의미를 전달하려면 각 단어가 정해진 순서대로 입력되어야 하기 때문입니다.
즉, 여러 데이터가 순서와 관계없이 입력되던 것과 다르게, 이번에는 과거에 입력된 데이터와 나중에 입력된 데이터 사이의 관계를 고려해야 하는 문제 생김.
순환 신경망
순환 신경망은 여러 개의 데이터가 순서대로 입력되었을 때 앞서 입력받은 데이터를 잠시 기억하는 방법
그리고 기억된 데이터가 얼마나 중요한지 판단하고 별도의 가중치를 주어 다음 데이터로 넘어감.
모든 입력 값에 이 작업을 순서대로 실행하므로 다음 층으로 넘어가기 전에 같은 층에 맴도는 것처럼 보임.
LSTM
현재는 이 방법을 가장 많이 쓰고 있음.
반복되기 직전에 다음 층으로 기억된 값을 넘길지 여부를 관리하는 단계를 추가한 것
RNN방법의 활용
1. 다수 입력 단일 출력 - 문장을 읽고 뜻을 파악할 때 활용
2. 단일 입력 다수 출력 - 사진의 캡션을 만들 때 활용
3. 다수 입력 다수 출력 - 문장을 번역할 때 활용
케라스는 데이터를 쉽게 내려받을 수 있게 load_data()함수를 제공한다.
MNIST외에도 RNN학습에 적절한 텍스트 대용량 데이터를 제공
1. LSTM을 이용한 로이터 뉴스 카테고리 분류하기
#로이터 뉴스 데이터셋 불러오기
from tensorflow.keras.datasets import reuters
#불러온 데이터를 학습셋과 데이터셋으로 나누기
(X_train, y_train), (X_test, y_test) = reuters.load_data(num_words=1000,test_split = 0.2)
reuters.load_data()함수를 이용해 기사를 불러오고 test_split을 통해 20%만 테스트셋으로 사용하겠다고 지정함.
#데이터를 확인 한 후 출력
category = np.max(y_train) + 1
print(category, '카테고리')
print(len(X_train), '학습용 뉴스 기사')
print(len(X_test), '테스트용 뉴스 기사')
print(X_train[0])
from tensorflow.keras.preprocessing import sequence
#단어의 수를 맞추어 줍니다.
X_train = sequence.pad_sequences(X_train, maxlen=100)
X_test = sequence.pad_sequences(X_test, maxlen=100)
코드의 뜻
num_words = 1000의 의미는 빈도가 1~1000에 해당하는 단어만 선택해서 불러옴
maxlen = 100은 단어 수를 100개로 맞추라는 의미
위의 코드 뒤는
y데이터에 원-핫 인코딩 처리를 하여 데이터 전처리 과정
#원-핫 인코딩 처리를 합니다.
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
딥러닝의 구조 만들기
#모델의 구조를 설정합니다.
model = Sequential()
model.add(Embedding(1000, 100))
model.add(LSTM(100, activation='tanh'))
model.add(Dense(46, activation='softmax'))
Embedding층 LSTM층 추가
#모델의 실행 옵션을 정합니다.
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) ----- 1
#학습의 조기 중단을 설정합니다.
early_stopping_callback = EarlyStopping(monitor='val_loss', patience=5) ----- 2
#모델을 실행합니다.
history = model.fit(Xtrain, y_train, batch_size=20, epochs=200, validation data=(X_test, y_test), callbacks=[early_stopping_callback]) ----- 3
Embedding층은 데이터 전처리 과정을 통해 입력된 값을 받아 다음 층이 알 수 있는 형태로 변환
LSTM층은 RNN에서 기억 값에 대한 가중치를 제어, LSTM 형식으로 적용
- 모델 실행의 옵션을 정하고
- 조기 중단 설정과 함께
- 학습을 실행
실습|LSTM 이용 로이터 뉴스 카테고리 분석
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM, Embedding
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.preprocessing import sequence
from tensorflow.keras.datasets import reuters
from tensorflow.keras.callbacks import EarlyStopping
import numpy as np
import matplotlib.pyplot as plt
#데이터를 불러와 학습셋, 테스트셋으로 나눕니다.
