
🏃♂️ 5차 미니 프로젝트
미션: 스마트폰 센서 기반 데이터를 활용한 행동 인식
활용 데이터셋
UCL Machine Learning Repository(Tabular) - data.csv
도메인 이해
다양한 센서 데이터를 통해 사람의 모션을 인식하는 것이다.
가속도 센서 : 일직선으로 움직이는 물체의 선형의 가속도를 측정하는 센서
자이로스코프 센서 : 회전하는 물체의 각속도를 측정하는 센서
x,y,z로 나눠져있다. 즉 일어서고, 쓰러지는 등 모션에 따라 값이 다를 것이므로 잘 관찰할 것
피쳐가 561개로 많다. 수많은 피쳐들을 모두 살펴보는 것은 힘들기에 선택과 집중을 해야한다
모션 분류
- STANDING
- SITTING
- LAYING
- WAIKING
- WAIKING_UPSTAIRS
- WAIKING_DOWNSTAIRS
✔️데이터 분석
import matplotlib.pyplot as plt
# 막대 그래프 생성
plt.figure(figsize=(10, 6))
category_counts.plot(kind='bar')
plt.title('Activity별 빈도수')
plt.xlabel('Activity')
plt.ylabel('빈도수')
plt.xticks(rotation=45)
plt.show()
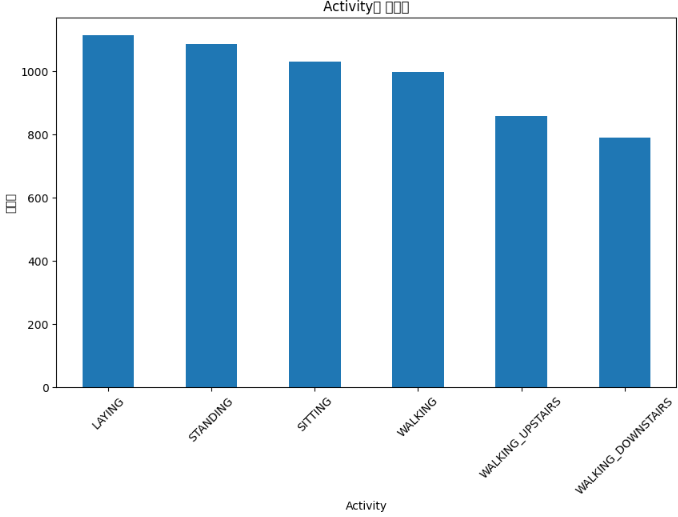
클래스는 불균형없이 괜찮은 수준으로 보여진다.
다음으로 피처 중요도를 확인한다. 이는 나중에 변수를 추출할 때 사용될 것이다.
# 2. features와 변수 중요도 결과 병합
merged_data_01 = pd.merge(features, fi_df_all, left_on='feature_name', right_on='feature_name', how='inner')
# 3. sensor 별 중요도 합계 계산 및 상위 변수 그룹별 비교 분석
sensor_importance = merged_data_01.groupby('sensor')['feature_importance'].sum().reset_index()
sensor_importance = sensor_importance.sort_values(by='feature_importance', ascending=False)
# 4. sensor + agg 별 중요도 합계 계산 및 상위 변수 그룹별 비교 분석
sensor_agg_importance = merged_data_01.groupby(['sensor', 'agg'])['feature_importance'].sum().reset_index()
sensor_agg_importance = sensor_agg_importance.sort_values(by='feature_importance', ascending=False)
merged_data_01.rename(columns={'feature_importance': 'feature_importance_01'}, inplace=True)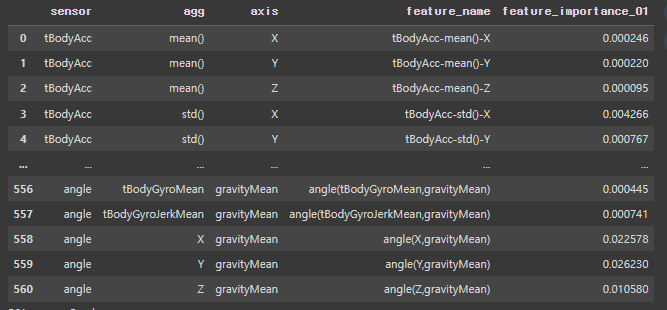
다음으로 6개의 행동에 대해 정적, 동적행동으로 구분해서 분석해보자.
