Introduction to ALGORITHMS
그래프 종류 / 표현 방식
6 그래프 알고리즘
기본 그래프 알고리즘
22.1 그래프의 표현
BFS / DFS
6 그래프 알고리즘
22.2 너비 우선 검색
22.3 깊이 우선 검색
위상정렬
22.4 위상 정렬
B-Tree
5 고급 자료구조
18 B-트리
트라이(Trie)
다익스트라, 플로이드 와샬
6 그래프 알고리즘
24 단일 출발지 최단 경로
24.3 다익스트라알고리즘
25 모든 최단쌍의 경로
25.2 플로이드 워샬 알고리즘
최소 신장 트리
6 그래프 알고리즘
23 최소 신장트리
그래프 종류 / 표현 방식
그래프(vertex, edge, node, arc)
종류: Undirected, Directed, Weighted Graph
표현방식: 인접행렬(Adjacency Matrix), 인접리스트(Adjacency List)
노드(node): 정점 (vertex)이라고도 하며 데이터가 저장되는 그래프의 기본 원소
간선 (edge): 링크(link)라고도 하며 노드 간의 관계
인접 노드: (adjacent node): 하나의 노드에서 간선에 의해 직접 연결되어 있는 노드
차수(degree): 노드에 연결된 간선의 수
진입 차수(in-degree): 외부에서 오는 간선의 수
진출 차수(out-degree): 외부로 향하는 간선의 수
경로 (path): 간선을 따라갈 수 있는 길
경로의 길이 (length): 경로를 구성하는 데 사용된 간선의 수
단순 경로 (simple path): 경로 중에서 반복되는 간선이 없는 경로
사이클 (cycle): 시작 노드와 종료 노드가 같은 단순 경로
유향, 무향 (방향성)
가중치 있음 없음 (가중치가 0인것과 간선이 없는게 구분되어야한다.)
인접행렬은
메모리 공간이 낭비됨.(호출은 바로 되는데 인덱스를 다 주니까.)
(또 간선의 수를 알아내려면 인접행렬 전체를 확인하여 시간복잡도 O(n^2) 소요.)
인접 리스트는
인접 노드를 연결리스트로 표현.
노드의 개수만큼 인접 '리스트'가 존재하며
(그러니까, 리스트의 크기가 노드의 갯수임.)
리스트 값에 들어가는 건 헤드 포인터
(연결 리스트 맨 처음 노드를 가리킴)
(정확히는, 노드 2에 연결되는 노드들이 추가적으로 연결리스트로 이어져있는 형태.)
(가중치를 더하면 노드 저장시 가중치도 같이 저장함.)(노드 번호, 간선 가중치 순.)
(여기서 좀 헷갈릴 수 있는건,
방향성이 없으면 각각 서로가 서로의 헤드 포인터라
선이 이어져있는 노드가 연결리스트로 모두 저장되지만,
방향성이 있으면 시작 지점이 명확하기때문에,
자신이 가리키는 노드만 연결리스트로 연결 됨.)
존재하는 선만 저장되기때문에 메모리적으로는 효율적인데,
간선 조회나 노드 차수를 알려면 리스트를 일일이 탐색해야해서,
노드의 차수만큼(연결된 숫자만큼) 시간이 걸린다.
그래도 전반적으로 시간이 덜 듦.
? arc : 방향성 엣지.
[자료구조] 그래프(Graph): 인접행렬과 인접리스트
BFS / DFS
[알고리즘] 너비 우선 탐색(BFS)이란
[알고리즘] 깊이 우선 탐색(DFS)이란
너비 우선 탐색(BFS, Breadth-First Search)
깊이 우선 탐색(DFS, Depth-First Search)
그래프 탐색이란,
하나의 정점에서 차례대로 모든 정점을 한번씩 방문하는 것.
깊이 우선 탐색은,
루트 노드(아니면 임의의 노드)에서 시작해,
다음 분기로 넘어가기 전에 해당 분기를 완벽하게 탐색하는 방법.
모든 노드를 방문 하고자하는 경우 이 방법을 선택.
메커니즘은 좀 더 간단해도,
단순 검색 속도 자체는 너비 우선 탐색에 비해 느리다.
