
✍️ 4차 미니 프로젝트
📌미션: AIVLE-EDU 1:1 문의 유형 분류하기
활용 데이터
AIVLE School 2기 1 대 1 게시판 데이터(text, label)
도메인 이해
내가 참여하고있는 에이블스쿨에서는 일대일문의를 통해 코드, 이론, 시스템운영에 관한 궁금증을 해소한다.
이 때 텍스트 분류를 통해 문의 유형을 분류한다면 더욱 빠른 피드백을 받을 수 있을 것이다!
문의 내용을 분석, 전처리해서 문의 유형 분류기를 만들어보자😝
✔️데이터 분석
display(train_df.head(10))
# label 데이터 분포를 확인합니다.
display(train_df.label.value_counts())
print("-"*100)
norm_label = train_df.label.value_counts(normalize=True)
display(norm_label)
norm_label.plot.bar(figsize=(5,5),color=sns.color_palette('hls',n_colors = len(norm_label)))
plt.show()
train_df.info()
display(train_df.describe(include='all'))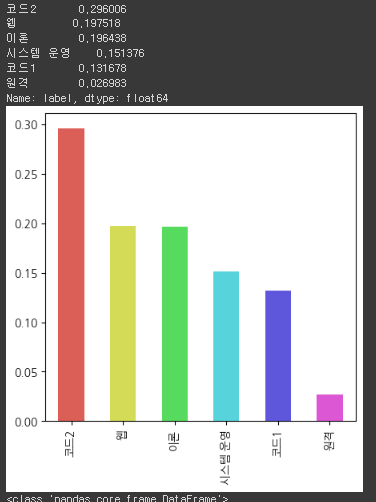
코드에 대한 질문이 가장 많았고, 원격에 관한 질문은 데이터가 현저히 적었다. 추후에 오버샘플링과 같은 클래스 불균형 처리를 시도해봐도 좋겠다고 생각했다.
plt.figure(figsize=(8,4))
plt.title("명사 개수 : " + str(len(nltk_nouns.tokens)))
nltk_nouns.plot(20)
plt.show()
plt.figure(figsize=(8,4))
plt.title("품사 태깅 개수 : " + str(len(nltk_pos.tokens)))
nltk_pos.plot(20)
plt.show()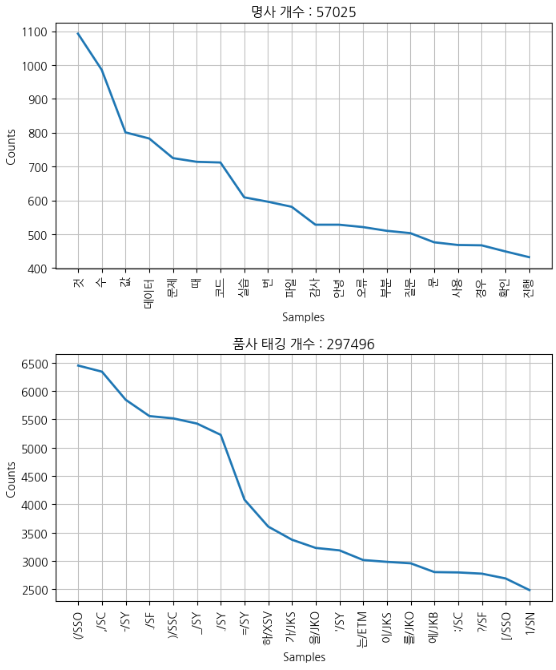
명사 태깅을 통해 분포를 보았을 때 '것', '수'등이 많았다. 지금 정리하며 다시 보니 것과 같은 단어를 처리해주는 것도 하나의 방법이 될 수 있었을 것 같다.
cloud = WordCloud(
max_font_size=100, max_words=50,
background_color='white', relative_scaling=.5,
width=800, height=600, font_path=FONT_PATH).generate(" ".join(nltk_nouns))
plt.figure(figsize=(12, 6))
plt.imshow(cloud, interpolation='bilinear')
plt.axis('off')
plt.show()
cloud = WordCloud(
max_font_size=100, max_words=50,
background_color='white', relative_scaling=.5,
width=800, height=600, font_path=FONT_PATH).generate(" ".join(nltk_morphs))
plt.figure(figsize=(12, 6))
plt.imshow(cloud, interpolation='bilinear')
plt.axis('off')
plt.show()워드 클라우드를 통해 명사 태깅한 결과를 시각화하였다.



