
한달여 전, 정보처리기사 필기시험 합격을 했다. 무난히 기출만 잘 풀어봐도 통과할 정도의 난이도였고, 평균 75점 정도 나왔던 기억이 있다.
이제 실기를 공부해보려고 한다. 최근에 실기 시험에서 프로그래밍 문제의 비중이 조금 높아지고, 난이도도 어려워진다는 얘기를 듣고, 프로그래밍쪽부터 공부를 하기로 계획했다. 아무래도 개념 문제는 너무 범위가 넓어서 나 포함 많은 사람들이 프로그래밍 및 SQL쪽 문제에서 최대한 많은 문제를 맞추는 전략으로 가는듯 하다.
1. C의 특징

자바가 웹 애플리케이션이나 엔터프라이즈 백엔드 환경에서 주로 활약한다면, C는 하드웨어와 가장 가까운 곳, 시스템 레벨에서 주로 쓰인다.
운영체제(OS)와 같은 Linux 커널이나 윈도우의 핵심 로직이 대부분 C로 작성되어 있고, 스마트 기기, 센서, 가전제품 등 CPU나 메모리 자원이 제한적인 하드웨어를 가볍고 빠르게 제어할 때 C가 주로 쓰인다. 작성자 본인도 학교에서 OS 과목을 수강하면서 pintOS 프로젝트를 C로 진행했는데, C를 잘 몰라 매우 힘들었던 기억이 있다. 망할 핀토스
작성자에게 제일 익숙한 언어인 자바와 비교해보자면, 자바는 JVM이라는 가상머신 위에서 돌아가서 가비지 컬렉터처럼 알아서 메모리를 관리해주는 기능이 있어 유연하게 개발하기 좋다. 하지만 C는 컴파일러를 통해 직접 기계어로 변환되기에 코드를 짜는 개발자가 직접 메모리 주소를 다루고 자원을 할당/해제해야한다.
2. 포인터
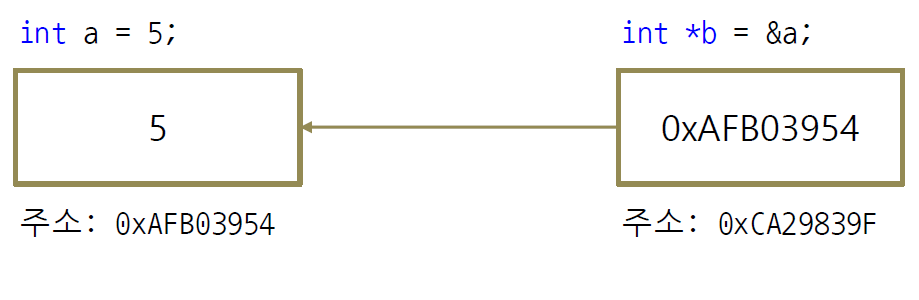
C에는 그 유명한 포인터가 있다. 자바에는 없는 개념이라 좀 계속 헷갈리긴 한다.
포인터란, 주소를 저장하는 변수다.
int a = 5;
int *p = &a;위 코드의 경우에 a에는 5가 들어가있고, p에는 a의 주소가 들어가 있다고 생각하면 된다.
'&'가 "주소를 꺼내라"라는 뜻이고, '*'는 "그 주소로 가서 실제 값을 꺼내라"이다.
즉, 위의 코드를 다시 보면, a에는 5라는 '값', &a는 a의 주소, p는 주소를 담은 변수, *p는 그 주소 안의 값이 되는 것이다.
포인터도 자료형이 있다.
int *p; //int를 가리키는 포인터
char *c; //char을 가리키는 포인터이게 중요한 이유는, 포인터가 한 칸 이동할 때 이동 크기가 자료형마다 다르기 때문이다.
int arr[] = {10, 20, 30};
int *p = arr;시험에서는 포인터+1은 다음 칸 이동이라고 생각하면 편하다.
변수를 처음 '선언할 때'와 나중에 '사용할 때' *의 의미는 완전히 다르다.
