아이오와주 에임스 지역에서 2006년부터 2010까지 거래된 부동산 판매기록을 보았을 때 80개의 서로 다른 속성이 존재했다.
주거 유형, 차고, 자재 및 환경에 관한 다른 속성을 이용해 볼건데
빠진 자료, 부족한 자료가 포함되어 있다.
이때 어떻게 할 것인가?
1. 데이터 파악하기
먼저 데이터를 불러오자
import pandas as pd
#깃허브에 준비된 데이터를 가져온다.
!git clone https://github.com/taehojo/data.git
#집 값 데이터를 불러온다.
df = pd.read_csv("./data/house_train.csv")
#데이터 미리 살펴보기
df
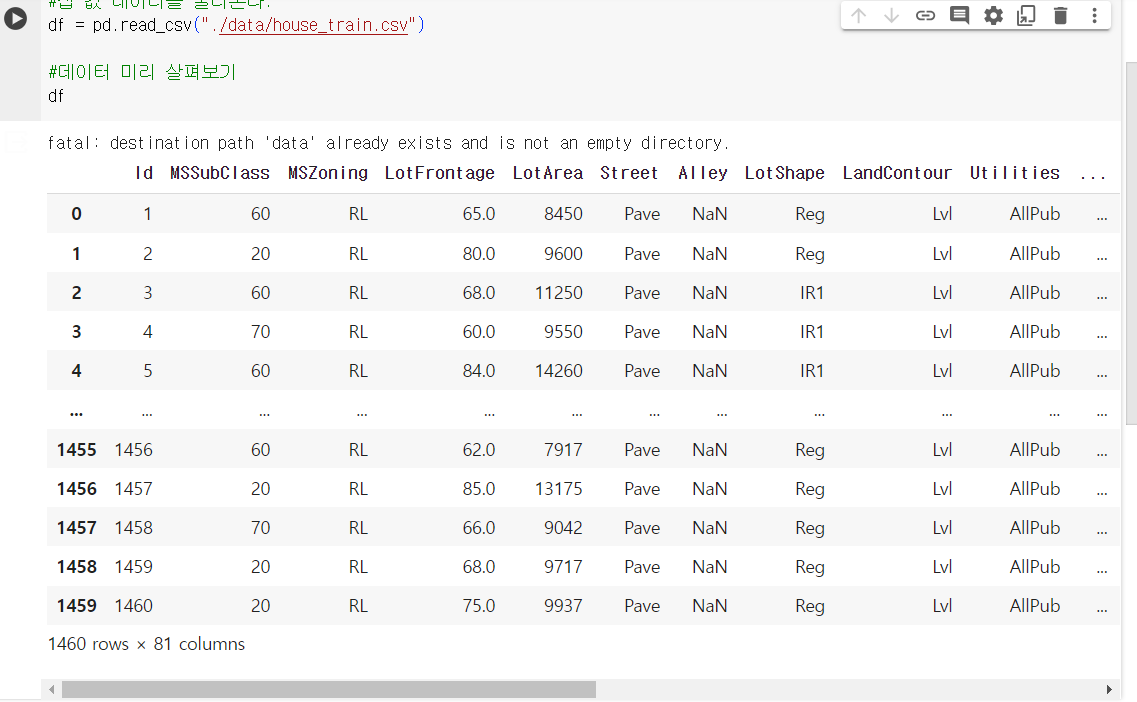
80개의 속성으로 이루어져있고, 마지막 열이 타겟인 집 값
1460개의 샘플이 있다.