자기 자신을 호출하는 순환 알고리즘 형태.
전위 순회(Pre-Order Traversals)를 포함한 다른 형태의 트리 순회는 모두 DFS의 한 종류
? 전위순회
뿌리를 먼저 방문.
0에서 시작해서
왼쪽부터 쭉 내려갔다가
원래 분기로 돌아오면
다시 방문 안했던 분기로 내려감.
그 외에는 중위순회, 후위순회, 층별 순회가 있다.
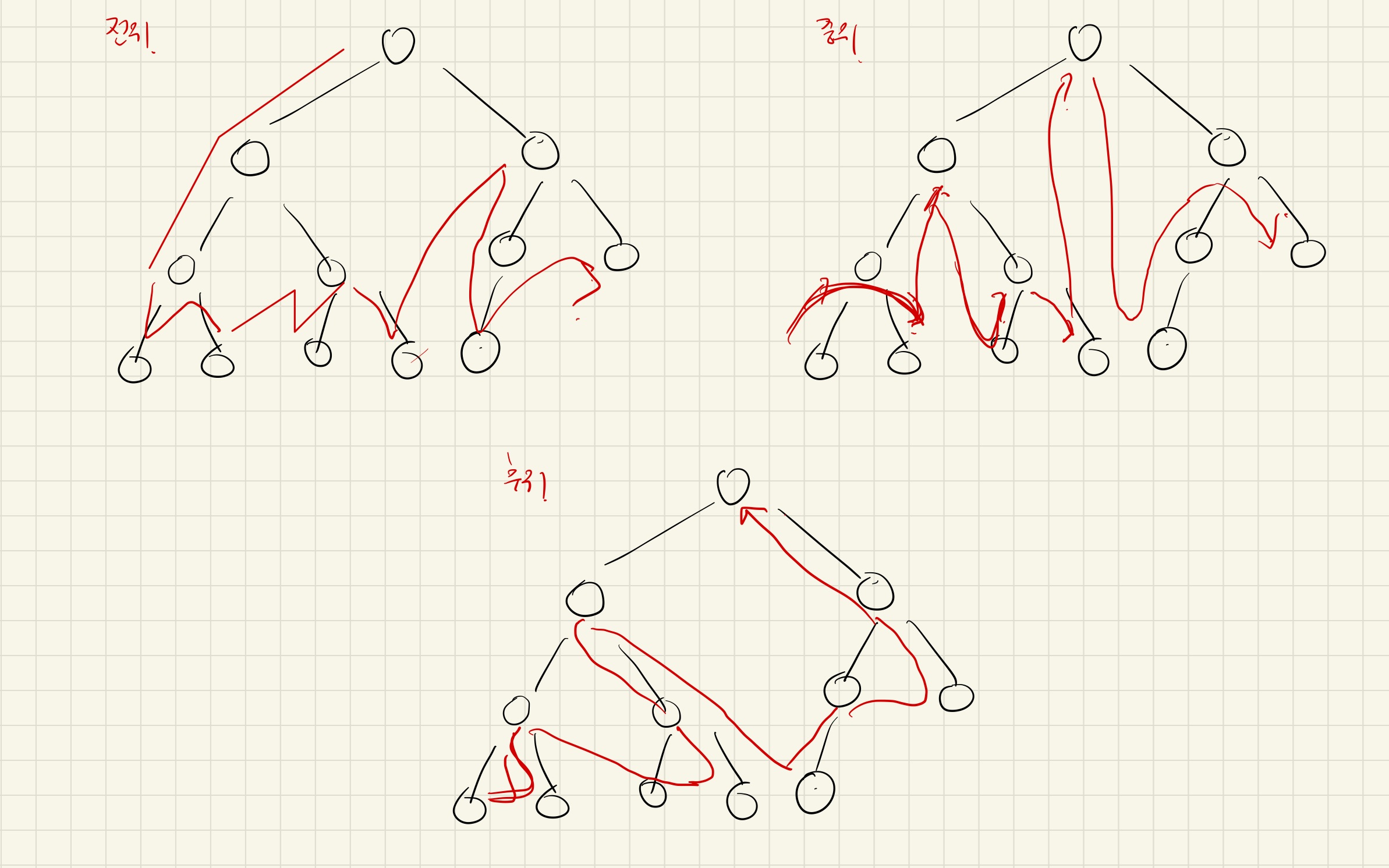
[자료구조] 트리(Tree)의 개념 및 전위순회, 중위순회, 후위순회, 층별순회
어떤 노드를 방문했었는지 여부를 반드시 검사해야한다.
