1. 데이터의 확인과 검증셋
import pandas as pd
!git clone https://github.com/taehojo/data.git
#와인 데이터를 불러옴
df = pd.read_csv('./data/wine.csv', header=None)
#데이터를 미리 보기
df
0~11번째 속성 12개를 X로, 13번째 열을 y로 정한다.
x = df.iloc[:,0:12]
y = df.iloc[:,12]
여기서는 데이터셋을 학습셋, 검증셋, 테스트 셋으로 나눈다람쥐.
테스트 셋 학습이 끝난 모델을 테스트하는 것이 목적
검증 셋 최적의 학습 파라미터를 찾기 위해 사용
model.fit() 함수 안에 validation_split이라는 옵션을 주어 만듦
실습
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from sklearn.model_selection import train_test_split
#깃허브에 준비된 데이터를 가져옵니다.
!git clone https://github.com/taehojo/data.git
#와인 데이터를 불러옵니다.
df = pd.read_csv('./data/wine.csv', header=None)
#와인의 속성을 X로, 와인의 분류를 y로 저장합니다.
X = df.iloc[:,0:12]
y = df.iloc[:,12]
#학습셋과 테스트셋으로 나눕니다.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=True)
#모델 구조를 설정합니다.
model = Sequential()
model.add(Dense(30, input_dim=12, activation='relu'))
model.add(Dense(12, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.summary()
#모델을 컴파일합니다.
model.compile(loss='binary_crossentropy', optimizer='adam',
metrics=['accuracy'])
#모델을 실행합니다.
history = model.fit(X_train, y_train, epochs=50, batch_size=500,
validation_split=0.25) # 0.8 x 0.25 = 0.2
#validation_split=0.25를 위에서 사용함
#테스트 결과를 출력합니다.
score = model.evaluate(X_test, y_test)
print('Test accuracy:', score[1])
결과를 보려고 했는데....
df = pd.read_csv('./data/wine.csv', header=None)
여기에서 pd에 에러가 생겨서 볼 수가 없다.. 무슨 에러지....
--> 오류는 라이브러리를 때려박아서 해결함 굳
책에서 나온 결과는 76.46% 정확도에서 50번째에서 94.08%로 업데이트
3. 그래프로 과적합 확인하기
역전파를 50번 반복하면서 학습을 했다. 반복횟수는 적절해야한다.
기본적으로 많으면 좋지만 많으면 과적합 현상을 불러오기 때문이다.
적절한 학습 횟수를 정하기 위해서 검증셋과 학습셋의 결과 그래프를 보는 것이 좋다.
model.fit()을 사용하면서 결과를 history에 저장했었다
model.complie()에서 metrics를 accuracy로 지정하면 accuracy 값이 함께 출력됩니다.
loss는 학습을 통해 구한 예측 값과 실제 값의 차이(=오차)를 의미하고
accuracy는 전체 샘플중에서 정답을 맞춘 샘플이 몇개인지 비율(정확도)
val_loss는 학습한 모델을 검증셋에 적용해 얻은 오차
val_accuracy는 검증셋으로 얻은 정확도
history는 model.fit()의 결과를 가진 파이썬 객체
history.params에는 model.fit()의 설정 값
history.epoch에는 에포크 정보
필요한 loss, accuracy, val_loss, val_accuracy는 history.history
이를 판다스 라이브러리에 불러와보자
hist_df = pd.DataFrame(history.history)
hist_df
2,000번의 학습 결과가 저장되어 있음.
학습법을 적용해 얻은 오차(val_loss)는 y_vloss에 저장
학습셋에서 얻은 오차(loss)는 y_loss에 저장
y_vloss = hist_df['val_loss']
y_loss = hist_df['loss']
#그래프 확인을 위한 긴 학습
history = model.fit(X_train, y_train, epochs=2000, batch_size=500,
validation_split=0.25)
#history에 저장된 학습 결과를 확인
hist_df = pd.DataFrame(history.history)
hist_df
#y_vloss에 검증셋의 오차를 저장함
y_vloss = hist_df['val_loss']
#y_loss에 학습셋의 오차를 저장함
y_loss = hist_df['loss']
#x 값을 지정하고 검증셋의 오차를 빨간색으로, 학습셋의 오차를 파란색으로 표시함
x_len = np.arange(len(y_loss))
plt.plot(x_len, y_vloss, "o", c="red", markersize=2, label='Testset_loss')
plt.plot(x_len, y_loss, "o", c="blue", markersize=2, label='Trainset_loss')
plt.legend(loc='upper right')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
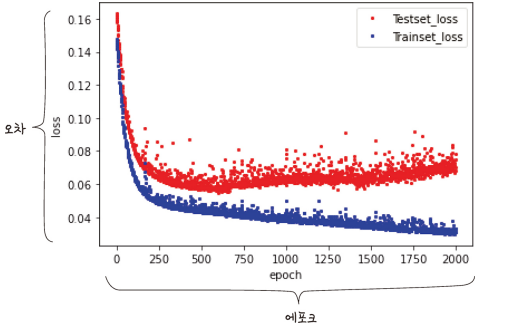
검증셋 오차가 커지기 직전까지 학습한 모델이 최적의 횟수로 학습한 모델
4. 학습의 중단
오차가 커지기 전에 학습을 자동으로 중단시키고, 그때의 모델을 저장하는 방법
텐서플로의 케라스 API는 Earlystopping()함수를 제공한다.