각 데이터가 어떤 유형으로 되어 있는지 알아보자.
df.dtypes
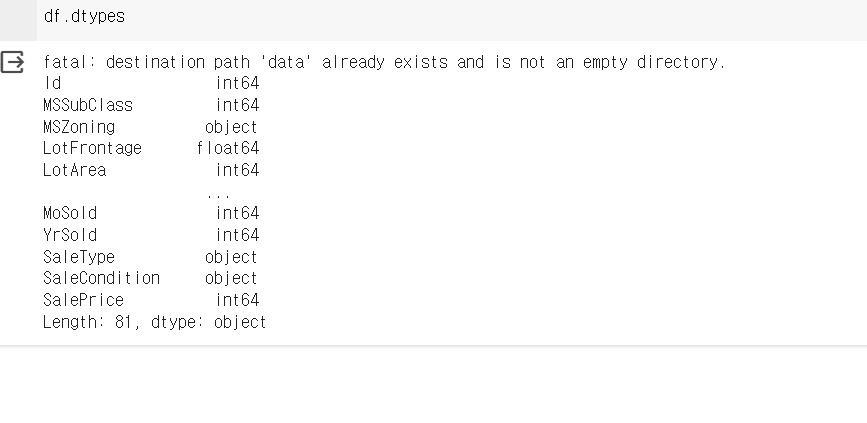
정수형 int64 그리고 실수형(float64), 오브젝트형(object)이 있는게 보인다.
2. 결측치, 카테고리 변수 처리하기
구글에서 결측치는 수집된 데이터 셋 중 관측되지 않은 특정 확률변수의 값
결측치가 있는지 알아보는 함수는 isnull()이다.
결측치가 모두 몇 개인지 세어 가장 많은 것부터 순서대로 나열
처음 20개만 출력하는 코드는 다음과 같다.
df.isnull().sum.sort_values(ascending=False).head(20)
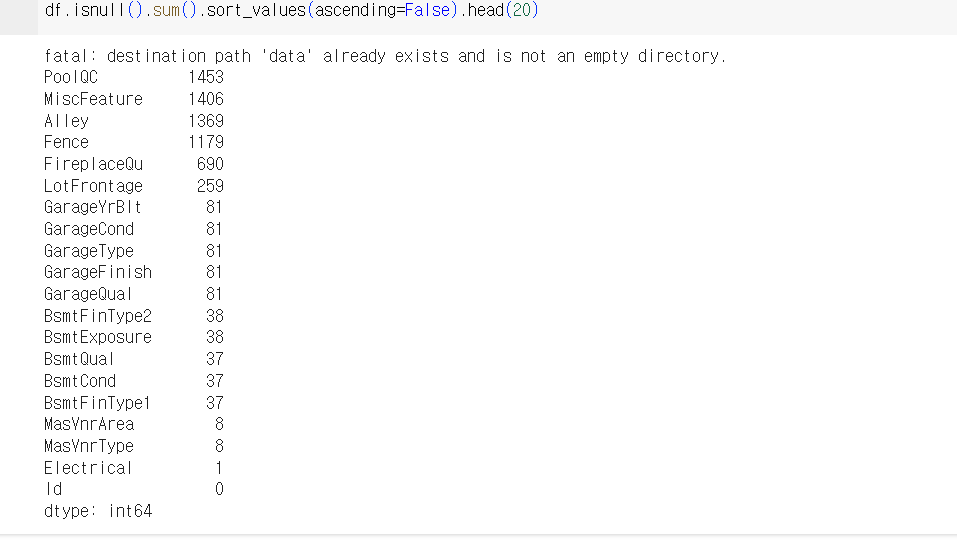
결측치를 확인했으니 데이터를 전처리 해보자.
판다스의 get_dummies()함수를 이용해 카테고리형 변수를 0과 1로 이루어진 변수로 바꾼다.
df = pd.get_dummies(df)
그리고 결측치를 채워 준다. 결측치를 채워 주는 함수는 판다스의 fillna()입니다. 괄호 안에 df.mean()을 넣어주면 값을 평균으로 채움.
