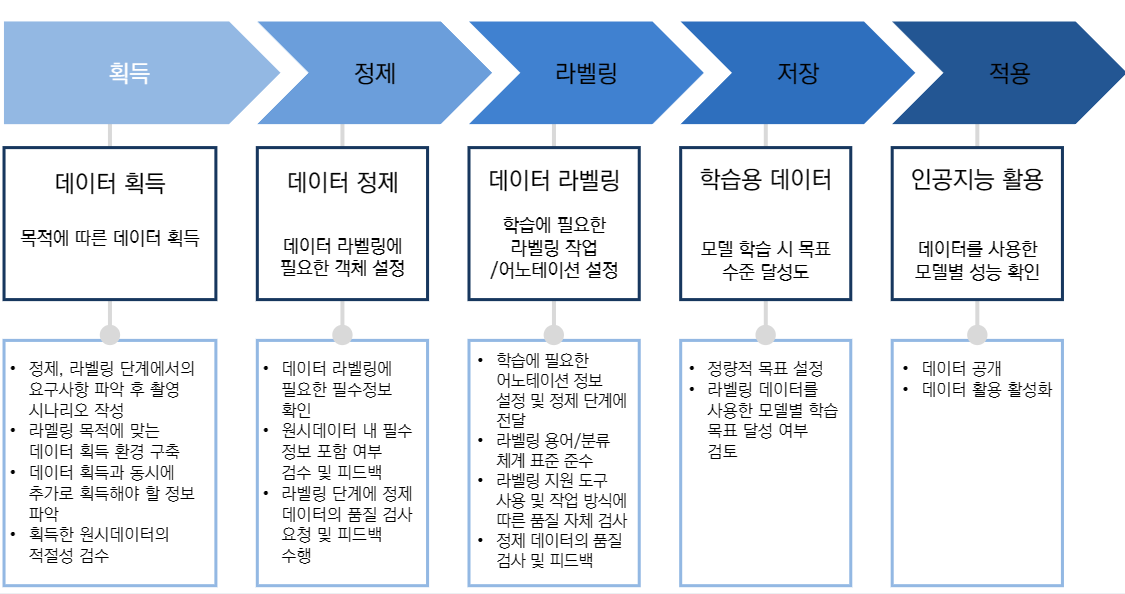
데이터 세트
데이터셋? 이거 매우 중요해 정말정말!
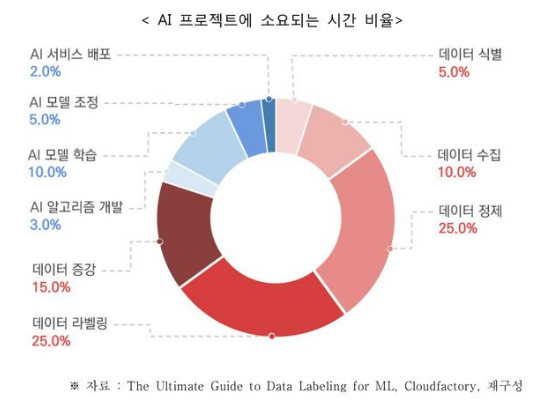
데이터들의 집합체 즉, 자료들의 모임이다. 특정한 작업을 위해서 데이터를 관령성 있게 모아놓은 것을 말한며 데이가 얼마나 중요하냐면, 실제 인공지능 프로젝트의 80%는 데이터를 수집하고 정제하고 라벨링하는 작업일정도로 중요하다!!
데이터의 중요성
Quality+Quantity
질(quality) : 데이터가 얼마나 모델(종속변수 Y)을 잘 설명할 수 있는지 보아야 한다.
양(quantity) : 선정한 데이터들이 모델을 잘 설명한다고 하여도 데이터가 충분하지 않다면 현실을 반영하지 못할 것이다.
즉, 의도하는 목적에 맞아야 하며(Quality), 현실을 잘 반영해야한다(Quantity)
5W1H
What?