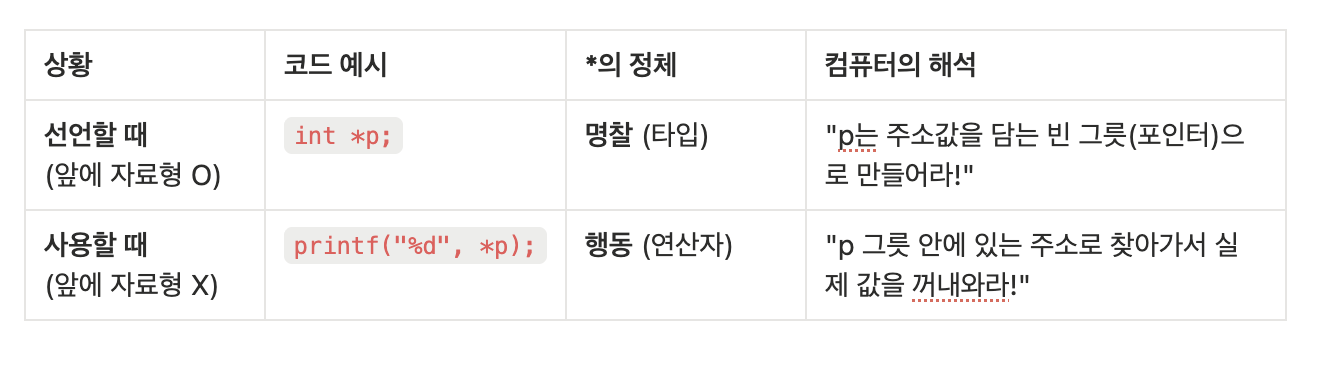
이 차이를 모르면 매우 헷갈릴 수 있다.
배열 이름은 첫 번째 칸의 주소처럼 생각하면 된다
int arr[] = {10, 20, 30};
printf("%d", arr[1]);
printf("%d", *(arr+1));위와 같은 코드가 있을 때, arr = &arr[0]처럼 생각하면 되고, arr = arr[0], (arr+1) = arr[1] 라고 이해하면 된다. 배열 이름 자체가 "첫 번째 원소의 주소"가 되는 것이다.
printf("%d", arr[1]); // 20
printf("%d", *(arr+1)); // 20이중 포인터는, "포인터를 가리키는 포인터"다.
int a = 10;
int *p = &a;
int **pp = &p;p가 a의 주소를 담고, pp는 p의 주소를 담고, *pp는 p의 값(a의 주소), **pp는 10이 되는 것이다. 이렇게 보니까 좀 헷갈리긴 한다. 이중 포인터의 개념을 정확히 알고가자.
3. 배열
자바에서 배열은 객체 느낌이 강하지만, C 배열은 메모리에 값이 줄줄이 붙어서 저장된 것이라고 생각하면 된다.
int arr[3] = {1, 2, 3};이게 대표적인 C의 배열 선언이다. 선언할 때 자료형과 같이 쓰인 arr[3]의 3이 index가 아니라 3이 배열의 크기라는 것을 유의하자.
arr[i] = *(arr+i)
- arr[0] = *arr
- arr[1] = *(arr+1)
이건 엄청 자주 나온다. arr이라는 배열의 이름 자체가 배열의 첫 번째 원소의 '주소'를 가리키므로, *가 붙으면 배열의 첫 번째 값이 되는 것이다.
C에도 2차원 배열이 있다. 또, 포인터를 저장하는 배열도 있다.
int *parr[2];위의 코드는 포인터 2개를 저장하는 배열을 선언하는 방식이다. 포인터를 저장하는데 왜 '&'를 안 쓰고 ''를 쓰냐고 묻는다면, '&'은 이미 만들어져 있는 변수에게 가서 '너의 메모리 주소를 가져와'라는 '동사적 성격'을 띄고, ''기호가 선언할 때 붙으면 '이 배열은 '주소'를 저장할 방이구나'라고 인식하게 되기에 *를 사용하는 것이다.
4. C 문자열
C는 문자열이 '문자 배열'이다.
자바에는 "ABC"처럼 String 객체가 따로 존재했지만, C는 그렇지 않다.
char str[] = "ABC";위의 코드처럼 str이라는 문자 배열에 A, B, C가 하나씩 순서대로 저장되고, 마지막에 '\0' 이라는 '문자열 끝'을 표시하는 원소가 들어간다.
char a[] = "Art";
char *p = a;a는 문자 배열이고, p는 이 문자 배열의 첫 글자를 가리키는 포인터다. 시험에서 '문자열의 시작점을 가리키는 의미'로 잘 나오니 기억해두자.
strlen은 문자열 길이를 구하는 함수다.
strlen("ABC") // 3for (i = 0; str[i] != '\0'; i++) //끝 표시가 나올 때까지 한 글자씩 보기while (*s) {
*d = *s; //s가 가리키는 글자를 d가 가리키는 곳에 복사
d++; // d 다음칸으로 이동
s++; //s 다음칸으로 이동
}위의 코드는 문자열을 한 글자씩 복사하는 코드다. 시험에서는 위와 반대로 양쪽 끝에서 안쪽으로 가면서 바꾸는, 문자열 전체를 뒤집는 코드도 많이 나온다.