(속성으로 주나?)
backtracking 개념 씀..ㅠㅠ
-
시작 노드!
-
그 다음, 시작 노드와 인접한 노드를 순회.
인접한 노드가 없으면 종료. -
한번 다른 노드에 진입하면, 그 분기는 다 봐야 되돌아감.
-
분기가 끝나면, 되돌아감.
방문이 안 된 정점이 없으면, 종료.
있으면, 거기서부터 DFS 시작.
깊이 우선 탐색 구현.
- 순환 호출 이용.
- 명시적인 스택 사용.
명시적 스택을 사용하여, 방문한 정점들을 스택에 저장하였다가 다시 꺼내어 작업.
앞으로 찾아 가야할 노드 와 이미 방문한 노드를 기준으로 데이터를 탐색.
앞으로 찾아가야할 노드면 계속 검색,
이미 방문한 노드면 무시하거나 따로 저장.
(아직 바로는 잘 모르겠군.)
스택/큐를 활용한 DFS 구현
리스트를 활용한 구현
graph = dict()
graph['A'] = ['B', 'C']
graph['B'] = ['A', 'D']
graph['C'] = ['A', 'G', 'H', 'I']
graph['D'] = ['B', 'E', 'F']
graph['E'] = ['D']
graph['F'] = ['D']
graph['G'] = ['C']
graph['H'] = ['C']
graph['I'] = ['C', 'J']
graph['J'] = ['I']
def dfs(graph, start_node):
## 기본은 항상 두개의 리스트를 별도로 관리해주는 것
need_visited, visited = list(), list()
## 시작 노드를 시정하기
need_visited.append(start_node)
## 만약 아직도 방문이 필요한 노드가 있다면,
while need_visited:
## 그 중에서 가장 마지막 데이터를 추출 (스택 구조의 활용)
node = need_visited.pop()
## 만약 그 노드가 방문한 목록에 없다면
if node not in visited:
## 방문한 목록에 추가하기
visited.append(node)
## 그 노드에 연결된 노드를
need_visited.extend(graph[node])
return visited설명.
[방문해야하는 리스트][방문한 리스트]
방문할거 설정해.
(시작 노드)
스택에 넣어.
(방문해야하는 리스트에 시작 노드를 넣음.)
이후...
스택에서 꺼내.
(방문해야하는 리스트에서 시작 노드를 꺼냄. 정확히는 앞으로 방문 루트 볼 노드.)
도착했으니 방문한 노드로 빼되,
(이 루트는 봤다고 체크를 할 거니까 노드에 체크.)
이 노드 주변에 연결되어있는 노드 전부 불러와.
(시작 노드와 간선으로 연결된 친구1 친구2 친구3..)
스택에 다 쌓아놔.
(방문해야하는 리스트에 친구1 친구2 친구 3...)
그리고, 방문해야하는 리스트가 있으면,
방문 해야하는 리스트에서 위에서부터 하나씩 꺼내서 반복.
deque를 활용한 구현
def dfs2(graph, start_node):
## deque 패키지 불러오기
from collections import deque
visited = []
need_visited = deque()
##시작 노드 설정해주기
need_visited.append(start_node)
## 방문이 필요한 리스트가 아직 존재한다면
while need_visited:
## 시작 노드를 지정하고
node = need_visited.pop()
##만약 방문한 리스트에 없다면
if node not in visited:
## 방문 리스트에 노드를 추가
visited.append(node)
## 인접 노드들을 방문 예정 리스트에 추가
need_visited.extend(graph[node])
return visited
방문한 목록은 리스트로,
방문해야하는 리스트는 데크로.
pop으로 방문해야하는거 꺼내고,
방문한 리스트에는 리스트니까 append로 넣어...