(X_train, y_train), (X_test, y_test) = reuters.load_data(num_words=1000, test_split=0.2)
#데이터를 확인해 보겠습니다.
category = np.max(y_train) + 1
print(category, '카테고리')
print(len(X_train), '학습용 뉴스 기사')
print(len(X_test), '테스트용 뉴스 기사')
print(X_train[0])
#단어의 수를 맞추어 줍니다.
X_train = sequence.pad_sequences(X_train, maxlen=100)
X_test = sequence.pad_sequences(X_test, maxlen=100)
#원-핫 인코딩 처리를 합니다.
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
#모델의 구조를 설정합니다.
model = Sequential()
model.add(Embedding(1000, 100))
model.add(LSTM(100, activation='tanh'))
model.add(Dense(46, activation='softmax'))
#모델의 실행 옵션을 정합니다.
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
#학습의 조기 중단을 설정합니다.
early_stopping_callback = EarlyStopping(monitor='val_loss', patience=5)
#모델을 실행합니다.
history = model.fit(X_train, y_train, batch_size=20, epochs=200, validation_data=(X_test, y_test), callbacks=[early_stopping_callback])
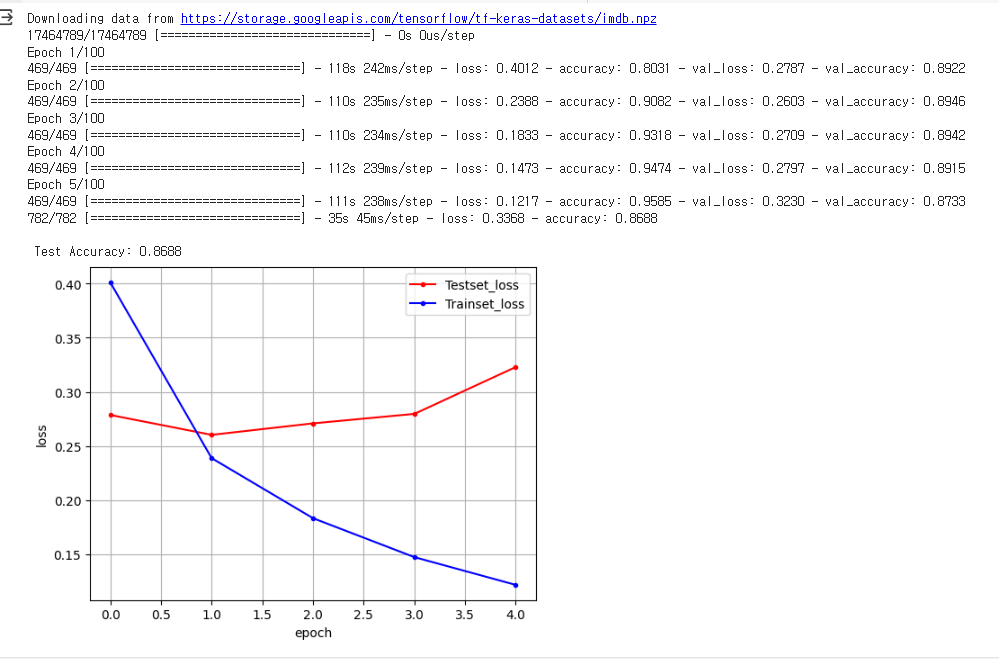
#테스트 정확도를 출력합니다.
print("\n Test Accuracy: %.4f" % (model.evaluate(x_test, y_test)[1]))
#학습셋과 테스트셋의 오차를 저장합니다.
y_vloss = history.history['val_loss']
y_loss = history.history['loss']
#그래프로 표현해 보겠습니다.
x_len = np.arange(len(y_loss))
plt.plot(x_len, y_vloss, marker='.', c="red", label='Testset_loss')
plt.plot(x_len, y_loss, marker='.', c="blue", label='Trainset_loss')
#그래프에 그리드를 주고 레이블을 표시하겠습니다.
plt.legend(loc='upper right')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
2. LSTM과 CNN의 조합을 이용한 영화 리뷰 분석하기
테스트셋 지정
#테스트셋을 지정합니다.
