인공지능 비서는 사람의 말을 듣고 대답을 해준다. 이는 사람의 언어를 이해하는 능력이 필요하다는 것.
이번 장에서는 자연어 처리에 대해 배워보자
1. 텍스트의 토큰화
자연어의 전처리
입력될 테스트가 준비되면 이를 단어별, 문장별, 형태소별로 나눌 수 있다.
토큰 이렇게 작게 나누어진 하나의 단위
토큰화 입력된 텍스트를 잘게 나누는 과정
ex) '해보지 않으면 해낼 수 없다.'
케라스가 제공하는 text 모듈의 text_to_word_sequence()함수를 사용하면 쉽게 나누기가 가능하다.
from tensorflow.keras.preprocessing.text import text_to_woed_sequence
#전처리할 텍스트를 정합니다.
text = '해보지 않으면 해낼 수 없다.'
#해당 텍스트를 토큰화합니다.
result = text_to_word_sequence(text)
print("\n원문:\n", text)
print("\n토큰화:\n", result)
결과는
원문:
해보지 않으면 해낼 수 없다
토큰화:
['해보지', '않으면 '해낼', '수', 없다]
이번에는 단어를 세어 출현 빈도가 높은 것 부터 나열해보자
from tensorflow.keras.preprocessing.text import Tokenizer
docs = ['먼저 텍스트의 각 단어를 나누어 토큰화합니다.',
'텍스트의 단어로 토큰화해야 딥러닝에서 인식됩니다.'
'토큰화한 결과는 딥러닝에서 사용할 수 있습니다.' , ]
token = Tokenizer() #토큰화 함수 지정
token.fit_on_texts(docs) #토큰화 함수에 문장 적용
print("\n단어 카운트:\ㅜ, token.word_counts)
#단어의 빈도수를 계산한 결과 출력

print("\n문장 카운트: ", token.document_count)
문장 카운트: 3
word_docs()함수를 통해 각 단어들이 몇 개의 문장에 나오는지 세어서 출력도 가능
print("\n각 단어가 몇 개의 문장에 포함되어 있는가:\n", token.word_docs)
각 단어에 매겨진 인덱스 값을 출력하려면 word_index()함수를 사용하면 된다.
print("\n각 단어에 매겨진 인덱스 값:\n", token.word_index)
2. 단어의 원-핫 인코딩
원-핫 인코딩 단어가 문장의 다른 요소와 어떤 관계를 가지고 있는지 알아보는 방법
'오랫동안 꿈꾸는 이는 그 꿈을 닮아간다'
긱 딘어를 모두 0으로 바꾸어 주고 원하는 단어만 1로 바꿔주는 것이
원-핫 인코딩
[0(인덱스) 0(오랫동안) 0(꿈꾸는) 0(이는) 0(그) 0(꿈을) 0(닮아간다)]
이러한 과정을 케라스로 실습
text = "오랫동안 꿈꾸는 이는 그 꿈을 닮아간다"
token = Tokenizer()
token.fit_on_texts([text])
print(token.word_index)
결과는 다음과 같다.
{'오랫동안': 1, '꿈꾸는': 2, '이는': 3, '그': 4, '꿈을': 5, '닮아간다' :6}
케라스에서 제공하는 Tokenizer의 texts_to_sequences()함수를 사용해서 앞서 만들어진 토큰의 인덱스로만 채워진 새로운 배열을 만든다.
x = token.texts_to_sequences([text])
print(x)
실행결과 [[1,2,3,4,5,6]]
실행결과가 1~6의 정수로 인덱스되어 있는 것을 0과 1로만 이루어지게 바꿈.
to_categorical()함수를 사용해서
코드
from tensorflw.keras.utils import to_categorical
#인덱스 수에 하나를 추가해서 원-핫 인코딩 배열 만들기
word_size = len(token.word_index) + 1
x = to_categorical(x,num_classes=word_size)
print(x)
결과
[[[0.1.0.0.0.0.0] 오랫동안
[0.0.1.0.0.0.0] 꿈꾸는
[0.0.0.1.0.0.0] 이는
.
.
[0.0.0.0.0.0.1]]] 닮아간다
3. 단어 임베딩
원-핫 인코딩 방식을 사용하면 너무 많은 0이 들어가서 낭비임
--> 단어 임베딩 공간적 낭비 해결을 위해 등장
단어 임베딩
주어진 배열으 정해진 길이로 압축시킨다.