...
pop을 리스트에서 하면 성능이 떨어지니까,
pop 기능만 쓰는 리스트를 데크로 바꿔준것.
재귀함수를 통한 DFS 구현
def dfs_recursive(graph, start, visited = []):
## 데이터를 추가하는 명령어 / 재귀가 이루어짐
visited.append(start)
for node in graph[start]:
if node not in visited:
dfs_recursive(graph, node, visited)
return visited시작 지점을 넣어.
그래프에 있는 시작지점과 이어진 노드를 for로 전부 꺼내.
그거 방문했어 안 했어?
안 했으면 방문 예정 목록에 넣어놔.
재귀.
? 정점의 수가 N, 간선의 수가 E.
시간 복잡도는 인접리스트는 O(N+E), 인접행렬은 O(N^2).
만약 그래프 내에 적은 숫자의 간선을 가진다면,(희소 그래프의 경우. Sparse Graph 라고 함.)
인접리스트를 사용하는 것이 유리.
위상 정렬
B-Tree
B-Tree
[자료구조] B-트리(B-Tree)란? B트리 그림으로 쉽게 이해하기, B트리 탐색, 삽입, 삭제 과정
-
노드에는 2개 이상의 데이터(key)가 들어갈 수 있으며,
항상 정렬된 상태로 저장된다.
(한 노드에 데이터가 2개, 3개 들어갈 수 있는 것.) -
그래서 데이터는 여러개여도, 노드 자체는 M차 B트리, M이라는 차수에 맞는 갯수의 자식 노드만 가질 수 있다. (최소는 M/2까지. 올림으로.)(그럼 4차수면 꼭 2개 가져야함?)
-
특정 노드의 데이터(key)가 k개라면, 자식 노드의 개수는 k+1개여야한다.
(노드의 데이터가 1개 -> 자식 노드 2개)
(노드의 데이터가 2개 -> 자식 노드 3개...) -
특정 노드의 왼쪽 서브트리는
특정 노드의 key보다 작은 값을,
오른쪽 서브트리는 큰값들로 구성한다. -
노드 내에 데이터는 ceil(M/2)-1개부터 최대 M-1개까지 포함될 수 있다.
(3 자식이면 각 노드들 안에 데이터는 1개에서 두개까지.)
(4 자식이면 각 노드들 데이터는 1개에서 3개까지.)... -
모든 리프 노드들이 같은 레벨에 존재한다.
(즉, 1레벨이 다 안 채워졌는데 2레벨을 채울 수는 없는것.)
(그래서 루트 노드에서 모든 리프 노드로 가는 경로의 길이가 같다.)
그러니까 지정되는게
자식 노드 갯수,
노드의 데이터 갯수에 따라 자식 노드 갯수
왼쪽 오른쪽 서브트리 조건
노드 내 데이터 갯수 제한
..
외우는 순서
b 트리를 그려봅시다
- 노드 자체에는 데이터가 2개 이상 들어갈 수 있습니다.
- 그래서 자식을 그려야하는데? 최대 갯수는 이 트리의 차수에 따릅니다.
- 그렇게 그리려는데? 만약 노드의 데이터 갯수에 따라 최소 자식이 있습니다.
- 데이터를 넣을때는? 왼쪽부터 작은 값을 넣고요.
- 이렇게 자식을 넣을 때도? 트리의 차수에 따라 절반의 올림에서 차수-1까지 데이터 갯수를 넣을 수 있고요.
- 이 모든 리프 노드들이 같은 레벨에 존재해야합니다.
B - Tree 탐색 과정
하향식.
찾으려는 값 K.
루트에서 데이터 비교.
데이터 중에 제일 작아?
->가장 왼쪽에 보냄.
데이터 중간값이야?
-> 중간에 보냄.
데이터들보다 커?
-> 오른쪽에 보냄.
그런걸 반복함.
B 트리(Balanced-Tree) 삽입 과정
탐색과는 다르게 상향식으로 진행.
루트 노드가 비어있어?
루트에 넣어.
안 비어있어?