✔️데이터 전처리
label_dict = {
'코드1': 0,
'코드2': 0,
'웹': 1,
'이론': 2,
'시스템 운영': 3,
'원격': 4
}
preprocessed_df = train_df.replace({'label': label_dict}).copy()
각 레이블를 숫자로 매핑시켜주었다.
import re
import string
#removal_list = "‘, ’, ◇, ‘, ”, ’, ', ·, \“, ·, △, ●, , ■, (, ), \", >>, `, /, -,∼,=,ㆍ<,>, .,?, !,【,】, …, ◆,%"
removal_list = "‘’◇‘”’'·\“·△●■()\">>`/-∼=ㆍ<>.?!【】…◆%"
removal_list += string.punctuation
def cleansing_special(sentence: str = None) -> str:
"""
특수문자를 전처리를 하는 함수
:param sentence: 전처리 대상 문장
:return: 전처리 완료된 문장
"""
#sentence = re.sub("[.,\'\"’‘”“!?]", "", sentence)
sentence = re.sub("[^가-힣0-9a-zA-Z\\s]", " ", sentence)
sentence = re.sub("\s+", " ", sentence)
sentence = sentence.translate(str.maketrans(removal_list, ' '*len(removal_list)))
sentence = sentence.strip()
return sentence특수문자 제거를 해주었다.
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
mecab_cv = CountVectorizer(tokenizer=mecab_tokenizer)
okt_cv = CountVectorizer(tokenizer=okt_tokenizer)
# 내부적으로 transformer 클래스로 l2 방식으로 벡터 정규화하여 tf-idf 값 계산
okf_tv = TfidfVectorizer(tokenizer=okt_tokenizer, norm='l2')
x_tr_mecab_cv = mecab_cv.fit_transform(x_train)
x_te_mecab_cv = mecab_cv.transform(x_test)
x_tr_okt_cv = okt_cv.fit_transform(x_train)
x_te_okt_cv = okt_cv.transform(x_test)
x_tr_okt_tv = okf_tv.fit_transform(x_train)
x_te_okt_tv = okf_tv.transform(x_test)
tf_transformer = TfidfTransformer()
x_tr_me_tf = tf_transformer.fit_transform(x_tr_mecab_cv)
x_te_me_tf = tf_transformer.transform(x_te_mecab_cv)
x_tr_okt_tf = tf_transformer.fit_transform(x_tr_okt_cv)
N-grams처리를 해주었다. okt, mecab등을 통해 형태소 분석을 진행하고, tf-idf가중치를 통해 표현해주었다.
%%time
import tensorflow as tf
import numpy as np
import tensorflow.keras as keras
from keras.preprocessing import sequence
from keras.preprocessing import text
TOP_K = 5000
MAX_SEQUENCE_LENGTH = 500
X_mor_tr_str = X_tr.apply(lambda x:' '.join(mecab_tokenizer(x)))
X_mor_val_str = X_val.apply(lambda x:' '.join(mecab_tokenizer(x)))
X_mor_tr = X_tr.apply(lambda x:mecab_tokenizer(x))
X_mor_val = X_val.apply(lambda x:mecab_tokenizer(x))
tokenizer_str = text.Tokenizer(num_words=TOP_K, char_level=False)
tokenizer_str.fit_on_texts(X_mor_tr_str)
X_mor_tr_seq_str = tokenizer_str.texts_to_sequences(X_mor_tr_str)
X_mor_val_seq_str = tokenizer_str.texts_to_sequences(X_mor_val_str)
max_length = len(max(X_mor_tr_seq_str, key=len))
if max_length > MAX_SEQUENCE_LENGTH:
max_length = MAX_SEQUENCE_LENGTH
print(max_length)
X_mor_tr_seq_str = sequence.pad_sequences(X_mor_tr_seq_str, maxlen=max_length)
X_mor_val_seq_str = sequence.pad_sequences(X_mor_val_seq_str, maxlen=max_length)
tokenizer = text.Tokenizer(num_words=TOP_K, char_level=False)
tokenizer.fit_on_texts(X_mor_tr)
X_mor_tr_seq = tokenizer.texts_to_sequences(X_mor_tr)
X_mor_val_seq = tokenizer.texts_to_sequences(X_mor_val)
max_length = len(max(X_mor_tr_seq, key=len))
if max_length > MAX_SEQUENCE_LENGTH:
max_length = MAX_SEQUENCE_LENGTH
print(max_length)
X_mor_tr_seq = sequence.pad_sequences(X_mor_tr_seq, maxlen=max_length)
X_mor_val_seq = sequence.pad_sequences(X_mor_val_seq, maxlen=max_length)
sequence 처리를 해주었다. 문장 길이 분포를 파악하고 설정한 길이로 맞춰준 후 텍스트 데이터를 정수 시퀀스로 변환해준다.