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=5000)
X_train = sequence.pad_sequences(x_train, maxlen=500)
X_test = sequence.pad_sequences(x_test, maxlen=500)
모델의 구조 생성
#모델의 구조를 설정합니다.
model = Sequential()
model.add(Embedding(5000, 100))
model.add(Dropout(0.5))
model.add(Conv1D(64, 5, padding='valid', activation='relu', strides=1))
model.add(MaxPooling1D(pool_size=4))
model.add(LSTM(55))
model.add(Dense(1))
model.add(Activation('sigmoid'))
model.summary()
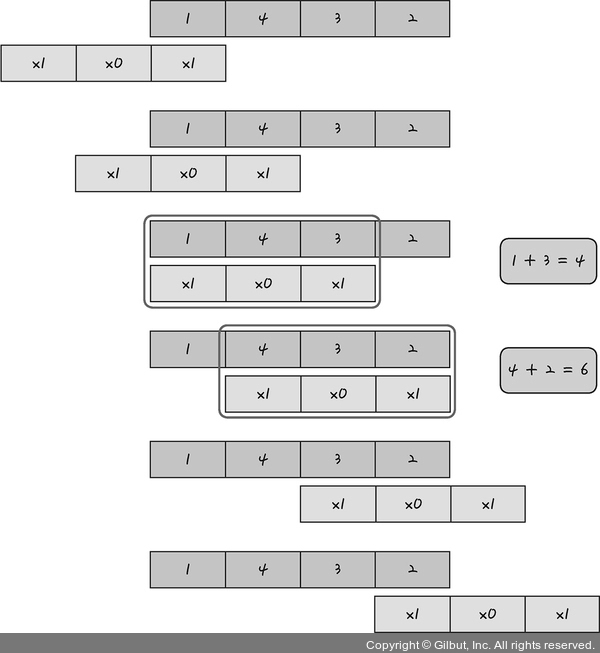
2번째 줄이 커널을 의미
커널이 지나가면서 원래의 1차원 배열에 가중치를 각각 곱해 새로운 층인 컨볼루션 층을 만듬.
실습| LSTM과 CNN을 조합해 영화 리뷰 분석
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Activation, Embedding, LSTM, Conv1D, MaxPooling1D
from tensorflow.keras.datasets import imdb
from tensorflow.keras.preprocessing import sequence
from tensorflow.keras.callbacks import EarlyStopping
import numpy as np
import matplotlib.pyplot as plt
#데이터를 불러와 학습셋, 테스트셋으로 나눕니다.
(X_train, y_train), (X_test, y_test) = imdb.load_data(num_words=5000)
#단어의 수를 맞춥니다.
X_train = sequence.pad_sequences(X_train, maxlen=500)
X_test = sequence.pad_sequences(X_test, maxlen=500)
#모델의 구조를 설정합니다.
model = Sequential()
model.add(Embedding(5000, 100))
model.add(Dropout(0.5))
model.add(Conv1D(64, 5, padding='valid', activation='relu', strides=1))
model.add(MaxPooling1D(pool_size=4))
model.add(LSTM(55))
model.add(Dense(1))
model.add(Activation('sigmoid'))
#모델의 실행 옵션을 정합니다.
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
#학습의 조기 중단을 설정합니다.
early_stopping_callback = EarlyStopping(monitor='val_loss', patience=3)
#모델을 실행합니다.
history = model.fit(X_train, y_train, batch_size=40, epochs=100, validation_split=0.25, callbacks=[early_stopping_callback])
#테스트 정확도를 출력합니다.
print("\n Test Accuracy: %.4f" % (model.evaluate(X_test, y_test)[1]))
#학습셋과 테스트셋의 오차를 저장합니다.
y_vloss = history.history['val_loss']
y_loss = history.history['loss']
#그래프로 표현해 보겠습니다.
x_len = np.arange(len(y_loss))
plt.plot(x_len, y_vloss, marker='.', c="red", label='Testset_loss')
plt.plot(x_len, y_loss, marker='.', c="blue", label='Trainset_loss')
#그래프에 그리드를 주고 레이블을 표시하겠습니다.