적절한 리프 노드 찾아.
리프노드에 넣어봤는데 상태가 부적절해?
분리해서 정렬.
분리가 일어나지 않는 경우
리프에서 찾아봤는데, (탐색으로)
넣어봤더니 그대로 괜찮으면 냅둠.
분리가 일어나는 경우
적절한 리프에 넣어봤는데,
데이터 갯수가 초과하므로 분리.
그 중 중앙값을 부모 노드로 보내고,
같이 있던 리프 노드는 작은 값을 왼쪽 자식, 큰값을 오른 쪽 자식으로 설정함.
부적절하면 계속 부모 노드로 보내고 자식 설정을 반복함.
B 트리 삭제 과정
B- 트리의 데이터 삭제 과정은 삽입하는 과정보다 조금 더 복잡하다. 우선 설명의 편의를 위해 다음과 같은 용어들을 임의로 정의했다.
Lmax = 현재 노드의 왼쪽 자식들 중 가장 큰 key
Rmin = 현재 노드의 오른쪽 자식들 중 가장 작은 key
Parent : 현재 노드를 가리키는 부모 노드의 자식 포인터 오른쪽에 있는 key. 단, 마지막 자식 노드의 경우는 부모의 마지막 key.
K : 삭제할 key
출처: https://code-lab1.tistory.com/217 [코드 연구소:티스토리]
마지막 문장이 잘 이해가 안 가는군.
3차 트리를 예시로 들어보자. 1~3개의 자식을 가질 수 있고, 0~2개의 key 값을 가질 수 있다. 이 조건을 최소 유지 개수라고 부르겠다.
출처: https://code-lab1.tistory.com/217 [코드 연구소:티스토리]
리프 노드에서 삭제
1-1) 삭제했는데 만족한다면, 그대로 삭제.
1-2) 삭제했더니 최소 유지 개수는 만족 못하지만, 바로 옆 형제 노드들에게 값을 빌려올 수 있는 경우.
아아,
리프를 삭제하면
원래 연결되어있던
부모 노드를 끌어내려서
형제 노드가 데이터 개수가 좀 넉넉하면
걔를 부모 노드로 보냄.
1-3) 삭제했더니 최소유지개수도 형제도 없는데 부모 노드는 분할할 수 있을 때..
가져올 형제는 없지만
부모가 데이터가 두개면
(부모는 많은데 자식은 적은경우)
(부모 데이터 하나를 자식 데이터로 보내버림)
1-4) 다 못하면 다음으로.
리프 노드가 아닌 노드에서 삭제.
2-1) 내부 노드에서 삭제시,
현재 노드, 혹은 자식 노드의
최소 유지개수의 최소보다 큰..
뭔소리야
아무튼 부모를 삭제하면
자식이 너무 많아버리는데
리프의 자식 하나를 부모로 등극하는데
그게 Lmax나 Rmin임.
음...
이게 왜 Lmax과 저게 왜 Rmin이지
오 이해완료
2-2) 내부 노드에서 값을 삭제할때,
현재 노드와 자식 노드 모두 key 개수가 최소인 경우.
- K를 삭제하고 K의 자식을 하나로 합친다. 합쳐진 노드를 N1이라고 하자.
- K의 Parent를 K의 형제 노드에 합친다. 합쳐진 노드를 N2라고 하자.
- N1을 N2의 자식이 되도록 연결한다.
4-1. 만약 N2의 key수가 최대보다 크다면 key 삽입 과정과 동일하게 분할한다.
4-2. 만약 N2의 key수가 최소보다 작다면 2번 과정으로 돌아가서 동일한 과정을 반복한다.
출처: https://code-lab1.tistory.com/217 [코드 연구소:티스토리]
그러니까...
중간값이 빠졌을떄,
최소개수가 문제니까,
-
자식두개를 자식 하나로 합쳐(데이터 두개인)
-
부모 중 하나를 중간값의 형제로 내려
-
그리고 그 내려온 부모와 하나로 합친 자식을 잇고,
키 값이 추가로 많아졌다면 분할 과정을 거친다.