측정대상
획득 시 포함되어야 할 변수들
: 일반인이 대상을 식별할 수 있는 피사체
: 장비,사람,시간,종류,객체,지역별 검토
When?
획득기간
: N주간 몇 시부터 몇시까지 몇 회
where?
획득 장소/프로세스
Who?
획득 담당자/획득하는 사람
: 연구 담당자
How?
획득 방법, 측정주기, 샘플 크기
데이터 양식
Why?
측정 목적 / 기대결과
: 목적에 맞는 힉득 데이터 이해와 프로세스 능력의 파악/추세분석
Data 불러오기 ex)
파이토치 제공 데이터
import torch # 파이토치 기본 라이브러리
import torchvision # 이미지 관련 된 파이토치 라이브러리
import torchvision.transforms as tr # 이미지 전처리 기능들을 제공하는 라이브러리
from torch.utils.data import DataLoader, Dataset # 데이터를 모델에 사용할 수 있도록 정리해 주는 라이브러리
import numpy as np # 넘파이 기본 라이브러리
transf = tr.Compose([tr.Resize(16),tr.ToTensor()]) # 16x16으로 이미지 크기 변환 후 텐서 타입으로 변환한다.
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transf)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transf)
print(trainset[0][0].size())
trainloader = DataLoader(trainset, batch_size=50, shuffle=True)
testloader = DataLoader(testset, batch_size=50, shuffle=False)
len(trainloader)
dataiter = iter(trainloader)
images, labels = next(dataiter)
print(images.size())
같은 클래스 별로 폴더 정리
from google.colab import drive
drive.mount('/content/gdrive')
cd/content/gdrive/My Drive/
transf = tr.Compose([tr.Resize((128, 128)),tr.ToTensor()]) # 128x128 이미지 크기 변환 후 텐서로 만든다.
trainset = torchvision.datasets.ImageFolder(root='./class', transform=transf) # 커스텀 데이터 불러온다.
trainloader = DataLoader(trainset, batch_size=2, shuffle=False) # 데이터를 미니 배치 형태로 만들어 준다.
dataiter = iter(trainloader)
images, labels = next(dataiter)
print(images.size(), labels)
정형화 되지 않은 커스텀 데이터 불러오기
#32x32 컬러 이미지와 라벨이 각각 100장이 있다고 가정하다.
train_images = np.random.randint(256,size=(100,32,32,3)) # (이미지 수)x(높이)x(너비)x(채널 수)
train_labels = np.random.randint(2,size=(100,1)) # 라벨 수
print(train_images.shape, train_labels.shape)
class TensorData(Dataset):
def __init__(self, x_data, y_data): #데이터 불러오기/기본 값
self.x_data = torch.FloatTensor(x_data) # 이미지 데이터를 FloatTensor로 변형
self.x_data = self.x_data.permute(0,3,1,2) # (이미지 수)x(높이)x(너비)x(채널 수) -> (이미지 수)x(채널 수)x(높이)x(너비)
self.y_data = torch.LongTensor(y_data) # 라벨 데이터를 LongTensor로 변형
self.len = self.y_data.shape[0] # 클래스 내의 들어 온 데이터 개수
def __getitem__(self, index): # 실제 나가는 데이터
return self.x_data[index], self.y_data[index] # 뽑아 낼 데이터를 적어준다.
def __len__(self): # 데이터 길이
return self.len # 클래스 내의 들어 온 데이터 개수
train_data = TensorData(train_images,train_labels) # 텐서 데이터 불러오기
train_loader = DataLoader(train_data, batch_size=10, shuffle=True) # 미니 배치 형태로 데이터 갖추기
커스텀 데이터와 전처리
import torch
import torchvision.transforms as tr # 이미지 전처리 기능들을 제공하는 라이브러리
from torch.utils.data import DataLoader, Dataset # 데이터를 모델에 사용할 수 있도록 정리해 주는 라이브러리
import numpy as np # 넘파이 기본 라이브러리
#32x32 컬러 이미지와 라벨이 각각 100장이 있다고 가정하다.