단어 간 유사도
적절한 크기로 배열을 바꾸어 주기 위해 최적의 유사도를 계산하는 학습과정
이 과정은 케라스 제공의 Embedding()함수를 사용해서 만들수 있다.
예를 들어 Embedding() 함수를 적용해 딥러닝 모델을 만들 수 있음.
코드
from tensorflow.keras.layer import Embedding
model = Sequential()
model.add(Embedding(16,4))
출력될 총 단어수 는 16, 임베딩 후 출력되는 벡터 크기는 4
Embedding(16, 4, input_length=2)라고 하면 총 입력되는 단어 수는 16개, 매번 2개씩 넣겠다는 의미
4.텍스트를 읽고 긍정, 부정 예측
영화를 보고 긍정적이면 1 부정적이면 0을 주는 과제
코드
#텍스트 리뷰 자료를 지정합니다.
docs = ['너무 재밌네요', '최고에요', '참 잘 만든 영화에요', '추천하고 싶은 영화입니다.' , '한 번 더 보고싶네요', '글쎄요', '생각보다 지루하네요', '연기가 어색해요', '재미없어요.']
#긍정 리뷰는 1, 부정 리뷰는 0으로 클래스를 지정합니다.
class = array([1,1,1,1,1,0,0,0,0,0])
#토큰화
token = Tokenizer()
token.fit_on_texts(docs)
print(token.word_index) #토큰화된 결과를 출력해 확인합니다.
#이제 토큰에 지정된 인덱스로 새로운 배열을 생성한다.
x = token.texts_to_sequences(docs)
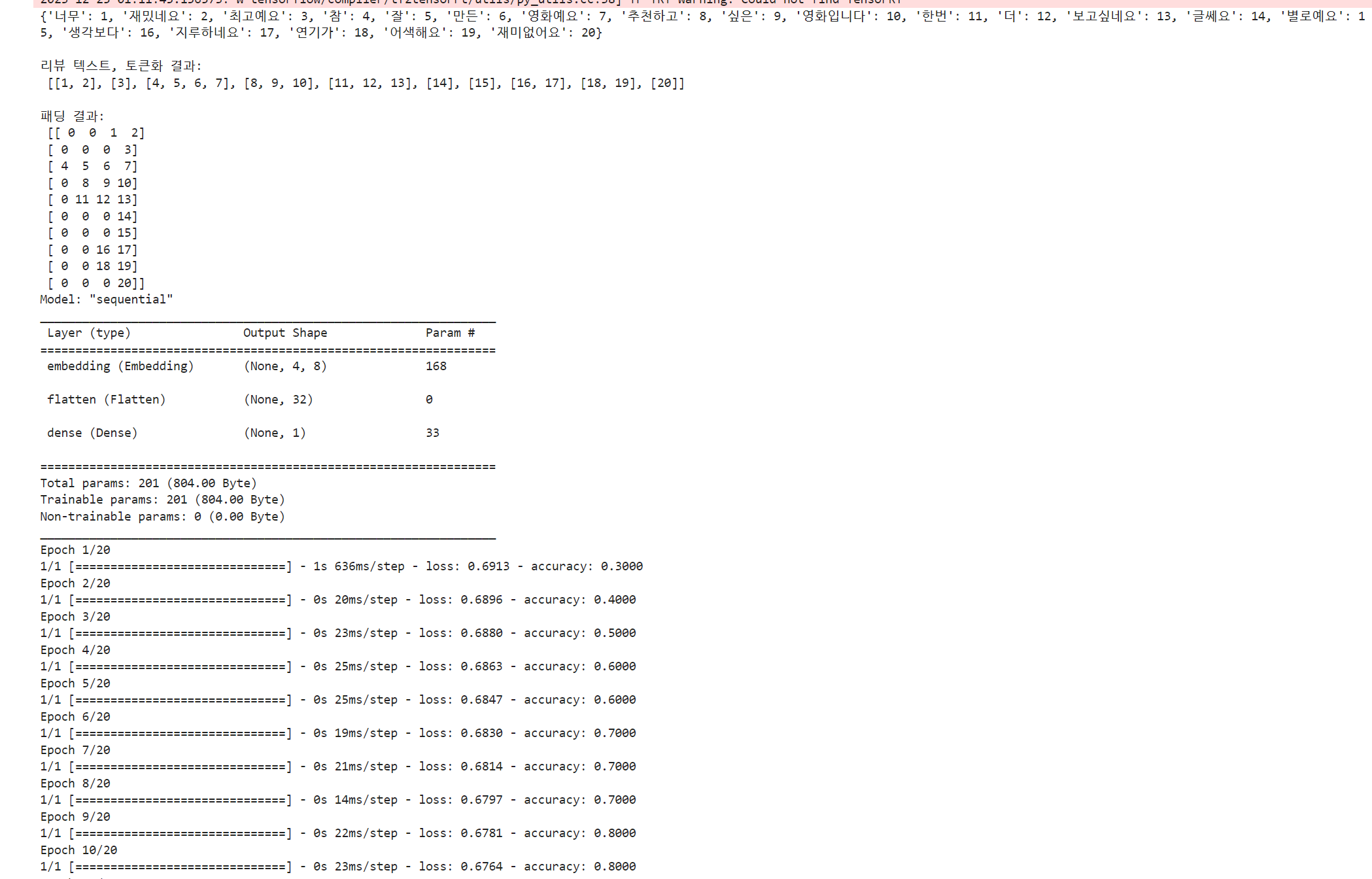
print("\n리뷰 텍스트, 토큰화 결과:\n", x)
결과
문장마다 토큰으로 만들어짐
토큰으로 이루어진 문장을 보여줌.