df = df.fillna(df.mean())
그리고 관측
df
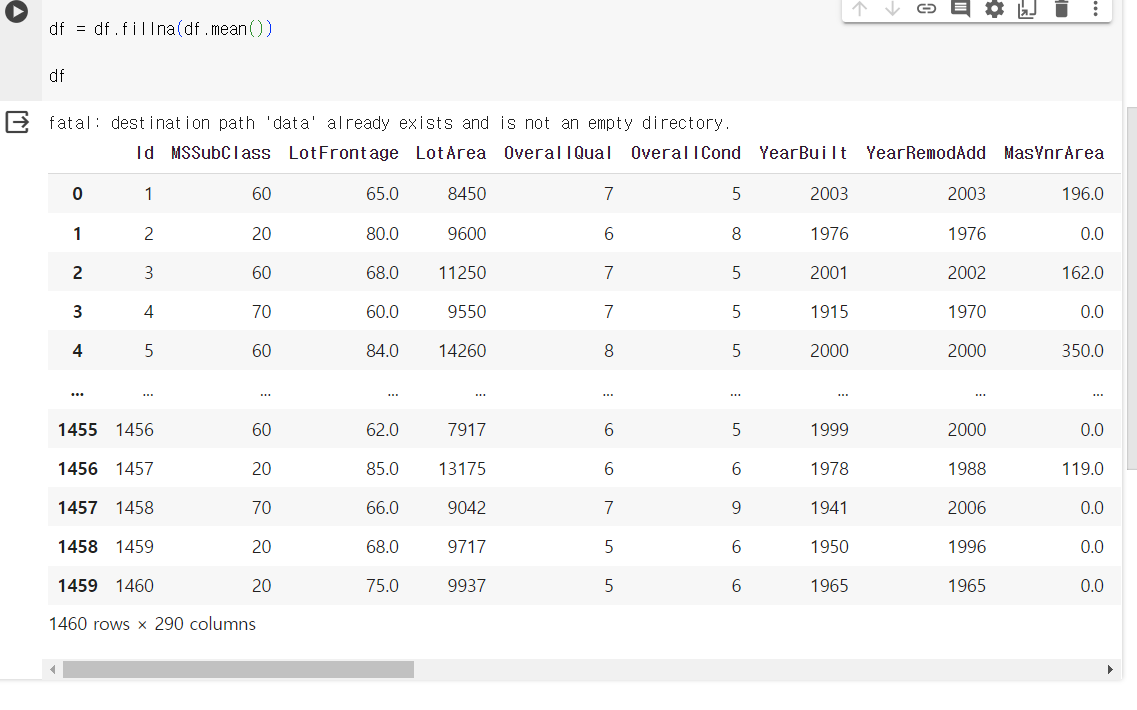
--> 결측치가 보이지 않고, 카테고리형 변수를 모두 원-핫 인코딩 처리
81개에서 290개로 열이 증가함.
원-핫 인코딩
단어 집합의 크기를 벡터의 차원으로 하고, 표현하고 싶은 단어의 인덱스에 1의 값을 부여하고, 다른 인덱스에는 0을 부여하는 단어의 벡터 표현 방식
3. 속성별 관련도 추출하기
이제 필요한 정보를 추출해보자
1. 데이터 사이의 상관관계를 df_corr변수에 저장
2. 집 값과 관련이 큰 것부터 순서대로 정렬해 df_corr_sort 변수에 저장
3. 집 값과 관련도가 가장 큰 열 개의 속성들을 출력
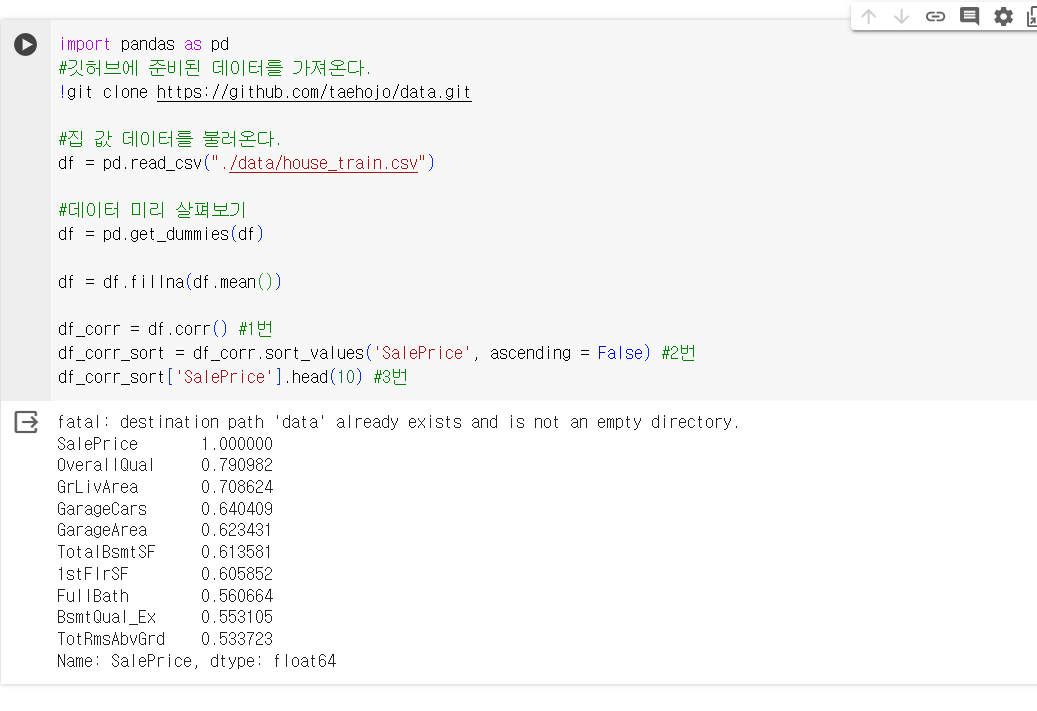
df_corr = df.corr() #1번
df_corr_sort = df_corr.sort_values('SalePrice', ascending = False) #2번
df_corr_sort['SalePrice'].head(10) #3번
추출된 속성들과 집 값의 관련도를 시작적으로 확인하기 위해 상관도 그래프
cols = ['SalePrice','OverallQual','GrlivArea','GarageCars','GarageArea','TotalBsmtSF']
sns.pairplot(df[cols])
plt.show()
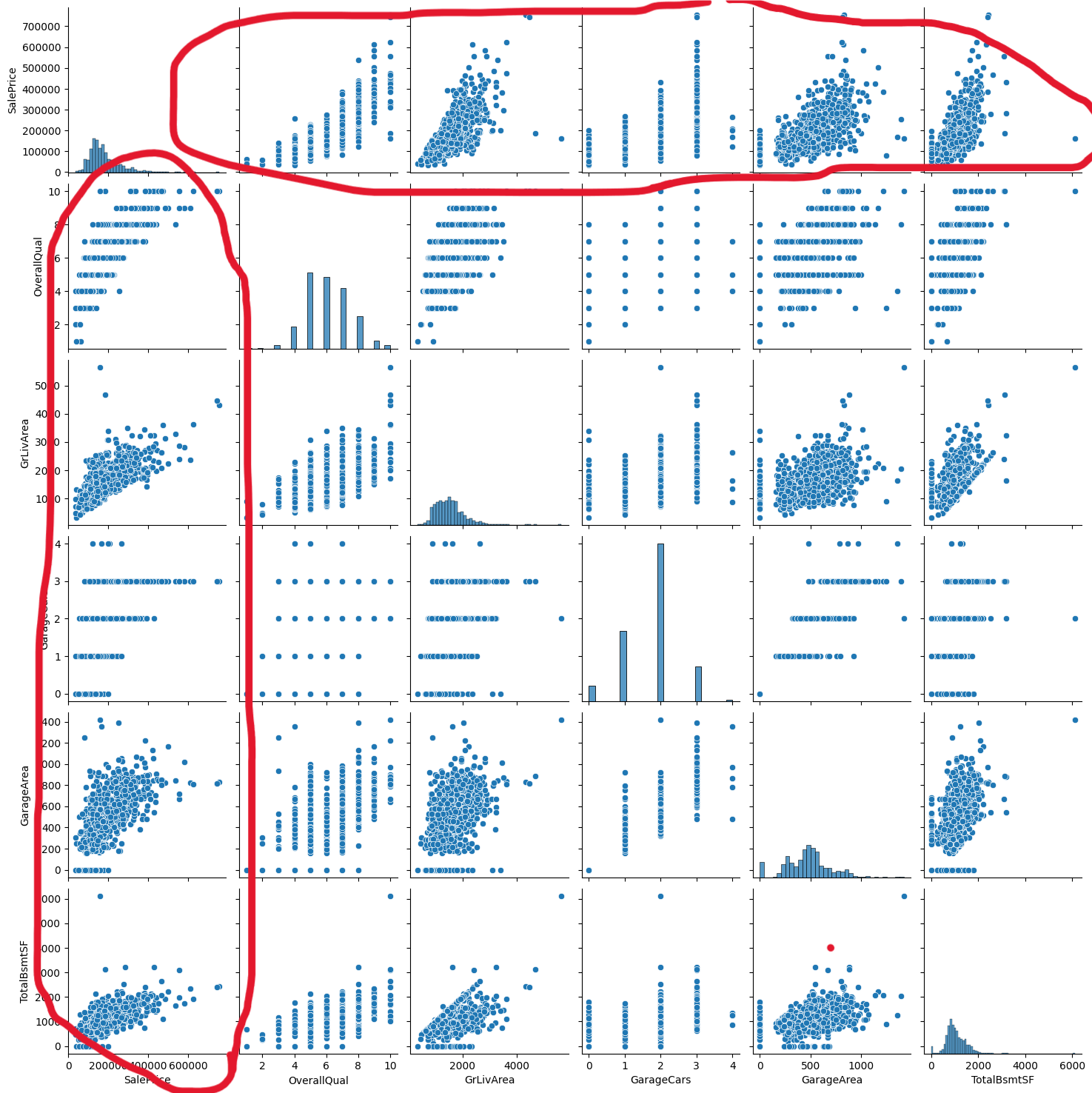
빨간색으로 그린 부분이 집 값과 상관이 있음을 확인 가능하다.