#glob -> PIL, openCV ..
train_images = np.random.randint(256,size=(100,32,32,3)) # (이미지 수)x(높이)x(너비)x(채널 수)
train_labels = np.random.randint(2,size=(100,1)) # 라벨 수
class MyDataset(Dataset):
def __init__(self, x_data, y_data, transform=None):
self.x_data = x_data # 넘파이 배열이 들어온다.
self.y_data = y_data # 넘파이 배열이 들어온다.
self.transform = transform
self.len = len(y_data)
def __getitem__(self, index):
sample = self.x_data[index], self.y_data[index]
if self.transform:
sample = self.transform(sample) #self.transform이 None이 아니라면 전처리를 작업한다.
return sample # 3.3과 다르게 넘파이 배열로 출력 되는 것에 유의 하도록 한다.
def __len__(self):
return self.len -
텐서 변환
class ToTensor:
def call(self, sample):
inputs, labels = sample
inputs = torch.FloatTensor(inputs) # 텐서로 변환
inputs = inputs.permute(2,0,1) # 크기 변환
return inputs, torch.LongTensor(labels) # 텐서로 변환 -
선형식
class LinearTensor:def __init__(self, slope=1, bias=0): self.slope = slope self.bias = bias def __call__(self, sample): inputs, labels = sample inputs = self.slope*inputs + self.bias # ax+b 계산하기 return inputs, labels
trans = tr.Compose([ToTensor(),LinearTensor(2,5)]) # 텐서 변환 후 선형식 2x+5 연산
dataset1 = MyDataset(train_images,train_labels, transform=trans)
train_loader1 = DataLoader(dataset1, batch_size=10, shuffle=True)
dataiter1 = iter(train_loader1)
images1, labels1 = next(dataiter1)
print(images1.size()) # 배치 및 이미지 크기 확인
커스텀 데이터와 torchvision.transforms 전처리
class MyTransform:
def __call__(self, sample):
inputs, labels = sample
inputs = torch.FloatTensor(inputs)
inputs = inputs.permute(2,0,1)
labels = torch.FloatTensor(labels)
transf = tr.Compose([tr.ToPILImage(), tr.Resize(128),tr.ToTensor(),tr.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
final_output = transf(inputs)
return final_output, labels dataset2 = MyDataset(train_images,train_labels, transform=MyTransform())
train_loader2 = DataLoader(dataset2, batch_size=15, shuffle=True)
dataiter2 = iter(train_loader2)
images2, labels2 = next(dataiter2)
print(images2.size()) # 배치 및 이미지 크기 확인
FashionMNIST 예제
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
from torch.autograd import Variable
