비지도 학습은 지도 학습처럼 레이블이 필요하지 않으며 정답이 없느 상태에서 훈련시키는 방식을 말한다.
비지도 학습에는 군집(clustering)과 차원 축소(dimensionality reduction)가 있다.
군집은 각 데이터의 유사성(거리)을 측정한 후 유사성이 높은(거리가 짧은)데이터끼리 집단으로 분류하는 것을 말한다.
차원 축소는 차원을 나타낸는 특성을 줄여서 데이터를 줄이는 방식이다.
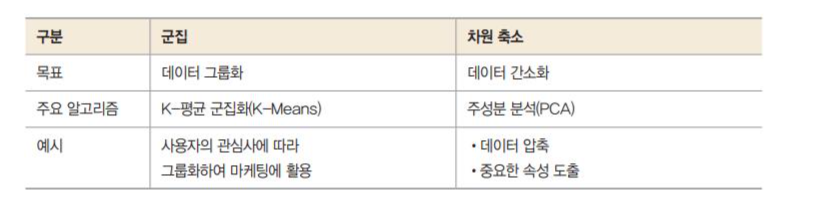
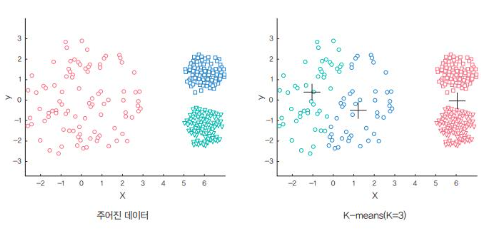
k-평균 군집화 / K-means clustering
K-평균 군집화는 데이터를 입력받아 소수의 그룹으로 묶는 알고리즘임.
레이블이 없는 데이터를 입력받아 각 데이터에 레이블을 할당해서 군집화를 수행하는데, 학습 과정은 다음과 같다.
1. 중심적 선택 : 랜덤하게 초기 중심점을 선택
2. 클러스터 할당 : k개의 중심점과 각각의 개별 데이터 간의 거리를 측정한 후, 가장 가까운 중심점을 기준으로 데이터를 할당이 과정을 통해 클러스터가 구성(이때 클러스터링은 데이터를 하나 혹은 둘 이상의 덩어리로 묶는 과정이며, 클러스터는 덩어리 자체를 의미함)
3. 새로운 중심점 선택 : 클러스터마다 새로운 중심점을 계산.
4. 범위 확인(convergence) : 선택된 중심점은 더 이상의 변화가 없다면 진행을 멈추고 만약에 계속 변화가 있다면 2~3 과정을 반복함.
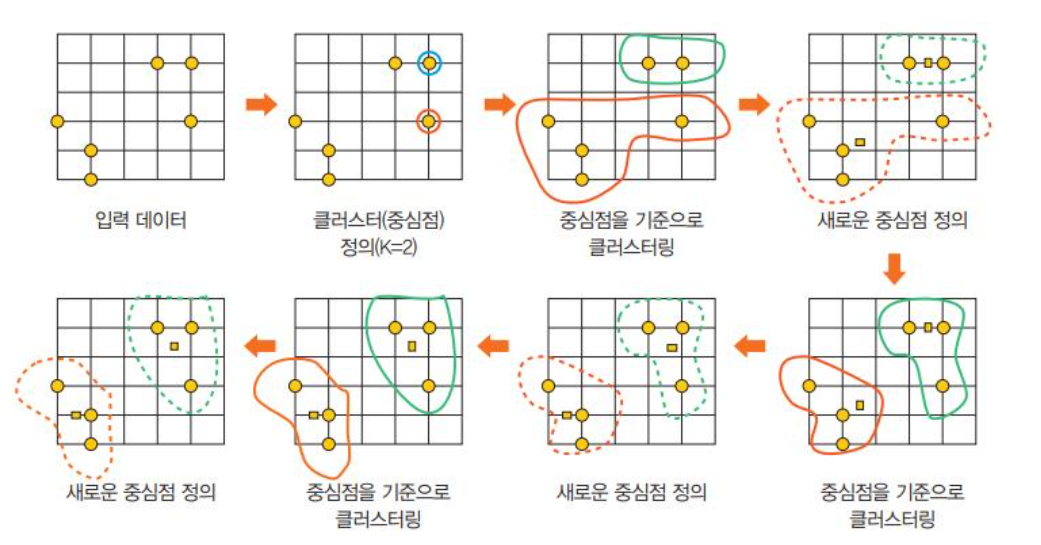
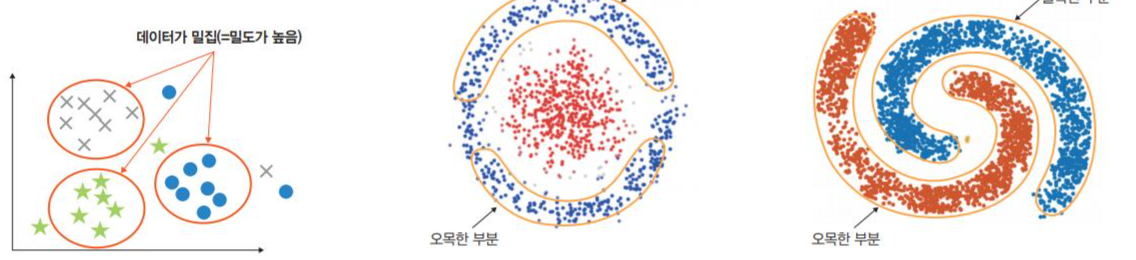
데이터가 비선형일 때 -
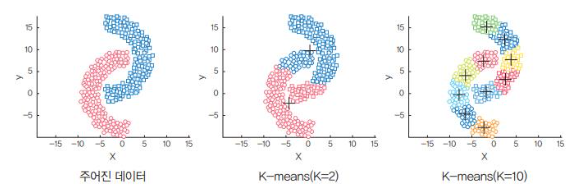
군집의 크기가 다를때 -
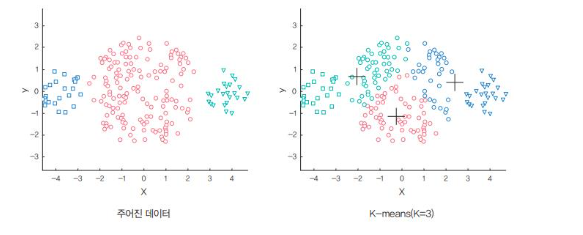
군집마다 밀집도와 거리가 다를 때 -
밀도 기반 군집 분석 / DBSCAN
왜 사용할까? -> 주어진 데이터에 대한 군집화