✔️모델링
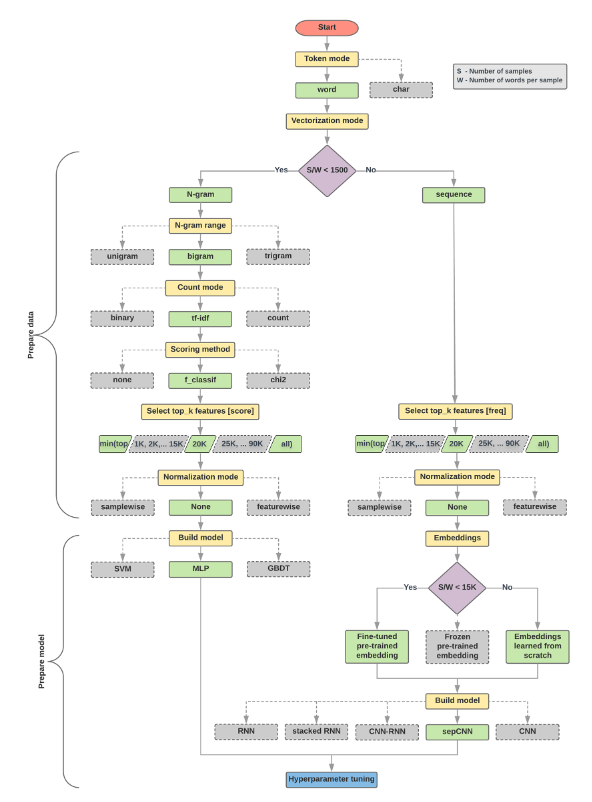
구글에서 제공한 가이드를 보면 Number of Samples / Number of words per sample 값에 따라 모델링을 다르게 하라고 말해준다.
🔗구글 가이드: https://developers.google.com/machine-learning/guides/text-classification/step-2-5?hl=ko

이번 데이터에서는 46정도의 숫자가 나왔고, 이 때 N-grams를 통한 머신러닝 모델링을 했을 때 성능이 좋을 것이라고 예측했다.
🚩 Model 1 (SVC)
# Hyperparameter
param_grid = {
'C': [0.1, 1, 10],
'kernel': ['linear', 'rbf','sigmoid'],
'gamma': [0.1, 1, 'scale']
}
# 교차 검증
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
# GridSearchCV 객체를 생성
grid_search = GridSearchCV(SVC(), param_grid, cv=skf, scoring='f1_macro')
grid_search.fit(x_train, y_train)
best_params = grid_search.best_params_
best_model = grid_search.best_estimator_
나는 서포트 벡터 머신의 분류기를 사용하였고, 하이퍼 파라미터 튜닝 및 교차검증을 적용하였다. 전처리할 때 코드 레이블에는 특수문자를 제거하지않았다. 코드 문의는 기호가 많을 것이라고 생각했기 때문이다. 그 결과~~~ 0.94!!!!!!!!!!
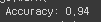
하지만 테스트 데이터에도 전처리를 동일하게 적용해줘야 하는데 테스트 데이터에는 레이블이 없잖니... 고로 코드 레이블 제외한 특수문자 제거는 불가능... 따라서 모든 데이터에 특수문자를 제거했더니 결과는 0.84정도로 떨어졌다. 그래도 준수한 정확도이다. 이 후 높은 성능을 위해 MLP, XGB등을 사용해보고 앙상블도 시도했지만 0.84에서 오르지않았다. 이 때 나의 선택은 pre-trained model을 가져오는 것이였다.