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import Dataset, DataLoader
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
train_dataset = torchvision.datasets.FashionMNIST("FashionMNIST/", download=True, transform=
transforms.Compose([transforms.ToTensor()]))
test_dataset = torchvision.datasets.FashionMNIST("FashionMNIST/", download=True, train=False, transform=
transforms.Compose([transforms.ToTensor()]))
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=100)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=100)
labels_map = {0 : 'T-Shirt', 1 : 'Trouser', 2 : 'Pullover', 3 : 'Dress', 4 : 'Coat', 5 : 'Sandal', 6 : 'Shirt',
7 : 'Sneaker', 8 : 'Bag', 9 : 'Ankle Boot'}
fig = plt.figure(figsize=(8,8));
columns = 4;
rows = 5;
for i in range(1, columns*rows +1):
img_xy = np.random.randint(len(train_dataset));
img = train_dataset[img_xy][0][0,:,:]
fig.add_subplot(rows, columns, i)
plt.title(labels_map[train_dataset[img_xy][1]])
plt.axis('off')
plt.imshow(img, cmap='gray')
plt.show()

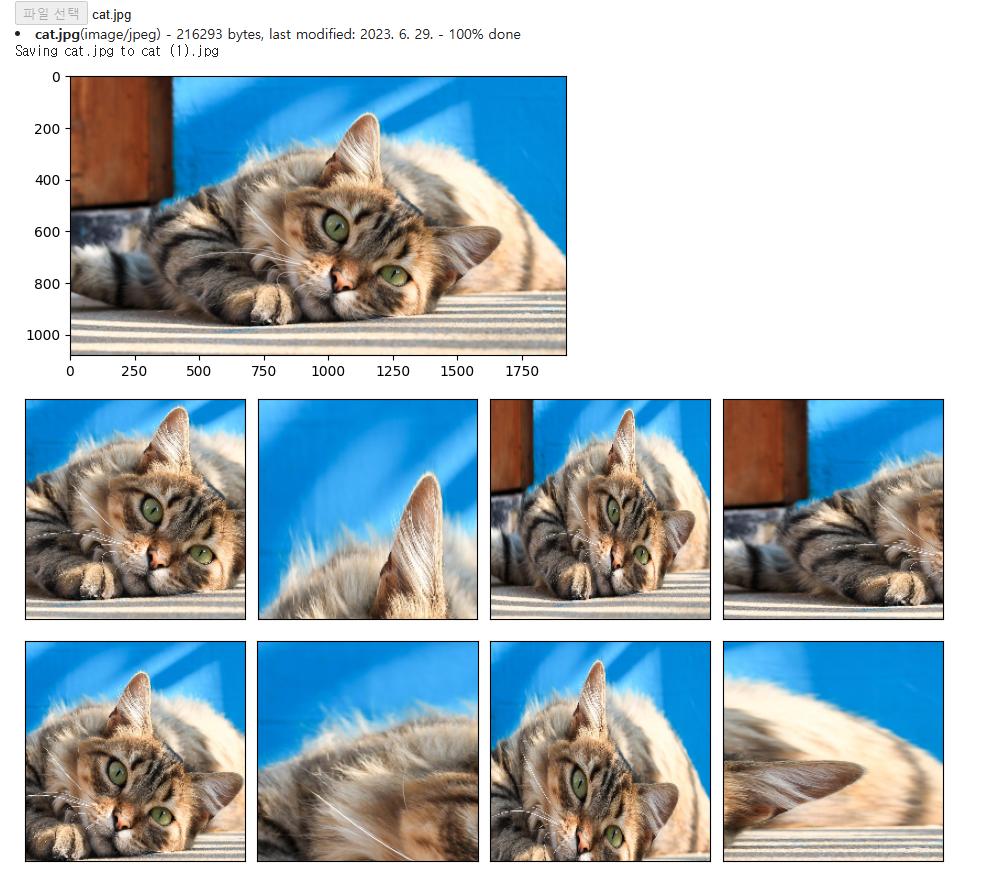
RandomResizedCrop 예제
!pip install mxnet
import matplotlib.pyplot as plt
import mxnet as mx
from mxnet.gluon.data.vision import transforms
from google.colab import files # 데이터 불러오기
file_uploaded=files.upload() # chap05/data/cat.jpg 데이터 불러오기
example_image = mx.image.imread("cat.jpg")
plt.imshow(example_image.asnumpy())
def showimages(imgs, num_rows, num_cols, scale=2):
aspect_ratio = imgs[0].shape[0]/imgs[0].shape[1]
figsize = (num_cols scale, num_rows scale * aspect_ratio)
, axes = plt.subplots(num_rows, num_cols, figsize=figsize)
for i in range(num_rows):
for j in range(num_cols):
axes[i][j].imshow(imgs[i * num_cols + j].asnumpy())
axes[i][j].axes.get_xaxis().set_visible(False)
axes[i][j].axes.get_yaxis().set_visible(False)
plt.subplots_adjust(hspace=0.1, wspace=0)
return axes
def apply(img, aug, numrows=2, num_cols=4, scale=3):
Y = [aug(img) for in range(num_rows * num_cols)]
show_images(Y, num_rows, num_cols, scale)
shape_aug = transforms.RandomResizedCrop(size=(200, 200),
scale=(0.1, 1),
ratio=(0.5, 2))
apply(example_image, shape_aug)