그래서,
연산이 복잡하긴 하나
오버플로우, 언더플로우를 방지,
리프 노드의 레벨을 동일하게 유지하여,
한쪽으로 편향되어있는 경우가 발생하지 않기때문에,
이에 따라 탐색 연산에 있어 logN의 형태로 응답시간 보장.
트라이(Trie)
왜 이건 없을까요 섭섭하게
다익스트라, 플로이드 와샬
플로이드 와샬(Floyd-Warshall) 알고리즘
[알고리즘] 플로이드 워셜 알고리즘 (Floyd-Warshall Algorithm)
모든 최단 경로를 구하는 알고리즘.
(그러니까, 한 지점에서 어떤 지점까지의 최단 경로가 아니라,)
(모든 지점에서, 다른 모든 지점까지의 최단 경로를 모두 구함.)
한번 실행하여, 모든 노드 간 최단 경로를 구한다.
- 소스코드가 다익스트라에 비해 매우 짧아 구현이 쉽다.
- 다익스트라의 경우 단계마다 최단 거리를 가지는 노드를 하나씩 반복적으로 선택한다. 이후 해당 노드를 거쳐가는 경로를 확인하며 최단 거리 테이블을 갱신하는 방식으로 동작한다.
<--> 플로이드 워셜 알고리즘 또한 단계마다 '거쳐 가는 노드'를 기준으로 알고리즘을 수행한다. 하지만, 매 단계마다 방문하지 않은 노드 중에서 최단 거리를 갖는 노드를 찾을 필요가 없다! (무슨 소리지?)- 플로이드 워셜은 2차원 테이블에 최단 거리 정보를 저장한다. (모든 지점에서 다른 모든 지점까지의 최단 거리를 저장해야 하기 때문이다.)
<--> 다익스트라는 한 지점에서 다른 지점까지의 최단 거리이기 때문에 1차원 리스트에 저장한다.- 플로이드 워셜 알고리즘은 DP 알고리즘에 속한다. 왜냐하면 만약 노드의 개수가 N개라고 할 때, N번 만큼의 단계를 반복하며 '점화식에 맞게' 2차원 리스트를 갱신하기 때문에 DP라고 볼 수 있다.
<--> 다익스트라는 그리디 알고리즘에 속한다고 볼 수 있다.
? DP 알고리즘, 동적 계획법(Dynamic Programming)
상향식 접근법.
작은 부분의 문제를 해결한후,
해당 부분의 해로 큰 크기의 문제를 해결.
Memoization 기법을 사용.
-
Memoization : 프로그램 실행시 이전에 계산한 값을 저장하여, 다시 계산하지 않도록 하여 전체 실행 속도를 빠르게 하는 기술.
ex) 피보나치 수열.
? 분할 정복과 뭐가 다른데?
: 하향식 접근법이고,
재귀 함수로 구현하며,
부분 문제가 중복되지 않음.
ex) 병합정렬, 퀵 정렬.
플로이드 워셜 알고리즘 점화식.
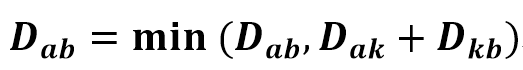
? 점화식 : 수열에서 두 항 사이가 갖는 관계.
모르
모르겟어 크레이지
정
정신나간다
내일 해야지
돌아옴
흠.
앞이 뭔가 설명하고 있는게 없어가지고
다시!! 다시다시.
알고리즘 - 플로이드-워셜(Floyd-Warshall) 알고리즘
초기 그래프를 인접 행렬로 나타낸다.
(인접 리스트 쓴다매?? 걘 누가 쓰지)
(그냥 일단 가시적으로 쓴 건가.)
아무튼 봐봐.
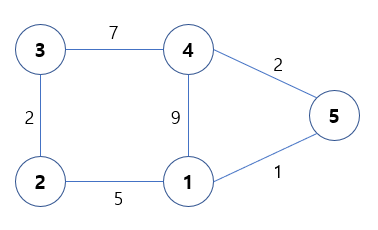
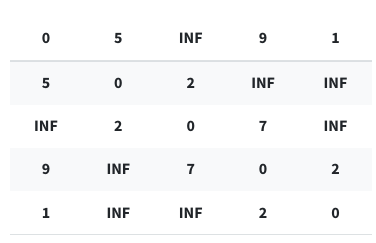
보면...