ModelCheckpoint() 함수와 사용해서 최적의 모델을 저장해보자
실습
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from sklearn.model_selection import train_test_split
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping
import os
import pandas as pd
#데이터를 입력합니다.
df = pd.read_csv('./data/wine.csv', header=None)
#와인의 속성을 X로 와인의 분류를 y로 저장합니다.
X = df.iloc[:,0:12]
y = df.iloc[:,12]
#학습셋과 테스트셋으로 나눕니다.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=True)
#모델 구조를 설정합니다.
model = Sequential()
model.add(Dense(30, input_dim=12, activation='relu'))
model.add(Dense(12, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.summary()
#모델을 컴파일합니다.
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
#학습이 언제 자동 중단 될지를 설정합니다.
early_stopping_callback = EarlyStopping(monitor='val_loss', patience=20)
#최적화 모델이 저장될 폴더와 모델의 이름을 정합니다.
modelpath="./data/model/Ch14-4-bestmodel.hdf5"
#최적화 모델을 업데이트하고 저장합니다.
checkpointer = ModelCheckpoint(filepath=modelpath, monitor='val_loss', verbose=0, save_best_only=True)
#모델 실행합니다.
history=model.fit(X_train, y_train, epochs=2000, batch_size=500, validation_split=0.25, verbose=1, callbacks=[early_stopping_callback,checkpointer])
#테스트 결과를 출력합니다.
score=model.evaluate(X_test, y_test)
print('Test accuracy:', score[1])
monitor옵션은 model.fit()의 실형 결과 중 어떤 것을 이용할지 정함.
검증셋의 오차는 val_loss로 지정
patience 옵션은 지정된 값이 몇 번 이상 향상되지 않으면 학습을 종료
monitor = 'val_loss', patience = 20이면 검증셋의 오차가 20번 이상 낮아지지 않으면 학습을 종료하는 의미
이번에는 최고의 모델 1개만 저장되게끔 해보자.
에포크나 정확도를 포함하지 않고,
ModelCheckpoint()의 save_best_only 옵션을 True로 설정
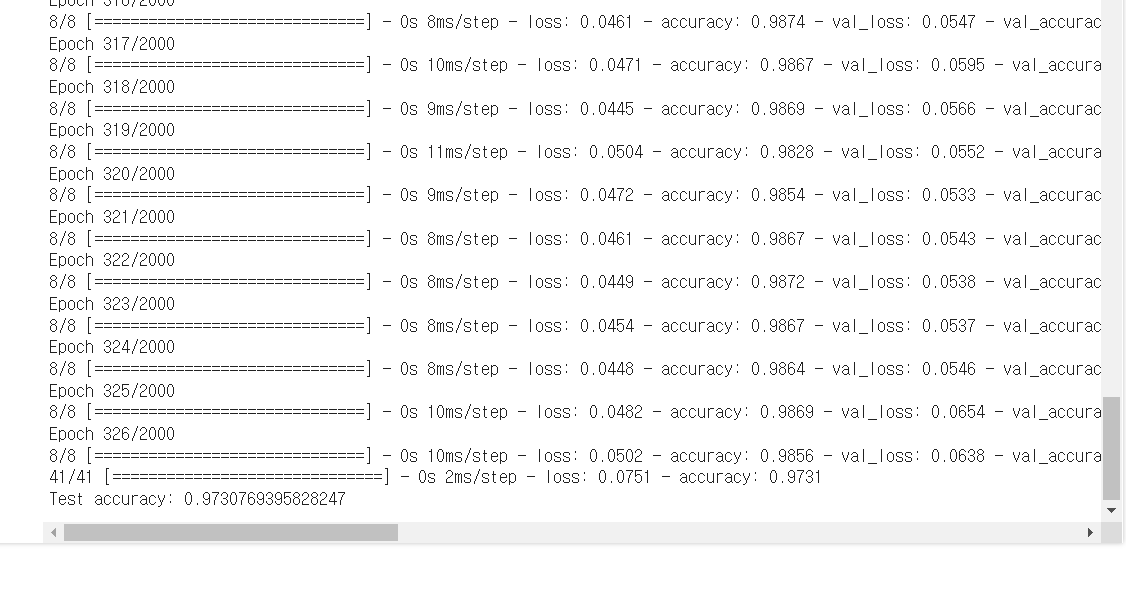
epoch를 넉넉하게 2000으로 했지만 정확도는 0.97307에서 멈춤
성능이 향상된 것을 볼 수 있었다. 짝짝짝
[^출처]: 모두의 딥러닝 개정 3판 (지은이: 조태호)