#include <stdio.h>
#include <string.h>
void reverseString(char *str) {
// 1. 양 끝을 가리키는 포인터 설정
char *start = str; // 문자열의 첫 글자를 가리킴
char *end = str + strlen(str) - 1; // 문자열의 마지막 글자를 가리킴
char temp; // 값을 교환하기 위한 임시 빈 잔
// 2. start와 end가 만나거나 엇갈리기 전까지 반복
while (start < end) {
// 3. 값 교환 (Swap) 알고리즘
temp = *start; // 첫 글자를 임시 공간에 보관
*start = *end; // 마지막 글자를 첫 글자 위치에 덮어씀
*end = temp; // 보관해둔 첫 글자를 마지막 위치에 넣음
// 4. 포인터 이동
start++; // 왼쪽 포인터는 오른쪽으로 한 칸 이동
end--; // 오른쪽 포인터는 왼쪽으로 한 칸 이동
}
}
int main() {
char arr[] = "HELLO"; // 뒤집을 문자열 배열
reverseString(arr);
printf("%s\n", arr); // 출력 결과: OLLEH
return 0;
}
// 인덱스를 사용하는 방식 (원리는 포인터와 100% 동일)
int left = 0;
int right = strlen(str) - 1;
char temp;
while (left < right) {
temp = str[left];
str[left] = str[right];
str[right] = temp;
left++;
right--;
}C에서는 문자가 숫자처럼 움직인다.
자바에서도 char가 숫자값이 있긴 하지만, 잘 써먹진 않는 반면, C에서는 자주 사용한다.
'E' - 'A' // 4
'3' - '0' // 3A와 E 사이에 B, C, D 거리가 4이기 때문에 4가 출력된다. 또 아랫줄처럼 문자열을 숫자처럼 계산하는 식으로 사용도 가능하다.
5. 함수

C는 기본적으로 값만 복사해서 넘긴다.
void swap(int a, int b) {
int t = a;
a = b;
b = t;
}위의 코드는 a와 b를 바꾸는 함수가 아니다. 이 함수의 경우 원본이 아닌 복사본만 받게 된다. main에 있던 진짜 a,b가 들어가지 않고, 그 값을 복사한 '새 변수' a,b가 들어간다.
원본을 바꾸려면, 주소를 넘겨야 한다.
void swap(int *a, int *b)이렇게 주소를 받아야 원본 위치를 직접 바꿀 수 있다.
static 지역 변수는 함수가 끝나도 값이 유지된다.
int f() {
int x = 0;
x++;
return x;
}이건 매번 호출할 때마다 x가 0으로 다시 시작하지만,
int f() {
static int x = 0;
x++;
return x;
}static으로 선언하게 되면, 첫 번째 호출 1, 두 번째는 2, 이렇게 함수가 끝나도 값이 유지되어 누적이 된다. 시험에서 이걸 활용한 누적값 문제를 많이 낸다.
6. 구조체(struct)
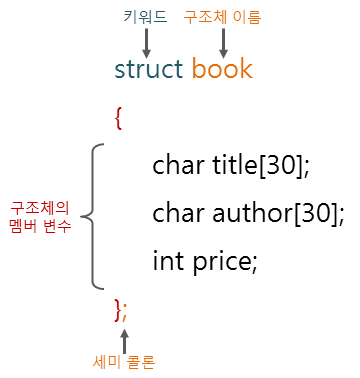
구조체는 '관련 있는 데이터의 묶음' 정도로 보면 된다.
struct Person {
char name[20];
int age;
};위의 코드는 이름, 나이를 하나로 묶은 자료형이다. 자바의 class처럼 메서드, 상속 이런걸 굳이 생각할 필요는 없다.
//구조체 멤버 접근
p.age //변수 접근은 '.'
ptr->age // 포인터 접근은 '->'
(*ptr).agep가 구조체를 가리키는 포인터일 때 '.'이나 '->'를 사용해 접근한다.
구조체에 포인터가 합쳐지면 연결 리스트를 구현할 수 있다.
struct Node {
int value; //일반 변수
struct Node *next; //포인터 변수
};이렇게 되면 각 노드가 자기 값 하나, 다음 노드를 가리키는 주소 하나를 가진다는 뜻이다. 다만, 위의 코드가 구조체 안에 구조체가 들어간 형태는 아니다. next는 다음 노드의 메모리 주소를 담는 '포인터 변수'인 것이다.