X,Y축을 보았을 때
4.주택 가격 예측 모델
중요 속성을 이용해 학습셋과 테스트셋을 만들어 보자.
집 값을 y로, 나머지 열을 X_train_pre로 저장한 후
전체의 80%를 학습셋으로, 20%를 테스트셋으로 지정
cols_train = ['OverallQual','GrlivArea','GarageCars','GarageArea','TotalBsmtSF']
X_train_pre = df[cols_train]
y = df['SalePrice'].values
X_train, X_test, y_train, y_test = train_test_split(X_train_pre, y, test_size = 0.2)
#test_size = 0.2 부분이 20%를 테스트셋으로 지정한 것
모델의 구조와 실행 옵션을 설정한다.
입력될 속성의 개수를 X_train.shape[1]로 지정해 자동으로 세도록 했습니다.
model = Sequential()
model.add(Dense(10, input_dim=X_train.shape[1],activation='relu'))
model.add(Dense(30, activation = 'relu'))
model.add(Dense(40, activation = 'relu'))
model.add(Dense(1))
model.summary()
실행에서 달라진 점은 손실 함수.
선형 회귀이므로 평균 제곱 오차('mean_squared_error')
model.compile(optimizer='adam', loss='mean_squared_error')
20번 이상 결과가 향상되지 않으면 자동으로 중단
early_stopping_callback = EarlyStopping(monitor='val_loss', patience = 20)
modelpath = "./data/model/Ch15-house.hdf5"
checkpointer = ModelCheckpoint(filepath=modelpath, monitor = 'val_loss', verbose=0, save_best_only=True)
history = model.fitX_train, y_train, validation_split=0.25,epochs=2000,batch_size=32, callbacks=[early_stopping_callback,checkpointer])
모든 코드를 모으면
from sklearn.model_selection import train_test_split
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
from sklearn.model_selection import train_test_split
import pandas as pd
import matplotlib.pyplot as plt
#집 값을 제외한 나머지 열을 저장
cols_train=['OverallQual','GrLivArea','GarageCars','GarageArea','TotalBsmtSF']
X_train_pre = df[cols_train]
#집 값을 저장
y = df['SalePrice'].values
#전체의 80%를 학습셋으로, 20%를 테스트셋으로 지정.