data['is_dynamic'] = data['Activity'].apply(lambda x: 0 if x in ["STANDING", "SITTING", "LAYING"] else 1)
# 2. features와 변수 중요도 결과 병합
merged_data_02 = pd.merge(features, fi_df_all, left_on='feature_name', right_on='feature_name', how='inner')
# 3. sensor 별 중요도 합계 계산 및 상위 변수 그룹별 비교 분석
sensor_importance = merged_data_02.groupby('sensor')['feature_importance'].sum().reset_index()
sensor_importance = sensor_importance.sort_values(by='feature_importance', ascending=False)
# 상위 변수 그룹별 비교 분석을 위한 코드
# sensor_importance 에서 필요한 그룹만 선택하거나 시각화 등의 분석을 수행합니다.
# 4. sensor + agg 별 중요도 합계 계산 및 상위 변수 그룹별 비교 분석
sensor_agg_importance = merged_data_02.groupby(['sensor', 'agg'])['feature_importance'].sum().reset_index()
sensor_agg_importance = sensor_agg_importance.sort_values(by='feature_importance', ascending=False)이 후 개별 동작에 대해 분석한다. STANDING,SITTING 등 6개 동작을 하나씩 분석해본다. 아래 코드를 수정하며 6번 반복했다.
sample=pd.read_csv(r'/content/drive/MyDrive/2023.10.25_미니프로젝트5차_실습자료밀 데이터/데이터/data01_train.csv')
sample['is_sitting'] = (sample['Activity'] == 'SITTING').astype(int)
sample.drop('Activity', axis=1, inplace=True)
from sklearn.model_selection import train_test_split
# 특성과 목표 변수 선택
x = sample.drop(['is_sitting'], axis=1)
y = sample['is_sitting']
# 데이터 분할
x_train, x_valid, y_train, y_valid = train_test_split(x, y, test_size=0.2, random_state=42)
from sklearn.ensemble import RandomForestClassifier
# 랜덤 포레스트 기본 모델 생성
rf_model = RandomForestClassifier(n_estimators=100, random_state=42)
rf_model.fit(x_train, y_train)
# 모델 평가
y_pred = rf_model.predict(x_valid)
accuracy = accuracy_score(y_valid, y_pred)
print("정확도:", accuracy)
importance = rf_model.feature_importances_
feature_names = x.columns
fi_df_5 = plot_feature_importance(importance, feature_names, topn=5)
print(fi_df_5)
fi_df_all = plot_feature_importance(importance, feature_names, topn='all')
# 2. features와 변수 중요도 결과 병합
merged_data_04 = pd.merge(features, fi_df_all, left_on='feature_name', right_on='feature_name', how='inner')
merged_data_04.rename(columns={'feature_importance': 'feature_importance_04'}, inplace=True)
merged_data_04
# 3. sensor 별 중요도 합계 계산 및 상위 변수 그룹별 비교 분석
sensor_importance = merged_data_04.groupby('sensor')['feature_importance_04'].sum().reset_index()
sensor_importance = sensor_importance.sort_values(by='feature_importance_04', ascending=False)
# 상위 변수 그룹별 비교 분석을 위한 코드
# sensor_importance 에서 필요한 그룹만 선택하거나 시각화 등의 분석을 수행합니다.
# 4. sensor + agg 별 중요도 합계 계산 및 상위 변수 그룹별 비교 분석
sensor_agg_importance = merged_data_04.groupby(['sensor', 'agg'])['feature_importance_04'].sum().reset_index()
sensor_agg_importance = sensor_agg_importance.sort_values(by='feature_importance_04', ascending=False)
# 출력
print("Sensor별 중요한 변수 그룹:")
print(sensor_importance)
print("Sensor+Agg별 중요한 변수 그룹:")
print(sensor_agg_importance)마지막으로 위에서 확인한 관점별 피쳐 중요도들을 하나의 데이터프레임으로 합쳐보았다.