- head : 첫 번째 노드
- head->value : 첫 번째 노드 값
- head->next : 두 번째 노드 주소
- head->next->value : 두 번째 노드 값
7. Bit 연산 & Shift 연산
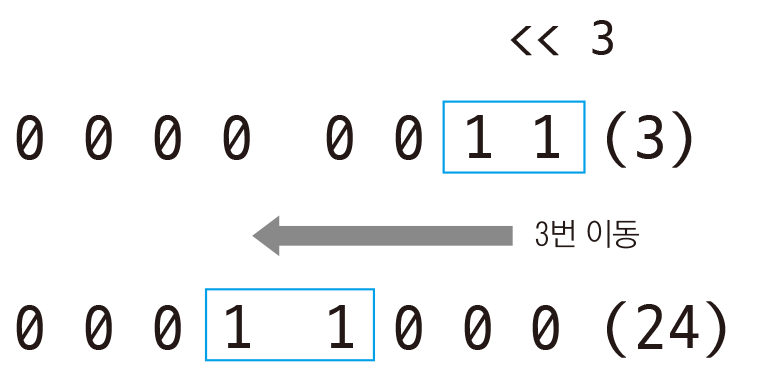
비트 연산과 시프트 연산은 숫자를 이진수로 다루는 문제다. 다소 난이도가 있는 내용이긴 하지만, 정처기에서는 깊게까지는 안간다.
35 << 2 //140이건 왼쪽으로 2칸 민 형태인데, 시험에서는 왼쪽으로 1칸은 2배, 2칸은 4배라고 생각하면 된다. 반대로 >>은 보통 2로 나누는 느낌으로 본다.
비트 연산 기호
• & : 둘 다 1일 때만 1
• | : 하나라도 1이면 1
• ^ : 서로 다를 때만 1
• ~ : 0과 1 뒤집기
다른 건 몰라도 &과 >>, << 연산자는 꼭 기억하도록 하자.
0x로 시작하면 16진수고, 2진수로 바꿔서 직접 보는게 맞다.
8. switch문의 함정
switch문에서, break가 없으면 아래의 코드도 계속 실행된다는걸 기억하자.
switch(a) {
case 11:
b += 2;
default:
b += 3;
break;
}a가 11이면 case 11이 실행되지만, break;가 없어서 아래의 default도 실행된다. C에서 이걸 함정으로 많이 내니 switch문이 나오면 break가 어디있는지 확인해봐야 한다.
9. malloc: 동적 메모리 할당
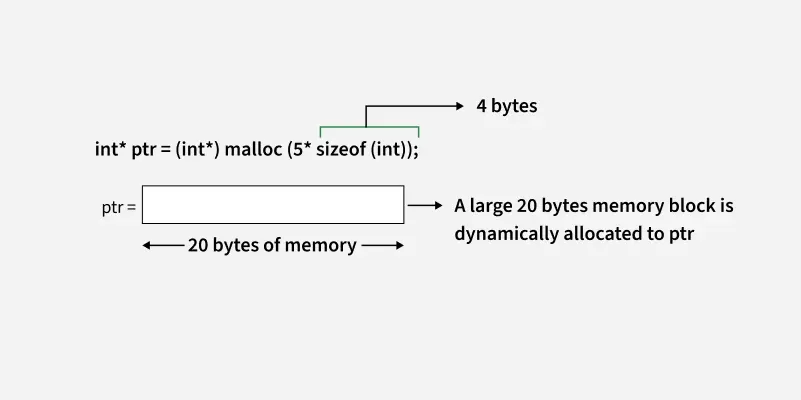
malloc은 '자바의 new'와 똑같은 역할이다.
'동적 메모리 할당'은, 프로그램이 실행되는 도중에 딱 필요한 크기의 공간만큼만 OS로부터 빌려오는 효율적인 방식이다. 여기에 대표적으로 활용되는게 malloc인 것이다.
반면에 정적 할당은 int arr[100]과 같이 미리 size를 정해놓고 할당해놓는 비효율적인 방식이다.
res = (int **)malloc(sizeof(int *) * rows);위 코드는 rows 개수만큼 포인터를 담을 공간을 만든다는 뜻이다.
다 쓰면 'free'로 메모리도 반납해주어야 한다.
자바의 경우, new로 새 객체를 선언하고 안쓰게 되면 가비지 컬렉터가 알아서 객체를 치워줘 메모리 걱정을 할 필요가 없지만, C언어는 따로 이런 기능이 없다. 따라서 free로 메모리를 해제해줘야, Memory leak(메모리 누수)가 발생하지 않는다.
*꼭 기억해야 할 것들
배열은 객체가 아니다.
C배열은 값들이 연속적으로 붙어있는 메모리 덩어리다. 배열 이름은 시험에서 거의 첫 번째 칸 주소처럼 쓰인다.
문자열은 String이 아니다.
C 문자열은 char 배열 + 마지막 '\0'이다.
함수에서 원본을 바꾸려면 주소를 넘거야 한다.
switch는 해당 case만 실행되지 않고, break가 없으면 계속 실행된다.