🚩 Model 2 (klue/bert-base)
허깅페이스를 통해 모델들을 찾아보다가 klue/bert-base을 발견하고 바로 적용해보았다. 하지만 모델마다 데이터 입력 형식을 맞춰줘야하기에 어려움을 겪었다. 하지만 여러 자료들을 찾아보며 해결했다.
from transformers import BertTokenizerFast
# Load Tokenizer
tokenizer = BertTokenizerFast.from_pretrained(HUGGINGFACE_MODEL_PATH)
# Tokenizing
train_encodings = tokenizer(train_texts, truncation=True, padding=True)
val_encodings = tokenizer(val_texts, truncation=True, padding=True)
test_encodings = tokenizer(test_texts, truncation=True, padding=True)
import tensorflow as tf
# trainset-set
train_dataset = tf.data.Dataset.from_tensor_slices((
dict(train_encodings),
train_labels
))
# validation-set
val_dataset = tf.data.Dataset.from_tensor_slices((
dict(val_encodings),
val_labels
))
from transformers import TFBertForSequenceClassification
model = TFBertForSequenceClassification.from_pretrained(HUGGINGFACE_MODEL_PATH, num_labels=5, from_pt=True)
optimizer = tf.keras.optimizers.Adam(learning_rate=1e-5, weight_decay=0.1)
model.compile(optimizer=optimizer, loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy'])
callback_earlystop = EarlyStopping(
monitor="val_accuracy",
min_delta=0.001, # the threshold that triggers the termination (acc should at least improve 0.001)
patience=5)
history =model.fit(
train_dataset.shuffle(1000).batch(8), epochs=3, batch_size=8,
validation_data=val_dataset.shuffle(1000).batch(8),
callbacks = [callback_earlystop])
# Save the ensemble model
import joblib
joblib.dump(model, 'best_pre_model.pkl')먼저 결과는 F1-score 0.85!!!!! 이 결과를 얻어내는데 정말 오래 걸렸다. epochs, learning late를 조절하며 학습을 진행하느라 많은 시간을 썼다🫠 그래도 의미있는 시간이였다. 허깅페이스를 통해 pretrained model을 사용해보았고, bert를 사용해보았기에 유익한 시간이였다.
참고 링크: https://velog.io/@jaehyeong/Fine-tuning-Bert-using-Transformers-and-TensorFlow

상위10등이 A인데, 8등으로 마무리! 아쉬운 것도 있지만 만족한다!
🚩4차 미니 프로젝트를 마치며
이번 프로젝트는 가장 재밌었다!! 자연어 처리는 거리감이 있었는데 재밌어서 의외?였다. 데이터를 분석하고 이에 따라 알맞은 전처리를 진행하는 것이 가장 중요하다는 것을 느꼈다. 하지만 결과적으로 가장 중요한 것은 성능 좋은 모델을 만들어내는 것이다. 이것이 가능하려면? pre-trained model을 잘 활용하는 것이다. 직접 모델링을 해보며 기본적인 이론은 숙지해야하는 것은 당연하다. 하지만 요즘은 많은 모델들이 이미 나와있기에 이것으로 빠른 일처리를 하는 능력이 요구된다. 강사님도 이 부분을 강조하셨다! 물론 구현에만 집중하는 것이 아닌 이론적인 부분도 잘 알아야하는 것이 전제조건이라고 생각한다. 이번 프로젝트를 마치며 아쉬운 점은 SVC와 bert를 앙상블해보면 더 좋은 모델이 나왔을 것이라고 생각한다. 하지만 프로젝트 진행중에는 시간이 촉박했기에 이제 생각이 들었다🤣 상위 3개조의 발표를 들어보았는 데 GPT API를 사용하거나 전처리를 더 세밀하게 진행하였다. 역시 같은 주제로 프로젝트를 진행해도 방법이 다르고, 결과도 다른 것을 보며 많이 배울 수 있었다. 발표는 정말 싫지만 다음에는 더 상위권에 진입해보고싶다. 에이블스쿨을 진행하며 많은 사람들과 프로젝트를 진행해볼 수 있다는 것이 정말 좋다. 여러 생각을 공유할 수 있고, 이를 취합하는 경험을 하는 것이 귀하다고 생각한다. 남은 기간도 뿌셔보자👊