- 관점1 : 6개 행동 구분
- 관점2 : 동적, 정적 행동 구분
- 관점3 : Standing 여부 구분
- 관점4 : Sitting 여부 구분
- 관점5 : Laying 여부 구분
- 관점6 : Walking 여부 구분
- 관점7 : Walking_upstairs 여부 구분
- 관점8 : Walking_downstairs 여부 구분
merged_data_01 = pd.merge(merged_data_01, merged_data_02, on=["sensor", "agg", "axis", "feature_name"], how="inner")
merged_data_01 = pd.merge(merged_data_01, merged_data_03, on=["sensor", "agg", "axis", "feature_name"], how="inner")
merged_data_01 = pd.merge(merged_data_01, merged_data_04, on=["sensor", "agg", "axis", "feature_name"], how="inner")
merged_data_01 = pd.merge(merged_data_01, merged_data_05, on=["sensor", "agg", "axis", "feature_name"], how="inner")
merged_data_01 = pd.merge(merged_data_01, merged_data_06, on=["sensor", "agg", "axis", "feature_name"], how="inner")
merged_data_01 = pd.merge(merged_data_01, merged_data_07, on=["sensor", "agg", "axis", "feature_name"], how="inner")
merged_data = pd.merge(merged_data_01, merged_data_08, on=["sensor", "agg", "axis", "feature_name"], how="inner")✔️모델링
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
import xgboost as xgb
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import accuracy_score
def create_classification_models(data):
# Step 1: Create a model to classify static (0) or dynamic (1) activities
data['Activity_dynamic'] = data['Activity'].apply(lambda x: 0 if x in ["STANDING", "SITTING", "LAYING"] else 1)
# Step 2: Create models for detailed activity classification
x = data.drop(columns=['Activity', 'Activity_dynamic'])
y1 = data['Activity']
y2 = data['Activity_dynamic']
# Split the data for both stage 1 and stage 2 models
x_train, x_valid, y_train_01, y_valid_01, y_train_02, y_valid_02 = train_test_split(x, y1, y2, test_size=0.2, random_state=42)
# Stage 1 model: Classify static (0) or dynamic (1)
model_stage1 = LogisticRegression(C=20, max_iter=1000)
model_stage1.fit(x_train, y_train_02)
# Static (0) classification model
x_static = x_train[y_train_02 == 0]
y_static = y_train_01[y_train_02 == 0]
model_static = RandomForestClassifier(n_estimators=100, max_depth=10, random_state=42)
model_static.fit(x_static, y_static)
# Dynamic (1) classification model
x_dynamic = x_train[y_train_02 == 1]
y_dynamic = y_train_01[y_train_02 == 1]
model_dynamic = LogisticRegression(C=20, max_iter=1000)
model_dynamic.fit(x_dynamic, y_dynamic)
return model_stage1, model_static, model_dynamic, x_valid, y_valid_01
def main():
path='/content/drive/MyDrive/2023.10.25_미니프로젝트5차_실습자료밀 데이터/데이터/data01_train.csv'
data = pd.read_csv(path)
data.drop(columns=['subject'], inplace=True)
model_stage1, model_static, model_dynamic, x_valid, y_valid_01 = create_classification_models(data)
# Predictions using the models
y_pred_stage1 = model_stage1.predict(x_valid)
y_pred_static = model_static.predict(x_valid[y_pred_stage1 == 0])
y_pred_dynamic = model_dynamic.predict(x_valid[y_pred_stage1 == 1])
# Calculate accuracies
accuracy_stage1 = accuracy_score(y_valid_02, y_pred_stage1)
accuracy_static = accuracy_score(y_valid_01[y_pred_stage1 == 0], y_pred_static)
accuracy_dynamic = accuracy_score(y_valid_01[y_pred_stage1 == 1], y_pred_dynamic)
print(f"Stage 1 Model Accuracy: {accuracy_stage1}")
print(f"Static (0) Classification Model Accuracy: {accuracy_static}")
print(f"Dynamic (1) Classification Model Accuracy: {accuracy_dynamic}")
total_samples = len(y_valid_02)
total_static_samples = len(y_pred_static)
total_dynamic_samples = len(y_pred_dynamic)
weighted_accuracy = (accuracy_stage1 * total_samples +
accuracy_static * total_static_samples +
accuracy_dynamic * total_dynamic_samples) / (total_samples + total_static_samples + total_dynamic_samples)
print(f"전체 정확도: {weighted_accuracy}")
# Assuming y_pred_static and y_pred_dynamic are NumPy arrays or lists
y_pred_static_list = y_pred_static.tolist()
y_pred_dynamic_list = y_pred_dynamic.tolist()
# Combine the two lists
combined_predictions = y_pred_static_list + y_pred_dynamic_list
# Create a DataFrame for the combined results
results_df = pd.DataFrame({'combined_predictions': combined_predictions})
# Save the DataFrame to a CSV file
results_df.to_csv('./results.csv', index=False)
if __name__ == "__main__":
main()
위 코드는 먼저 데이터를 정적, 동적으로 구분한다. 그리고 정적인 것에 대해 3가지 행동으로 분류, 동적인 것에 대해 3가지 행동으로 분류한다. 즉 3개의 모델을 사용하여 하나의 프로세스로 만들어서 함수화한 것이다. 내일은 위 내용을 바탕으로 캐글대회를 참가한다! 데이터가 바뀔 것이기 때문에 내일 빠른 시간 안에 분석해서 좋은 성능을 내보도록 해야겠다! 위에서 공부한 내용들을 적극 활용해보자구요👊👊
🚩캐글
저번 프로젝트에서도 마지막날 캐글 대회를 했던것과 같이 이번에도 마무리는 캐글 컴피티션..!