plt.legend(loc='upper right')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
3. 어텐션을 이용한 신경망
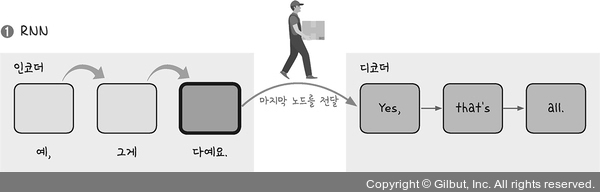
1은 인코더에 입력된 각 셀 값을 하나씩 뒤로 보내다가 맨 마지막 셀이 이 값을 디코더에 전달하는 것을 보여준다.
문맥 벡터 마지막 셀에 담긴 값에 전체 문장 뜻이 함축되어 있음
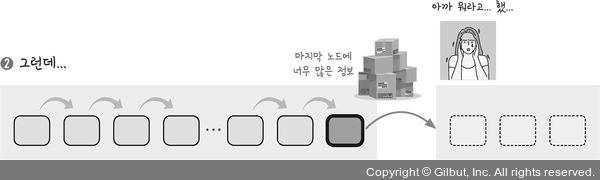
2를 보면 입력 값의 길이가 너무 길면 입력 받안 셀의 결과가 너무 많음
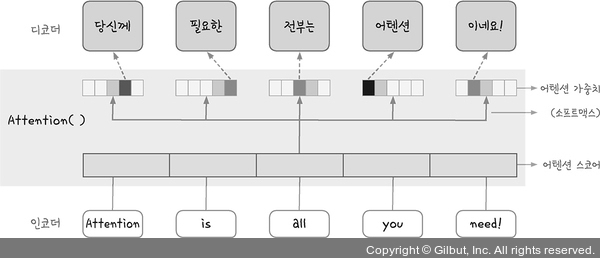
매 출력마다 모든 입력 값을 두루 활용하게 한 것이 어텐션
어텐션 라이브러리 설치
!pip install attention
model.add(attention())을 사용할 수 있게 됨.
실습
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Activation, Embedding, LSTM, Conv1D, MaxPooling1D
from tensorflow.keras.datasets import imdb
from tensorflow.keras.preprocessing import sequence
from tensorflow.keras.callbacks import EarlyStopping
from attention import Attention
import numpy as np
import matplotlib.pyplot as plt
#데이터를 불러와 학습셋, 테스트셋으로 나눕니다.
(X_train, y_train), (X_test, y_test) = imdb.load_data(num_words=5000)
#단어의 수를 맞춥니다.
X_train = sequence.pad_sequences(X_train, maxlen=500)
X_test = sequence.pad_sequences(X_test, maxlen=500)
#모델의 구조를 설정합니다.
model = Sequential()
model.add(Embedding(5000, 500))
model.add(Dropout(0.5))
model.add(LSTM(64, return_sequences=True))
model.add(Attention())
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation('sigmoid'))
#모델의 실행 옵션을 정합니다.
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
#학습의 조기 중단을 설정합니다.
early_stopping_callback = EarlyStopping(monitor='val_loss', patience=3)
#모델을 실행합니다.
history = model.fit(X_train, y_train, batch_size=40, epochs=100, validation_data=(X_test, y_test), callbacks=[early_stopping_callback])
#테스트 정확도를 출력합니다.
print("\n Test Accuracy: %.4f" % (model.evaluate(X_test, y_test)[1]))
#학습셋과 테스트셋의 오차를 저장합니다.
y_vloss = history.history['val_loss']
y_loss = history.history['loss']
#그래프로 표현해 보겠습니다.
x_len = np.arange(len(y_loss))
plt.plot(x_len, y_vloss, marker='.', c="red", label='Testset_loss')
plt.plot(x_len, y_loss, marker='.', c="blue", label='Trainset_loss')
#그래프에 그리드를 주고 레이블을 표시하겠습니다.https://thebook.io/080324/0304/
plt.legend(loc='upper right')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
결과는 너무 오래 기다려야할거 같아서... 못 적었다.
좋은 컴퓨터가 필요한 시점이다....
[^출처]: 모두의 딥러닝 개정 3판 (지은이: 조태호)