자기 자신은 0.
이어진 선은 가중치를 적어 숫자 표기.
이어지지 않은 노드와는 INF(infinity) 표기.
음!
그리고 각기 라운드,
즉 순환시킬 때마다,
1라운드에는 첫번째 노드가 중간 노드일 경우,
2라운드에는 두번쨰 노드가 중간 노드일 경우...
로,
INF 인 지점을 최단 거리로 갱신해준다.
(꼭 INF가 아니어도, 다른 것도 최단 거리가 된다면 갱신은 해주겠지..)
전부 돌아서 모두 다른 점과의 최단 거리를 구하게 되면 완료.
단, 플로이드-워샬 알고리즘은
시간 복잡도가 O(n^3)이라 그래프의 크기가 작을 때만 사용한다.
(노드 개수가 N개일 때,
N번의 단계를 거쳐,
단계마다 O(N^2)의 연산을 통해,
현재 노드를 거쳐가는 모든 경로를 고려하기 때문.)
소스코드로 구현
import sys
input = sys.stdin.readline
INF = int(1e9)
# 노드의 개수(n)과 간선의 개수(m) 입력
n = int(input())
m = int(input())
# 2차원 리스트 (그래프 표현) 만들고, 무한대로 초기화
graph = [[INF] * (n + 1) for _ in range(n + 1)]
# 자기 자신에서 자기 자신으로 가는 비용은 0으로 초기화
for a in range(1, n + 1):
for b in range(1, n + 1):
if a == b:
graph[a][b] = 0
# 각 간선에 대한 정보를 입력받아, 그 값으로 초기화
for _ in range(m):
# A -> B로 가는 비용을 C라고 설정
a, b, c = map(int, input().split())
graph[a][b] = c
# 점화식에 따라 플로이드 워셜 알고리즘을 수행
for k in range(1, n + 1):
for a in range(1, n + 1):
for b in range(1, n + 1):
graph[a][b] = min(graph[a][b], graph[a][k] + graph[k][b])
# 수행된 결과를 출력
for a in range(1, n + 1):
for b in range(1, n + 1):
if graph[a][b] == INF:
print('INFINITY', end=' ')
else:
print(graph[a][b], end=' ')
print()
# sample input
# 4
# 7
# 1 2 4
# 1 4 6
# 2 1 3
# 2 3 7
# 3 1 5
# 3 4 4
# 4 3 2노드 개수, 간선 개수 n, m으로 설정.
2차원 리스트, graph 생성.
[ [(INF), (INF), (INF)...], ... ,[(INF)*n] ...]
INF로 다 채움.
자기 자신 경로 0으로 바꿈.
(for 두개로 전부 순회하면서
[0][0], [1][1] 등의 위치를 0으로 채움.)
[ [0, (INF), (INF)...], [(INF), 0, (INF)...] ... ,[(INF)*n] ...]
각 간선에 대한 정보 입력.
m개의 선을 넣을 건데,
a => b로 가는 비용 c.
graph[a][b] = c
[ [0, 2, (INF)...], [2, 0, (INF)...] ... ,[(INF)*n] ...]
점화식에 따라!
플로이드 워셜 알고리즘 수정.
# 점화식에 따라 플로이드 워셜 알고리즘을 수행
for k in range(1, n + 1):
for a in range(1, n + 1):
for b in range(1, n + 1):
graph[a][b] = min(graph[a][b], graph[a][k] + graph[k][b])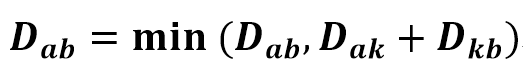
아아,
Dab와, Dak+Dkb
즉
D (a->b)와
D (a->k) + D(k->b) 를 비교해서
더 작은 값을 쓰겠단 뜻이로군.
- k가 중간 노드인걸 확인해볼건데
- a에서 출발해서
- b에 도착하는 모든 경우를
다 돌려서 알아낼거야.....
오!
해냈음!
최소 신장 트리