6시간안에 새로운 데이터를 분석해서 성능을 끌어올려야한다. 일단 결과를 먼저 말하자면 33등정도로 마무리해서 50등안에 들었기에 A를 받았다😎
먼저 데이터를 봤을 때 100000 rows × 9 columns.. 데이터 양 실화..? 일단 11가지의 행동으로 분류하는 문제였다.
import matplotlib.pyplot as plt
# 막대 그래프 생성
plt.figure(figsize=(10, 6))
category_counts.plot(kind='bar')
plt.title('Activity별 빈도수')
plt.xlabel('Activity')
plt.ylabel('빈도수')
plt.xticks(rotation=45)
plt.show()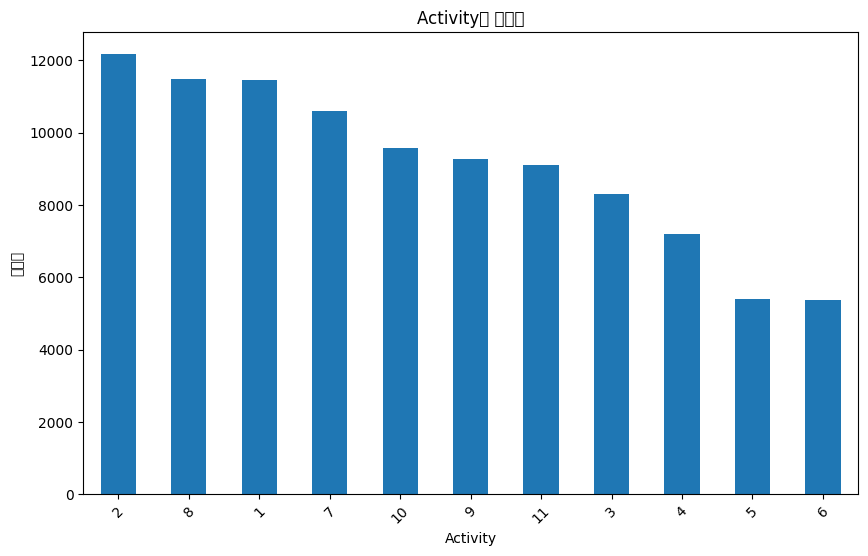
이것을 보았을 때 클래스 불균형이 있는듯하여 나중에 맞춰줘야겠다! 라고 생각했다.
data.info()
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Unnamed: 0 100000 non-null int64
1 timestamp 100000 non-null object
2 A_x 90000 non-null float64
3 A_y 90000 non-null float64
4 A_z 90000 non-null float64
5 B_x 90000 non-null float64
6 B_y 90000 non-null float64
7 B_z 90000 non-null float64
8 label 100000 non-null int64 결측치가 각 데이터마다 만개씩 있는 것으로 보아 결측치를 잘 채워주는 것이 중요하겠다고 생각했다. 그리고 timestamp가 있는 것을 보고, 시간을 잘 활용해야겠다고 생각했다. 그래서 timestamp로 정렬해보았을 때 역시나 같은 시간대에는 같은 행동으로 분류하고있었다. 0.02초?간격으로 센서가 행동을 인식했는데 비슷한 시간에 행동이 비슷하다면? timestamp열에서 데이터를 만들어내야겠다라고 생각했다.