패딩
딥러닝 모델에 입력하려면 학습 데이터의 길이가 동일해야 한다.
이처럼 길이를 맞춰주는 작업을 패딩이라고 함. (19장 사용예정)
케라스는 패딩 작업을 위해 pad_sequences()함수를 제공
pad_sequences()함수는 원하는 길이보다 짧은 부분은 숫자0을 넣어주고 긴 데이터는 잘라서 같은 길이로 맞춰준다.
패딩 코드
padded_x = pad_sequences(x, 4) #서로 다른 길이의 데이터를 4로 맞춤
print("\n패딩 결과:\n", padded_x)
결과
패딩 결과:
[[ 0 0 1 2][ 0 0 0 3]
[ 4 5 6 7][ 0 8 9 10]
.
.
.
[ 0 0 0 20]]
임베딩 함수에 필요한 파라미터는 '입력, 출력, 단어 수' 입니다.
- 먼저 몇 개의 인덱스가 '입력'되어야 하는지 정하고, word_size라는 변수를 만든 후 길이를 세는 len()함수를 이용해 word_index 값을 앞서 만든 변수에 대입
전체 단어 앞에 0이 먼저 나와야 하므로 총 단어수에 1을 더하자!
word_size = len(token.word_index) + 1
-
'출력'을 정할 차례
word_size만큼 입력 값을 이용해 여덟 개의 임베딩 결과를 만들자.
8은 임의로 정한 것, 데이터에 따라 적절한 값으로 바꿀 수 있음 -
매번 입력 될 '단어 수'를 정한다.
실습 영화리뷰 긍정? 부정?
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten, Embedding
from tensorflow.keras.utils import to_categorical
from numpy import array
#텍스트 리뷰 자료를 지정합니다.
docs = ["너무 재밌네요","최고예요","참 잘 만든 영화예요","추천하고 싶은 영화입니다"
,"한번 더 보고싶네요","글쎄요","별로예요","생각보다 지루하네요","연기가 어색해요",
"재미없어요"]
#긍정 리뷰는 1, 부정 리뷰는 0으로 클래스를 지정합니다.
classes = array([1,1,1,1,1,0,0,0,0,0])
#토큰화
token = Tokenizer()
token.fit_on_texts(docs)
print(token.word_index)
x = token.texts_to_sequences(docs)
print("\n리뷰 텍스트, 토큰화 결과:\n", x)
#패딩, 서로 다른 길이의 데이터를 4로 맞추어 줍니다.
padded_x = pad_sequences(x, 4)
print("\n패딩 결과:\n", padded_x)
#임베딩에 입력될 단어의 수를 지정합니다.
word_size = len(token.word_index) + 1
#단어 임베딩을 포함해 딥러닝 모델을 만들고 결과를 출력합니다.
model = Sequential()
model.add(Embedding(word_size, 8, input_length=4))
model.add(Flatten())
model.add(Dense(1, activation='sigmoid'))
model.summary()
model.compile(optimizer='adam', loss='binary_crossentropy',
metrics=['accuracy'])
model.fit(padded_x, classes, epochs=20)
print("\n Accuracy: %.4f" % (model.evaluate(padded_x, classes)[1]))
[^출처]: 모두의 딥러닝 개정 3판 (지은이: 조태호)
