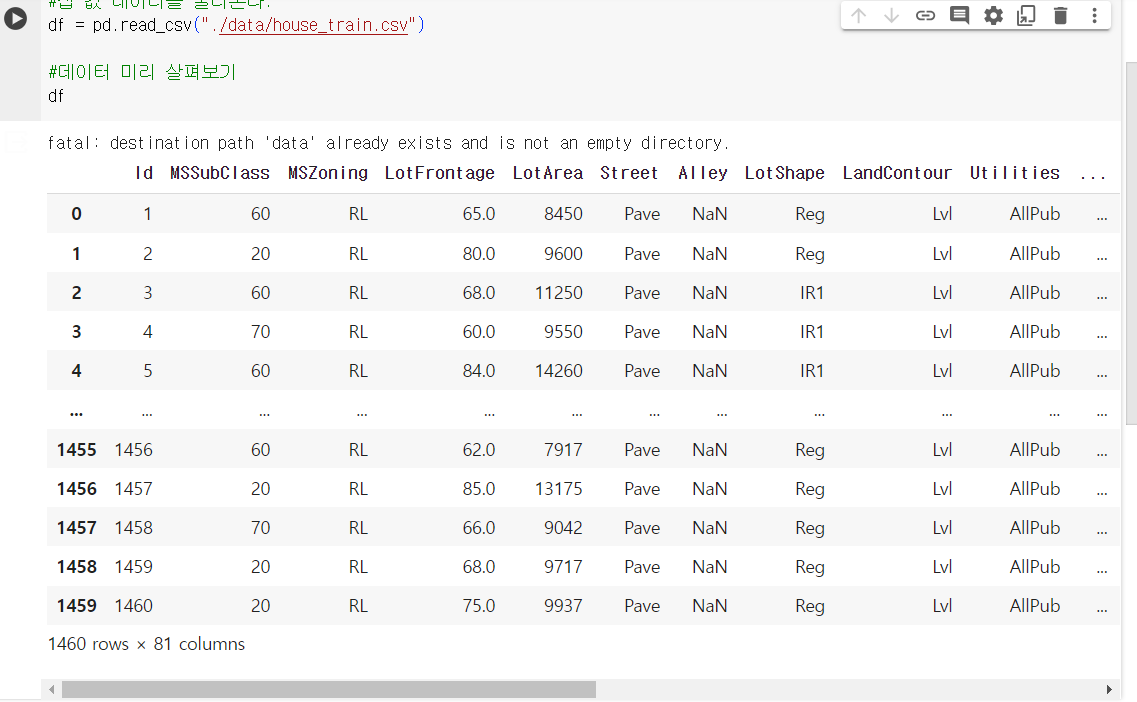
아이오와주 에임스 지역에서 2006년부터 2010까지 거래된 부동산 판매기록을 보았을 때 80개의 서로 다른 속성이 존재했다. 주거 유형, 차고, 자재 및 환경에 관한 다른 속성을 이용해 볼건데 빠진 자료, 부족한 자료가 포함되어 있다. 이때 어떻게 할 것인가?먼저 데
17.7주차 16장 이미지 인식의 꽃 컨벌루션 신경망(CNN)
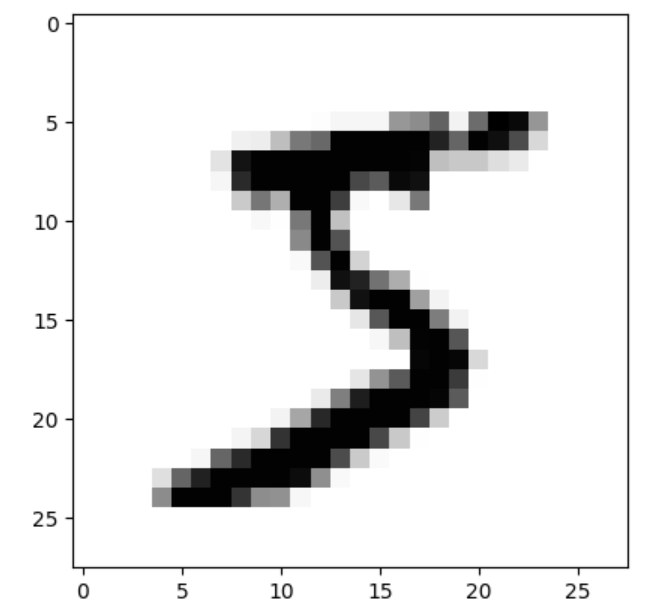
손 글씨를 인식해보자 MNIST 데이터는 텐서플로의 케라스 API를 이용해 불러오기 ㄱㄴ from tensorflow.keras.datasets import mnist학습에 사용될 부분: X_train, y_train테스트에 사용될 부분: X_test, y_test(X
18.7주차 - 17장 딥러닝을 이용한 자연어 처리

인공지능 비서는 사람의 말을 듣고 대답을 해준다. 이는 사람의 언어를 이해하는 능력이 필요하다는 것. 이번 장에서는 자연어 처리에 대해 배워보자 자연어의 전처리 입력될 테스트가 준비되면 이를 단어별, 문장별, 형태소별로 나눌 수 있다. 토큰 이렇게 작게 나누어진 하나의
19.9주차 - 18장 시퀀스 배열로 다루는 순환 신경망
의미를 전달하려면 각 단어가 정해진 순서대로 입력되어야 하기 때문입니다. 즉, 여러 데이터가 순서와 관계없이 입력되던 것과 다르게, 이번에는 과거에 입력된 데이터와 나중에 입력된 데이터 사이의 관계를 고려해야 하는 문제 생김. 순환 신경망 순환 신경망은 여러 개의 데
20.9주차 - 19장 세상에 없는 얼굴 GAN, 오토인코더
생성적 적대 신경망 줄여서 GAN(간)이라고 부르는 알고리즘을 이용해 위와 같은 가상의 얼굴을 만들었다. GAN 딥러닝의 원리를 활용해 가상 이미지를 생성하는 알고리즘 GAN은 적대적 경합을 통해 진짜 같은 가짜를 생성하는 원리 가짜를 만들어 내는 파트를 '생성