data['timestamp'] = pd.to_datetime(data['timestamp'])
# Timestamp 열의 각 구성 요소를 추출
data['Year'] = data['timestamp'].dt.year
data['Month'] = data['timestamp'].dt.month
data['Day'] = data['timestamp'].dt.day
data['Hour'] = data['timestamp'].dt.hour
data['Minute'] = data['timestamp'].dt.minute
data['Second'] = data['timestamp'].dt.second
# 각 구성 요소를 하나의 정수로 결합
data['Combined'] = data['Year'] * 10000000000 + data['Month'] * 100000000 + data['Day'] * 1000000 + data['Hour'] * 10000 + data['Minute'] * 100 + data['Second']
# 출력
print(data)일단 XGBClassifier로 모델링 했을 때 결과는..? 0.9901...? 응..? 이게 맞아?? 하며 캐글 테스트 데이터로 예측하고 제출했더니 바로 상위권,,,
이게 오전만에 일어난일이다. 그래서 얼른 팀원들에게 timestamp의 중요성을 설명해주고 맛점을 했다.
오후에는 바로 SMOTE, 데이터 스케일링, 하이퍼파라미터튜닝을 진행했다. 원래 0.99가 넘었어서 상위권은 정말 0.0001 싸움이였다. 성능이 너무 잘 나왔길래 더 이상 전처리를 하지않고 모델 튜닝에 집중해서 0.99282!! 이 스코어로 캐글을 마무리했다.
from sklearn.model_selection import train_test_split
from imblearn.over_sampling import SMOTE
from sklearn.preprocessing import MinMaxScaler
x=data.drop(columns=['label','timestamp','Unnamed: 0'])
y=data['label']
from imblearn.over_sampling import SMOTE
# SMOTE 객체 생성
smote = SMOTE(random_state=42)
# SMOTE를 적용하여 훈련 데이터를 오버 샘플링
x, y = smote.fit_resample(x, y)
# Min-Max 스케일러 객체 생성
scaler = MinMaxScaler()
# 훈련 데이터를 사용하여 변환 스케일러를 학습하고 적용
x = scaler.fit_transform(x)
x_test = scaler.transform(x_test)
from sklearn.preprocessing import LabelEncoder
import xgboost as xgb
from sklearn.metrics import accuracy_score
# 레이블 인코더 생성
label_encoder = LabelEncoder()
xgb_model = xgb.XGBClassifier(max_depth=12,n_estimators=500)
y_train_encoded = label_encoder.fit_transform(y)
# XGBoost 모델을 훈련
xgb_model.fit(x, y_train_encoded)
# 테스트 데이터로 예측
y_pred_encoded = xgb_model.predict(x_test) # 0부터 시작하는 클래스 레이블로 예측됩니다
# 0부터 시작하는 클래스 레이블을 1부터 시작하는 형식으로 변환
y_pred = label_encoder.inverse_transform(y_pred_encoded)
# 예측 결과를 DataFrame으로 만듭니다.
result_df = pd.DataFrame({'ID': range(len(test)), 'label': y_pred})
# 예측 결과를 CSV 파일로 저장
result_df.to_csv('prediction_results.csv', index=False)🚩5차 미니 프로젝트를 마치며
전처리 때 결측치를 버리기도 하고, 선형보간법을 통해 채웠을 때 성능에서 별 차이가 없어서 깔끔하게 결측치를 다 제거하고 시작했다. 그리고 모델 튜닝에 더 힘 썼는데 결과적으로 봤을 때 결측치를 채운 후 튜닝을 거쳤다면 아마도 성능이 더 좋았을 것이라고 생각한다. 또한 automl을 사용하여 모델 별 비교를 통해 모델을 선택했다면 성능 향상에 도움을 받았을 것이라고 생각한다. 항상 아쉬움은 남지만, 후회는 없도록 했다! A를 받았기에 만족한다. 교육을 받으며 느끼는거지만 캐글과 같은 대회에서 성장하고 있다고 느낀다. 정해진 시간안에 역량을 보여주는 연습을 하는 것이 좋고, 성장할 수 있는 기회서 좋다. 앞으로 남은 프로젝트도 잘해내고싶고, 성장하고싶다. 5차도 끝~👊