언제 사용하면 좋을까? -> k-평균 군집화와는 다르게 사전에 클러스터의 숫자를 알지 못할 때 사용하면 유용하고 주어진 데이터에 이상치가 많이 포함되었을 때 사용하면 좋다.
일정 밀도 이상을 가진 데이터를 기준으로 밀도를 형성하는 방법.
노이즈에 영향을 많이 받지 않으며 k-means clustering에 비해 연산량은 많지만 잘 처리하지 못하는 오목하거나 볼록한 부분을 처리하는데 유용함.
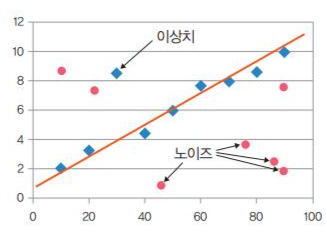
노이즈와 이상치 차이
노이즈는 주어진 데이터 세트와 무관하거나 무작위성 데이터로 전처리 과정에서 제거해야 할 부분이며 이상치는 관측된 데이터 범위에서 많이 벗어난 아주 작은 값이나 아주 큰 값을 말한다.
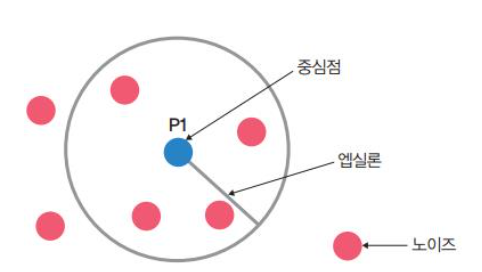
밀도 기반 군집 분석
1단계. 엡실론 내 점 개수 확인 및 중심점 결정.
밑에 그림과 같이 원 안에 점 P1에서 거리 엡실론(epsilon)내에 점이 m(minPts)개 있으면 하나의 군집으로 인삭한다고 가정하면 이때 엡실론 내에 점(데이터) m개를 가지고 있는 점 P1을 중심점이라고 한다. 예를 들어 minPts=3이라면 파란색 점 P1을 중심으로 반경 엡실론 내에 점이 세 개 이상 있으면 하나의 군집으로 판단할 수 있다. 다음 밑에 그림은 점이 네 개 있기 대문에 하나의 군집이 되고, P1은 중심점이 된다.
2단계. 군집 확장
1단계에서 새로운 군집을 생성했는데, 주어진 데이터를 사용하여 두 번째 군집을 생성해보면, 데이터의 밀도 기반으로 군집을 생성하기 때문에 밀도가 높은 지역에서 중심점을 만족하는 데이터가 있다면 그 지역을 포함하여 새로운 군집을 생성한다. 예를 들어 P1옆에 있던 빨간색 점을 중심점 P2로 설정하면 minPts=3을 만족하기 때문에 새로운 군집을 생성할 수가 있다.
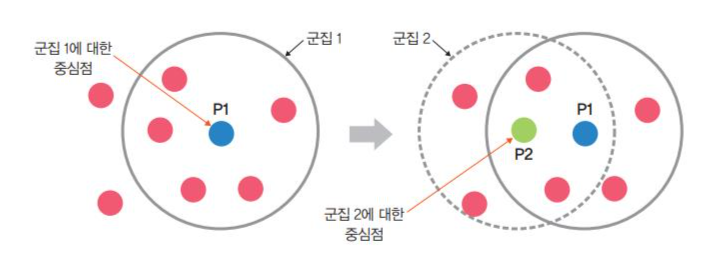
3단계. 1~2단계 반복
데이터가 밀집된 밀도가 높은 지역에서 더 이상 중심점을 정의할 수 없을 때까지 1~2단계 반한다.
4단계. 노이즈 정의
어떤 군집에도 포함되지 않은 데이터를 노이즈로 정의한다.
차원축소는 다음에!!