X_train, X_test, y_train, y_test = train_test_split(X_train_pre, y, test_size=0.2)
#모델의 구조를 설정.
model = Sequential()
model.add(Dense(10, input_dim=X_train.shape[1], activation='relu'))
model.add(Dense(30, activation='relu'))
model.add(Dense(40, activation='relu'))
model.add(Dense(1))
model.summary()
#모델을 실행.
model.compile(optimizer ='adam', loss = 'mean_squared_error')
#20회 이상 결과가 향상되지 않으면 자동으로 중단되게끔 함.
early_stopping_callback = EarlyStopping(monitor='val_loss', patience=20)
#모델의 이름을 정함.
modelpath="./data/model/Ch15-house.hdf5"
#최적화 모델을 업데이트하고 저장.
checkpointer = ModelCheckpoint(filepath=modelpath, monitor='val_loss', verbose=0, save_best_only=True)
#실행 관련 설정을 하는 부분입니다. 전체의 20%를 검증셋으로 설정.
history = model.fit(X_train, y_train, validation_split=0.25, epochs=2000, batch_size=32, callbacks=[early_stopping_callback, checkpointer])
학습 결과를 시각화하기 위한 코드
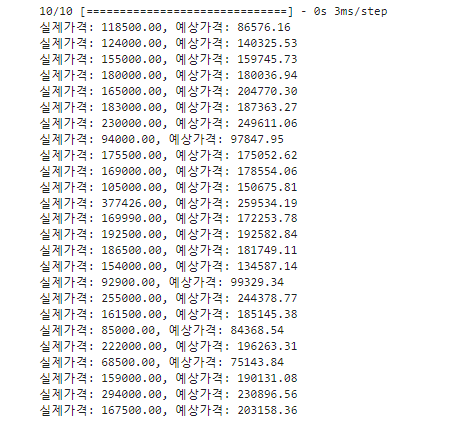
에측 값, 실제 값, 실행 번호가 들어갈 빈 리스트를 만들고 25개의 샘플로부터 얻은 결과를 채움.
real_prices = []
pred_prices = []
X_num = []
n_iter = 0
Y_prediction = model.predict(X_test).flatten()
for i in range(25):
real = y_test[i]
prediction = Y_prediction[i]
print("실제가격: {:.2f}, 예상가격: {:.2f}".format(real, prediction))
real_prices.append(real)
pred_prices.append(prediction)
n_iter = n_iter + 1
X_num.append(n_iter)
#그래프를 통해 샘플로 뽑은 25개의 값을 비교해보자
plt.plot(X_num, pred_prices, label='predicted price')
plt.plot(X_num, real_prices, label='real price')
plt.legend()
plt.show()
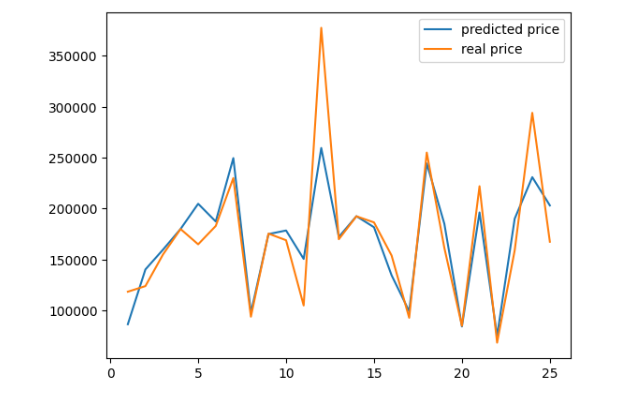
결과가 유사하게 나타난다.
[^출처]: 모두의 딥러닝 개정 3판 (지은이: 조태호)
